
Python微信订餐小程序课程视频
https://edu.csdn.net/course/detail/36074
Python实战量化交易理财系统
https://edu.csdn.net/course/detail/35475**阅读目录**
- 什么是实体队列
- 如何使用实体队列提升吞吐
- 系列教程
NewLife.XCode是一个有15年历史的开源数据中间件,支持netcore/net45/net40,由新生命团队(2002~2020)开发完成并维护至今,以下简称XCode。
整个系列教程会大量结合示例代码和运行日志来进行深入分析,蕴含多年开发经验于其中,代表作有百亿级大数据实时计算项目。
开源地址:https://github.com/NewLifeX/X(求star, 1067+)
在大数据分析处理中,需要对海量数据进行添删改操作,常规单行操作难以满足要求,批量操作势在必行!
飞仙(http://feixian.newlifex.com/)有收藏各种数据库批量插入数据的性能排行榜,其中**MySql冠军是60万tps,SQLite冠军是56.6万tps**!
然而很多时候,数据来自多个渠道(多线程、多网络连接),单个渠道数据量不大,甚至只有一行,就难以使用批量添删改操作了。例如物联网数据采集、埋点日志等,在多线程上有大量数据需要写入。因此,XCode创造性设计了实体队列技术!
!!阅读本文之前,建议阅读:https://www.yuque.com/smartstone/xcode/batch
回到目录# 什么是实体队列
要说实体队列EntityDeferredQueue,就不得不提它的基类延迟队列DeferredQueue。
延迟队列DeferredQueue的核心思想就是“凑批”,把要处理的零散数据放入一个“队列”,然后定时集中处理。
例如物联网采集服务端从多个连接收到数据,需要写入数据库,为了提升吞吐,可以把实体数据放入延迟队列,然后定时的落库,此时,延迟队列得到一批数据,可以使用批量插入技术。
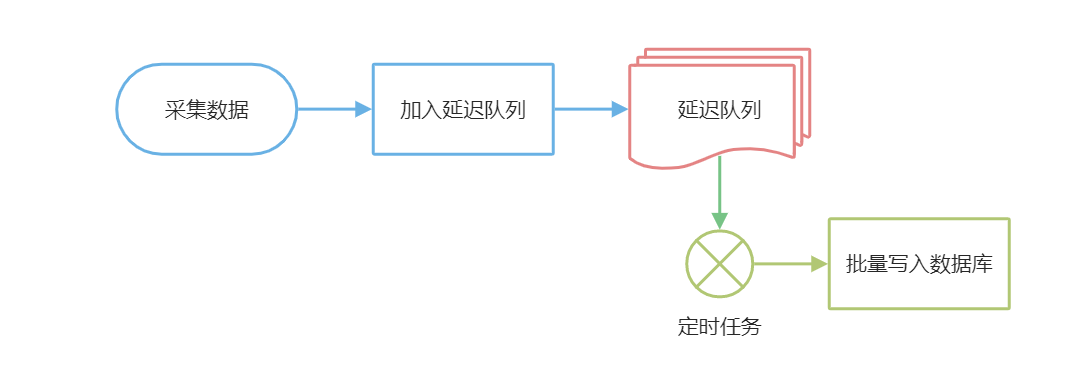
实际上DeferredQueue内部并不是一个队列,而是一个并发字典,因为有些业务场景,需要在“入队列”时去重,例如统计数据,需要拿出某省份的统计数据,多次累加后集中保存。
private static readonly DeferredQueue _statCache = new EntityDeferredQueue { Name = "Gun", Action = EntityActions.Save };
private static void SaveStat(DateTime date, Int32 provinceID, String kind, ScanKinds scanKind, String code)
{
var key = $"{date:yyMMdd}\_{provinceID}\_{kind}";
var stat = _statCache.GetOrAdd(key, k => GunProvinceStat.FindByKey(k, true) ?? new GunProvinceStat());
stat.StatDate = date;
stat.Kind = kind;
stat.ProvinceID = provinceID;
stat.LastCode = code;
stat.ProcessStat(scanKind);
_statCache.Commit(key);
}
主要流程
对于统计型数据来说,可以在内存里面多次累加计算指标,然后一次性保存,并且是批量保存,极大减少了数据库写入次数。这是大数据分析必备利器!
延迟队列主要属性
/// 跟踪数。达到该值时输出跟踪日志,默认1000
public Int32 TraceCount { get; set; } = 1000;
/// 周期。默认10\_000毫秒
public Int32 Period { get; set; } = 10_000;
/// 最大个数。超过该个数时,进入队列将产生堵塞。默认100\_000
public Int32 MaxEntity { get; set; } = 100_000;
/// 批大小。默认5\_000
public Int32 BatchSize { get; set; } = 5_000;
/// 等待借出对象确认修改的时间,默认3000ms
public Int32 WaitForBusy { get; set; } = 3_000;
/// 保存速度,每秒保存多少个实体
public Int32 Speed { get; private set; }
/// 是否异步处理。默认true表示异步处理,共用DQ定时调度;false表示同步处理,独立线程
public Boolean Async { get; set; } = true;
回过头来,实体队列EntityDeferredQueue作为延迟队列的扩展延伸,实际上是定义了“队列数据”的处理行为。延迟队列只负责收集数据和定时调度,实际处理行为Process需要扩展。
EntityDeferredQueue定义了 Save/Insert/Update/Upsert/Delete 等行为供选择。
回到目录# 如何使用实体队列提升吞吐
再次深入分析前文的例子
private static readonly DeferredQueue _statCache = new EntityDeferredQueue { Name = "Gun", Action = EntityActions.Save };
private static void SaveStat(DateTime date, Int32 provinceID, String kind, ScanKinds scanKind, String code)
{
var key = $"{date:yyMMdd}\_{provinceID}\_{kind}";
var stat = _statCache.GetOrAdd(key, k => GunProvinceStat.FindByKey(k, true) ?? new GunProvinceStat());
stat.StatDate = date;
stat.Kind = kind;
stat.ProvinceID = provinceID;
stat.LastCode = code;
stat.ProcessStat(scanKind);
_statCache.Commit(key);
}
这是一个非常简单的数据分析项目,统计每天各省每一种扫描类型的操作次数。日均分析处理5亿行数据,每一行数据都要识别出日期、省份、类别等字段,也就是SaveStat每天要调用5亿次,结果数据分类存入统计表。共31省份27种类别,每日统计行数约800行(并非每个省都有全部类别)。通俗来讲,5亿行数据,分组聚合得到800行,实时计算,每5秒计算一次。
采用流式计算框架,逐行遍历5亿行实时数据,如果Insert/Update数据库5亿次,显然很不现实!
平均每行写入62.5万次(5亿/800),如果能够在内存里面“凑一凑”,每1000次更新,才写入一次数据库,那么总写入次数降低为50万次,平均每行写入625次。
实体队列/延迟队列,正是为了这类场景而设计!
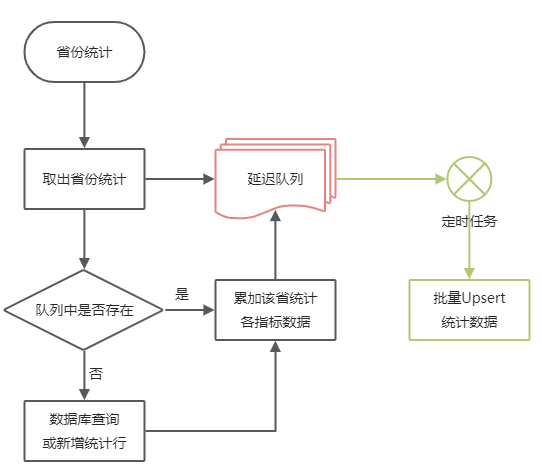
首先,根据业务去构造一个唯一key,在这里就是日期+省份+类别;
其次,GetOrAdd尝试从队列里获取该key对应的统计对象,99%时候内存命中,如果不存在,则查数据库或者new一个;
再次,取得统计对象后,可以进行字段累加,stat.ProcessStat(scanKind);
最后,Commit告诉队列,该key对应的实体对象已经使用完成,可以提交;
在延迟队列内部,定时(Period=10_000ms)执行一次保存,把内存里面的统计对象批量保存到数据库,并清空队列。
这里遇到的第一个问题就是,少量统计对象仍然使用怎么办?请放心,定时任务会等待一定时间(WaitForBusy=3000ms),如果使用方Commit则提前完成。因此,上面的Commit可以不要,效果会变差一些,同时,统计逻辑必须尽快完成(<3000ms)。
第二个问题很重要,定时间隔(Period=10_000ms)之内,内存数据是高危状态,如果此时进程退出,则意味着统计数据丢失。标准架构应该是在数据落库以后做Ack确认,但是原始数据实在太多(5亿),很不现实。因此,实际工作中,我们是通过提升系统可靠性来规避该问题,采用蚂蚁调度AntJob,结合分布式多节点部署,在实时计算中,内存保留数据并不多。每次需要更新程序时,先停止调度一分钟,等待数据落库和冷却,才能推出应用进程。在数据分析领域,一般允许有一定的数据误差(<0.01%),或者白天实时计算加夜晚离线重算的模式!
实际经验表明,只要应用没有非法退出,不存在数据丢失问题!
再来看看 ProcessStat内部,(这里的GunProvinceStat是XCode实体类,一张统计表)
public void ProcessStat(ScanKinds kind)
{
//stat.Total++;
Interlocked.Increment(ref _Total);
switch (kind)
{
case ScanKinds.Receipt:
//stat.Receipts++;
Interlocked.Increment(ref _Receipts);
break;
case ScanKinds.SendBill:
case ScanKinds.SendAir:
//stat.Sends++;
Interlocked.Increment(ref _Sends);
break;
case ScanKinds.SendBag:
Interlocked.Increment(ref _SendBags);
break;
case ScanKinds.ComeBill:
case ScanKinds.ComeAir:
//stat.Comes++;
Interlocked.Increment(ref _Comes);
break;
case ScanKinds.ComeBag:
Interlocked.Increment(ref _ComeBags);
break;
case ScanKinds.SendCar:
case ScanKinds.ComeCar:
Interlocked.Increment(ref _Cars);
break;
case ScanKinds.Dispatch:
//stat.Dispatchs++;
Interlocked.Increment(ref _Dispatchs);
break;
case ScanKinds.Sign:
//stat.Signs++;
Interlocked.Increment(ref _Signs);
break;
case ScanKinds.Back:
Interlocked.Increment(ref _Backs);
break;
case ScanKinds.Problem:
Interlocked.Increment(ref _Problems);
break;
case ScanKinds.Stay:
case ScanKinds.Other:
case ScanKinds.Input:
case ScanKinds.Order:
case ScanKinds.Electronic:
default:
Interlocked.Increment(ref _Others);
break;
}
}
数据表结构
<Table Name="GunProvinceStat" Description="巴枪省份统计" IgnoreNameCase="False">
<Columns>
<Column Name="ID" DataType="Int32" Identity="True" PrimaryKey="True" Description="编号" />
<Column Name="StatDate" DataType="DateTime" Description="统计日期" />
<Column Name="ProvinceID" DataType="Int32" Description="省份。0表示全国" />
<Column Name="Kind" DataType="String" Description="类别。All表示所有类型" />
<Column Name="Total" DataType="Int64" Description="总次数" />
<Column Name="Receipts" DataType="Int64" Description="收件数" />
<Column Name="Sends" DataType="Int64" Description="发件数" />
<Column Name="Comes" DataType="Int64" Description="到件数" />
<Column Name="Dispatchs" DataType="Int64" Description="派件数" />
<Column Name="Signs" DataType="Int64" Description="签收数" />
<Column Name="SendBags" DataType="Int64" Description="发包数" />
<Column Name="ComeBags" DataType="Int64" Description="到包数" />
<Column Name="Cars" DataType="Int64" Description="扫车数" />
<Column Name="Backs" DataType="Int64" Description="退件数" />
<Column Name="Problems" DataType="Int64" Description="问题件数" />
<Column Name="Others" DataType="Int64" Description="其它数" />
<Column Name="LastCode" DataType="String" Description="最后单号" />
<Column Name="CreateTime" DataType="DateTime" Description="创建时间" />
<Column Name="UpdateTime" DataType="DateTime" Description="更新时间" />
Columns>
<Indexes>
<Index Columns="StatDate,ProvinceID,Kind" Unique="True" />
<Index Columns="Kind,ProvinceID" />
Indexes>
Table>
回到目录# 系列教程
NewLife.XCode教程系列[2019版]
- 增删改查入门。快速展现用法,代码配置连接字符串
- 数据模型文件。建立表格字段和索引,名字以及数据类型规范,推荐字段(时间,用户,IP)
- 实体类详解。数据类业务类,泛型基类,接口
- 功能设置。连接字符串,调试开关,SQL日志,慢日志,参数化,执行超时。代码与配置文件设置,连接字符串局部设置
- 反向工程。自动建立数据库数据表
- 数据初始化。InitData写入初始化数据
- 高级增删改。重载拦截,自增字段,Valid验证,实体模型(时间,用户,IP)
- 脏数据。如何产生,怎么利用
- 增量累加。高并发统计
- 事务处理。单表和多表,不同连接,多种写法
- 扩展属性。多表关联,Map映射
- 高级查询。复杂条件,分页,自定义扩展FieldItem,查总记录数,查汇总统计
- 数据层缓存。Sql缓存,更新机制
- 实体缓存。全表整理缓存,更新机制
- 对象缓存。字典缓存,适用用户等数据较多场景。
- 百亿级性能。字段精炼,索引完备,合理查询,充分利用缓存
- 实体工厂。元数据,通用处理程序
- 角色权限。Membership
- 导入导出。Xml,Json,二进制,网络或文件
- 分表分库。常见拆分逻辑
- 高级统计。聚合统计,分组统计
- 批量写入。批量插入,批量Upsert,异步保存
- 实体队列。写入级缓存,提升性能。
- 备份同步。备份数据,恢复数据,同步数据
- 数据服务。提供RPC接口服务,远程执行查询,例如SQLite网络版
- 大数据分析。ETL抽取,调度计算处理,结果持久化
如果您觉得阅读本文对您有帮助,请点一下“**推荐**”按钮,您的**“推荐”**将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后**必须在文章页面明显位置给出作者和原文连接**,否则保留追究法律责任的权利。
版权归原作者 [虚幻私塾】 所有, 如有侵权,请联系我们删除。