
山东项目系统慢问题分析和解决
前言:
排查此类问题最重要的是要弄清事情的问题的原因表象以及根本原因是什么,
只要弄清楚是什么原因导致的我们才能解决此类问题,这也是一个过程,每个人的理解不同,所以说结果也是不同的. 这边文章就从技术的角度从
问题分析>问题猜想>问题处理>验证结果 四个过程进行 排查我们的系统如何慢.
ps:我这里是从后端的角度进行分析,关于前端分析这块可能会有描述差异
优化结果:
整体系统响应比之前有较大提升,一些卡顿的页面性能得到明显提升,以下是详细信息,也可以进到我们系统里体验下是否有提升.
问题列表和优化过程记录
1 大屏页面 - 领导驾驶舱
1.1 问题分析
问题描述分类问题描述原因初步分析原因分类领导驾驶舱矿山信息加载所有数据统计各自关联表数量1 数据稍多有计算矿山预警报警预警数据量比较大,实时统计就很慢1 数据量大矿山报警类型报警数据量比较大,实时统计就很慢1 数据量大安全评估分时统计了所有时间段的数据,实际只需要统计最近7天的数据1 查询条件有误地图加载
即有明确的界面展示,能够直观看到加载或响应时间
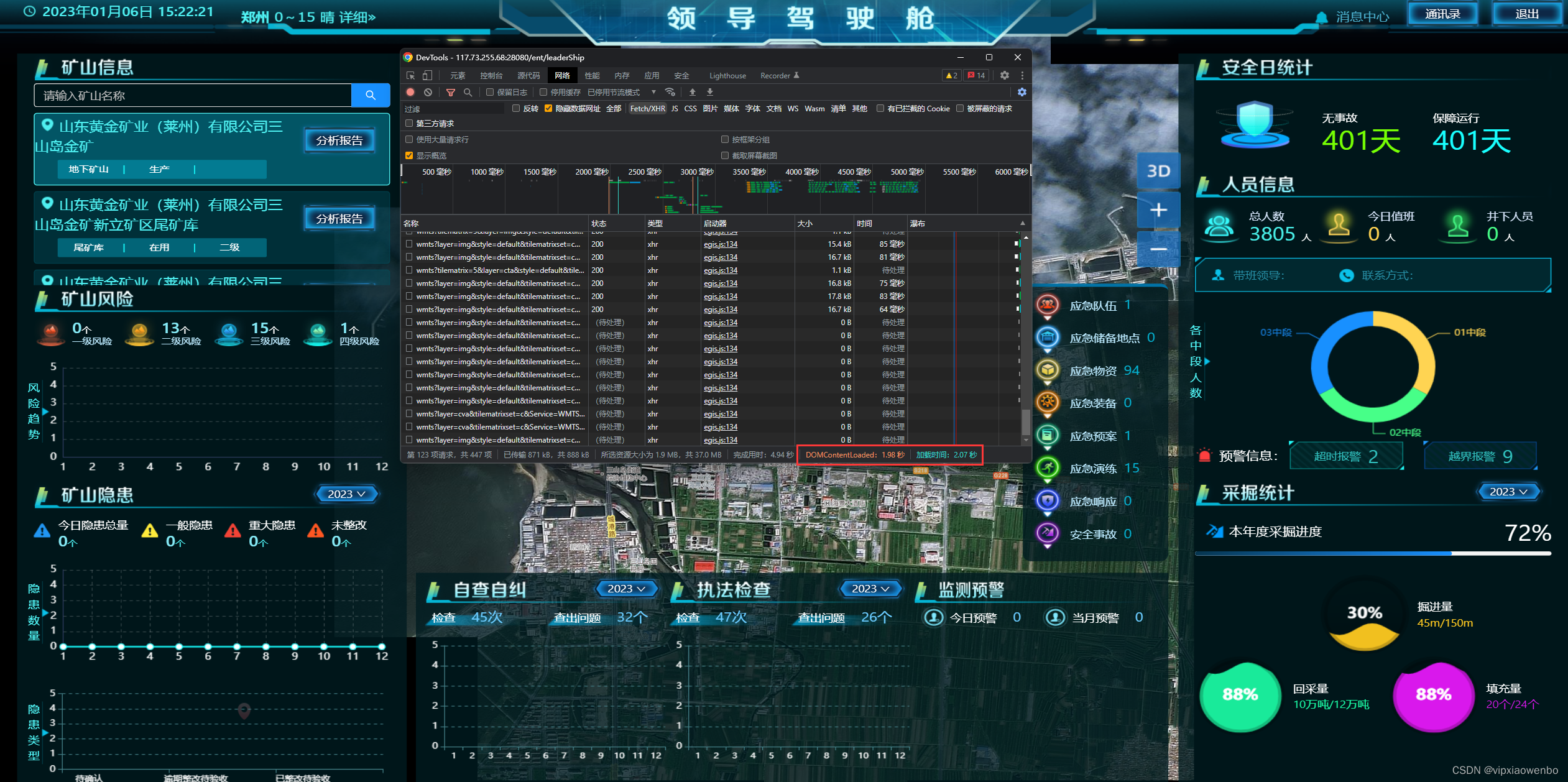
我们首先看一下这个图 前台dom加载共2秒 加载时间2.2秒 一共完成用了1.8分钟 另外有接口超时
在浏览器开发者面板里 这里主要分析一点 : 加载时间长的地方在哪 根据问题进行响应处理
1.2 问题解决
问题描述分类问题描述原因初步分析原因分类领导驾驶舱矿山信息加载所有数据统计各自关联表数量1 数据稍多有计算矿山预警报警预警数据量比较大,实时统计就很慢1 数据量大矿山报警类型报警数据量比较大,实时统计就很慢1 数据量大安全评估分时统计了所有时间段的数据,实际只需要统计最近7天的数据1 查询条件有误地图加载
1.2.1 问题解决思路
这类问题都是需要在大屏或者统计图表中统计出某某信息的列表和数量,这类代码往往牵涉到计算,以及实时显示的问题
解决方法:
- 实时计算数量放在redis里,查询的时候查基础数据数量不在数据库中做计算
- 最好单独起服务进行计算,将计算的结果存储在redis或者数据库中以供数据进行查询,计算的频率根据计算结果的快慢进行设置,计算频率至少>计算时间*2
- SQL 最小化查询条件
- SQL 减少不必要的查询
- SQL 优化<如何创建索引,以及命中索引>
- 前端加载js较大的时候可以采取CDN加速或者js压缩等方式
根据实际结果领导驾驶舱3秒内刷新加载就可以完成.
优化过之后两秒内即可刷新完成. 第一次加载的时间也是3-4秒即可完成
1.2.2 关于SQL优化
另外有由于领导驾驶舱是处理的第一个页面,所以从整体考虑来讲我这边打开了druid的SQL监控面板进行进一步优化
设置刷新频率为20秒 多看一会
点击这个页面的时候 手动多刷几次有问题的页面,这里主要优化最慢且执行数量比较高的 ,将这些有问题的贴到Navicat里explain
- 关于索引命中的问题 参考下面这个连接
https://blog.csdn.net/qq_45566762/article/details/116200103
本次排查主要包含以下使用到地方
1 强制索引 2 类型转换 3 like处理
- in处理
in范围小走索引,in范围大不走索引
这个需要根据实际情况处理,我测试的时候是将in替换为了关联查询 即 select a,b where a.x=b.x and b.xx like ‘a%’; 这个是处理其他慢sql处理的 在这里简单提一下,有的时候 网上的东西不一定对,可以根据实际情况进行测试看哪个快.
https://blog.csdn.net/Miss_SquarePants/article/details/124236679
https://www.365jz.com/article/27003
网上也有说exists替换为in等说法 这个要看情况 有的情况可能并不适用
- 另外也有一些关于数据库方面的知识:
1 关联字段创建索引或者外键等 一定要将数据库的类型和字段长度一致 否则可能会导致索引失效
例如a表关联b表 a.id = b.fid 假设 类型不一致可能会导致索引失效
2 大表有order by 查询分页等数据 需要将order by 的字段增加索引 一般都是时间字段
3 大数据量插入一定要使用批量插入
1.2.3 高峰时mysql cpu高整体查询慢
另外也有可能是锁表,死锁,阻塞等情况
参考:
https://blog.51cto.com/u_9625010/2486571
https://www.shuzhiduo.com/A/A2dmqOLAde/
详细步骤参考:
https://blog.csdn.net/vipxiaowenbo/article/details/125302212
2系统管理
2.1 问题分析
问题描述分类问题描述原因初步分析原因分类系统管理企业填报缺少分页缺少分页物联网接入缺少分页 有计算缺少分页和有计算在线用户缺少分页 有计算缺少分页和有计算主页跳转加载js过大前端资源大
2.2 问题解决
这个和前面的问题比较类似,多了一个前端加载js过大的问题
处理方式是一样的,
- 查询多的尽量改成分页
- 有计算多的将计算结果的数据存redis,定时进行清算
- 计算单独起服务尽量单独起服务进行计算
另外前端的问题本人不是很专业,
处理加载资源慢方法
- CDN加速
- 压缩
- 去掉没用的引用
3 隐患排查治理
3.1 问题分析和解决
问题描述分类问题描述原因初步分析原因分类隐患排查治理执法检查慢查询,没有命中索引慢查询报警预警处置大表 慢查询慢查询
执法检查检查处理比较简单,在查询字段上加索引explain就行了
报警预警处置就比较复杂了,大概花了我大半天的时间 大约从20秒优化到8秒左右
代码
这是一段分页查询代码,大概意思是先根据gov查询出一个id列表,在in到下面的另外一张表里面
这里有很多问题点
- in的范围比较大
- 查询的数据比较多
- 有多表关联
- 基表数量比较大,关联的也有大表
publicIPage<SafeCheckProblem>govPages(IPage<SafeCheckProblem> page,String gov,String mineName,String content){List<String> mineIds=baseMapper.getMineIdsForGov(gov);if(mineIds==null|| mineIds.size()==0)returnnewPage<>();return baseMapper.govPage(page,gov,mineName,content);}
我修改过的sql
- 去掉无用的关联 意义不是很大
- 将in 修改为关联查询 in大表索引会失效
- 类型转换 匹配字段3 改为’3’ 数据库类型是字符 这里直接匹配数字会导致索引失效
- order by 增加索引 增加查询分页数据效率
- *这个符号没有去掉,担心去对业务有影响 【原则上不允许出现select * 】
<selectid="govPage"resultType="com.zwsafety.drh.entity.SafeCheckProblem">
select scp.* from safe_check_problem scp
, ent_minebase em
<iftest="gov!=null">
LEFT JOIN sys_district sdt ON (em.districtid = sdt.id)
</if>
where source='3'
and scp.baseid=em.id
<iftest="gov!=null">
and sdt.id LIKE '${gov}%'
</if><iftest="content !=null ">
and scp.content like '%${content}%'
</if><iftest="mineName !=null ">
and em.minename like '%${mineName}%'
</if>
order by scp.create_time desc
</select>
4 矿山首页
这个功能由于涉及业务复杂,由其他同事后续补充.
5 SQL和其他
日志记录影响整体性能
由于我们系统后台采用是jeecg-boot框架开发的,生成代码上默认的控制层(controller层) 多了一个@Autolog这个注解,这个注解意思是记录日志,也就是前台发起一次请求,后台会记录是谁发起的请求,目前这个表已经到千万级别,所以每次请求都会有至少1条记录在这个里面,
我们的系统直接至少已经被点击了千万次以上
解决办法:
- 删除 【增改查】 记录日志
- 修改插入为批量插入
- 500多个controller层,说明我们的业务非常的多,删除无用的日志记录

批量插入
系统启动单线程启动执行检测有无数据需要数据需要批量入库 ,这块后期可以优化下,将数据存储在kafka或者redis里面,目前我放在了内存里面.
packageorg.jeecg.startup;importcom.google.common.util.concurrent.ThreadFactoryBuilder;importlombok.extern.slf4j.Slf4j;importorg.apache.commons.collections.CollectionUtils;importorg.jeecg.common.api.dto.LogDTO;importorg.jeecg.common.handler.JobDealHandler;importorg.jeecg.modules.base.service.BaseCommonService;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.boot.CommandLineRunner;importorg.springframework.stereotype.Component;importjava.util.List;importjava.util.concurrent.*;/**
* 系统启动插入数据
* @author Xiaowb
*/@SuppressWarnings("unused")@Component@Slf4jpublicclassSysLogStartupimplementsCommandLineRunner{@Autowired(required =false)privateBaseCommonService baseCommonMapper;@SuppressWarnings({"squid:S2142","squid:S2189","squid:S112","squid:S1604"})@Overridepublicvoidrun(String... args)throwsException{if(baseCommonMapper ==null){
log.error("baseCommonMapper init error!!! log can not be insert !!!");}ExecutorService executorService =newSingleThreadExecutor("SysLogInsert",1024);
executorService.execute(newRunnable(){@Overridepublicvoidrun(){while(true){List<LogDTO> li =JobDealHandler.getList();if(CollectionUtils.isNotEmpty(li)){
log.info("已消费到日志数据"+li.size());
baseCommonMapper.saveLogBatch(li);}try{Thread.sleep(5000);}catch(InterruptedException ex){thrownewRuntimeException(ex);}}}});}/***
* 创建单线程池
* @param maximumTaskSize 最大任务等待数
* @return java.util.concurrent.ExecutorService
* @author Xiaowb
* @date 2022/12/29
*/publicstaticExecutorServicenewSingleThreadExecutor(String name,int maximumTaskSize){ThreadFactory threadFactory =newThreadFactoryBuilder().setNameFormat(name +"-%d").build();returnnewThreadPoolExecutor(1,1,0L,TimeUnit.MILLISECONDS,newLinkedBlockingDeque<>(maximumTaskSize),
threadFactory);}}
SQL优化:
参考:1.2.2 和 1.2.3
服务器负载
mysql服务器
web服务器1
web服务器2
都没有太大问题
jvm之前分析过,优化过了。
版权归原作者 vipxiaowenbo 所有, 如有侵权,请联系我们删除。