
黑马程序猿的python学习视频:https://www.bilibili.com/video/BV1qW4y1a7fU/
===============================================================
1. pyspark定义

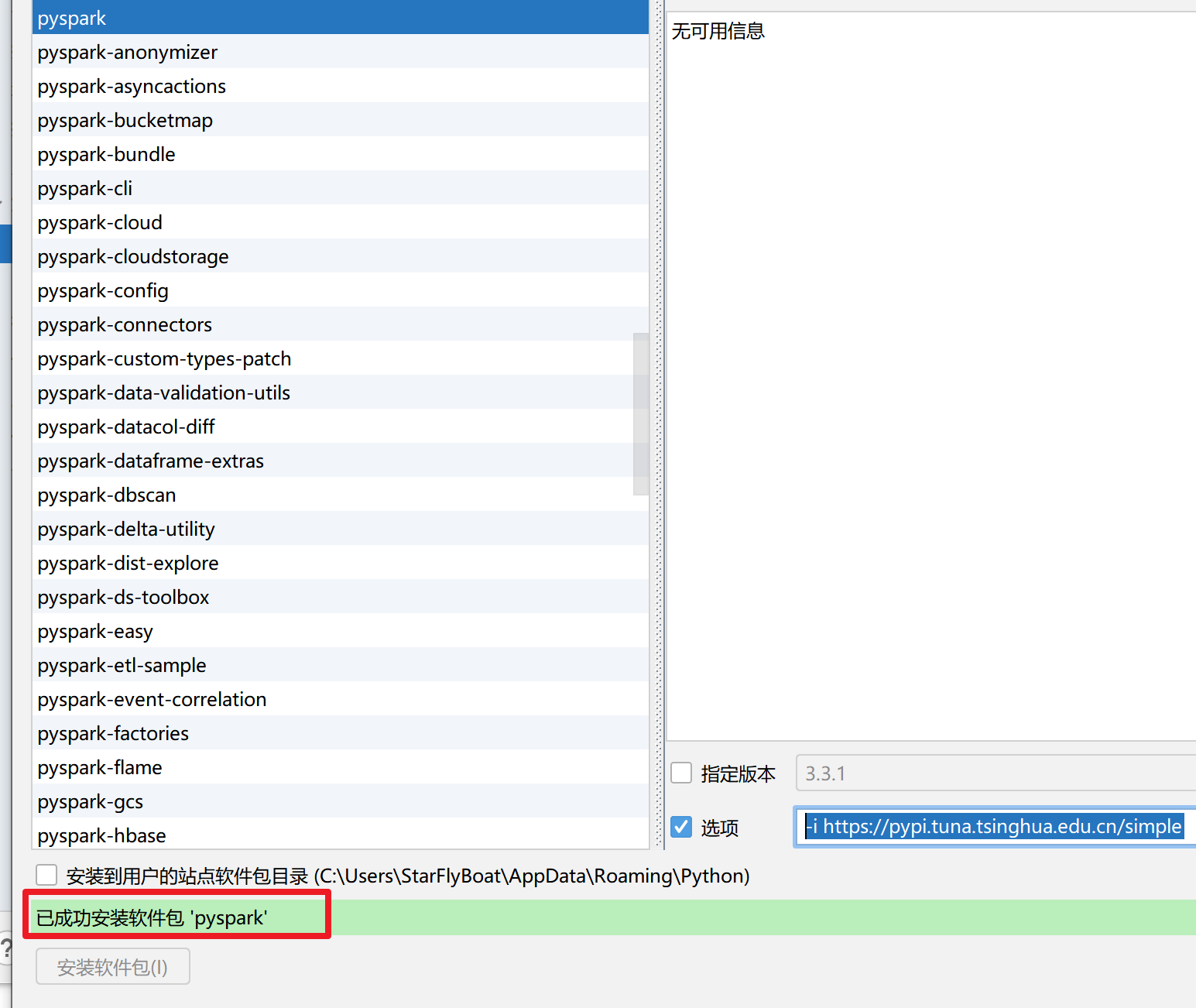
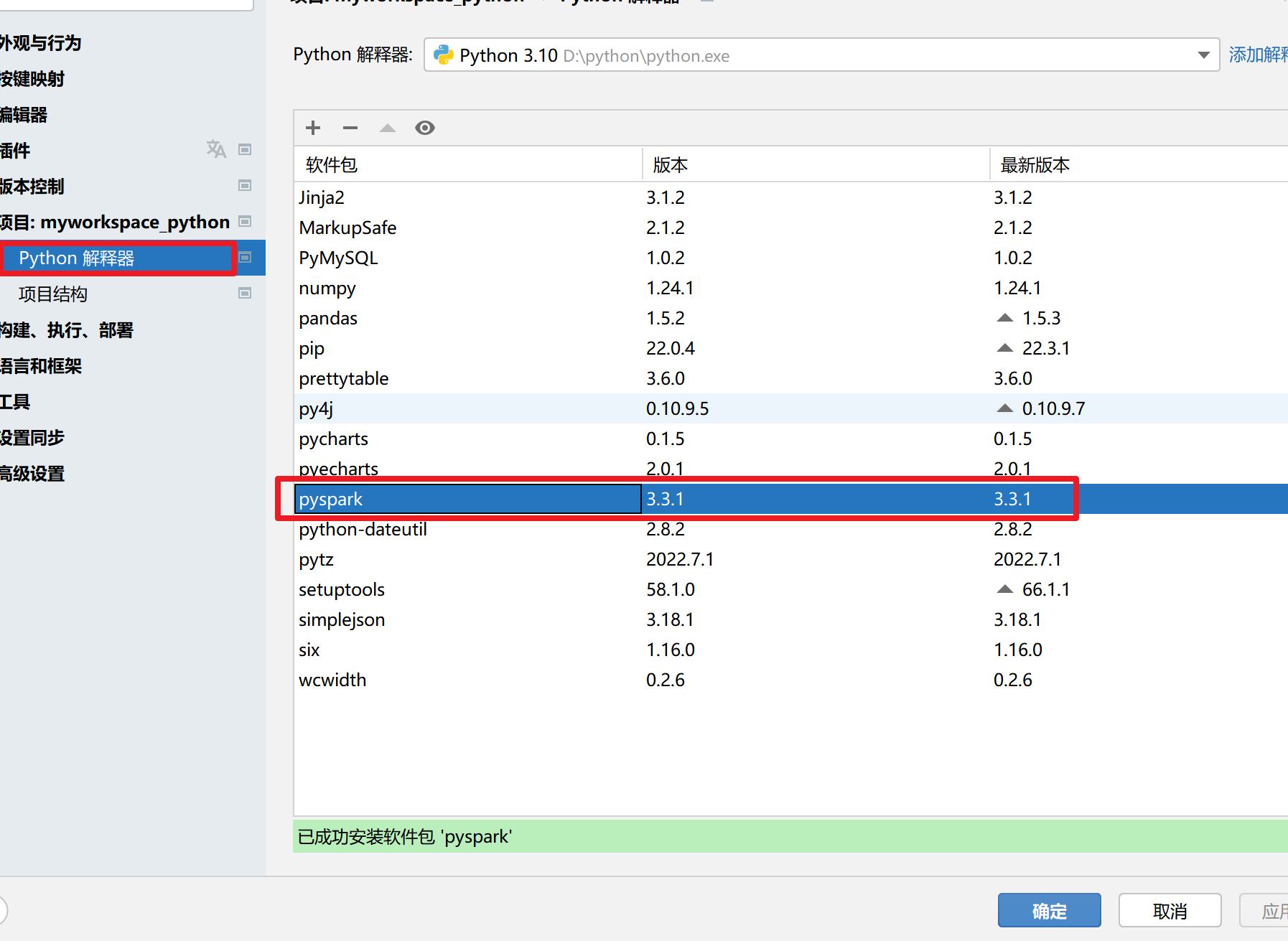
2. 下载
点击右下角版本 点击解释器设置
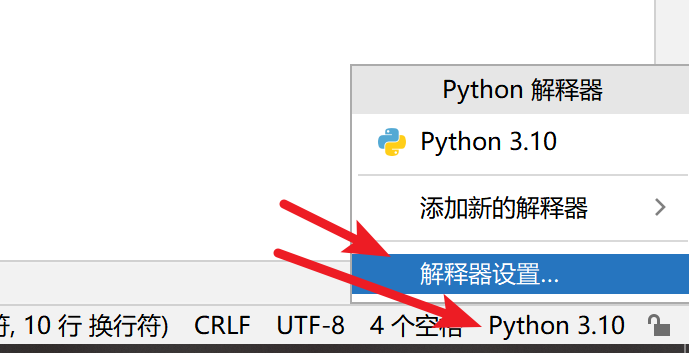
点击+号
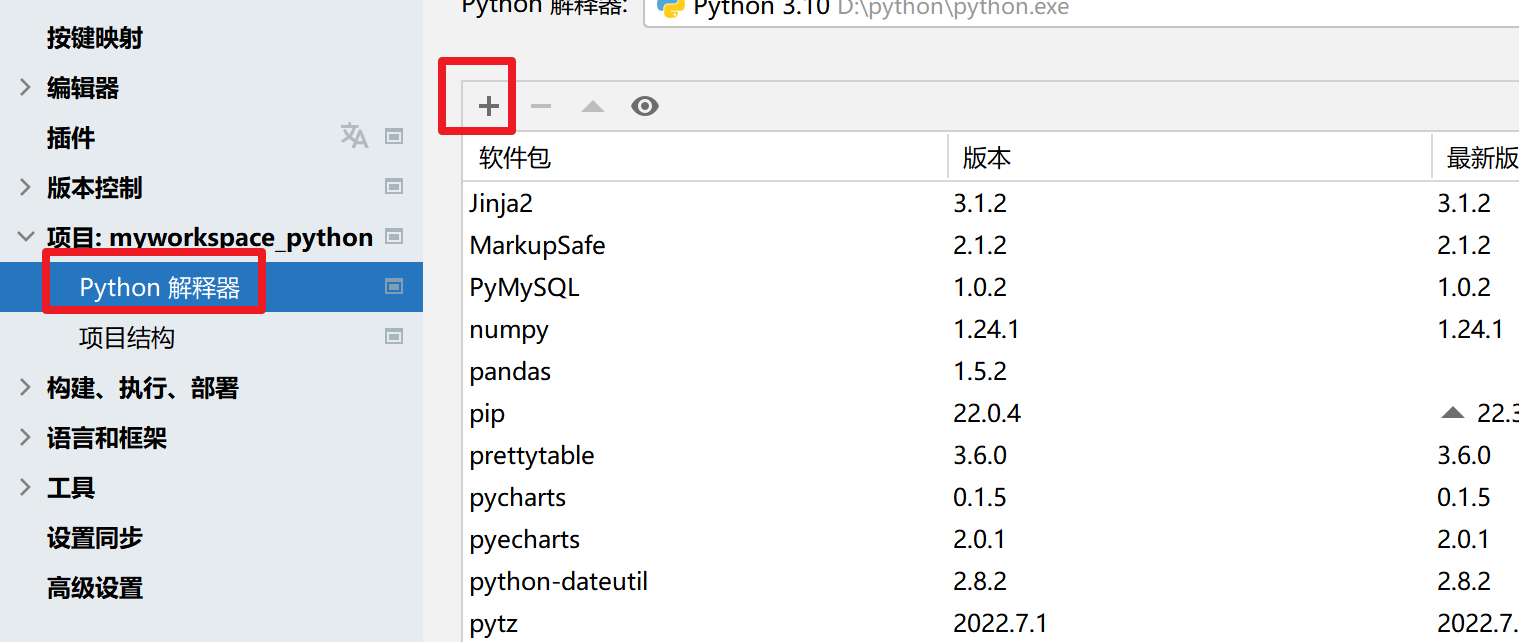
搜索pyspark 选择pyspark
勾选选项 在输入框中输入
-i https://pypi.tuna.tsinghua.edu.cn/simple
点击安装软件包
提示正在安装
等一两分钟就能安装完毕
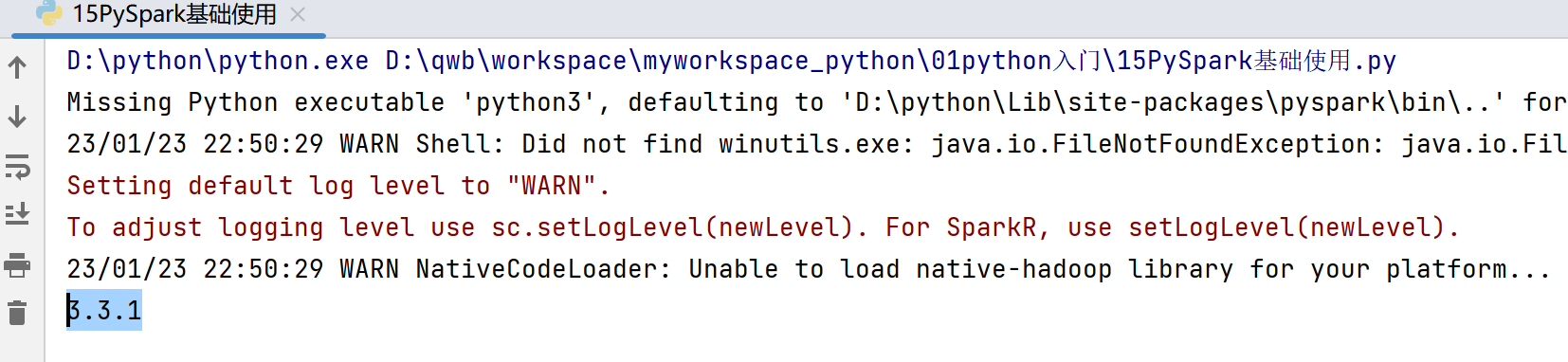
3. 获取PySpark版本号
*# *导包
from pyspark import SparkConf,SparkContext
*# 创建SparkConf*对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
*# 基于SparkConf类对象创建SparkContext*对象
sc = SparkContext(conf=conf)
*# 打印PySpark*的运行版本
print(sc.version)
*# 停止SparkContext对象的运行 (停止Spark*对象)
sc.stop()
3.3.1
4. 演示pyspark加载数据
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 通过parallelize方法将Python对象加载到Spark内 成为RDD*对象
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize((1, 2, 3, 4, 5))
rdd3 = sc.parallelize("abcdefg")
rdd4 = sc.parallelize({1, 2, 3, 4, 5})
rdd5 = sc.parallelize({"key1": "value1", "key2": "value2"})
*# 如果要查看RDD里边有什么内容 需要用Collect()*方法
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
['a', 'b', 'c', 'd', 'e', 'f', 'g']
[1, 2, 3, 4, 5]
['key1', 'key2']
5. 演示pyspark读取txt文档信息
在D盘准备一个test的txt文档

from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 通过textFile方法,读取文件数据加载到Spark内,成为RDD*对象
rdd = sc.textFile("D:/test.txt")
print(rdd.collect())
sc.stop()
23/01/23 23:15:35 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
['hello', 'world', 'world', '嘿嘿']
6. RDD对象是什么?为什么要使用它
RDD对象称之为分布式弹性数据集,是PySpark中数据计算的载体,他可以:
- 提供数据存储
- 提供数据计算的各类方法
- 数据计算的方法,返回值依旧是RDD(RDD迭代计算)
后续对数据进行各类计算,都是基于RDD对象进行
7. 如何输入数据到Spark(即得到RDD对象)
通过SparkContext的parallelize的成员方法,将Python数据容器转换为RDD对象
通过SparkContext的textFile成员方法,读取文本文件得到RDD对象
8. 数据计算
1. 通过map方法将全部数据乘以10
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 准备一个rdd*
rdd = sc.parallelize([1,2,3,4,5])
*# 通过map方法将全部数据乘以10*
rdd2 = rdd.map(lambda x:x*10)
print(rdd2.collect())
sc.stop()
[10, 20, 30, 40, 50]
2. map算子概念
接受一个处理函数,可用lambda表达式快速编写
对RDD内的元素逐个处理,并返回新的RDD
3. flatMap方法
将rdd中的单词全部提取出来 解除嵌套
注意:
计算逻辑和map一样
但是比map方法多出了解除一层嵌套的功能
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 准备一个RDD*
rdd = sc.parallelize(["111 222 333","444 555 666","777 888 999 000"])
*# 将rdd*中的单词全部提取出来 解除嵌套
rdd2 = rdd.flatMap(lambda x:x.split(" "))
print(rdd2.collect())
sc.stop()
['111', '222', '333', '444', '555', '666', '777', '888', '999', '000']
4. reduceByKey方法
功能:针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作
如下案例实现了对男女两个组的分组,并且分别计算2个组的和
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 准备一个RDD*
rdd = sc.parallelize([("男", 99), ("男",88), ("女",77), ("女",99), ("女",66),])
*# *求男生和女生两个组的成绩之和
rdd2 = rdd.reduceByKey(lambda a, b: a+b)
print(rdd2.collect())
sc.stop()
[('男', 187), ('女', 242)]
5. 练习案例1-单词计数
需求:读取txt文档信息,计算各个单词出现的次数
text.txt文档数据
hello hello
world world
啦啦 啦啦 啦啦
嘿嘿 嘿嘿 嘿嘿
代码和结果如下
*# *构建执行环境入口对象
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 2.*读取数据文件
rdd = sc.textFile("D:/test.txt")
*# 3. *取出全部单词
word_add = rdd.flatMap(lambda x:x.split(" "))
*# 4. 将所有的单词 都转成二元元组 单词为key,value设置成1 *方便计数
word_with_one_rdd = word_add.map(lambda x:(x,1))
*# 5. *分组求和
result_add = word_with_one_rdd.reduceByKey(lambda a, b:a+b)
*# 6. *打印输出结果
print(result_add.collect())
sc.stop()
[('world', 2), ('啦啦', 3), ('hello', 2), ('嘿嘿', 3)]
6. filter过滤:获取想要的数据
filter算子概念:接受一个处理函数,可以用lambda快速编写
函数对RDD数据逐个处理,得到True的保留至返回值的RDD中
以下案例是:获取数组中的偶数,把奇数过滤掉
*# *构建执行环境入口对象
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 准备一个rdd*
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9])
*# 对RDD*的数据进行过滤
rdd2 = rdd.filter(lambda num:num%2==0)
print(rdd2.collect())
sc.stop()
[2, 4, 6, 8]
7. distinct去重方法
概念:完成对RDD内数据的去重操作
*# *构建执行环境入口对象
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 准备一个rdd*
rdd = sc.parallelize([1,1,1,2,2,2,3,3,4,5,6,6,6])
*# 对RDD*的数据进行去重
rdd2 = rdd.distinct()
print(rdd2.collect())
sc.stop()
[1, 2, 3, 4, 5, 6]
8. sortBy排序方法
概念:接收一个处理函数,可用lambda快速编写
函数表示用来决定排序的依据
可以控制升序或降序
全局排序需要设置分区数为1
案例如下:对学生的成绩进行降序排序
第一个参数:取分数
第二个参数:设置False 说明是降序
第三个参数:设置为1
*# *构建执行环境入口对象
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 准备一个rdd*
rdd = sc.parallelize([('张三',99),('李四', 77),('王五', 88),('赵六', 100),('七七', 87)])
*# *对结果进行排序
rdd2 = rdd.sortBy(lambda x:x[1], ascending=False, numPartitions=1)
print(rdd2.collect())
sc.stop()
[('赵六', 100), ('张三', 99), ('王五', 88), ('七七', 87), ('李四', 77)]
9. 数据输出
1. 输出为python对象
1. collect:将RDD内容转换成list
rdd.collect():返回值是一个list
2. reduce:对RDD内容进行自定义聚合
reduce算子,对RDD进行两两聚合
*# *构建执行环境入口对象
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 准备一个rdd*
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
num = rdd.reduce(lambda a,b:a+b)
print(rdd2)
sc.stop()
55
3. take算子:取出RDD前N个元素组成list
概念:取出RDD中的前N个元素,组成list返回
*# *构建执行环境入口对象
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 准备一个rdd*
rdd = sc.parallelize([('张三',99),('李四', 77),('王五', 88),('赵六', 100),('七七', 87)])
*# 取出rdd中前两个元素,组成list*返回
rdd2 = rdd.take(2)
print(rdd2)
sc.stop()
[('张三', 99), ('李四', 77)]
4. count算子:统计RDD元素个数
*# *构建执行环境入口对象
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/python/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
*# 准备一个rdd*
num = sc.parallelize([('张三',99),('李四', 77),('王五', 88),('赵六', 100),('七七', 87)]).count()
print(num)
sc.stop()
5
2. 输出到文件中
saveAsTextFile算子:将RDD的数据写入到文本文件中
支持本地写出,hdfs等文件系统
版权归原作者 星银色飞行船 所有, 如有侵权,请联系我们删除。