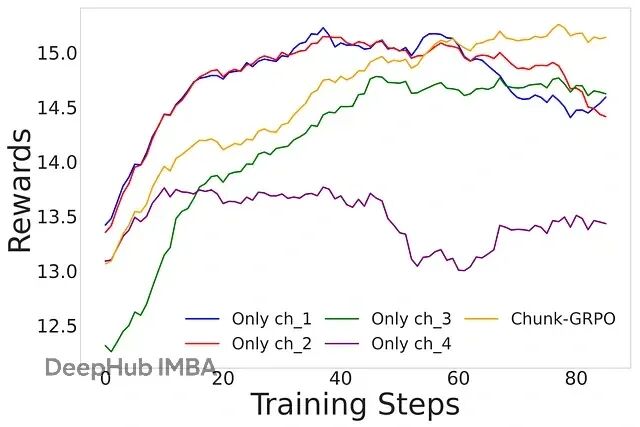
解决GRPO优势归因错误,Chunk-GRPO让文生图模型更懂"节奏"
Chunk-GRPO的解决办法是把连续时间步分组成"块",把这些块作为整体单元来优化,让训练信号更平滑,过程更稳定。
从零开始训练推理模型:GRPO+Unsloth改造Qwen实战指南
这篇文章会先介绍 GRPO的基本概念,然后我们会动手写代码训练一个推理 LLM,在实践中理解整个流程。
Chunk-GRPO的解决办法是把连续时间步分组成"块",把这些块作为整体单元来优化,让训练信号更平滑,过程更稳定。
这篇文章会先介绍 GRPO的基本概念,然后我们会动手写代码训练一个推理 LLM,在实践中理解整个流程。



