
第一章、安装Spring Data JPA
第一步,先确保你使用的是Spring Boot 3.0或以上环境,可以在pom.xml里加入Spring Data JPA依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>
第二步,配置你的Spring Data JPA,这里一定要有一个可以连接的数据库,这里以MySQL为例
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driver
url:"jdbc:mysql://127.0.0.1:3306/数据库名?useUnicode=true&characterEncoding=utf8&reWriteBatchedInserts=true&autoReconnect=true&maxReconnects=2&initialTimeout=5"username: 用户名
password: 密码
jpa:database: MySQL
show-sql:truegenerate-ddl:truehibernate:ddl-auto: none
至此安装完成
第二章、常规用法
首先我们要知道Spring Data JPA的作用,Spring Data JPA是一种基于JPA技术的ORM框架封装,相当于把EclipseLink或Hibernate加了一层壳,所以本质上你调用的还是Hibernate。
根据JPA的规范,我们要进行读写数据库,靠的是对实体(Entity)的定义,每一个实体都对应了一张表,这一点上并不是JPA的独创,大多数ORM框架都是这么做的,这么想就很容易理解了。
在进行实体操作的时候,传统方式是通过DAO(数据访问对象)进行操作,但到了JPA,你其实不必定义DAO,使用实体管理器即可进行实体操作和查询,用于取代DAO的则是Repository(仓库)。
第一步,我们定义一个实体,为了省略Getter和Setter方法,这里使用了Lombok的@Data注解:
importjakarta.persistence.*;importlombok.Data;@Entity@Table(name ="student")@DatapublicclassStudent{@Id@Column(name ="uuid")@GeneratedValue(strategy =GenerationType.UUID)privateString uuid;@Column(name ="name")privateString name;@Column(name ="age")privateInteger age;}
这里需要注意的是,对于日期类的字段,请加上
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
注解,否则很多情况下你的时间格式是不统一的,这里的GMT+8指的就是东八区时区,如果你做外贸系统,需要根据实际情况调整。
第二步,写Repository,泛型第一个是实体类,第二个是主键类型,这里主键用的是UUID,所以是String
importorg.springframework.data.repository.CrudRepository;importorg.springframework.stereotype.Repository;@RepositorypublicinterfaceStudentRepositoryextendsCrudRepository<Student,String>{StudentgetStudentByUuid(String uuid);}
这里不用给出任何具体实现,因为实现都是由Spring Data JPA自动为你写好的,只需要按规则把方法名写好即可,一般都是用find、get、delete开头,IDE会自动帮你提示出方法名。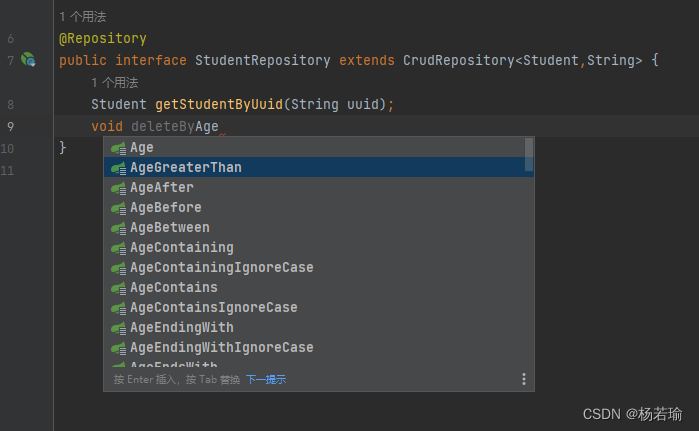
这里你可以让接口继承
Repository
、
CrudRepository
或
JpaRepository
无论是你想控制边界避免程序员随意调用未经许可的接口方法,还是想手动优化,让所有的方法都要自己定义,请使用Repository。
如果你想做一些简单的增删改查,请使用CrudRepository。
如果想要分页、多条件查询等常规功能,请使用JpaRepository。
其中JpaRepository是功能最为强大的,但也同时是可优化程度最低的,适用于小型项目。
第三步,注入到Controller或者Service层里,调用即可
importjakarta.annotation.Resource;importorg.springframework.transaction.annotation.Transactional;importorg.springframework.web.bind.annotation.GetMapping;importorg.springframework.web.bind.annotation.RequestMapping;importorg.springframework.web.bind.annotation.RestController;@RestController@RequestMapping("/api/student")@Transactional(rollbackFor =Exception.class)publicclassStudentController{@ResourceStudentRepository studentRepository;@GetMapping("/get")publicStudentget(String uuid){return studentRepository.getStudentByUuid(uuid);}}
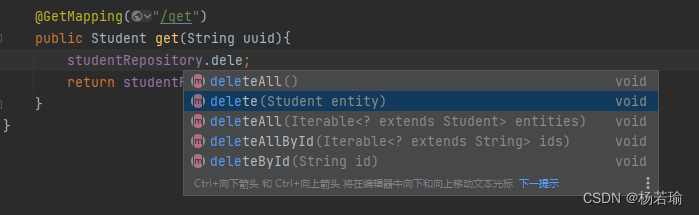
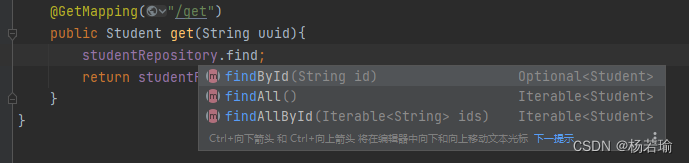
至于常规的增删改查直接就自带了,直接用即可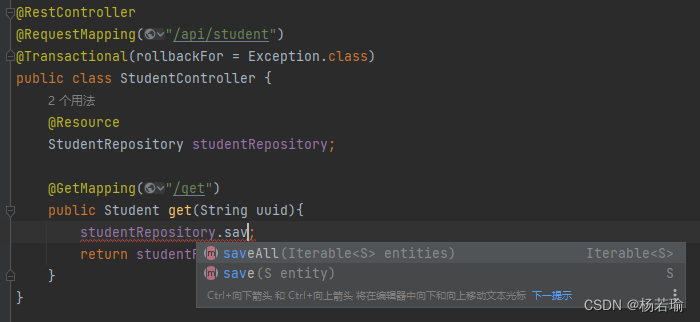
第三章、进阶用法
如果你实际做项目,并不是只需要这点增删改查就可以的,做做毕业设计也就罢了。我们需要的是对SQL语句的整体把控,能够进行手动优化,甚至封装框架。
在Repository中自定义JPQL或SQL查询
是不是做项目的时候发现Repository方法名写的太长了,可读性非常差呢?这里我们可以在方法上加上@Query注解,例如:
importorg.springframework.data.repository.CrudRepository;importorg.springframework.stereotype.Repository;@RepositorypublicinterfaceMaterialRepositoryextendsCrudRepository<Material,String>{@Query(value ="select * from material where enabled = ?1",nativeQuery =true)List<Material>queryValidMaterial(Boolean enabled);}
这里的nativeQuery如果是true,用的是SQL查询,如果是false,用的就是JPQL查询。而enabled就是咱们自己定义的参数,Material是实际业务系统中物料表的表名。
而value中所写的?1代表第一个参数,以此列推?2就代表第二个参数,如果你觉得这么写在长语句中不太直观,那也可以将占位符改为
:enabled
这样的形式,比如:
@Query(value ="select * from material where enabled = :enabled",nativeQuery =true)List<Material>queryValidMaterial(@Param("enabled")Boolean enabled);
使用EntityManager直接进行查询
EntityManager是JPA中的实体管理器,它的实例是与线程相关的,所以可以很方便的在Spring管理的任何地方进行查询。简单的来说,我们可以用EntityManager来替代Repository,这对于要自己封装框架的读者们会非常友好。
下面这个例子就是使用EntityManager进行SQL查询并返回结果的例子:
@RestController@RequestMapping("/api/material")@Transactional(rollbackFor =Exception.class)publicclassMaterialController{@PersistenceContextEntityManager entityManager;@GetMapping("/get")publicMaterialget(String uuid){// 创建SQL查询,第一个参数是SQL,第二个参数是要自动ORM的实体Query query = entityManager
.createNativeQuery("""
SELECT * FROM material
WHERE uuid = :uuid
""",Material.class);// 设置预编译参数,如果是?1、?2或者直接?做占位符的,第一个参数应当为从1开始的数字
query.setParameter("uuid",uuid);// 获取一个结果并返回,如果需要多个结果,则调用getResultList()Material result =(Material)query.getSingleResult();return result;}}
这里如果直接使用createQuery方法,则表明使用JPQL。因为很多人是MyBatis Plus转的,所以这里就用NativeQuery的写法,比较容易被读者接受。EntityManager可以说是JPA的核心,很多有趣的用法大家可以自行探索一下。
结合Spring Security自动写入审计信息
我们经常需要让系统自动维护创建人、创建时间、最后修改人、最后修改时间等信息,如果反复写这些代码会比较麻烦,最好的做法是让框架直接替咱们写进去。
第一步,创建自动审计信息写入的配置
importorg.springframework.context.annotation.Configuration;importorg.springframework.data.domain.AuditorAware;importorg.springframework.security.core.Authentication;importorg.springframework.security.core.context.SecurityContext;importorg.springframework.security.core.context.SecurityContextHolder;importjava.util.Optional;@ConfigurationpublicclassJpaAutoAuditorimplementsAuditorAware<String>{@OverridepublicOptional<String>getCurrentAuditor(){SecurityContext context =SecurityContextHolder.getContext();if(context ==null)returnOptional.of("");Authentication authentication = context.getAuthentication();if(authentication ==null)returnOptional.of("");if(!authentication.isAuthenticated())returnOptional.of("");returnOptional.of(authentication.getName());}}
第二步,我们同步在实体类(Entity)里创建对应的审计字段
/**
* 创建人
*/@CreatedBy@Column(name ="create_by")privateString createBy
/**
* 创建时间
*/@JsonFormat(pattern ="yyyy-MM-dd HH:mm:ss", timezone ="GMT+8")@CreatedDate@Column(name ="create_time")privateLocalDateTime createTime
/**
* 最后修改人
*/@LastModifiedBy@Column(name ="last_modified_by")privateString lastModifiedBy
/**
* 最后修改时间
*/@JsonFormat(pattern ="yyyy-MM-dd HH:mm:ss", timezone ="GMT+8")@LastModifiedDate@Column(name ="last_modified_time")privateLocalDateTime lastModifiedTime
这样便可以在保存和更新的时候自动填充时间和创建人、修改人了。注意JsonFormat引用的是
com.fasterxml.jackson.annotation.JsonFormat
。
分页
其实分页这块虽然叫做进阶用法,但是大多数情况还是根据实际业务来判断如何分页的。
如果你用Repository的方式,可以按如下方式进行分页
@Query(value ="SELECT * FROM material WHERE type = ?1",
countQuery ="SELECT count(1) FROM material WHERE type = ?1",
nativeQuery =true)Page<Material>findByType(Integer type,Pageable pageable);
这里的countQuery是用来确定总数量的SQL语句,调用的时候pageable这么传:
PageRequest.of(1,20)
,就代表取第一页的数据,每页20条
当然,如果因为查询效率不想用这个特性(比如跨库查询时往往会自定义一个KV库做查询堆),也可以手动写limit或rowno查询子句。
事务控制
上面的例子里大家会看到
@Transactional
注解,这个注解所标注的类或方法就会开启事务特性。如果你使用
org.springframework.transaction.annotation.Transactional
而不是jakarta的Transactional注解,还可以定制rollBackFor属性,当发生特定异常时才会进行回滚操作。
但有时候我们可能会做个EventBus封装一些消息,当执行过程到达某些错误消息的时候应当使之前所做的处理都恢复到原状,或者我们需要更加精细化的事务控制,这时候就会用到手动回滚。
// 无论在哪里执行,回滚当前线程下的事务(但不会立即回滚)TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();// 用EntityManager开启事务
entityManager.getTransaction().begin();// 用EntityManager提交事务
entityManager.getTransaction().commit();// 用EntityManager回滚事务
entityManager.getTransaction().rollback();// 用EntityManager标记为应当回滚
entityManager.getTransaction().setRollbackOnly();
这里会涉及到事务传播机制,想必大家之前应该都学习过这个内容。
其他用法
有兴趣的读者可以搜索以下进阶用法,难度都不是很大,展开的去讲会比较跑题,所以这里不做赘述,短时间内突破即可快速全面掌握Spring Data JPA的用法:
1. Spring Data JPA 配置 Druid数据源
2. Spring Data JPA 的查询缓存配置
3. Hibernate的三态变化
4. Spring Data JPA + JTA(Atomikos)做分布式事务
5. Spring Data JPA 多数据源
有兴趣的读者可以自行研究、写博客并告诉我,我会在这里附上链接。
第四章、精通领域
前面的知识已经足够可以覆盖你的日常业务,如非必要,这一章可以略过,研究这一章的内容会消耗大量时间和精力。
Spring Data JPA内部机制
Jpa的抽象适配器位于AbstractJpaVendorAdapter,其实现有两个,一个是EclipseLinkJpaVendorAdapter,另一个是HibernateJpaVendorAdapter
在启动时会通过getJpaPropertyMap方法构筑配置项。
由此EntityManagerFactory和EntityManager会被构建起来。在这个过程中,SpringHibernateJpaPersistenceProvider会提供其实现。实现将被定位到Hibernate的SessionFactoryImpl和SessionImpl。
所以当我们每次调用EntityManager实际上调用的是Hibernate的Session。
除此之外,Repository的实现是SimpleJpaRepository,你的各种自定义方法实现都是基于JdkDynamicAopProxy的动态代理。
Criteria查询
你可以利用Criteria查询可以将大多数的查询机制进行二次封装,而且借助JPQL的特性,与具体数据库方言无关。如果你希望做一款能支持多种数据库系统的BI,Criteria可能会是一个不错的选择。
例如刚才查询学生UUID的过程就可以这样写:
CriteriaBuilder builder = entityManager.getCriteriaBuilder();CriteriaQuery<Student> query = builder.createQuery(Student.class);Root<Student> root = query.from(Student.class);
query.where(builder.and(
builder.equal(root.get("uuid"), uuid)));return entityManager.createQuery(query).getSingleResult();
使用该工具可以很方便的实现数据湖、BI等产品
GraphQL
当你使用Spring Data JPA之后就可以无缝使用GraphQL了。
第一步,引入
spring-boot-starter-graphql
第二步,开启GraphQL
spring
graphql
graphiql
enabled:true
第三步,Spring Boot会在
src/main/resources/graphql/**
目录寻找结尾为
.graphqls
或
.gqls
的文件,这些文件里可以这样描述我们的GraphQL查询结构:
type Student {
uuid: ID!
name: String!
age: Int
}
type Query {
allStudents: [Student]!
studentByUuid(uuid: ID): Student
}
type Mutation {
createStudent(studentInput: StudentInput): Student
}
input StudentInput {
uuid: ID!
name: String!
age: Int
}
第四步,在Controller的方法上标注@QueryMapping注解、在参数上标注@Argument就可以执行查询了。如果是增删改操作,则加上@MutationMapping注解即可。
第五章、总结
为了能最大限度的让读者开箱即用Spring Data JPA,这里有很多细节问题没有展开的去说,大多数的专业术语已经在文中给出提示。
总的来说,Spring Data JPA是一个非常不错的持久化层框架,以渐进式的方式可以帮助我们快速搭建应用到深度使用。随着多行字符串语法糖的普及,很多SQL语句都可以直接写在Java文件中,相较于MyBatis写在XML的做法而言,一来更容易保护我们的知识产权,二来更可以避免因为服务器被黑客提权从而修改XML进行二次攻击的风险,第三还可以以一种与数据库方言无关的方式完成跨数据库平台的应用系统设计。
版权归原作者 杨若瑜 所有, 如有侵权,请联系我们删除。