
一、Ubuntu20.04配置深度学习环境
1.首先给Ubuntu安装Chrome浏览器(搜索引擎换成百度即可)
安装命令:打开终端直接输入
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo dpkg -i google-chrome-stable_current_amd64.deb
sudo apt-get -f install
2.换成搜狗输入法(如果安装完成无法打汉字,可输入以下命令)
sudo apt-get update
sudo apt install libqt5qml5 libqt5quick5 libqt5quickwidgets5 qml-module-qtquick2
sudo apt install libgsettings-qt1
3.安装WPS for Linux
进入搜狗for linux官网下载搜狗输入法 ,下载x86版本
WPS for linux
4. 安装其它之前需要先安装anaconda
先去官网下载好anaconda后面是.sh文件
输入命令(命令上对应你自己下载的版本号):
sh Anaconda3-2021.11-Linux-x86_64.sh
后面根据提示进行操作即可
- 新打开一个终端可以看到前面带一个base,说明安装成功
5. ubuntu换国内镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
6.安装配置anaconda
anaconda添加国内镜像源
#添加镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
#显示检索路径
conda config --set show_channel_urls yes
#显示镜像通道
conda config --show channels###### 安装完成anaconda后创建一个虚拟环境
conda create -n yolo python=3.7
yolo是你虚拟环境名字,可自己取,Python不要安装太高版本3.7即可
查看自己的虚拟环境
conda env list
激活虚拟环境
conda activate yolo
接下来需要在虚拟环境里面安装pytorch
二、安装pytorch前首先安装显卡驱动
输入
nvidia-smi
提示Command 'nvidia-smi' not found, but can be installed with:说明你还没有安装显卡驱动
2.安装显卡驱动最简单方式:
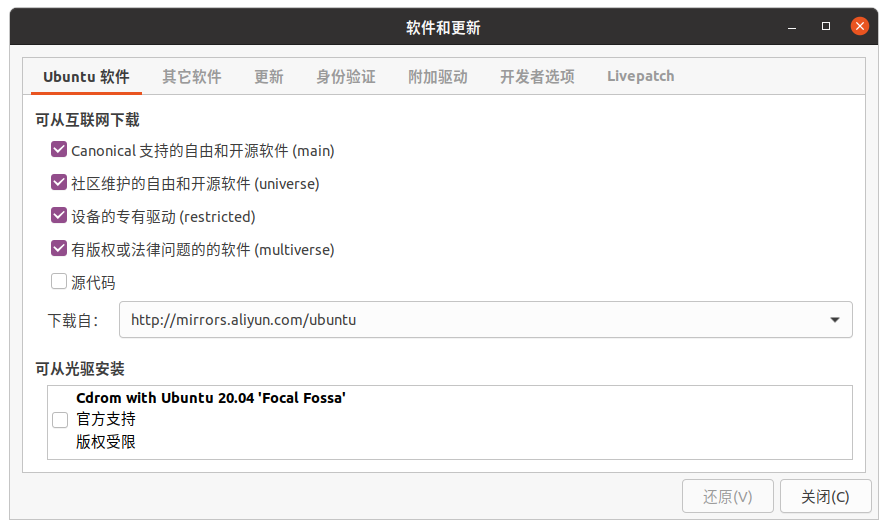
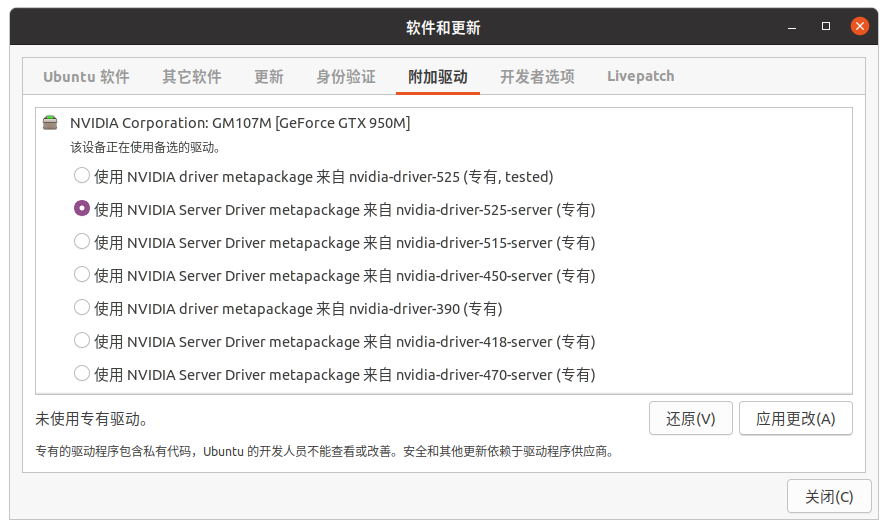
打开软件和更新
ununtu软件-下载自-安装源改成国内,然后左面有一个附加驱动里面有许多专有的驱动程序,点击一个专有的,接着点击应用更改
3.这时如果弹出更新应用时出错
解决方法:打开软件更新器更新一下
完成后重启在输入nvidia-smi就可以看到电脑可以安装cuda的最高版本号
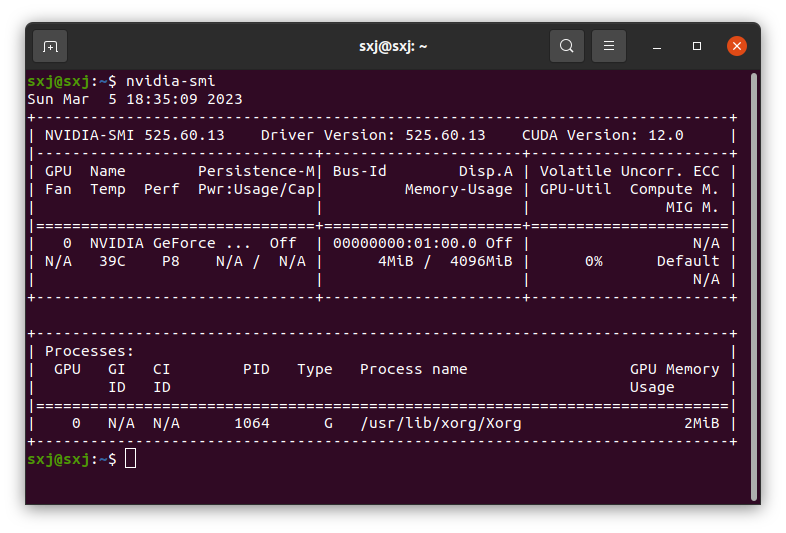
(图上看到可以安装的cuda最高版本号为12.0)
三、安装配置pytorch
1.首先查看查看显卡使用情况
打开终端输入:
nvidia-smi
查看可以安装cuda的版本(低于这个或等于这个版本都可以安装,高于11.3版本,建议安装11.3的)
2.进入自己创建的虚拟环境把pytorch安装在自己的虚拟环境里面
(可以在torch官网Previous PyTorch Versions | PyTorch上复制安装命令)
打开终端输入:两个不同版本看你选择(Python需要3.7版本装的cuda才是10.2)
这个是cuda11.3版本的torch
国内镜像源经常用放在这里
-i https://pypi.tuna.tsinghua.edu.cn/simple
下载错了删除虚拟环境的命令
# 第一步:首先退出环境
conda deactivate
# 第二步:删除环境
conda remove -n yolo --all
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorch
这个是cuda10.2版本的
conda install pytorch==1.8.1 torchvision==0.9.1 torchaudio==0.8.1 cudatoolkit=10.2 -c pytorch
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
下面复现VIT-SAM使用的版本
python3.8+pytorch2.0****+****torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.8
1. 新建虚拟环境python3.8
conda create -n yolo python=3.8
- 安装pytorch2.0.0
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
- 安装cuda11.8+cudnn(参考文章Ubuntu16.04下安装cuda和cudnn的三种方法)
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.run
gedit ~/.bashrc
在bashrc里面添加如下代码
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.8/lib64
export PATH=$PATH:/usr/local/cuda-11.8/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.8
source ~/.bashrc
nvcc -V #查看cuda是否安装完成
出现如下cuda11.8的版本好说明安装完成
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
安装cudnn官网(参考文章Ubuntu安装cuda与cudnn,亲测可用)
参考(文章cudnn升级方法,解决CuDNN版本不兼容问题)
主要之前安装测试完成之后在autokeras环境中遇到了这种问题:
Loaded runtime CuDNN library: 8.2.1 but source was compiled with: 8.6.0. CuDNN library needs to have matching major version
现在写一些安装cudnn的流程:
- 如果你下载的cudnn是tar.xz结尾的用解压:
tar xvJf data.tar.xz
cudnn是.tgz结尾的用解压:
tar -zxvf cudnn-11.3-linux-x64-v8.2.1.32.tgz
cudnn是.deb结尾的用解压:
sudo dpkg -i
- 删除旧版本
sudo rm -rf /usr/local/cuda/include/cudnn.h
sudo rm -rf /usr/local/cuda/lib64/libcudnn*
- 安装新版本
cd进入刚才解压的cuda文件夹
sudo cp include/cudnn.h /usr/local/cuda/include/
sudo cp lib64/lib* /usr/local/cuda/lib64/
- 建立软连接(其中so.8.2.1和so.8是你下载的cudnn版本)
cd /usr/local/cuda/lib64/
sudo chmod +r libcudnn.so.8.2.1
sudo ln -sf libcudnn.so.8.2.1 libcudnn.so.8
sudo ln -sf libcudnn.so.8 libcudnn.so
sudo ldconfig
- 测试验证:
查看cudnn的版本
首先使用以下指令查看现有cudnn的版本
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 2
#define CUDNN_PATCHLEVEL 1
--
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#include "driver_types.h"
报错解决:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2 没有显示
2.解决方法:
原因:可能是最新版本的cudnn把文件放入的cudann_version.h中而没有在原来的cudnn.h中 所以要换一个文件复制, 具体操作如下;
执行下面代码
sudo cp cuda/include/cudnn_version.h /usr/local/cuda/include/
查看是否安装成功:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
找到
下载这三个
cuDNN Runtime Library for Ubuntu20.04 x86_64 (Deb)
cuDNN Developer Library for Ubuntu20.04 x86_64 (Deb)
cuDNN Code Samples and User Guide for Ubuntu20.04 x86_64 (Deb)
用sudo dpkg -i直接解压即可
用以下代码进行测试:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def main():
cudnn.benchmark = True
torch.manual_seed(1)
device = torch.device("cuda")
kwargs = {'num_workers': 1, 'pin_memory': True}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=64, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
for epoch in range(1, 11):
train(model, device, train_loader, optimizer, epoch)
if __name__ == '__main__':
main()
如果正常输出一下以下信息,证明已经安装成了:
Train Epoch: 1 [0/60000 (0%)] Loss: 2.365850
Train Epoch: 1 [640/60000 (1%)] Loss: 2.305295
Train Epoch: 1 [1280/60000 (2%)] Loss: 2.301407
Train Epoch: 1 [1920/60000 (3%)] Loss: 2.316538
Train Epoch: 1 [2560/60000 (4%)] Loss: 2.255809
Train Epoch: 1 [3200/60000 (5%)] Loss: 2.224511
Train Epoch: 1 [3840/60000 (6%)] Loss: 2.216569
Train Epoch: 1 [4480/60000 (7%)] Loss: 2.181396
ubuntu20.4+cuda11.8+python3.8对应的tensorrt(参考文章TensorRT安装及使用教程)
(TensorRT安装亲测这个可以我的cudnn是8.2也可以对应cuda11.8就没改)
因为TensorRT不同的版本依赖于不同的cuda版本和cudnn版本。所以很多时候我们都是根据我们自己电脑的cuda版本和cudnn版本来决定要下载哪个TensorRT版本。
cuda版本
nvcc -V
在我的系统里,cudnn文件存在于/usr/include/文件夹下。cd进入/usr/include/文件夹,查看cudnn的版本:
cd /usr/include/
cat cudnn_version.h
- 首先下载TensorRT编译YOLOv5的代码
tensorrt官网(点进去选择你对应的版本)
- 模型转换
在tensorrtx/yolov5文件夹中可找到gen_wts.py,该脚本可将Pytorch模型(.pt格式)转换成权重文本文件(.wts格式)。将gen_wts.py拷贝到{ultralytics}/yolov5文件夹中,并在此文件夹中打开终端,输入(其中best.pt 是你训练好的权重文件)
python gen_wts.py -w best.pt -o best.wts
这样就在{ultralytics}/yolov5文件夹中生成了best.wts文件。
- 修改yololayer.h参数
打开tensorrtx\yolov5文件夹,找到yololayer.h文件,修改CLASS_NUM,使与pytorch模型一致:
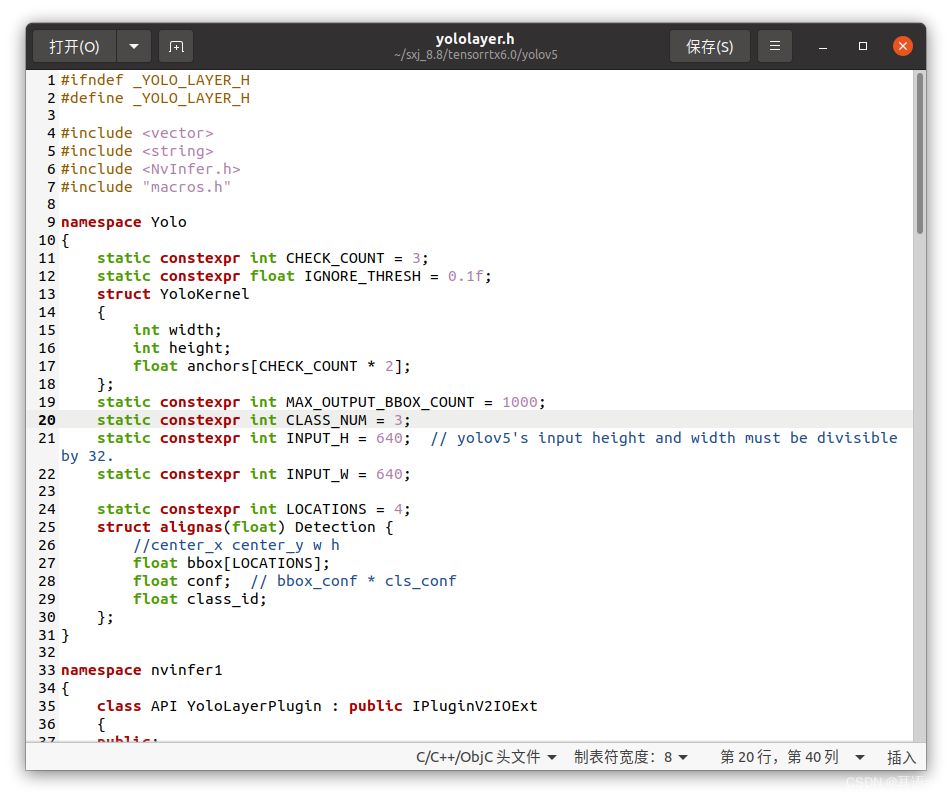
- 编译并生成引擎文件
终端依次输入下列指令,在tensortrtx/yolov5目录下新建build文件夹
mkdir build
将生成的best.wts拷贝到build文件夹下,输入下列指令对其进行编译
cmake ..
make
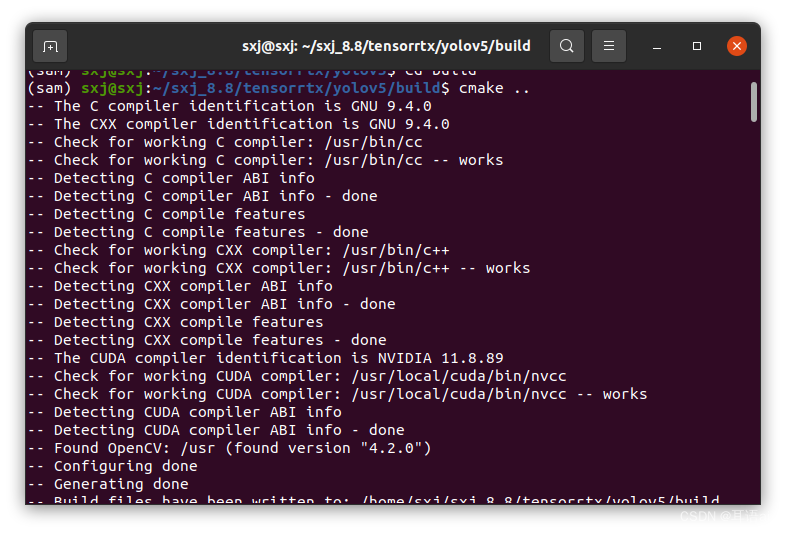
再输入下列指令,可使best.wts生成best.engine,注意末尾的n代表模型尺度,可选项有n/s/m/l/x/n6/s6/m6/l6/x6 or c/c6 gd gw,必须与pytorch模型一致:
sudo ./yolov5 -s best.wts best.engine s
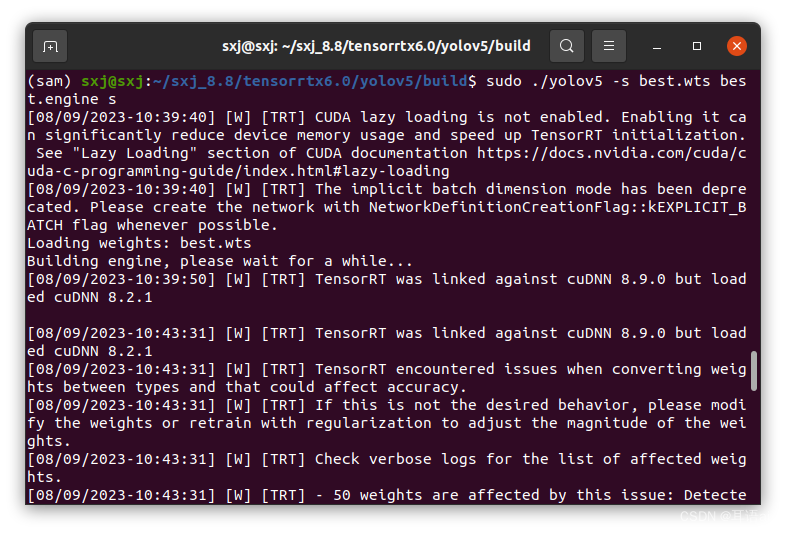
- 进行检测
输入下列指令,可对指定路径下的图片进行检测,这里的图片路径是…/samples:
sudo ./yolov5 -d best.engine ../samples
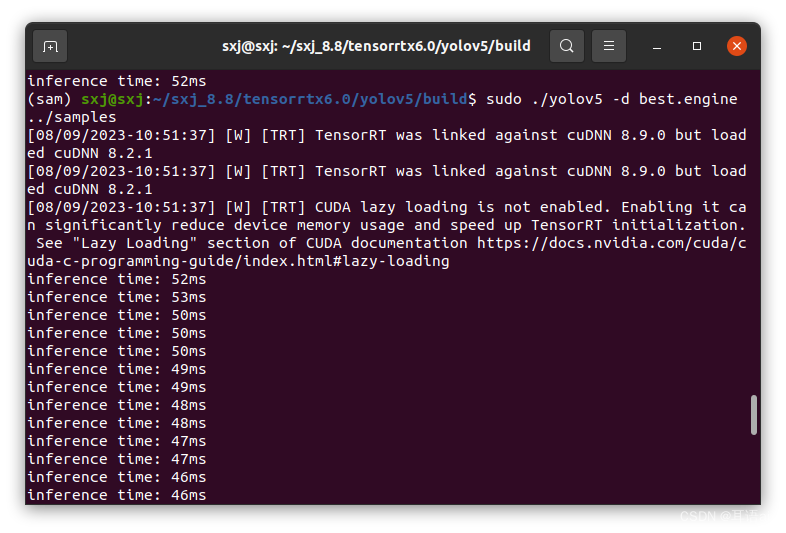
可以和之前没有使用tensorrt时使用的Pytorch模型检测所耗时间进行对比,TensorRT加速后单幅图片耗时明显缩短
看到这里就可以了,后面的文字是之前写的没有删
参考文章:【Jetson平台 ubuntu 18.04 使用 TensorRT 加速 YOLOv5 检测】
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
安装命令复制过来进行安装(不要把安装命令后面的-c pytorch -c conda-forge去掉,否则你安装的将是cpu版的,无法调用gpu)
pytorch要选1.10以后的不然还是CPU版本的,具体原因看:
解决cpu版本解决torch是cpu版本的问题
输入:nvidia-smi
如果报错:Module nvidia/470.182.03 already installed on kernel 5.15.0-69-generic/x86_6
说明自己装的驱动和电脑内核驱动不一致(还没有更新)重启一下电脑即可
还不行进入BIOS把找到驱动后面的Secure Boot改为Disabled
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver.
Make sure that the latest NVIDIA driver is installed and running.
解决方法:
安装dkms:
sudo apt-get install dkms
查看本机连接不上的驱动版本:
ls -l /usr/src/
使用dkms重新安装适合驱动:
sudo dkms install -m nvidia -v 470.103.01
完成重启即可测试:
nvidia-smi
import torch
print(torch.cuda.is_available())
输出true即可
3. 配置完成测试,终端打开输入:
Python
import torch # 如果pytorch安装成功即可导入
print(torch.cuda.is_available()) # 查看CUDA是否可用,输出true代表可以调用GPU
print(torch.cuda.device_count()) # 查看可用的CUDA数量
print(torch.version.cuda) # 查看CUDA的版本号
4.用conda list查看pytorch和cuda、cudnn的版本
如果发现安装成CPU版本,用以下命令卸载在重新安装:
conda uninstall pytorch
conda uninstall libtorch
有问题看以下链接
解决cpu版本解决torch是cpu版本的问题
yolov5跑模型时报错:
RuntimeError: result type Float can't be cast to the desired output type long int
解决方法:
1.打开你的【utils】文件下的【loss.py】
2.按【Ctrl】+【F】打开搜索功能,输入【for i in range(self.nl)】找到下面的一行内容:
(上面的代码在【loss.py】的后半部分)
将下面代码替换掉这一行的红色字:anchors = self.anchors[i]
anchors, shape = self.anchors[i], p[i].shape
3.按【Ctrl】+【F】打开搜索功能,输入【indices.append】找到下面的一行内容:
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
(上面的代码在【loss.py】的最后部分,具体位置在上一处搜索位置的下面几行)
将下面的代码替换掉上图中的红字部分:
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
参考:yolov5部署之环境配置及源码测试_yolov5环境测试_Christo3的博客-CSDN博客
四、ubuntu20.04下载安装tensorrt
4.1 环境
CUDA 11.1 (11.2、11.3)
CUDNN 8.1
4.2 下载tensorRT (匹配相应的版本)
官网地址 :Log in | NVIDIA Developer
下载的时tar包
安装
解压
tar zxf TensorRT-8.0.1.6.Linux.x86_64-gnu.cuda-11.3.cudnn8.2.tar.gz
存放在自己想放的目录下(也可以重命名),如:
mv TensorRT-8.0.1.6 /opt
4.3 添加环境
将下面的环境变量 添加到.bashrc文件并保存:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/TensorRT-8.0.1.6/lib
激活环境:
source ~/.bashrc
复制tensorRT目录下 lib、include文件夹到系统文件夹(或者将这两个文件夹路径添加到.bashrc文件中)
sudo cp -r ./lib/* /usr/lib
sudo cp -r ./include/* /usr/include
4.4 C++测试是否成功
测试代码:TensorRT-8.0.1.6/samples/sampleMNIST
本版本无需去data文件夹下载对应的数据集,自己带了,如果没有,那就下载对应的数据集
4.5 python download_pgms.py
如果文件夹下有pgm格式的图片 说明下载成功
在tensorRT目录下samples文件夹下 用sampleMNIST示例测试
编译:
make
清除之前编译的可执行文件及配置文件:
make clean
编译成功,执行bin目录下的可执行文件
./../../bin/sample_mnist
参考文章:Ubuntu20.04 安装tensorRT_tensorrt安装 ubuntu_墨文昱的博客-CSDN博客
需要对yolov5中的权重模型.pt转换成onnx的,请点击以下链接:
yolo的模型转换权重pt文件转onnx(1)
yolo的模型转换权重pt文件转onnx(1)_yolov5 pt转onnx_耳语ai的博客-CSDN博客
参考文章:
检查pytorch是否安装成功、查看torch和cuda的版本
超详细 Ubuntu安装PyTorch步骤
ubuntu18.04安装显卡驱动(四种方式)
Ubuntu20.04 安装tensorRT
参考链接:yolov5部署之环境配置及源码测试_yolov5环境测试_Christo3的博客-CSDN博客
版权归原作者 耳语ai 所有, 如有侵权,请联系我们删除。