
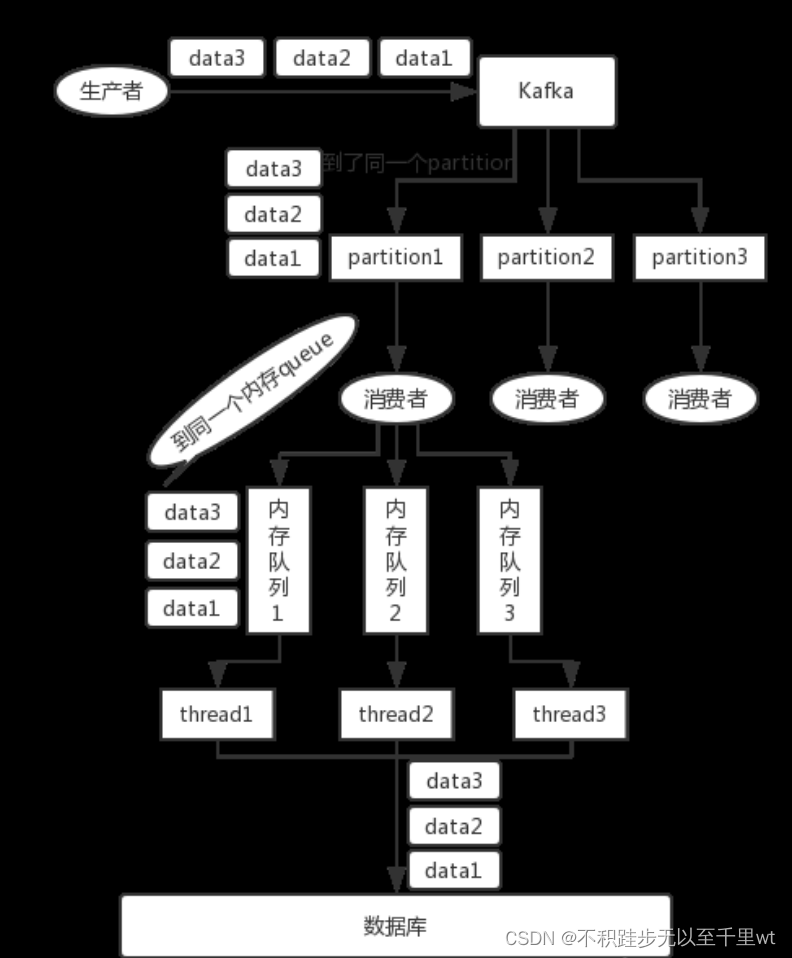
Kafka消息生产
一个Topic对应一个Partition
生产者生产的所有数据都会发送到此Topic对应的Partition下,从而保证消息的生产顺序。
一个Topic对应多个Partition
此时Kafka根据时机情况采取三种消息分发机制:
- partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
- 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition数进行取余得到 partition 值;在Producer往Kafka插入数据时,控制同一Key分发到同一Partition。
- 既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition值,也就是常说的 round-robin 算法。
Kafka消息的顺序性保证(Producer、Consumer)
- 全局有序: 一个Topic下的所有消息都需要按照生产顺序消费。
- 局部有序:一个Topic下的消息,只需要满足同一业务字段的要按照生产顺序消费。例如:Topic消息是订单的流水表,包含订单orderId,业务要求同一个orderId的消息需要按照生产顺序进行消费。
全局有序
全局有序需要保证一个Topic下的所有消息都需要按照生产顺序消费。此时设置**一个Topic下只对应一个Partition即可。而且对应的consumer也要使用单线程或者保证消费顺序的线程模型。****即可保证全局有序。**
局部有序
要满足局部有序,只需要在发消息的时候指定Partition Key,Kafka对其进行Hash计算,根据计算结果决定放入哪个Partition。这样Partition Key相同的消息会放在同一个Partition。此时,Partition的数量仍然可以设置多个,提升Topic的整体吞吐量。并且为了达到严格的顺序消费还需要
max.in.flight.requests.per.connection = 1。
不直接指定对应的Partition而是指定Partition Key
- 直接指定Partition,将所有消息指定到一个Partition中,此时相当于全局有序,此Topic下的其他Partition无用,浪费资源。
- 将不同的消息设置不同的Partition,此时生产者需要进行额外的计算,不好控制具体的Partition值。
在不增加partition数量的情况下想提高消费速度,可以考虑再次hash唯一标识(例如订单orderId)到不同的线程上,多个消费者线程并发处理消息(依旧可以保证局部有序)。
max.in.flight.requests.per.connection参数详解
消息重试对消费顺序的影响:**对于一个有着先后顺序的消息A、B,正常情况下应该是A先发送完成后再发送B,但是在异常情况下,在A发送失败的情况下,B发送成功,而A由于重试机制在B发送完成之后重试发送成功了。这时对于本身顺序为AB的消息顺序变成了BA。**
针对这种问题,严格的顺序消费还需要
max.in.flight.requests.per.connection
参数的支持。该参数指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,同时也会提升吞吐量。把它设为1就可以保证消息是按照发送的顺序写入服务器的。

保证消息不丢失是一个消息队列中间件的基本保证,那producer在向kafka写入消息的时候,怎么保证消息不丢失呢?其实上面的写入流程图中有描述出来,那就是通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
- 0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
- 1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
- all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
最后要注意的是,如果往不存在的topic写数据,能不能写入成功呢?kafka会自动创建topic,分区和副本的数量根据默认配置都是1。
此外,对于某些业务场景,设置
max.in.flight.requests.per.connection
=1会严重降低吞吐量,如果放弃使用这种同步重试机制,则可以考虑在消费端增加失败标记的记录,然后用定时任务轮询去重试这些失败的消息并做好监控报警。
Kafka为什么这么快
Kafka不基于内存,而是基于磁盘,因此消息堆积能力更强。
顺序写磁盘,充分利用磁盘特性:利用磁盘的顺序访问速度可以接近内存,kafka的消息都是append操作,partition是有序的,节省了磁盘的寻道时间,同时通过批量操作、节省写入次数,partition物理上分为多个segment存储,方便删除;
零拷贝:- Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入。 - mmap()系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作;
Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗。 - 传统: - 读取磁盘文件数据到内核缓冲区;- 将socket发送缓冲区中的数据发送到网卡、进行传输;- 将用户缓冲区的数据copy到socket的发送缓冲区;- 将内核缓冲区的数据copy到用户缓冲区;Kafka不依赖于JVM,主要依赖OS的PageCache,如果生产消费速率相当,直接使用PageCache交换数据,不需要经过系统磁盘。
消息压缩:Producer 可将数据压缩后发送给 broker,从而减少网络传输代价,目前支持的压缩算法有:Snappy、Gzip、LZ4。数据压缩一般都是和批处理配套使用来作为优化手段的。
分批发送:批量处理,合并小的请求,然后以流的方式进行交互,直顶网络上限;
参考链接
一文理解Kafka如何保证消息顺序性-腾讯云开发者社区-腾讯云 (tencent.com)
Kafka基本原理详解(超详细!)_kafka工作原理-CSDN博客
如何保证kafka消费的顺序性_kafka顺序消费 如何控制-CSDN博客
版权归原作者 不积跬步无以至千里wt 所有, 如有侵权,请联系我们删除。