
场景应用和使用
在自动化测试中,部分场景无法使用自动化Selenium原生方法来进行测试:
滚动到某个元素(位置)修改时间控件(修改元素属性)其它场景
因此我们需要使用js脚本来执行,js脚本有两种执行场景:
在页面上直接执行js定位到指定元素再执行js
WebDriver有两个方法来执行JavaScript,分别是:
- execute_script(同步执行)
- execute_async_script(异步执行)
下面将介绍使用execute_script()方法执行js的实例
页面滚动
1.滚动页面操作
页面滚动我们可以滚到到指定位置,也可以滚到到页面底部
页面滚动使用
window.scrollTo(x,y)
来进行滚动,其中x表示横向滚动的位置,y表示纵向滚动的位置
1.滚动到指定位置
假设我们想滚动到距离顶部1000的位置,我们可以设置x=0,y=1000,如下:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
class casetest(object):
def __init__(self):
self.driver = webdriver.Edge()
self.driver.get('http://wwww.baidu.com')
def test_execute(self):
# 滚动条滚动
self.driver.find_element(By.ID,('kw')).send_keys('selenium')
self.driver.find_element(By.ID,('su')).click()
sleep(2)
#滚动到指定位置
js= 'window.scrollTo(0,1000)'
#使用execute_script执行js脚本
self.driver.execute_script(js)
sleep(2)
if __name__ == '__main__':
case = casetest()
case.test_execute()
case.driver.quit()
运行后,我们发现位置已经在距离顶部1000的位置了
或者我们可以使用Document来实现
js脚本如下:
js = 'document.documentElement.scrollTop=1000'
document:这是 JavaScript 中的一个全局对象,代表当前网页文档。documentElement:这是document对象的一个属性,它代表整个文档的根元素,在 HTML 页面中通常是<html>元素。scrollTop:这是document.documentElement的一个属性,表示当前文档根元素的垂直滚动条的位置,即页面在垂直方向上滚动的距离,以像素为单位。1000即为滚动1000个像素
2.滚动到窗口底部
同样的,如果我们想滚动到窗口底部,我们可以使用刚才说的 scrollTo方法,这样写js脚本:
js = 'window.scrollTo(0,document.body.scrollHeight)'
只不过y轴高度变成了整个文档元素的高,相当于滑到了最底下:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
class casetest(object):
def __init__(self):
self.driver = webdriver.Edge()
self.driver.get('http://wwww.baidu.com')
def test_execute(self):
self.driver.find_element(By.ID,('kw')).send_keys('selenium')
self.driver.find_element(By.ID,('su')).click()
sleep(2)
#滚动到网页底部
js = 'window.scrollTo(0,document.body.scrollHeight)'
#使用execute_script执行js脚本
self.driver.execute_script(js)
sleep(2)
if __name__ == '__main__':
case = casetest()
case.test_execute()
case.driver.quit()
这样就把窗口界面的滚动说完了
获取返回值
以博客园某作者为例,https://www.cnblogs.com/yoyoketang/,**以获得“博客园”这个文本为例**

我们首先定位到博客园,找到该元素的相关属性
这样我们找到了id属性,便可以利用js定位到该属性了,然后我们可以使用innerText()来获得该文本。
我们首先可以不在代码中执行,打开F12,点击控制台,输入定位的元素. innerText,可以直接进行调试,获得返回结果,我们可以看一下:
可以看到已经返回结果了,此时我们可以把这段js写到代码中了,需要注意的是,**在代码中加入时,需要在前面写上return 才可以正常返回! **
代码如下:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
class casetest(object):
def __init__(self):
self.driver = webdriver.Edge()
self.driver.get('https://www.cnblogs.com/yoyoketang/')
def test_execute(self):
js = ('return '
'document.getElementById("blog_nav_sitehome").innerText')
res = self.driver.execute_script(js)
print(res)
sleep(2)
if __name__ == '__main__':
case = casetest()
case.test_execute()
case.driver.quit()
可以看到文本值已经被返回并输出出来了:
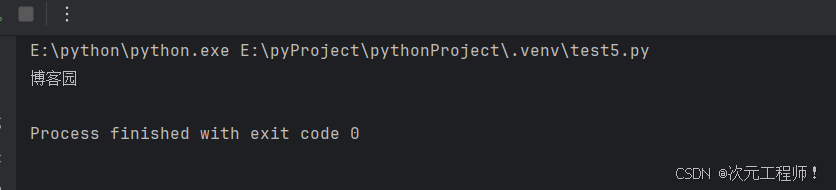
返回JavaScript定位的元素对象
当我们定位元素以后,我们使用js可以将它获取到,然后继续再selenium中使用它,还是以上一个例子为例,我们此时拿到“博客园”这一整个元素,便可以拿到它的所有属性了,如下:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
class casetest(object):
def __init__(self):
self.driver = webdriver.Edge()
self.driver.get('https://www.cnblogs.com/yoyoketang/')
def test_execute(self):
js = ('return document.getElementById("blog_nav_sitehome")')
res = self.driver.execute_script(js)
#获取元素文本
print(res.text)
#获取元素href属性
link = res.get_attribute("href")
print(link)
#点击元素
res.click()
sleep(2)
if __name__ == '__main__':
case = casetest()
case.test_execute()
case.driver.quit()
可以看到文本和;链接已经被打印出来了:
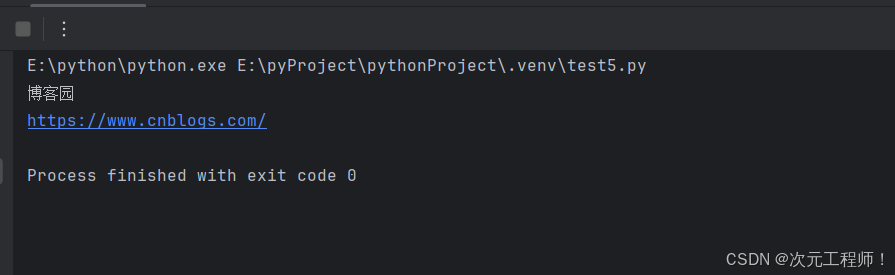
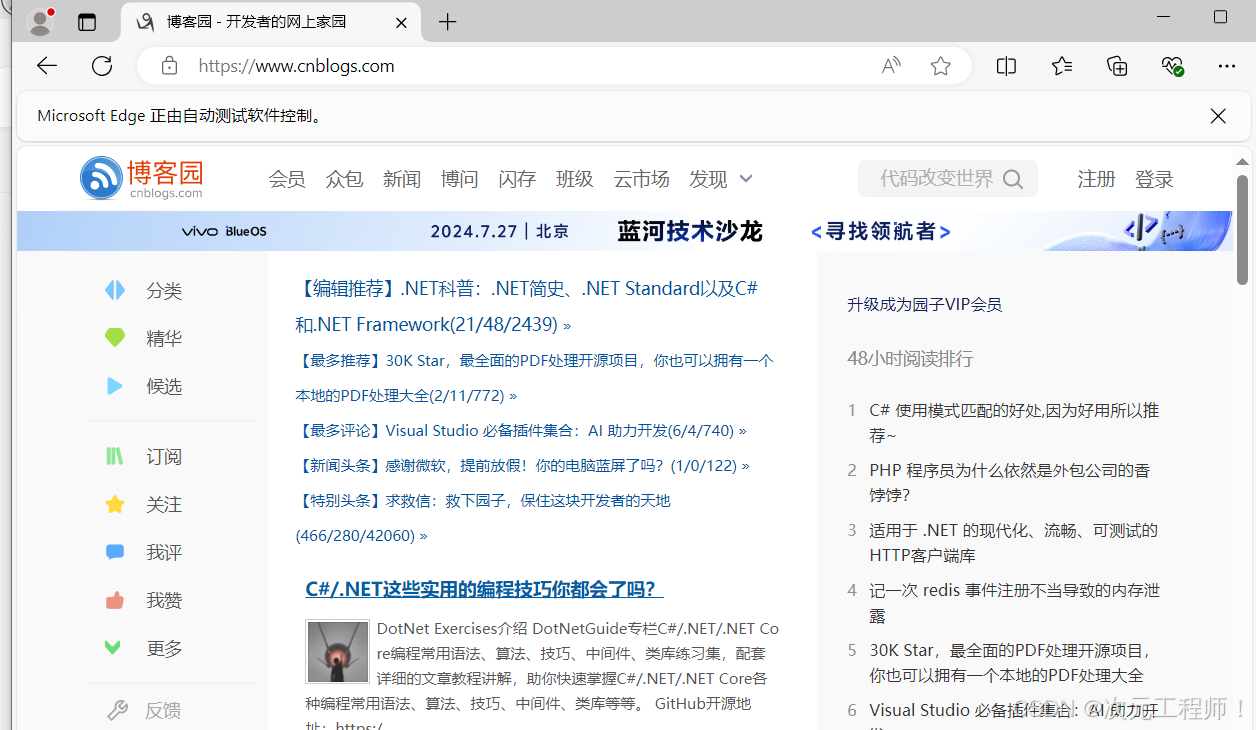
同时也点击了“博客园”这个元素,进入了我们想要的界面
修改元素属性
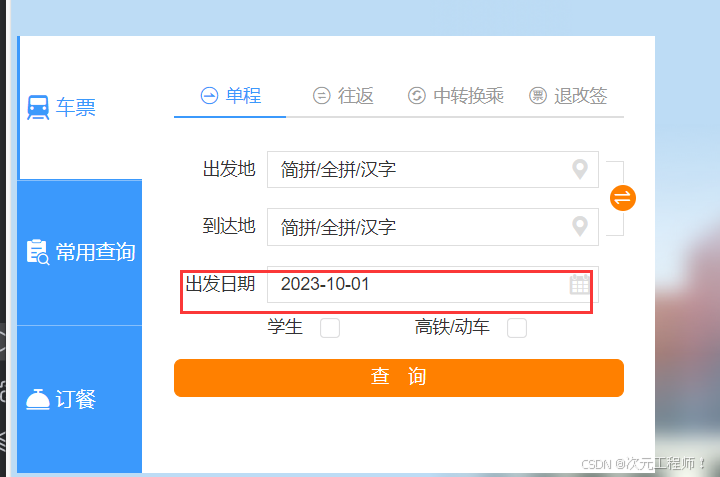
大部分时间控件都是 readonly属性,需要手动去选择对应的时间。自动化测试中,可以使用JavaScript代码取消readonly属性,这样便可以自己输入时间,而避免了必须选择手动日期
测试网站:中国铁路12306网站
整体测试步骤:
1.打开测试页面
2.定位元素,移除只读属性
3.修改日期并断言是否修改成功
代码如下:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
class casetest(object):
def __init__(self):
self.driver = webdriver.Edge()
def test_datettime(self):
self.driver.get("https://www.12306.cn/index/")
# 取消readonly属性
self.driver.execute_script("dat=document.getElementById('train_date'); dat.removeAttribute('readonly')")
#修改出发时间为2023-10-1
self.driver.execute_script("document.getElementById('train_date').value='2023-10-01'")
time.sleep(3)
now_time = self.driver.execute_script("return document.getElementById('train_date').value")
#判断是否修改成功
assert '2023-10-01' == now_time
if __name__ == '__main__':
case = casetest()
case.test_datettime()
case.driver.quit()
可以看到日期已经被成功修改
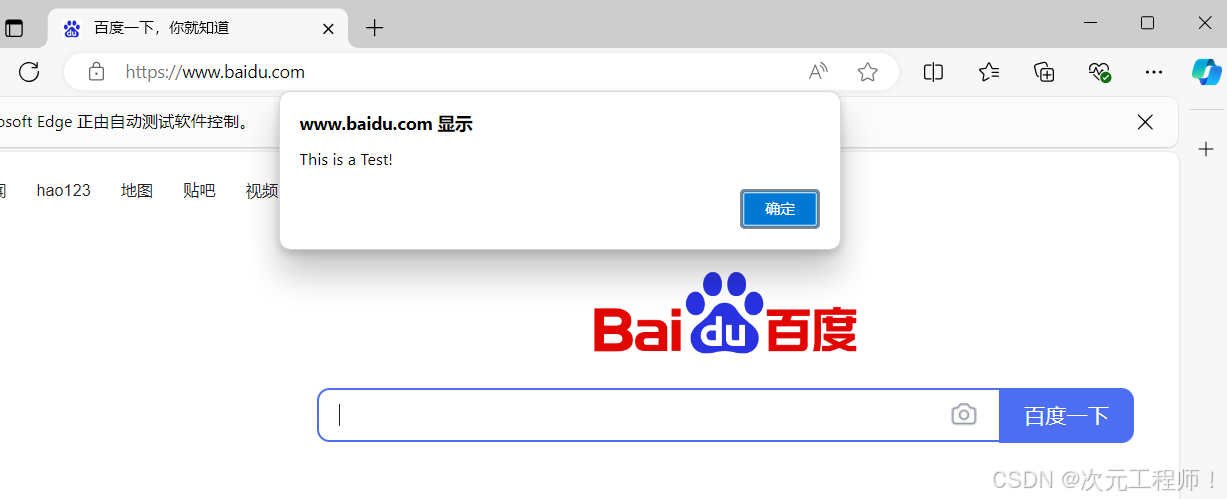
弹出提示框
alert可以弹出一个提示框,用法为alert("显示的文本")
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
class casetest(object):
def __init__(self):
self.driver = webdriver.Edge()
self.driver.get("http://baidu.com")
def test_execute(self):
js = "alert('This is a Test!')"
self.driver.execute_script(js)
sleep(2)
if __name__ == '__main__':
case = casetest()
case.test_execute()
case.driver.quit()
测试效果如下:
到这里,关于execute_script的一些基本用法就结束了,总的来说,通过 execute_script 方法,利用 JavaScript 的强大功能与页面进行更深入的交互,完成一些 Selenium 本身无法直接实现的功能,从而更灵活地进行 Web 自动化测试或数据抓取任务。
简洁来说,就是使用selenium执行js脚本,进而完成selenium自动化不能完成的事情
到这里本文章就结束了,入如果有疑问,欢迎指正私信或评论区留言~
版权归原作者 次元工程师! 所有, 如有侵权,请联系我们删除。