
Kafka怎么做到避免消息重复消费的? 消费者组是什么?
消费者
:
1、订阅Topic(主题)
2、从订阅的Topic消费(pull)消息,
3、将消费消息的offset(偏移量)保存在Kafka内置的一Topic名字是_consumer_offsets的主题中,在Kafka的logs文件下能看到这👟文件,存放的是消息的偏移量数据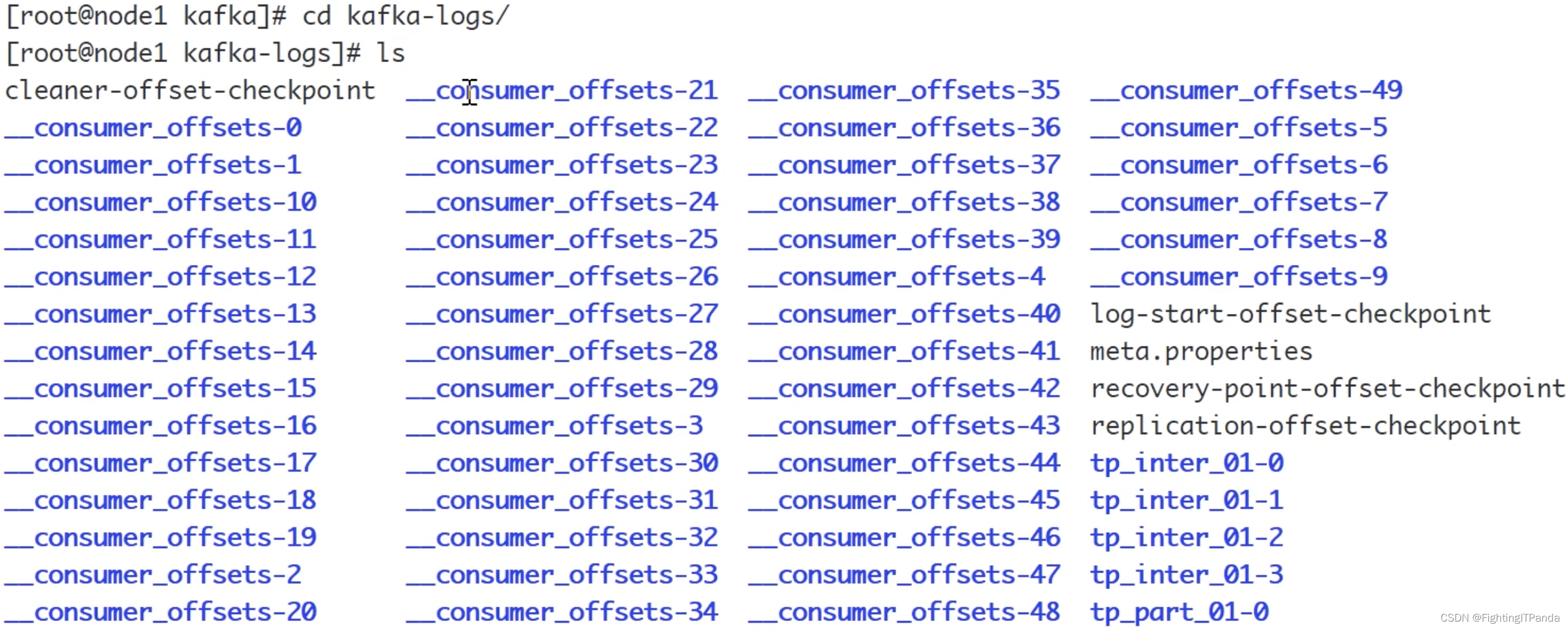
消费者组
:
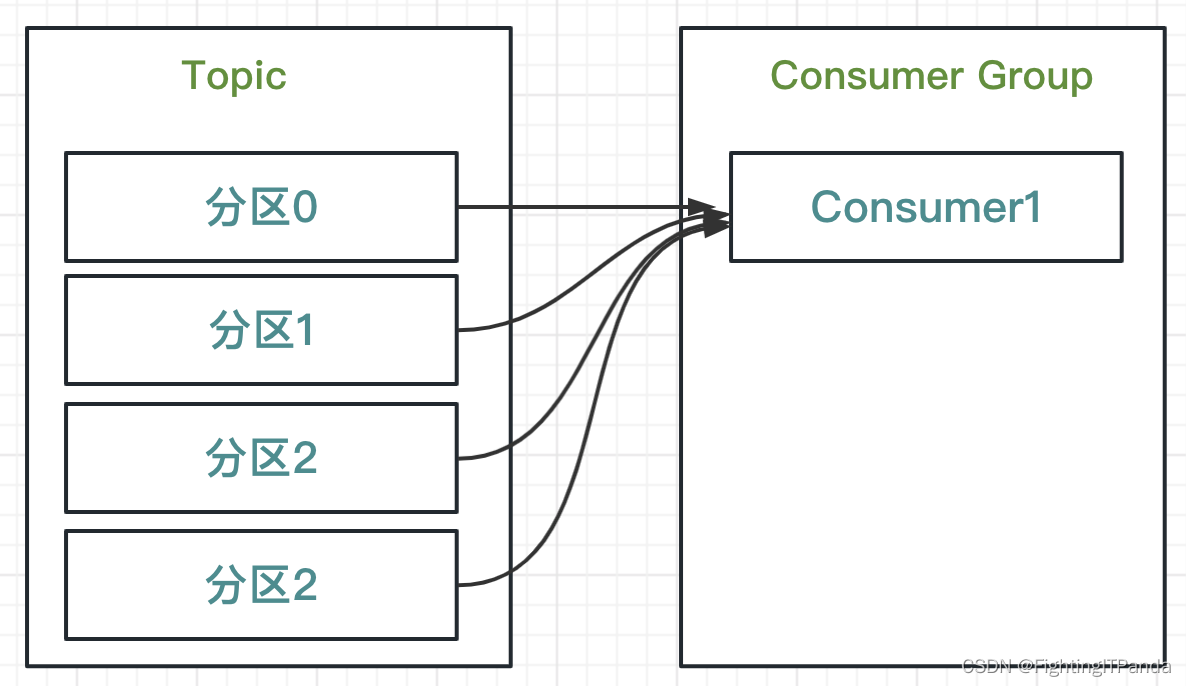
1、订阅同一个Topic的消费者可以加入到一个consumer Group(消费者组)
2、消费者组中的consumer共享一个
group_id
,
configs,put(“group.id”,”XXX”);
只要消费者的group_id一样,就属于同一个消费者组
3、消费者组保证每个topic下一个partition的消息只能被一个消费者组下一个消费者消费,避免消息的重复消费
如上图,当前只有一个消费者组订阅这个Topic,消费者组里只有一个消费者,那么当前Topic中所有分区的消息都由这个消费者消费
4、当消费者端业务逻辑比较复杂,消费消息比较慢,这个时候我们可以向消费者组中多加几个消费者(横向扩展)来提升消费速度。无非就是消费者端一套代码再在几台新的服务器部署一套,加入到同一个group_id下,同时从主题消费消息
横向扩展后,Kafka会对消息的分区与消费者的对应关系重新调整,这就是rebalance(再平衡机制)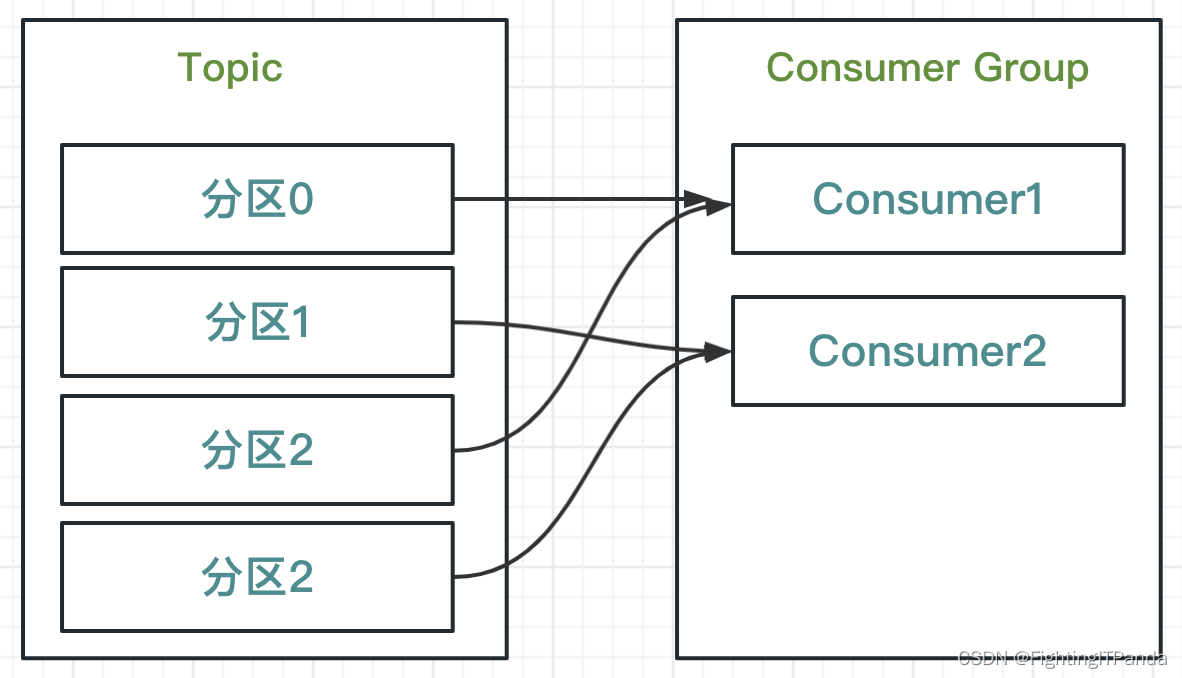
如上图,消费者组扩展一个消费者后,消费者1、2分别消费两个分区的消息
我们可以看到,一个分区对应一个消费者,但是一个消费者可以对应多个分区
如果上面结构还不够,两个消费者消费速度依然跟不上,那么我们还可以继续添加消费者,添加到4个消费者,此时主题分区与消费者的关系再次发生变化,需要再平衡,此时一个消费者消费一个分区消息,达到并行消费的效果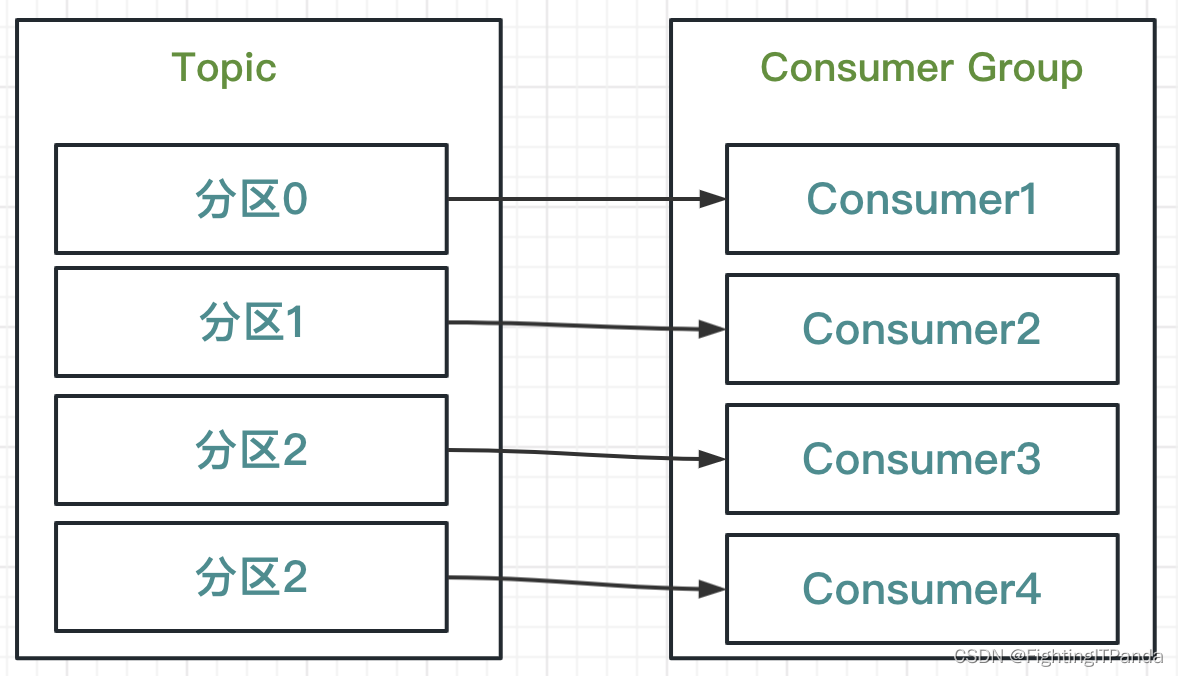
上面步骤我们看到了消息的分区可以横向扩展,消息的消费者也可以横向扩展,
向消费者组添加消费者是横向扩展消费能力的主要方式,
而消费者组是消费者的关键,
消费者组来保证,主题下的消息不管由多少个分区,每条消息只会被一个消费者消费,就不会引起重复消费的情况
一般最佳情况是:消费者数 = 分区数,一个分区对应一个消费者,
消费者也不是越多越好,消费者数受限于分区数, 过多消费者会导致有的消费者没有分配分区导致空闲,如下图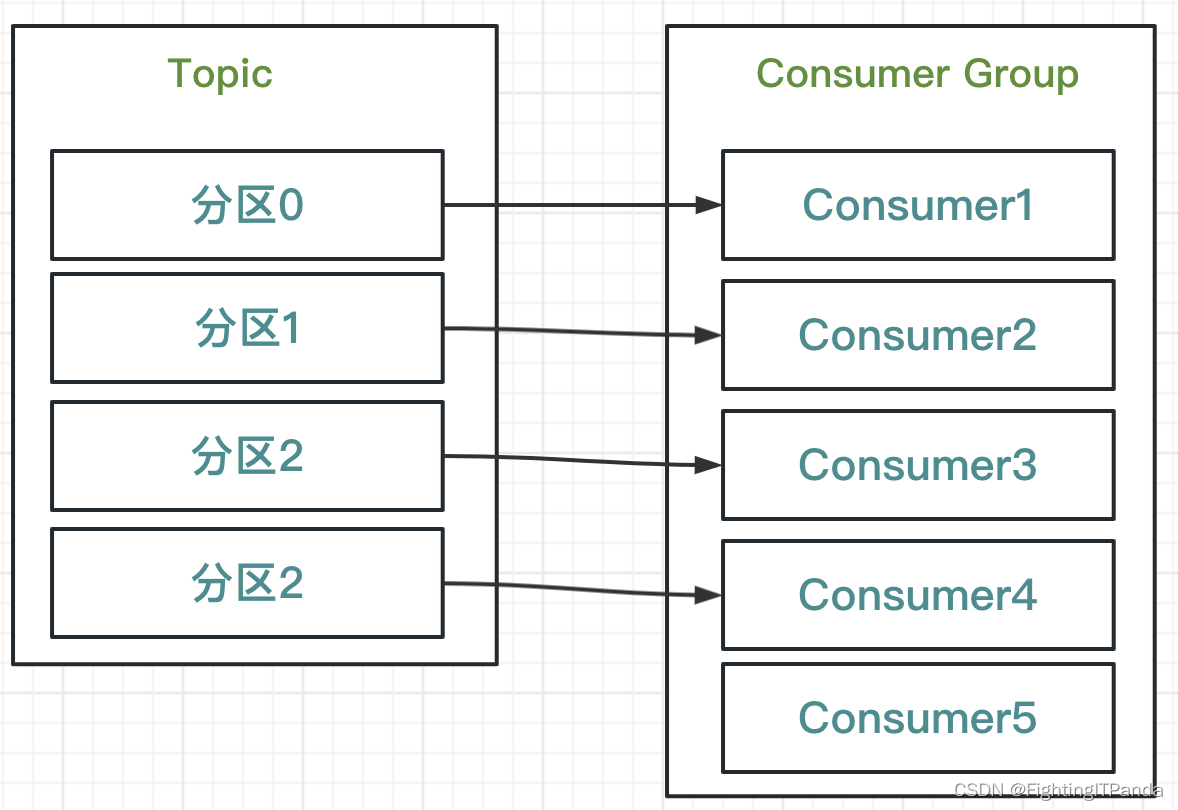
所以对于高并发的场合,我们通常会给一个主题设置很多个分区,分区数多利于消费者横向扩张
上面是一个消费者组的情况,实际上对于一个Topic可以有不同的消费者组,如下图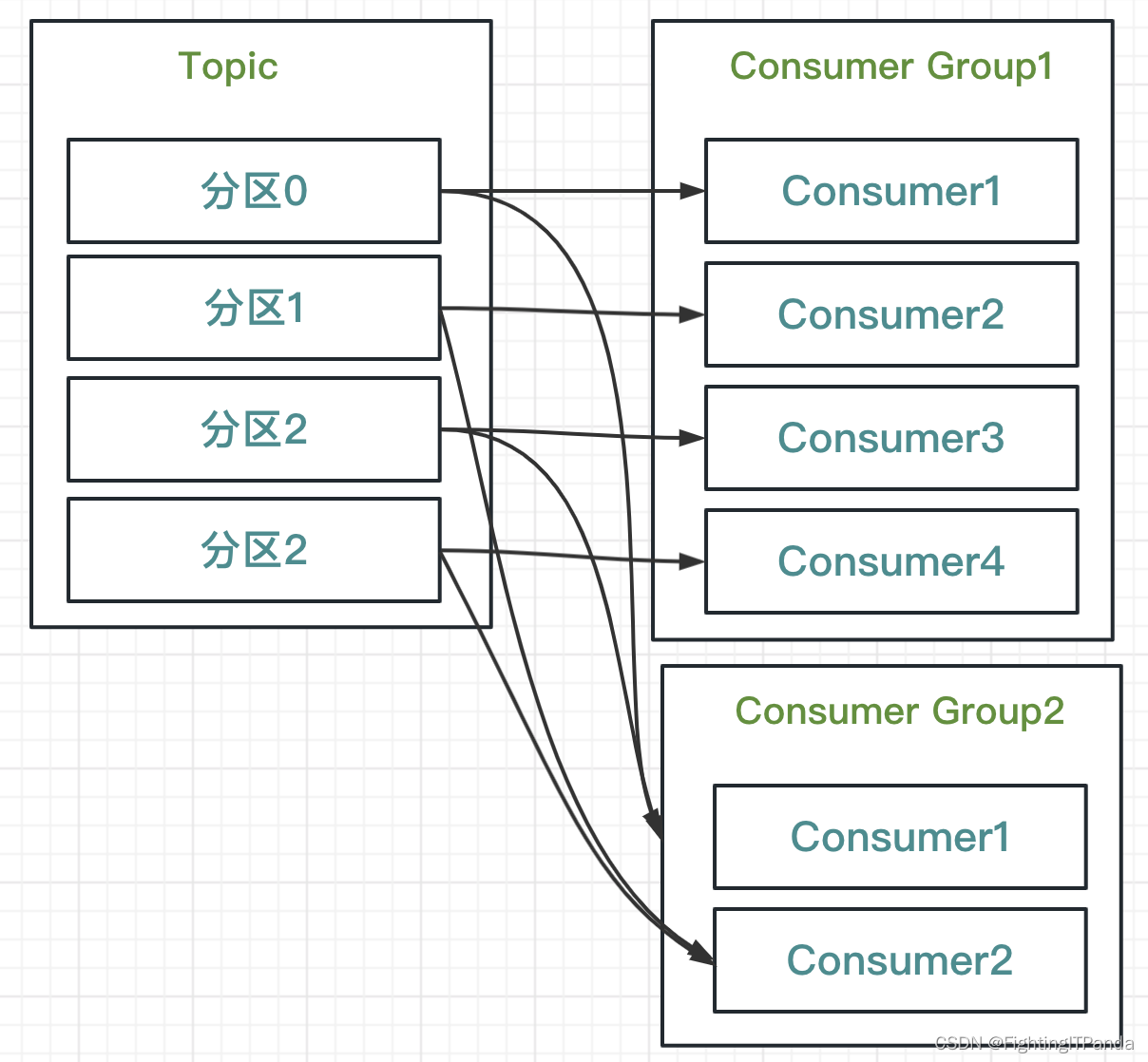
- 每个消费者组是相互独立的
- 每个消费者组都可以拿到主题的全部数据
版权归原作者 FightingITPanda 所有, 如有侵权,请联系我们删除。