
文章目录
概要
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
官方文档
有界无界流
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。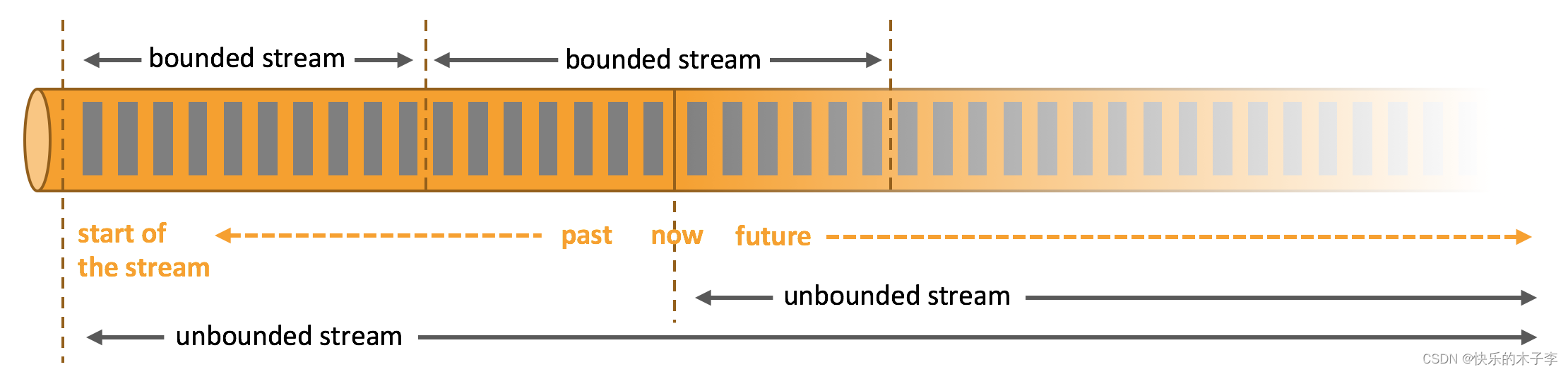
无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
集群
官方入口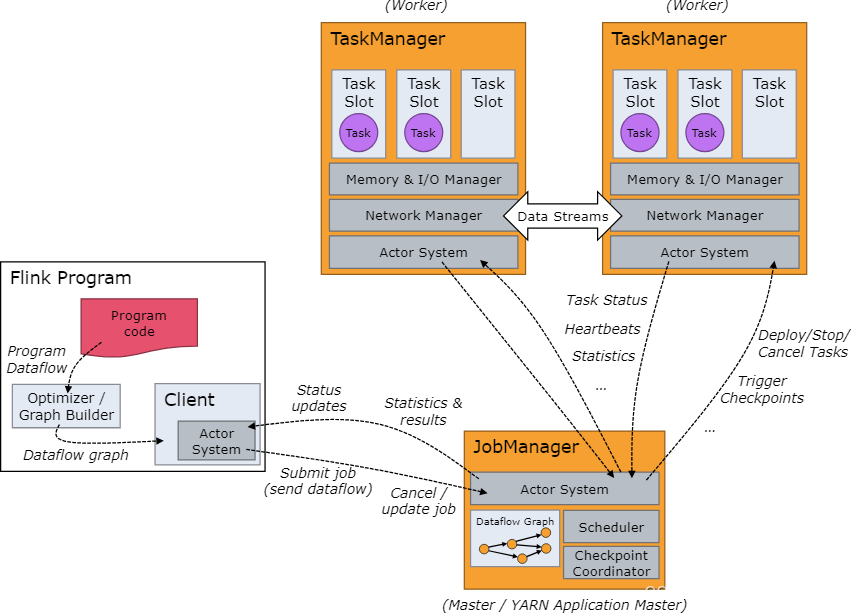
Client 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。之后,客户端可以断开连接(分离模式),或保持连接来接收进程报告(附加模式)。客户端可以作为触发执行 Java/Scala 程序的一部分运行,也可以在命令行进程./bin/flink run …中运行。
可以通过多种方式启动 JobManager 和 TaskManager:直接在机器上作为standalone 集群启动、在容器中启动、或者通过YARN等资源框架管理并启动。TaskManager 连接到 JobManagers,宣布自己可用,并被分配工作。
JobManager
JobManager 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。这个进程由三个不同的组件组成:
- ResourceManager :负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的单位(请参考TaskManagers)。Flink 为不同的环境和资源提供者(例如 YARN、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
- Dispatcher: 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster: 负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。始终至少有一个 JobManager。高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby(请参考 高可用(HA))。
TaskManagers
TaskManager(也称为 worker)执行作业流的 task,并且缓存和交换数据流。必须始终至少有一个 TaskManager。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量。请注意一个 task slot 中可以执行多个算子(请参考Tasks 和算子链)。
Tasks 和算子链
对于分布式执行,Flink 将算子的 subtasks 链接成 tasks。每个 task 由一个线程执行。将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。链行为是可以配置的;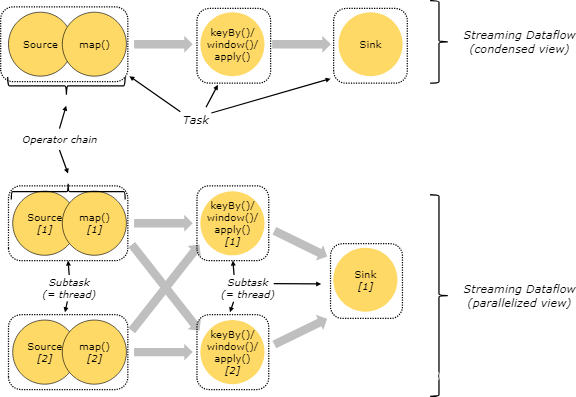
Task Slots 和资源
每个 worker(TaskManager)都是一个 JVM 进程,可以在单独的线程中执行一个或多个 subtask。为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)。
每个 task slot 代表 TaskManager 中资源的固定子集。例如,具有 3 个 slot 的 TaskManager,会将其托管内存 1/3 用于每个 slot。分配资源意味着 subtask 不会与其他作业的 subtask 竞争托管内存,而是具有一定数量的保留托管内存。注意此处没有 CPU 隔离;当前 slot 仅分离 task 的托管内存。
通过调整 task slot 的数量,用户可以定义 subtask 如何互相隔离。每个 TaskManager 有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。具有多个 slot 意味着更多 subtask 共享同一 JVM。同一 JVM 中的 task 共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个 task 的开销。
小结
提示:这里可以添加总结
例如:
提供先进的推理,复杂的指令,更多的创造力。
版权归原作者 快乐的木子李 所有, 如有侵权,请联系我们删除。