
一.引言
工业场景下 Flink 经常使用 ValueState + RocksDBStateBackend 的组合,针对不断增大的 ValueState 或者数量过大的 ValueState,RocksDBStateBackend 使用了 TaskManager 所在机器的本地目录,从而突破 JVM Heap 的限制,满足了大量 ValueState 存储的场景,下面介绍大状态下 ValueState 的实践与优化。
二.ValueState + RocksDB 组合
1.IO 瓶颈
RocksDBStateBackend 使用了 TaskManager 本地目录,突破 JVM 限制实现了大规模状态的存储,但由于 RocksDB 的 JNI 序列化 API 基于 Byte[],因此每次获取状态都需要进行序列化与反序列化的操作,这使得 EmbeddedRocksDBStateBackend 不适应频繁大规模更新状态的作业,因为磁盘的 IO 会限制状态读取的性能:

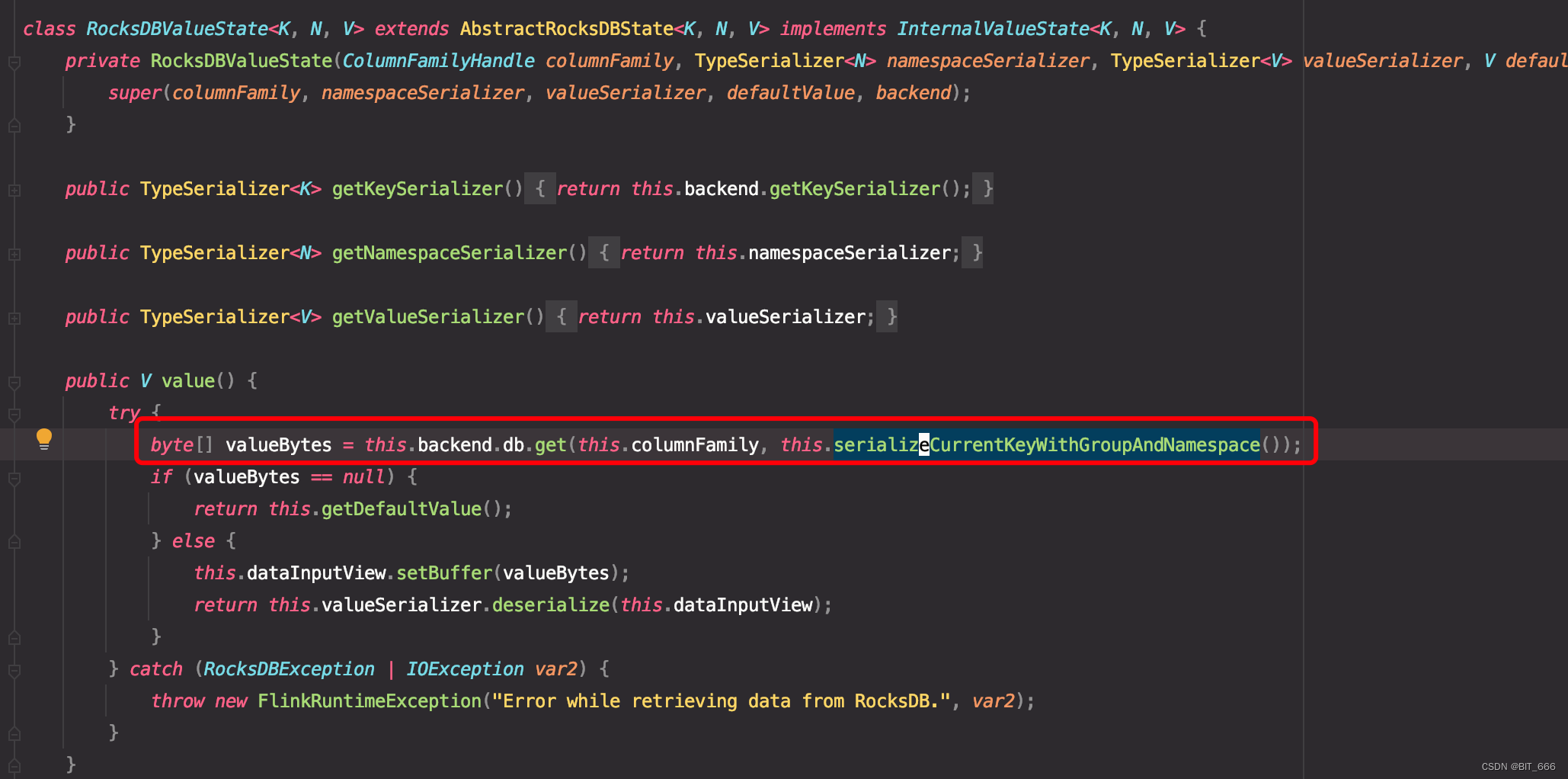
其源码位于 org.apache.flink.contrib.streaming.state 下 value 方法,与我们 Flink Api 中获取 ValueState 方法的 ValueState.value() 对应,其通过 backenddb.db.get 方法获取对应状态,后面的 serializeCurrentKeyWithGroupAndNamespace 方法负责将当前内容序列化并返回 byte[]。
2.问题影响
通过监控页面的 FlameGraph 火焰图的 Mixed 可以查看当前任务主要瓶颈在哪个线程上:
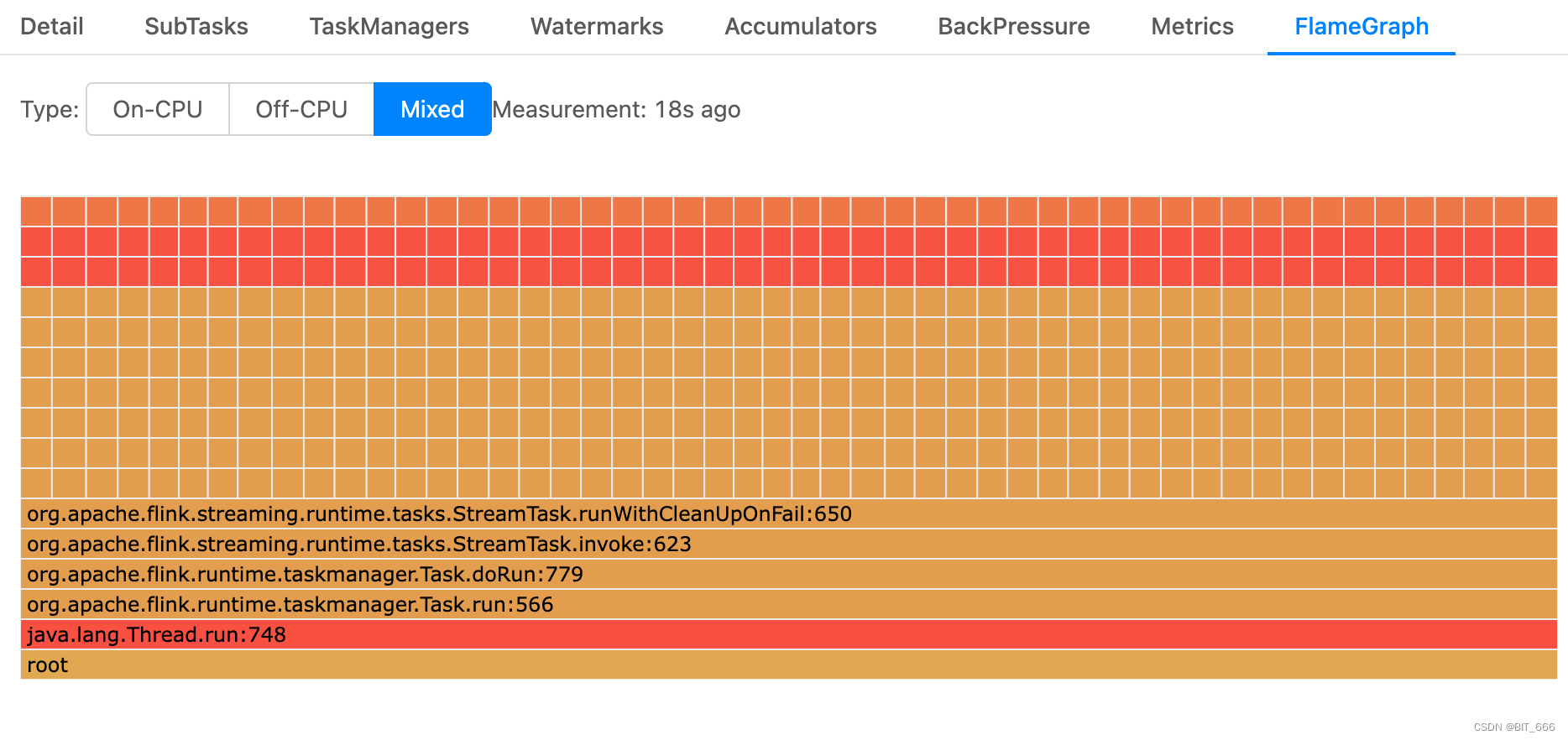
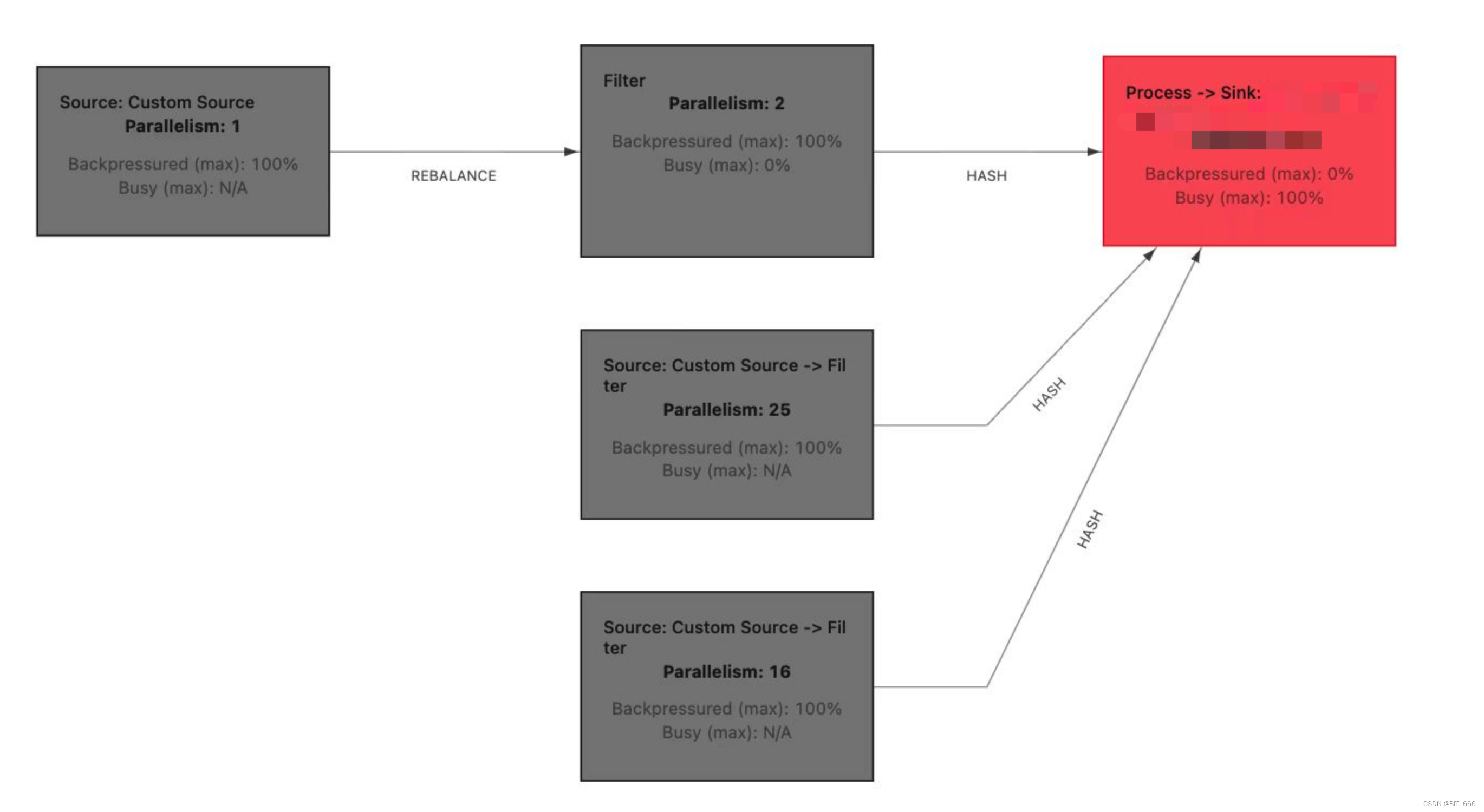
例如上边的火焰图大部分指向了 RockDBs.get 则代表当前瓶颈为状态获取的 IO 瓶颈,IO 瓶颈会导致当前 Opeartor Busy 打满,如果任务当前 Source 端流量较大则导致前置任务全部 Backpressured 背压打满,从而影响任务整体的运行时效性,严重的话会导致任务异常退出。
三.IO 瓶颈问题定位
1.常见情况
造成瓶颈归根到底是两个原因:
1> 磁盘性能不足即机器资源不足,因为 RocksDB 频繁与本机机器交互,资源不足导致 IO 瓶颈
2> 磁盘分配不均匀即负载不均匀,有足够的机器资源但因为分配不均,造成流量集中从而 IO 瓶颈
RocksDB 读取 TaskManager 本地机器,所以分析 IO 瓶颈主要从 TaskManager 所在机器分析即可,大致可以分为以下几种情况:
- A.Flink 并行度低,执行机器资源不足造成 IO 瓶颈
- B.Flink 并行度高,执行机器集中造成几个单点机器 IO 瓶颈
- C.Flink 并行度高,执行机器分散,状态访问频率过高,机器 IO 瓶颈
- D.Flink 并行度高,执行机器分散,公用机群,他人任务 IO 密集导致机器 IO 瓶颈
2.iotop 查看单台机器 IO 任务
基于上面四种情况,都需要查看机器 IO 来判断任务瓶颈原因,iotop 需要拥有 sudo 权限,常用的命令为 iotop -o,-o 代表查看当前正在产生 io 的任务:
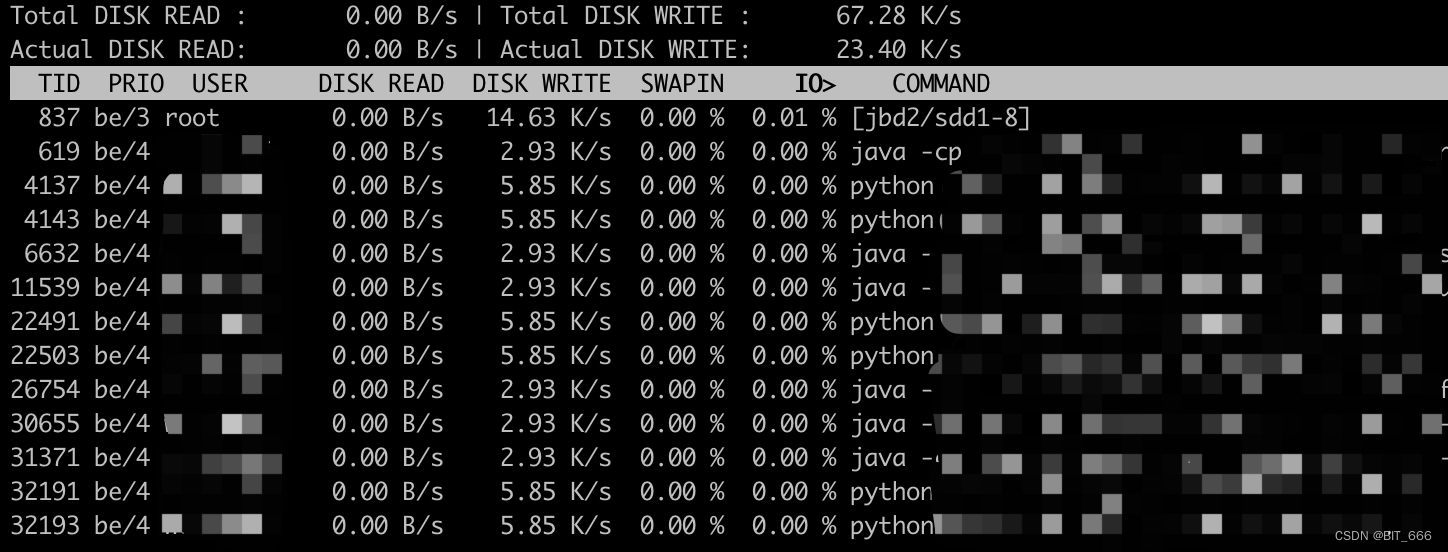
主要有 head 端的三列参数,下面逐一解释下:
参数含义Total DISK READ磁盘读取总速率Total DISK WRITE磁盘写入总速率Actual DISK READ磁盘真实读取总速率Actual DISK WRITE磁盘真实写入总速率TID类似 PID,代表进程 IDPRIO任务优先级USER线程所有者DISK READ当前磁盘读取速率DISK WRITE当前磁盘写入速率SWAPINswap 交换百分比IO>IO 等待所占的百分比COMMAND线程命令,例如 java xxx、python xxx
一般查看 IO> 即可,IO> 百分比较高,或者 DISK READ 、DISK WRITE 列过高对应的任务 TID/PID 即为 IO 密集型任务。
3.iostat 查看单台机器磁盘 IO 负载
sudo 权限下在机器下输入 iostat 查看各台物理机磁盘 IO 情况,interval 为整数,代表更新频率
iostat -x -d interval
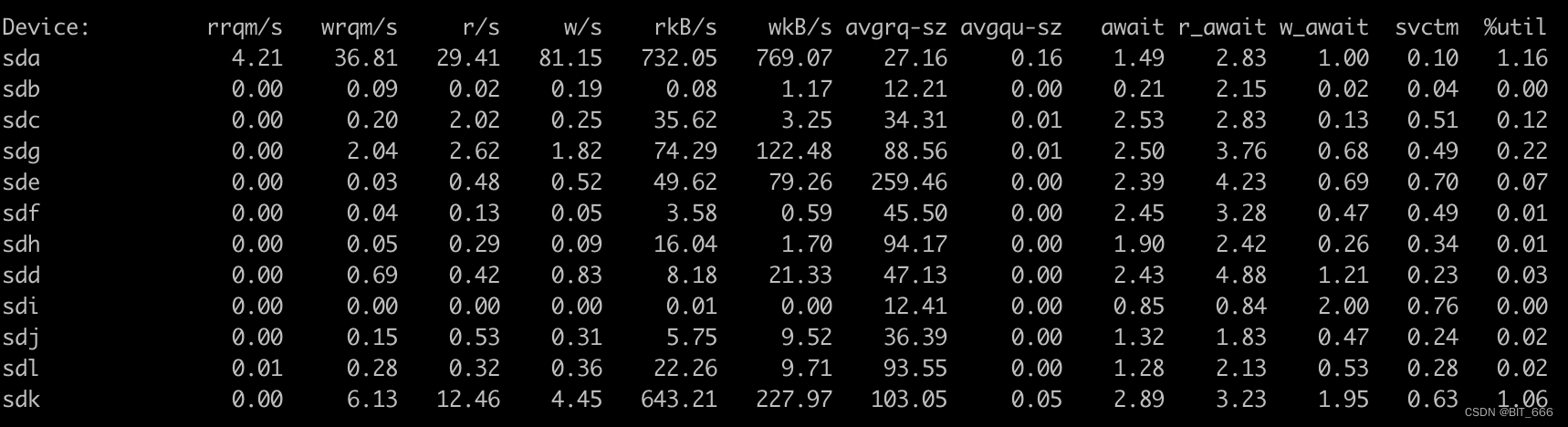
参数含义rrqm/s每s进行的读merge操作wrqm/s每s进行的写merge操作r/s每s完成的读 IO 设备次数w/s每s完成的写 IO 设备次数rkB/s每s读取 KB 字节数wkB/s每s写入 KB 字节数avgrq-sz平均每次设备 IO 操作的数据大小avgqu-sz平均 IO 队列长度await平均每次 IO 设备的等待时间r_await读 IO 请求设备的等待时间w_await写 IO 请求设备的等待时间svctm平均每次 IO 设备操作的服务时间%util每s中 IO 操作时间的占比
A.是否 IO 密集 / 瓶颈
一般可以参考 await,%util 参数,await 反应等待响应的时间,根据任务 IO 类型不同,也可关注 r_await 或者 w_await,其次 %util 参数比较直接,该值虽然反应的是 IO 操作时间的占比,但是 100% 时也并不代表当前发生 IO 瓶颈,只能说明当前 IO 任务比较密集,需要结合 await 或者 avgqu-sz 参数来判断任务是否 IO 瓶颈。
单独说一下 avgqu-sz,该参数代表平均 IO 队列长度,可以理解为超市买东西的队伍,当前队伍过长则可以认为当前 device 服务繁忙,反之服务空闲,普通 HDD 可能达到 4 的水平,而 SSD 则可以提高多倍以上,具体看 HDD 与 SSD 性能差异。
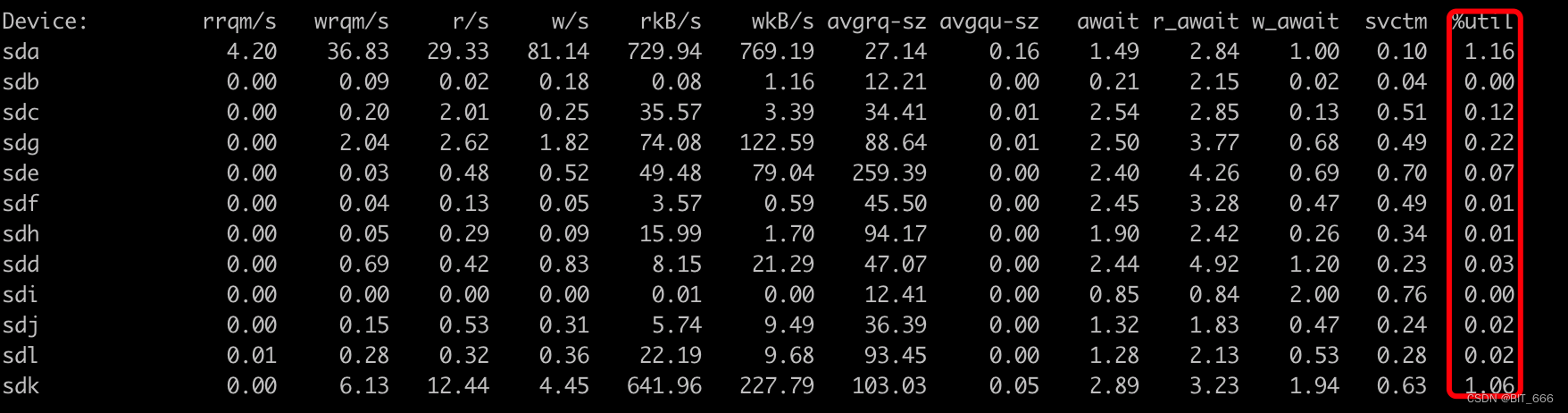
B.是否负载不均匀
一台机器下包含了 sda、sdb...、sdk 多台 Device标识该机器下多块磁盘,每台机器的多块磁盘是为了分担压力,均衡负载。可以直接查看各 Device 的 %util 参数,如果几个磁盘 %util 参数接近 100% 而其他 Device 百分比不高,则代表当前运行负载不均,一些 IO 密集的任务集中到几块磁盘上。
4.IO 场景分析
针对上述几种常见的场景简单分析下 IO 瓶颈的原因与解决方法,这里主要基于 HDD 集群场景,不考虑 HDD 直接更换 SSD 的大佬级操作,分析前可以先用 iotop 查看当前主要哪个任务占用 io 资源,随后查看 iostat 查看是否磁盘负载不均匀:
A.Flink 并行度低,执行机器资源不足造成 IO 瓶颈
- 任务并行度低,执行机器资源不足,这个最简单,增大并行度,提高负载的机器资源即可。
B.Flink 并行度高,执行机器集中造成几个单点机器 IO 瓶颈
- 这种需要均匀负载,控制任务不集中提交到某台或某几台机器的几个 Device 上。
C.Flink 并行度高,执行机器分散,状态访问频率过高,机器 IO 瓶颈
- 此处对应上面高 QPS 访问 EmbeddingRocksDB ValueState 的 get IO 瓶颈,该模式下首先需要分析是否负载均衡,如果负载均衡则需考虑增加机器或者修改状态后端存储
D.Flink 并行度高,执行机器分散,公用机群,他人任务 IO 密集导致机器 IO 瓶颈
- 该场景问题不在自己的程序,主要是公用集群下和其他同学的 IO 密集任务恰巧分配到一台机器上,造成自己的 IO 空间有限,最简单的方法是重启任务,尝试分配到新的机器上执行,如果想彻底摆脱该情况则申请独占队列资源,保证提交集群的机器只有自己的任务可以提交,避免公用
四.ValueState 大状态场景优化
下面基于最上面提到的 IO 瓶颈任务进行分析:
当前任务使用 ValueState 存储信息,使用 RocksDBStateBackend 作为状态后端,关于状态后端的选择可以参考:Flink - 最新 StateBackend 状态后端详解,该任务以 Kafka 作为源头,由于数据存在短时峰值增加了几十倍导致 ValueState 访问量过大:

1.Flink 如何实现负载均衡
Flink 支持通过 state.backend.rocksdb.localdir 配置 rocksdb TaskManager 上的多个磁盘,例如我要配置机器下的十个盘,则直接在 /data/flink/flink-version/conf/flink-conf.yaml 下配置即可:
state.backend.rocksdb.localdir: /data1/flink/rocksdb,/data2/flink/rocksdb,/data3/flink/rocksdb,/data4/flink/rocksdb,/data5/flink/rocksdb,/data6/flink/rocksdb,/data7/flink/rocksdb,/data8/flink/rocksdb,/data9/flink/rocksdb,/data10/flink/rocksdb
Flink On Yarn 模式下,调度会配置多台机器,和上面的会有所差别,这里只需要知道 Rocksdb 需要存储到多台负载的机器上即可,下面看看源码如何基于多台机器进行分配。
A.Job 初始化地址
该代码位于 org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend,上一篇文章也提到了,新版本下 RocksDBStateBackend 切换 API 为 EmbeddedRocksDBStateBackend
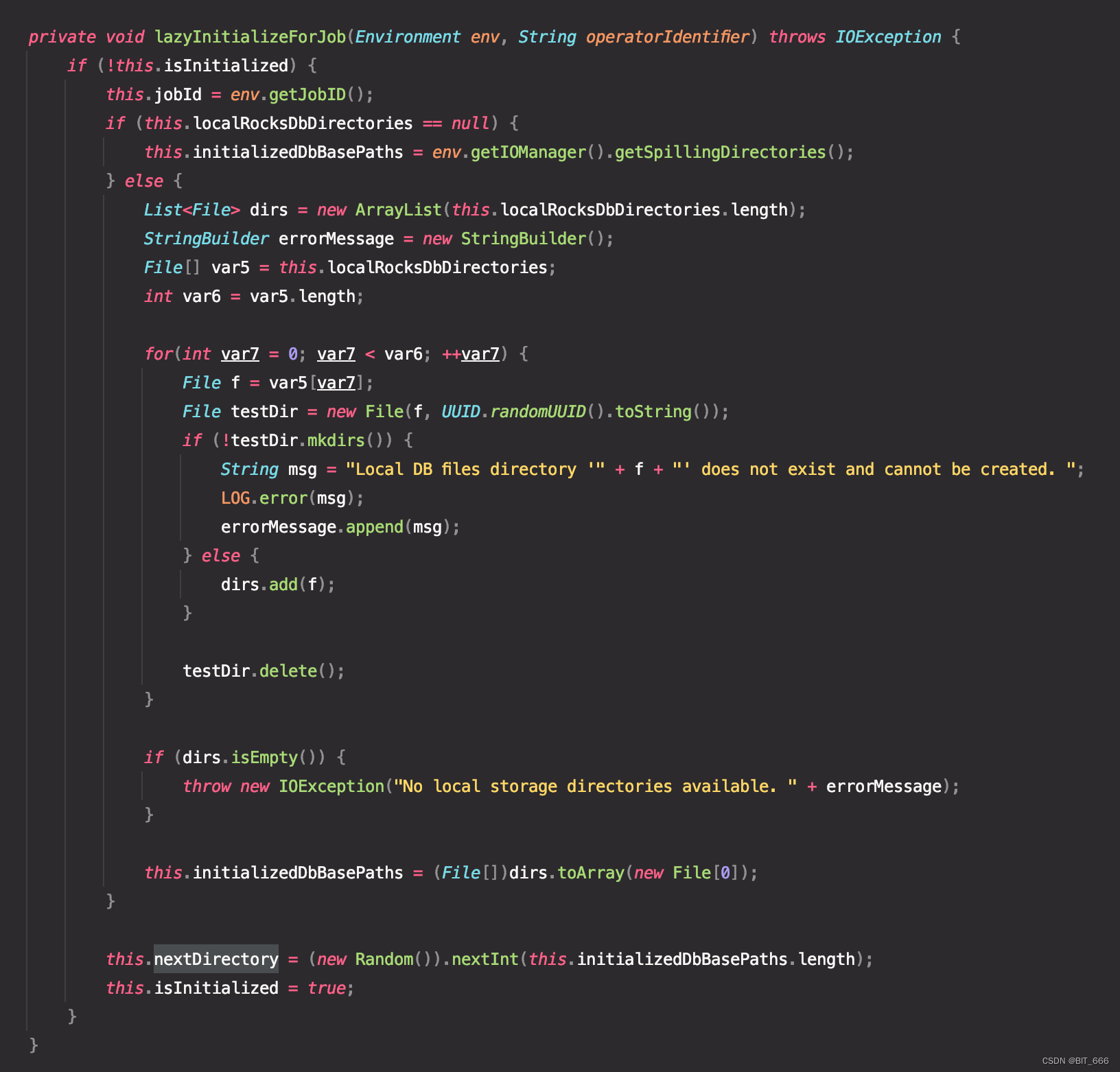
lazyInitialzeForJob 代码内直接看最下方 this.nextDirectory ,这里 initializedDbBasePaths 则为当前集群或者任务下可用的多个 DB 存储路径,通过 Random.next() 方法获取第一个路径的地址,所以这里通过 Random 随机分配 device,该模式下有一定概率使得多个任务 DB path 重合,一方面基于当前任务的并行度与资源申请,另一方面也基于当前 initializedDbBasePaths 初始化 device 的数量:
- 相同机器下,任务越多,并行度越高,越容易冲突
- 相同任务数量下,initializedDbBasePaths 数量越多,越不容易冲突
B.获取更多地址
lazyInitialzeForJob 方法初始化了起始 device 的地址,当任务并行度较高时,job 需要申请多个 device 地址,这里用到了 getNextStoragePath 方法,该方法基于 initializedDbBasePaths 与初始化好的 nextDirectory 决定后续的 DB path:

? : 表达式负责防止数组越界,可以看到基于当前 nextDIrectory 索引,后面新增的 device 都是基于 initializedDbBasePaths 递增循环的,到达末尾后更新 ni,重新遍历,当集群任务数量较大且 IO 整体压力相当的情况下,该分配模式可以发挥作用,当集群内任务较少时,可能出现冲突的可能,但概率不大,概率基数受 initializedDbBasePaths.length 影响。
2.其他负载方式
除了该负载方式,基于不同工业场景也可以采用其他分配调度策略,但是需要修改 Flink 源码的 lazyInitialzeForJob 与 getNextStoragePath 方法
A.全局均匀负载
集群上提交多个任务,源码中每个任务 Random 生成一个索引,假定有 N 个备选 path,则两个任务在某个点位冲突的概率为 1 / (N*2),如果考虑后续交叉的冲突概率则更为复杂,可以考虑引入全局变量控制每个任务获取的初始点位,例如维护一个全局的原子变量,该变量标记当前集群最新分配的 DB device 节点,第三方通信可以考虑 Zookeeper,原子变量可以使用 Java 原生的 AtomicInteger 也可以自己加锁实现方法:
val atomNum = new AtomicInteger()
var nextDirectory: Int = _
val initializedDbBasePaths: Array[File] = _
// initJob
nextDirectory = atomNum.intValue()
val path = initializedDbBasePaths(nextDirectory)
// nextDirectory
val nextIndex = atomNum.incrementAndGet()
val nextPath = initializedDbBasePaths(atomNum.intValue())
// updateIndex
if (atomNum.intValue().equals(length)) {
atomNum.set(0)
}
initJob 时 nextDirectory 索引不再使用 Random 而是获取 atomNum 的值,nextDirectory 则是直接累加 atomNum,最后判断 atomNum 的 value,如果其值达到 initializedDbBasePaths 数组边界则重新归0,重新调度。
B.压力均匀负载
上面介绍了 iostata 方法监控磁盘数据,iostat -x -d interval 最后的 interval 参数可以指定间隔监控机器相关压力,我们可以基于 await,%util 等参数构建综合指标,利用 Redis 等外部存储更新当前最小压力机器列表 :
val host = "host"
val port = 0
val socket: Jedis = new Jedis(host, port)
var initializedDbBasePaths: Array[File] = _
val until: Double = 0D
val await: Double = 0D
val combineIndicator = until + await
// initJob 获取最小 IO 的 device
val allIndicator = Array[Double]()
initializedDbBasePaths = initializedDbBasePaths.zip(allIndicator).sortBy(_._2).map(_._1)
socket.lpush("aliveDevice", "deviceFile")
// nextDirectory
val aliveDeviceList = socket.lrange("aliveDevice",0, -1)
val nextPath = aliveDeviceList.get(0)
初始化 Jedis 作为 Socket 存储可用 device 列表,综合指标可以结合 until 的百分数 + await 的数值,或者结合 iostat 构造更复杂的指标,基于 combineIndicator 综合指标进行排序并存储,根据 iostat 的 interval 更新最小负载机器 redis list,通过 lrange 获取完整列表,然后循环索引从压力小到压力大依次分配。不过该方法也存在一些问题,即 IO 可能存在瞬时过高的情况,结合 interval 的更新频率,combineIndicator 指标可能有一定欺骗性,所以该方法的关键就是构造综合评估指标 combineIndicator。
3.大状态优化
在均匀负载,机器资源固定的情况下,如果要对大状态任务优化,一种是减少 IO 压力,一种是提高 IO 吞吐,下面基于两种方案讲解,以下方案依旧基于上面给到的高瞬发 QPS kafka 案例:
A.减少 IO 等待
在 QPS 不变的情况下,如果想要降低压力,唯一的办法就是切换状态后端,由 EmbeddingStateBackend 切换为 HashMapStateBackend,由于 IO 由 TaskManager 的机器 IO 转换为 JVM heap 的内存 IO 且无需序列化,IO 的效率达到了质的提升,但是有两个前提:
- 状态大小可控:
RocksDB 突破 JVM 限制存储大量 ValueState,如果需要切换 HashMapStateBackend,需要保证状态的数量或大小不会无限制增加,即有界
- 内存资源充足:
由于大规模数量容量的 ValueState 由 TaskManager 本机切换至 JVM heap,因此需要 heap 分配足够多的内存,这里也对应上面的有界,因为如果状态无界,则总会有一个时刻 OOM 导致异常
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStateBackend(new HashMapStateBackend)
// 切换为 MemoryStateBackend
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage)
// 切换为 FsStateBackend
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage(path));
采用 HashMap 存储 ValueState,Fs 存储 Checkpoint ,该解决方案适合状态数量大,状态访问频率高,但状态总体容量有限的大状态场景。
B.提高 IO 吞吐
在 QPS 不变 且 状态后端无法切换的情况下,如果想要提高 IO 吞吐只能通过如下几个方法实现:
增加 state.backend.rocksdb.localdir 或集群 device 的数量
将公用集群切换为独占集群,独享每台 device IO
HHD 切换为 SSD
4.最终优化方案
本例高 Kafka QPS 最终采取方案1,减少 IO 压力实现。
A.计算 ValueState 总量
这里可以通过原有 RocksDBPath 下存储的 checkpoint 粗略估计任务的 ValueState 存储总量,这里注意序列化的压缩比例,或者通过 org.apache.spark.util.SizeEstimator 类对每个 ValueState 进行容量预估,再结合总量进行 Heap 量总算。
B.计算 TaskManger 使用量
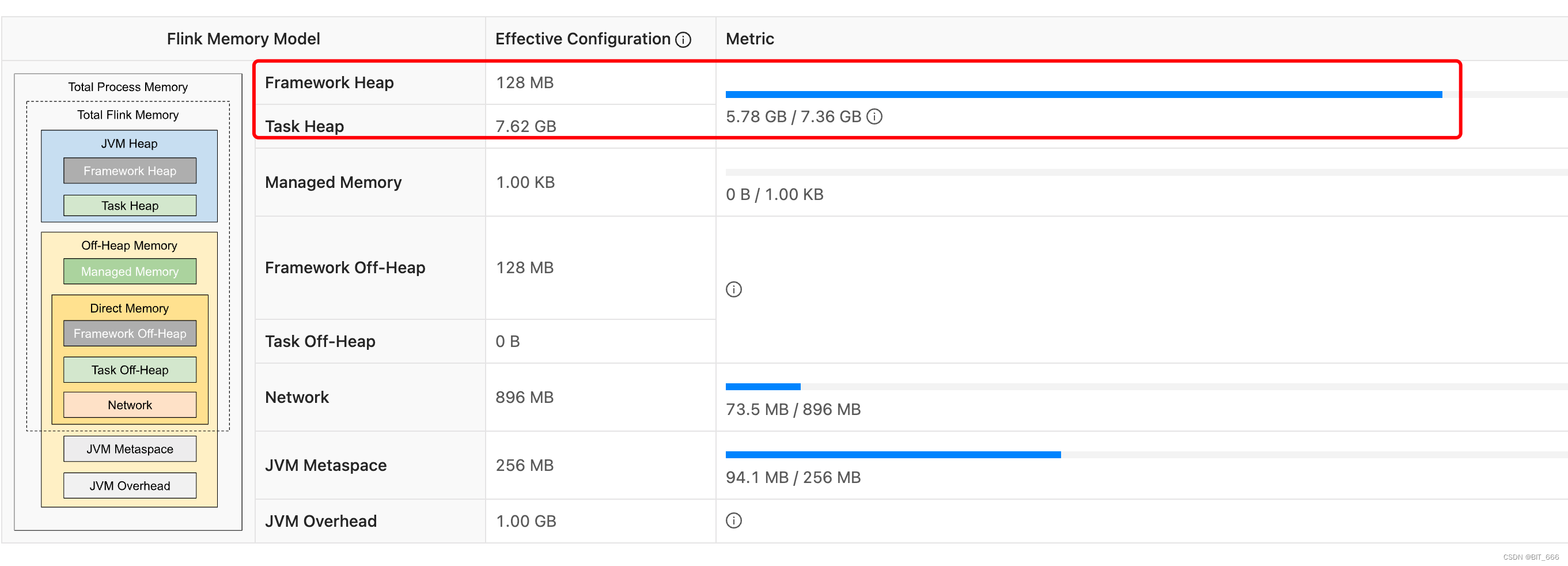
基于 Flink 内存模型参数 配置获得每个 TaskManager Heap 的大致容量,然后空余出冗余量,根据上面 ValueState 的总 Heap 量进行除法计算即可得到最终需要的 TaskManager 数量即 Flink Container 的数量。
C.优化效果
该任务 Source 和 Sink 均为 kafka,可以通过 Sink 端 kafka 的产出效率判断任务的 IO 吞吐量。
- 优化前
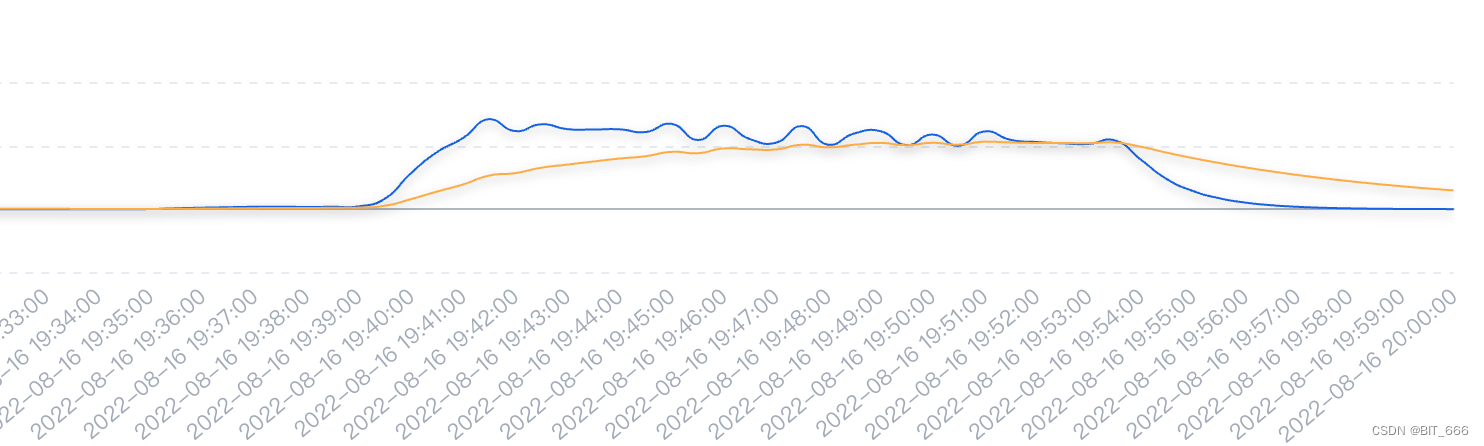
- 优化后 👍
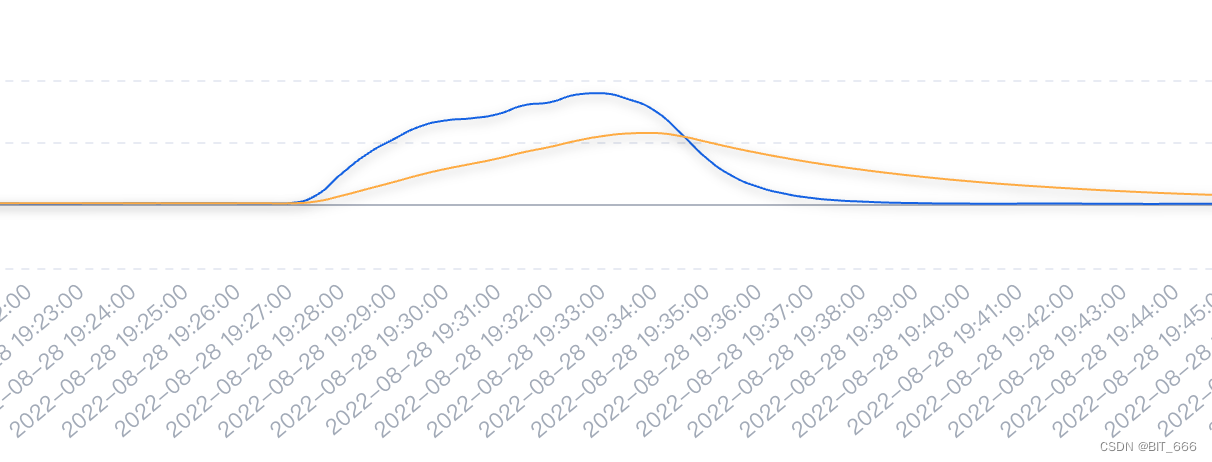
可以看到优化前由于 IO 瓶颈的限制,出库 kafka 的记录数量是先增加再保持到最后的下降,期间持平的量即为当前最大 IO 的量,优化为 HashMapStateBackend 后 IO 效率提高,出库 kafka 先增加后下降,没有出现平行的瓶颈期,处理周期也由原有的 15min + 缩短至 10min 左右,粗略估计效率提高了 33.3%+。
五.总结
本文主要基于 ValueState + RocksDBStateBackend 实例介绍了如下知识点:
- 如何通过 iotop 获取机器 IO 任务列表
- 如何通过 iostat 获取机器磁盘 IO 负载情况
- Flink RocksDB 如何实现均匀负载
- Flink 全局均匀、压力均匀负载方式思路
- Flink 大状态作业如何减小 IO 等待、增加 IO 吞吐
除此之外,本文一些讲解涉及到如下知识点,有需要的同学可以参考:
- Flink 内存模型详解
- Flink 状态后端详解
- Flink 有状态算子详解
版权归原作者 BIT_666 所有, 如有侵权,请联系我们删除。