
开窗函数over(),over()里面一般可以配合分组,排序,窗口范围三个条件使用,也可以单独用一个条件,格式如over(partition by order by between ... and)
通过partition by 关键字来对窗口分组,特殊注意:通过order by 来对order by字段排序后的行进行开窗,窗口范围如果没有设置,则每一行对应整张表。窗口函数一般和分析函数连用。
1、over()窗口函数的语法结构
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
over()函数中包括三个函数:
order by是排序的意思
partition bypartition by可理解为group by 分组。over(partition by 列名)搭配分析函数时,分析函数按照每一组每一组的数据进行计算的。rows between 开始位置 and 结束位置是指定窗口范围,比如第一行到当前行。而这个范围是随着数据变化的。over(rows between 开始位置 and 结束位置)搭配分析函数时,分析函数按照这个范围进行计算的。
窗口范围说明:我们常使用的窗口范围是ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行),常用该窗口来计算累加。
窗口范围说明:我们常使用的窗口范围是ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行),常用该窗口来计算累加。
PRECEDING:往前
FOLLOWING:往后 CURRENT ROW:当前行 UNBOUNDED:起点(一般结合PRECEDING,FOLLOWING使用) UNBOUNDED PRECEDING 表示该窗口最前面的行(起点) UNBOUNDED FOLLOWING:表示该窗口最后面的行(终点)
比如说: ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行) ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING(表示往前2行到往后1行) ROWS BETWEEN 2 PRECEDING AND 1 CURRENT ROW(表示往前2行到当前行) ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING(表示当前行到终点)
2、示例
示例:现有一张表数据,三列,name,month,num
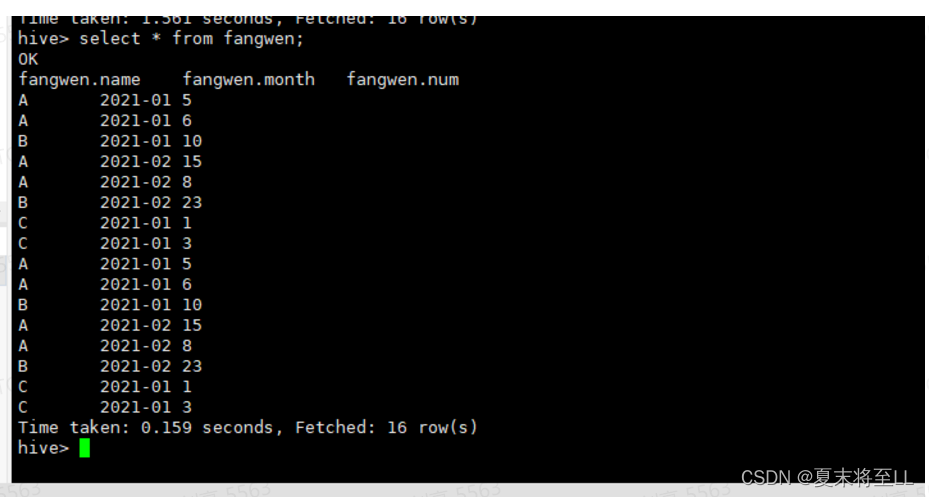
(1)使用开窗逐行累计求和(加不加排序不影响)
select * ,sum(num) over(ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) from fangwen;
select * ,sum(num) over( order by month ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) from fangwen;
 (2)分不同的name分组,逐行累计求和
(2)分不同的name分组,逐行累计求和
select * ,sum(num) over(partition by name ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) total from fangwen;
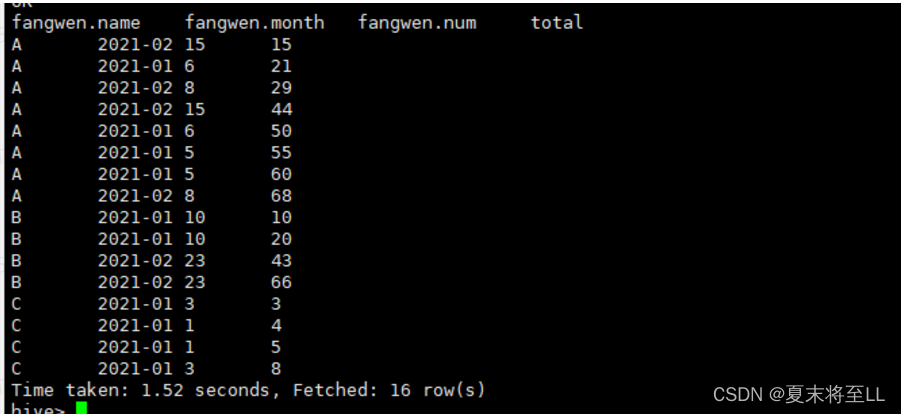
不同的组之间互不影响。
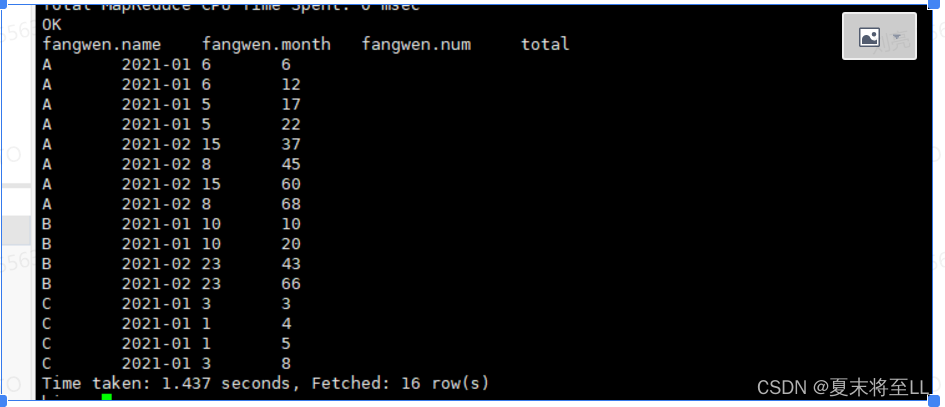
(3)分组排序逐行求和
select * ,sum(num) over(partition by name order by month ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) total from fangwen;
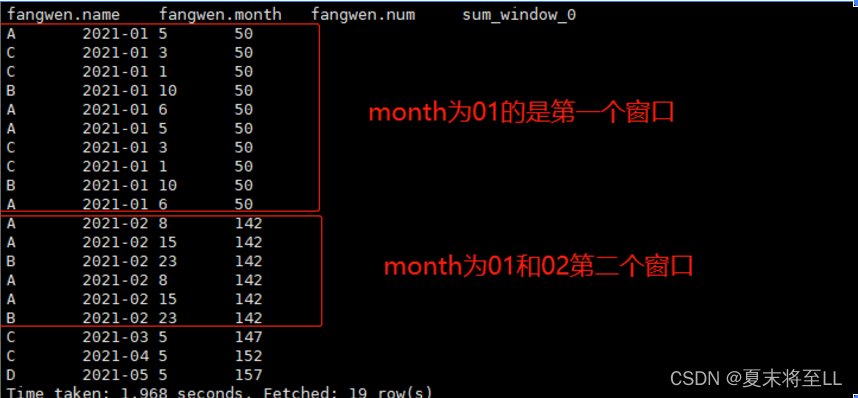
(4)只排序,不分组,不指定窗口范围,结果会把排序列同样的作为一个窗口,后续的列会把前面的当成窗口行。
select *,sum(num) over (order by month) from fangwen;
3、常与over()一起使用的分析函数:
(1)聚合类
avg()、sum()、max()、min()
(2)排名类
row_number()按照值排序时产生一个自增编号,不会重复(如:1、2、3、4、5、6)
rank() 按照值排序时产生一个自增编号,值相等时会重复,会产生空位(如:1、2、3、3、3、6)
dense_rank() 按照值排序时产生一个自增编号,值相等时会重复,不会产生空位(如:1、2、3、3、3、4)
(3)其他类
lag(列名,往前的行数,[行数为null时的默认值,不指定为null]),可以计算用户上次购买时间,或者用户下次购买时间。或者上次登录时间和下次登录时间
lead(列名,往后的行数,[行数为null时的默认值,不指定为null])
ntile(n) 把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,ntile返回此行所属的组的编号
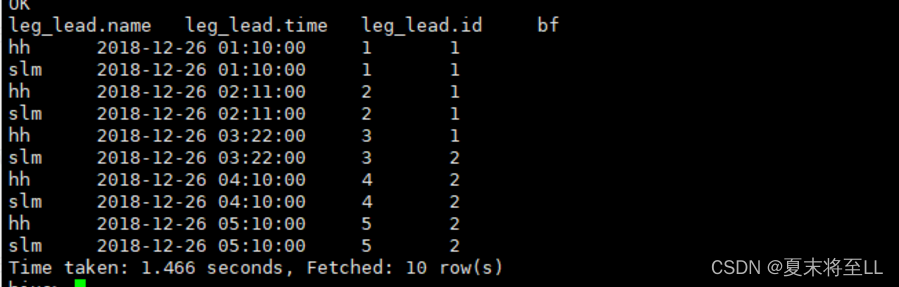
lag示例:

select * ,lag(time,1) over(partition by name order by time asc ) from leg_lead;
lead示例:
 select * ,lead(time,1) over(partition by name order by time asc ) from leg_lead;
select * ,lead(time,1) over(partition by name order by time asc ) from leg_lead;
ntile(n)一般用法按照排序之后把数据分成n组,好让你得到你要的组。
如下:
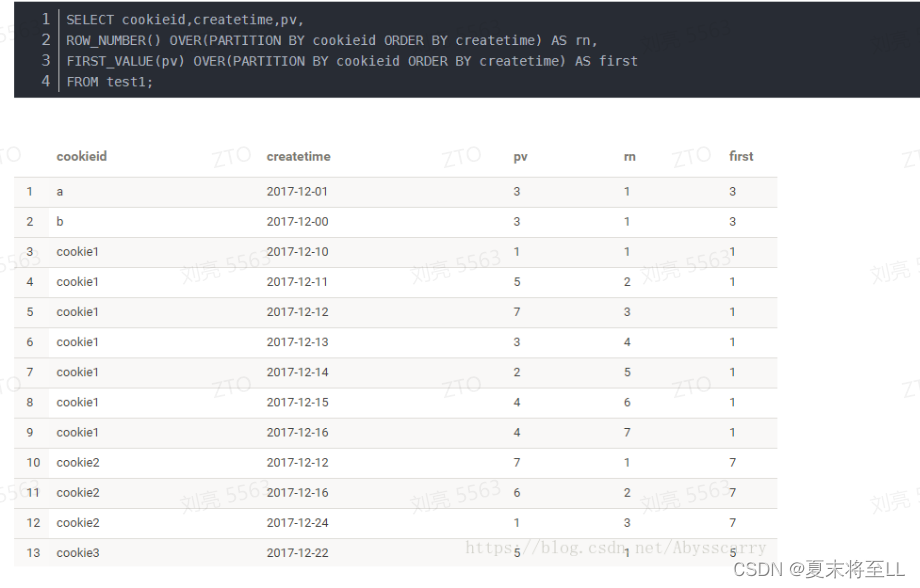
FIRST_VALUE 取分组内排序后,截止到当前行,第一个值
(4)开窗聚合函数和group by的共用
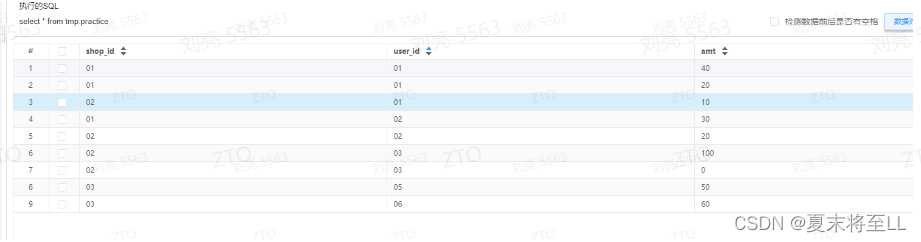
原始数据。
不带group by的开窗数据
select shop_id,user_id,count(1) over(partition by user_id) from tmp.practice;

带了group by的开窗数据
select shop_id,user_id,count(1) over(partition by user_id) from tmp.practice group by shop_id,user_id;
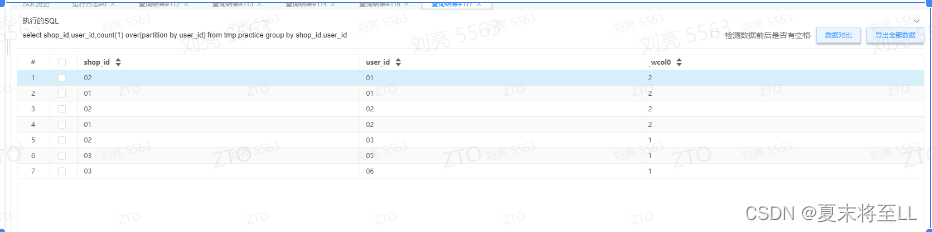
所以,看出带了group by之后,开窗函数的作用范围是,group by之后的数据了,不再是原始数据。
结论:group by和over()配合起来使用的数据生成的流程是,先通过group by进行分组聚合,over函数是作用在group by所生成的数据之上的。
版权归原作者 夏末将至LL 所有, 如有侵权,请联系我们删除。