
一.spark是什么
1.什么是spark?
spark是基于内存计算的通用大数据并行计算框架,是一个快速、通用可扩展的大数据分析引擎。它给出了大一统的软件开发栈,适用于不同场合的分布式场景,如批处理、迭代算法、交互式查询、流处理、机器学习和图计算。
2.Spark生态系统?
SparkCore:spark的核心计算 主要Rdd
SparkSQL:提供了类sql方式操作结构化半结构化数据。对历史数据进行交互式查询。(即席查询:用户根据自己的需求,自定义查询)
SparkStreaming:提供了近乎实时的流式数据处理,与storm相比有更高的吞吐量。(实时计算 目前实时计算框架有哪些? storm、sparkstreaming、flink)
SparkMl:提供了常见的机器学习算法库,包括分类、回归、聚类、协同工过滤(个性推荐:用户画像)等,还提供模型评估、数据处理等额外功能,使得机器学习能够更加方便的在分布式大数据环境下,快速的对数据进行处理形成模型后提供在线服务。
Graphx:用来操作图的程序库,可以进行并行的图计算。支持各种常见的图算法,包括page rank、Triangle Counting等。
3.常见的 分布式文件系统?
hdfs fastdfs Tachyon TFS GFS S3
4.master资源分配有哪些?
尽量集中 尽量打散
1.Application的调度算法有两种,一种是spreadOutApps,另一种是非spreadOutApps。
2.spreadOutApps,会将每个Application要启动的executor都平均分配到各个worker上去。(比如有10个worker,20个cpu core要分配,那么实际会循环两遍worker,每个worker分配一个core,最后每个worker分配了2个core,这里的executor数量可能会与spark-submit设置的不一致)
3.非spreadOutApps,将每个Application尽可能分配到尽量少的worker上去。(比如总共有10个worker,每个有10个core,app总共要分配20个core,其实只会分配到两个worker上,每个worker占满10个core,其余app只能分配到下一个worker,这里的executor数量可能会与spark-submit设置的不一致)
5.spark 可以代替hadoop 吗?
spark会替代Hadoop的一部分,会替代Hadoop的计算框架,如mapReduce、Hive查询引擎,但spark本身不提供存储,所以spark不能完全替代Hadoop。
6.spark 特点?
6.1 速度快
Spark 使用DAG 调度器、查询优化器和物理执行引擎,能够在批处理和流数据获得很高的性能。根据官方的统计,它的运算速度是hadoop的100x倍
6.2 使用简单
Spark的易用性主要体现在两个方面。一方面,我们可以用较多的编程语言来写我们的应用程序,比如说Java,Scala,Python,R 和 SQL;另一方面,Spark 为我们提供了超过80个高阶操作,这使得我们十分容易地创建并行应用,除此之外,我们也可以使用Scala,Python,R和SQL shells,以实现对Spark的交互
6.3 通用性强
与其说通用性高,还不如说它集成度高,如图所示:以Spark为基础建立起来的模块(库)有Spark SQL,Spark Streaming,MLlib(machine learning)和GraphX(graph)。我们可以很容易地在同一个应用中将这些库结合起来使用,以满足我们的实际需求。
6.4 到处运行
Spark应用程度可以运行十分多的框架之上。它可以运行在Hadoop,Mesos,Kubernetes,standalone,或者云服务器上。它有多种多种访问源数据的方式。可以用standalone cluster模式来运行Spark应用程序,并且其应用程序跑在Hadoop,EC2,YARN,Mesos,或者Kubernates。对于访问的数据源,我们可以通过使用Spark访问HDFS,Alluxio,Apache Cassandra,HBase,Hive等多种数据源。
Scala的特点
① Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统。
② Scala语法简洁,能提供优雅的API。
③ Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中。
Spark生态系统
在实际应用中,大数据处理主要包括一下3个类型:
① 复杂的批量数据处理:时间跨度通常在数十分钟到数小时之间。
② 基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟之间。
③ 基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒之间。
当同时存在以上三种场景时,就需要同时部署三种不同的软件
二.Spark SQL
1,Spark SQL简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象结构叫做DataFrame的数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrames API和Datasets API三种方式实现对结构化数据的处理。
2,Spark SQL功能
Spark SQL主要提供了以下三个功能:
Spark SQL可从各种结构化数据源中读取数据,进行数据分析。
Spark SQL包含行业标准的JDBC和ODBC连接方式,因此它不局限于在Spark程序内使用SQL语句进行查询。
Spark SQL可以无缝地将SQL查询与Spark程序进行结合,它能够将结构化数据作为Spark中的分布式数据集(RDD)进行查询。
3,Spark SQL架构
Spark SQL架构与Hive架构相比,把底层的MapReduce执行引擎更改为Spark,还修改了Catalyst优化器,Spark SQL快速的计算效率得益于Catalyst优化器。从HiveQL被解析成语法抽象树起,执行计划生成和优化的工作全部交给Spark SQL的Catalyst优化器进行负责和管理。
三.Spark运行模式及集群
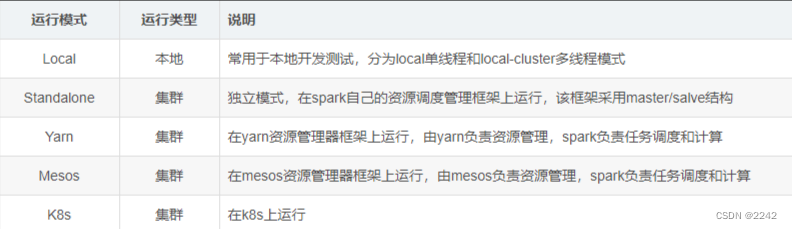
Spark运行模式
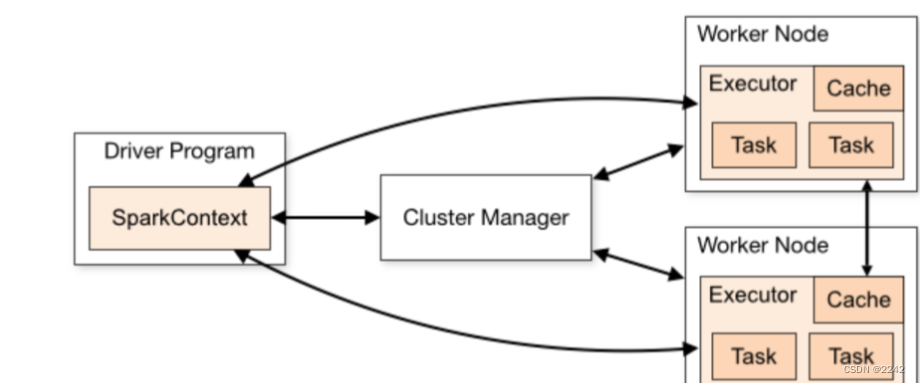
Spark集群
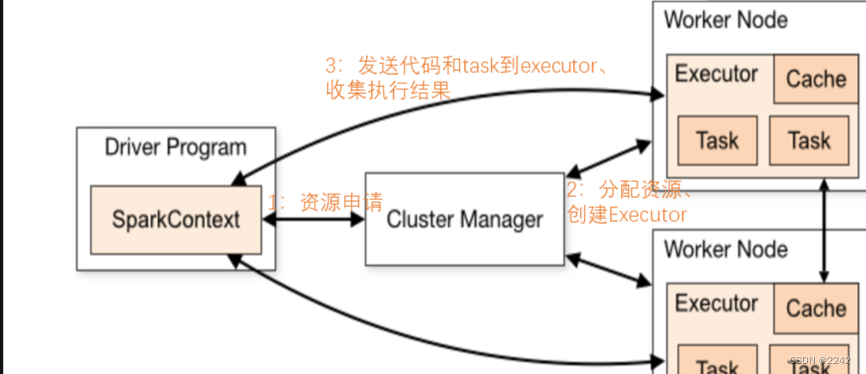
Spark作业流程
四.RDD
3.1.RDD概念
1.一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,不同节点上进行并行计算
2.RDD提供了一种高度受限的共享内存模型,RDD是只读的记录分区集合,不能直接修改,只能通过在转换的过程中改
优点
惰性调用,管道化,避免同步等待,不需要保存中间结果,每次操变得简单
3.2.RDD特性
1.高效的容错性
现有容错机制:数据复制或者记录日志RDD具有天生的容错性:血缘关系,重新计算丢失分区,无需回滚系统,重算过程在不同节点之间并行,只记录粗粒度的操作
2.中间结果持久化到内存,数据在内存中的多个RDD操作直接按进行传递,避免了不必要的读写磁盘开销
3.存放的数据可以是JAVA对象,避免了不必要的对象序列化和反序列化
3.3.RDD的创建
var lines = sc.textFile("文件路径")//sc是SparkContent对象
lines.filter(x => x.contains("error")).count()//filter是transformation算子不触发计算,count是action算子,会触发计算
3.4.RDD的窄依赖和宽依赖
窄依赖:没有数据的shuffling,所有的父RDD的partition会一一映射到子RDD的partition中
宽依赖:发生数据的shuffling,父RDD中的partition会根据key的不同进行切分,划分到子RDD中对应的partition中
五.spark编程基础
一.从内存中读取数据创建RDD
RDD的算子操作案例
重点掌握rdd常见的一些算子操作
flatMap
map
reduceByKey
sortBy
distinct
count
mapPartitions
foreach
parallelize()方法有两个输入参数,说明如下。
要转化的集合,必须是Seq集合。Seq表示序列,指的是一类具有一定长度的、可迭代访问的对象,其中每个数据元素均带有一个从0开始的、固定的索引。
分区数。若不设分区数,则RDD的分区数默认为该程序分配到的资源的CPU核心数。
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf().setAppName("ParallelizeExample").setMaster("local")
val sc = new SparkContext(conf)
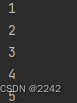
val data = Array(1, 2, 3, 4, 5)
val rdd = sc.parallelize(data)
rdd.foreach(println)
sc.stop()
效果
1.2makeRDD()方法
makeRDD()方法有两种使用方式。
第一种方式的使用与parallelize()方法一致;
第二种方式是通过接收一个是Seq[(T,Seq[String])]参数类型创建RDD。
第二种方式生成的RDD中保存的是T的值,Seq[String]部分的数据会按照Seq[(T,Seq[String])]的顺序存放到各个分区中,一个Seq[String]对应存放至一个分区,并为数据提供位置信息,通过preferredLocations()方法可以根据位置信息查看每一个分区的值。调用makeRDD()时不可以直接指定RDD的分区个数,分区的个数与Seq[String]参数的个数是保持一致的
from pyspark import SparkContext
# 创建 SparkContext 对象
sc = SparkContext("local", "parallelize Example")
# 创建一个列表
data = [1, 2, 3, 4, 5]
# 使用 parallelize() 方法创建 RDD
rdd = sc.parallelize(data)
# 打印 RDD 中的元素
for element in rdd.collect():
print(element)
效果
二、从外部创建RDD
1.文本文件:textFile
textFile() 方法是 Apache Spark 中用于从文件系统中读取文本文件的函数
基本语法:
textFile(path, minPartitions=None, use_unicode=True)
代码实例
from pyspark import SparkContext
# 创建 SparkContext 对象
sc = SparkContext("local", "textFile Example")
# 读取文本文件
lines = sc.textFile("path/to/file.txt")
# 打印每一行
for line in lines.collect():
print(line)
2.Sequence文件:sequenceFile()
sequenceFile() 方法用于在 Apache Spark 中读取 Hadoop SequenceFile 格式的文件,并将其作为 RDD 返回。SequenceFile 是 Hadoop 中一种常用的二进制文件格式,通常用于存储键-值对数据。
基本语法:
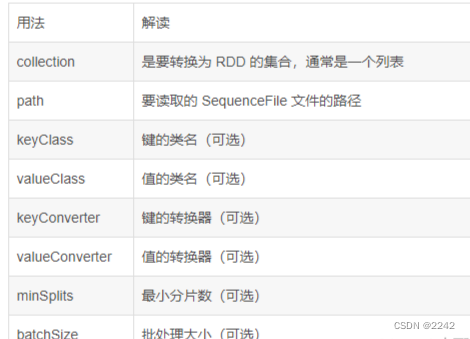
sequenceFile(path, keyClass=None, valueClass=None, keyConverter=None, valueConverter=None, minSplits=None, batchSize=0)
代码示例:
from pyspark import SparkContext
# 创建 SparkContext 对象
sc = SparkContext("local", "sequenceFile Example")
# 读取 SequenceFile 文件并创建 RDD
data = sc.sequenceFile("hdfs://path/to/sequence_file")
# 打印 RDD 中的元素
for key, value in data.collect():
print(key, value)
3.对象文件(Object files):
objectFile() 方法用于在 Apache Spark 中读取以序列化形式保存的对象文件,并将其作为 RDD 返回。这种文件格式通常用于将对象序列化为字节流,并存储在文件中,以便在后续操作中进行读取和处理。
基本语法:
objectFile(path, minPartitions=None, batchSize=0)
代码示例:
from pyspark import SparkContext
# 创建 SparkContext 对象
sc = SparkContext("local", "objectFile Example")
# 读取对象文件并创建 RDD
data = sc.objectFile("hdfs://path/to/object_file")
# 打印 RDD 中的元素
for obj in data.collect():
print(obj)
RDD的缓存机制
1、什么是rdd的缓存机制、好处是什么?
可以把一个rdd的数据缓存起来,后续有其他的job需要用到该rdd的结果数据,可以直接从缓存中获取得到,避免了重复计算。缓存是加快后续对该数据的访问操作。
2、如何对rdd设置缓存? cache和persist方法的区别是什么?
RDD通过persist方法或cache方法可以将前面的计算结果缓存。
但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
3、什么时候设置缓存?
1、某个rdd的数据后期被使用了多次
公共rdd进行持久化,避免后续需要,再次重新计算,提升效率。
2、rdd的数据来之不易时
为了获取得到一个rdd的结果数据,经过了大量的算子操作或者是计算逻辑比较复杂
4、如何清除缓存?
1、自动清除 :一个application应用程序结束之后,对应的缓存数据也就自动清除
2、手动清除 :调用rdd的unpersist方法
六、DataFrame简介
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格
DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化
DataFrame和RDD对比
RDD可以把它内部元素看成是一个java对象
DataFrame可以把内部是一个Row对象,它表示一行一行的数据
DataFrame
DataFrame引入了schema元信息和off-heap(堆外内存)
优点
DataFrame引入了schema元信息,解决了rdd数据的序列化和反序列性能开销很大这个缺点。
DataFrame引入了off-heap,解决了rdd构建大量的java对象 占用了大量heap堆空间,导致频繁的GC这个缺点。
缺点
1、编译时类型不安全
2、不在具有面向对象编程的风格
DataFrame常用的操作
1、DSL风格语法 :
spark自身提供了一套Api
/加载数据
val rdd1=sc.textFile("/person.txt").map(x=>x.split(" "))
//定义一个样例类
case class Person(id:String,name:String,age:Int)
//把rdd与样例类进行关联
val personRDD=rdd1.map(x=>Person(x(0),x(1),x(2).toInt))
//把rdd转换成DataFrame
val personDF=personRDD.toDF
//打印schema信息
personDF.printSchema
//展示数据
personDF.show
//查询指定的字段
personDF.select("name").show
personDF.select($"name").show
personDF.select(col("name").show
//实现age+1
personDF.select($"name",$"age",$"age"+1)).show
//实现age大于30过滤
personDF.filter($"age" > 30).show
//按照age分组统计次数
personDF.groupBy("age").count.show
//按照age分组统计次数降序
personDF.groupBy("age").count().sort($"count".desc)show
2.SQL风格语法
把dataFrame注册成一张表,通过sparkSession.sql(sql语句)操作该表数据
//DataFrame注册成表
personDF.createTempView("person")
//使用SparkSession调用sql方法统计查询
spark.sql("select * from person").show
spark.sql("select name from person").show
spark.sql("select name,age from person").show
spark.sql("select * from person where age >30").show
spark.sql("select count(*) from person where age >30").show
spark.sql("select age,count(*) from person group by age").show
spark.sql("select age,count(*) as count from person group by age").show
spark.sql("select * from person order by age desc").show
通过IDEA开发程序实现把RDD转换DataFrame
1、利用反射机制
事先可以确定DataFrame的schema信息
定义一个样例类,样例类中的属性,通过反射之后生成DataFrame的schema信息
2、通过StructType动态指定schema信息
事先不确定DataFrame的schema信息,在开发代码的过程中动态指定
其本质调用底层方法
//1、构建SparkSession对象
val spark: SparkSession = SparkSession.builder().appName("StructTypeSchema").master("local[2]").getOrCreate()
//2、获取sparkContext对象
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("warn")
//3、读取文件数据
val data: RDD[Array[String]] = sc.textFile("E:\\person.txt").map(x=>x.split(" "))
//4、将rdd与Row对象进行关联
val rowRDD: RDD[Row] = data.map(x=>Row(x(0),x(1),x(2).toInt))
//5、指定dataFrame的schema信息
//这里指定的字段个数和类型必须要跟Row对象保持一致
val schema=StructType(
StructField("id",StringType)::
StructField("name",StringType)::
StructField("age",IntegerType)::Nil
)
val dataFrame: DataFrame = spark.createDataFrame(rowRDD,schema)
dataFrame.printSchema()
dataFrame.show()
dataFrame.createTempView("user")
spark.sql("select * from user").show()
spark.stop()
}
版权归原作者 2242 所有, 如有侵权,请联系我们删除。