
文章目录
HDFS安全模式
注意:只有安全模式关闭时,上传下载文件才会生效

如果Safemode is on
执行
hdfs dfsadmin -safemode leave
提交文件
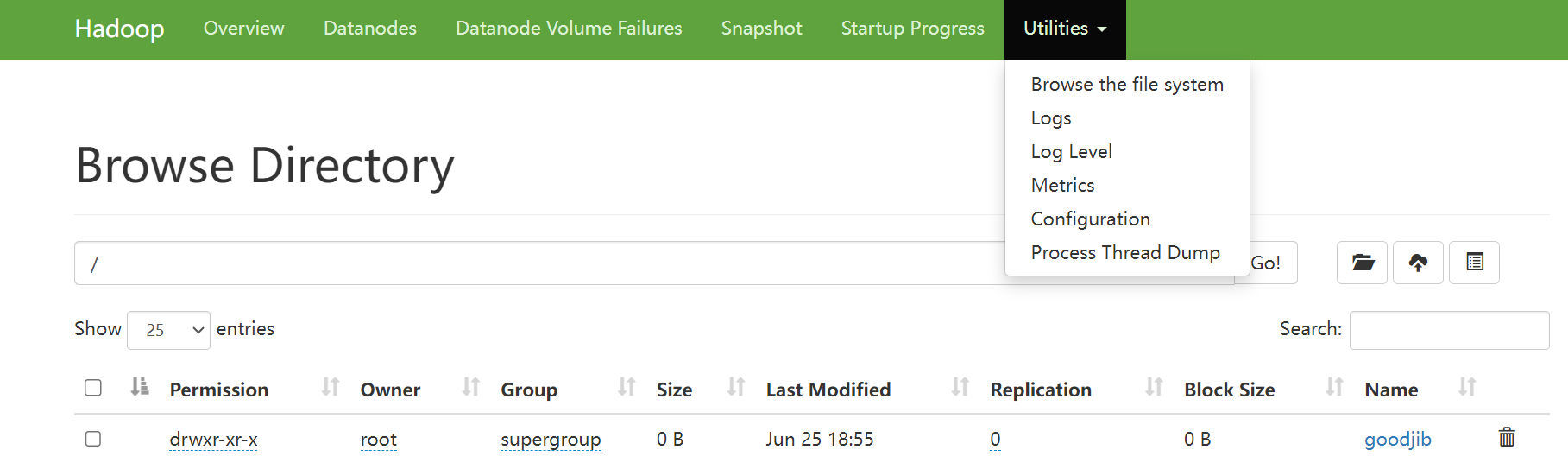
在此可对文件进行操作
创建Maven项目

在pom.xml注入依赖
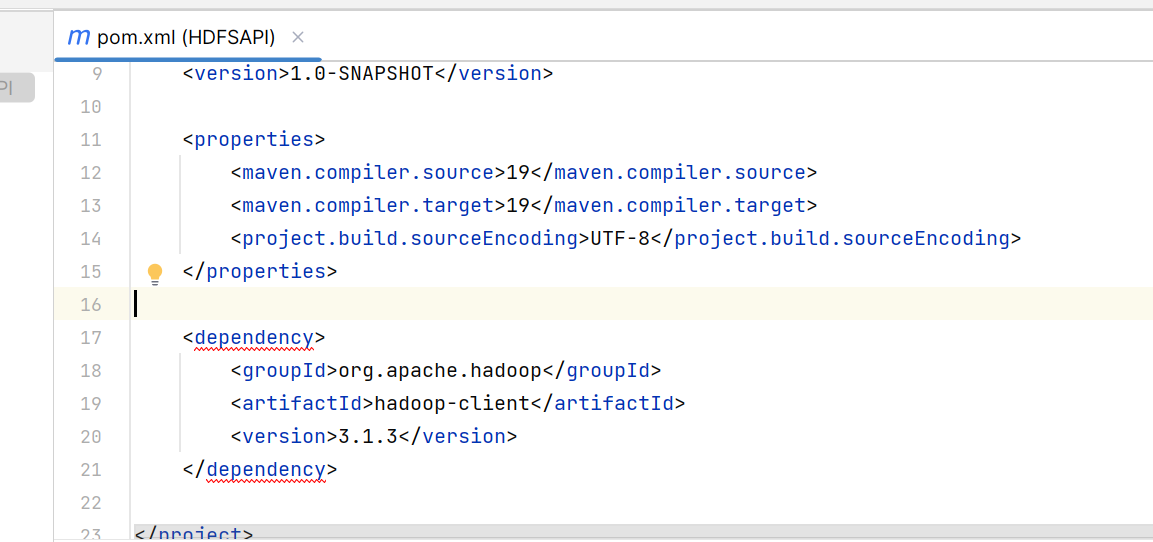
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
创建两个类

获取hdfs连接对象
在HDFSUTIL创建连接对象,并输出进行测试
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import java.io.IOException;
import java.net.URI;
public class HDFSUTILS {
static FileSystem fileSystem;
//获取HDFS连接对象
static {
Configuration conf = new Configuration();
try {
fileSystem = FileSystem.get(URI.create("hdfs://192.168.117.128:9000"), conf, "root"); //参数1是链接参数,2是配置项,3是用户名
System.out.println(fileSystem);
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
//让外部可访问到连接对象
public static FileSystem getFileSystem(){
return fileSystem;
}
public static void main(String[] args) {
}
}
可以看到连接成功

实现各种方法
创建目录
在HDFSAPI创建mkdir方法,并测试是否创建成功
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class HDFSAPI {
//创建目录
public static void mkdir(String fileName){
//获取连接对象
FileSystem fileSystem = HDFSUTILS.getFileSystem();
//创建
try {
boolean mkdir = fileSystem.mkdirs(new Path(fileName));
if(mkdir){
System.out.println("成功");
}else{
System.out.println("失败");
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) {
mkdir("/hello world!"); //代表根目录下文件夹
}
}
输出成功:

库里也有文件
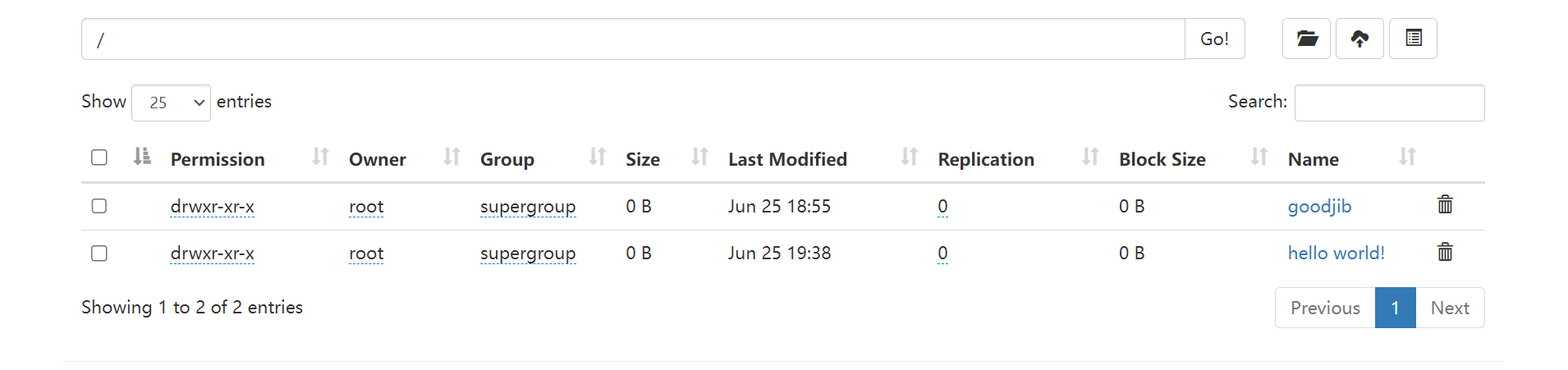
删除
增加方法
//删除
public static void deletefile(String fileName){
FileSystem fileSystem = HDFSUTILS.getFileSystem();
try {
boolean delete = fileSystem.delete(new Path(fileName), true);
if (delete){
System.out.println("删除成功");
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
调用
public static void main(String[] args) {
// mkdir("/hello world!");
deletefile("/goodjib");
}
打印的结果

库:

移动与重命名
可用于移动也可用于重命名
增加方法
//移动目录
public static void renameFile(String path1, String path2){
FileSystem fileSystem = HDFSUTILS.getFileSystem();
try {
boolean rename = fileSystem.rename(new Path(path1), new Path(path2));
if (rename){
System.out.println("修改成功");
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
调用方法进行测试
public static void main(String[] args) {
// mkdir("/hello world!");
//deletefile("/goodjib");
renameFile("/hello world!", "/new world!");
}
打印的结果
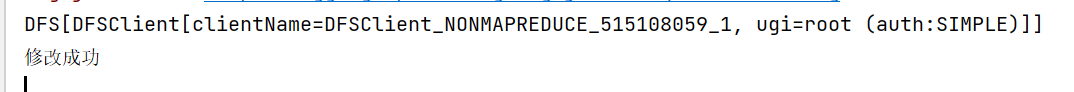

查询
FileStatus:FileStatus对象封装了文件系统中文件和目录的元数据,包括文件的长度、块大小、备份数、修改时间、所有者以及权限等信息。
递归查询:查询当前目录下文件,且查询当前目录文件夹内的文件,层层递归
时间戳:定义为从格林威治时间1970年01月01日00时00分00秒起至现在的总秒数。
当前目录查询
//查询当前路径下,不显示当前目录下文件夹里面的内容
public static void findFiles(String fileName){
FileSystem fileSystem = HDFSUTILS.getFileSystem();
try {
FileStatus[] fileStatus = fileSystem.listStatus(new Path(fileName));
//遍历
for (FileStatus fs : fileStatus){
System.out.println("文件路径:"+fs.getPath());
System.out.println("文件大小:"+fs.getLen());
System.out.println("文件副本数:"+fs.getReplication());
System.out.println("文件上传时间:"+fs.getModificationTime());
//之后可自行进行转换 System.out.println("***************************************************");
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
成功显示

查询所有目录
此时需要使用迭代器,参考:
海量数据在处理过程中可能占用大量的内存空间,而使用迭代器(Iterator)可以有效地节省内存开销。下面是一些关键原因:
- 内存效率:集合(例如列表、集、字典)在内存中存储所有数据。如果数据集非常庞大,一次性将所有数据加载到内存中可能导致内存溢出。相比之下,迭代器每次只会加载并处理一部分数据,这样可以避免将整个数据集一次性加载到内存中。
- 延迟计算:迭代器使用惰性计算的方式,只在需要时逐个生成数据项。这对于处理海量数据非常有用,因为它允许你在数据生成的同时进行其他操作,而无需等待整个数据集加载完毕。
- 时间效率:当处理大规模数据集时,迭代器可以在每次迭代中只处理当前数据项,而不需要对整个集合进行遍历。这样可以减少不必要的计算时间和遍历开销。
- 存储效率:迭代器通常只需要存储单个数据项的引用或状态信息,而不需要为整个数据集分配额外的内存空间。相比之下,集合需要为每个数据项都分配内存,导致额外的存储开销。
需要注意的是,迭代器并不适用于所有场景。如果需要在数据处理过程中进行多次随机访问或需要在不同阶段对数据进行多次遍历,集合可能更适合。此外,使用迭代器也可能增加代码的复杂性,因为你需要手动管理迭代过程和处理迭代器的状态。
增加方法
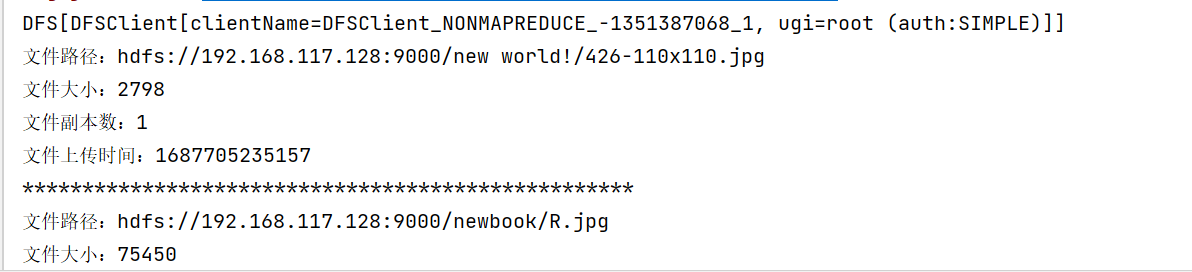
public static void findAlls(String filePath){
FileSystem fileSystem = HDFSUTILS.getFileSystem();
//海量数据用迭代器
try {
RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(new Path(filePath), true);
while(iterator.hasNext()){
LocatedFileStatus fs = iterator.next();
System.out.println("文件路径:"+fs.getPath());
System.out.println("文件大小:"+fs.getLen());
System.out.println("文件副本数:"+fs.getReplication());
System.out.println("文件上传时间:"+fs.getModificationTime());
System.out.println("***************************************************");
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
结果
上传文件
path1是源,path2是目的地址
//上传文件
public static void upload(String path1, String path2){
FileSystem fileSystem = HDFSUTILS.getFileSystem();
try {
fileSystem.copyFromLocalFile(new Path(path1), new Path(path2));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
调用测试
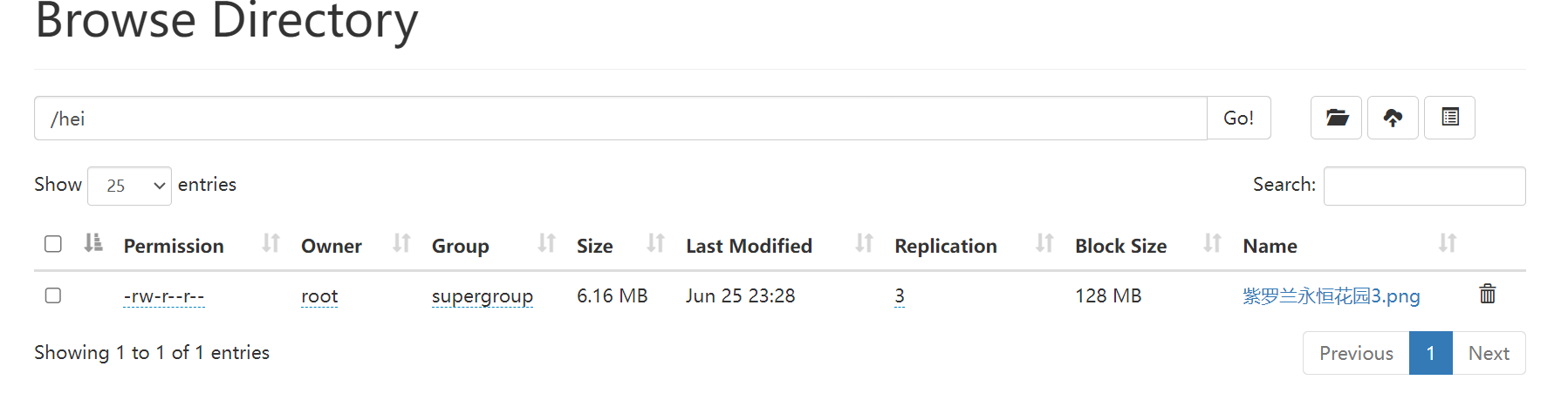
public static void main(String[] args) {
upload("C:\\Users\\32600\\Pictures\\紫罗兰永恒花园3.png", "/hei");
}
可以看到已经上传成功
文件下载
path1是源即HDFS,path2是目标路径
//下载文件
public static void download(String path1, String path2){
FileSystem fileSystem = HDFSUTILS.getFileSystem();
try {
fileSystem.copyToLocalFile(new Path(path1), new Path(path2));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
调用测试
public static void main(String[] args) {
download("/hei/R.jpg", "C:\\Users\\32600\\Desktop");
}
结果:

本文转载自: https://blog.csdn.net/m0_56369204/article/details/131379332
版权归原作者 ParadoxTuT 所有, 如有侵权,请联系我们删除。
版权归原作者 ParadoxTuT 所有, 如有侵权,请联系我们删除。