
MapReduce
1、优缺点
优点:易于编程、良好的扩展性、高容错性
缺点:不适合做实时计算、不适合做流式计算(要求数据是静态的)、不适合DAG(有向图)计算
2、MapReduce的阶段分类【掌握】
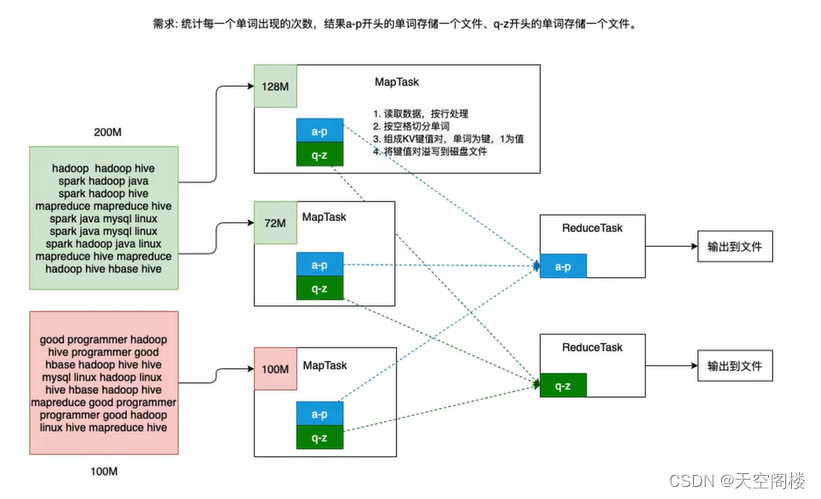
MapReduce的程序在运行的过程中,一般分为两个阶段:Map阶段和Reduce阶段
2.1、第一阶段:Map
第一阶段,也称之为Map阶段。这个阶段会有若干个MapTask实例,完全并行运行,互不相干。每个MapTask会读取分析一个InputSplit(输入分片,简称分片)对应的原始数据。计算的结果数据会临时保存到所在节点的本地磁盘里。
该阶段的编程模型中会有一个map函数需要开发人员重写,map函数的输入是一个<key,value>对,map函数的输出也是一个<key,value>对,key和value的类型需要开发人员指定。
2.2、第二阶段:Reduce
第二阶段,也称为Reduce阶段。这个阶段会有若干个ReduceTask实例并发运行,互不相干。但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。一个ReudceTasK会从多个MapTask运行节点上fetch自己要处理的分区数据。经过处理后,输出到HDFS上。
该阶段的编程模型中有一个reduce函数需要开发人员重写,reduce函数的输入也是一个<key,value>对,reduce函数的输出也是一个<key,value>对。这里要强调的是,reduce的输入其实就是map的输出,只不过map的输出经过shuffle技术后变成了<key,List>而已。
注意:MapReduce编程模型只能包含一个map阶段和一个reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行执行。
3、IDE 编写MapReduce 实现wordCount
3.1、在IDE中需要依次创建WordCountMapper、WordCountReducer、WordCountDriver
示例中的包路径:com.ms.mshadoop.mapreduce
packagecom.ms.mshadoop.mapreduce;importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Mapper;importjava.io.IOException;/**
* Map阶段开始的时候,每一个MapTask都会逐行读取分片中的数据,并将读取到的数据进行扭转形成 keyIn, valueIn
* 由于计算程序需要到不同节点之间进行移动,因此涉及到 keyIn/valueIn/keyOut/valueOut都必须支持序列化的类型
* Hadoop提供了一套序列化的机制 writeable
* byte => ByteWritable
* short => ShortWritable
* int => IntWritable
* long => LongWritable
* float => FloatWritable
* double => DoubleWritable
* boolean => BooleanWritable
* String => Text
* <p>
* keyIn:读取到的 行数据 中 首字母 的偏移量 需要设计为LongWritable
* valueIn:读取到的 行数据 需要设计为Text
* <p>
* keyOut:经过逻辑处理后,需要写出的键值对中 键的类型 Text
* valueOut:经过逻辑处理后,需要写出的键值对中 值的类型 IntWritable
*/publicclassWordCountMapperextendsMapper<LongWritable,Text,Text,IntWritable>{/**
* 每当读取到一行数据时,将其扭转为keyIn和valueIn,调用该方法
* @param key 行偏移量
* @param value 行记录
* @param context 操作上下文
* @throws IOException
* @throws InterruptedException
*/@Overrideprotectedvoidmap(LongWritable key,Text value,Mapper<LongWritable,Text,Text,IntWritable>.Context context)throwsIOException,InterruptedException{//1、将读取的行数据,切割出每一个单词// 正则表达式中\s匹配任何空白字符,包括空格、制表符、换页符等等, 等价于[\f\n\r\t\v]// 而\s+则表示匹配任意多个上面的字符String[] words = value.toString().split("\\s+");//2、遍历每一个单词for(String word : words){//3、为每一单词配上(value,1) 组成键值对 写出
context.write(newText(word),newIntWritable(1));}}}
packagecom.ms.mshadoop.mapreduce;importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Reducer;importjava.io.IOException;/**
* keyIn: Map阶段输出的键类型
* valueIn: Map阶段输出的值类型
* <p>
* keyOut: 最终输出的键值对中,键的类型
* valueOut: 最终输出的键值对中,值的类型
*/publicclassWordCountReducerextendsReducer<Text,IntWritable,Text,IntWritable>{/**
* Reduce阶段逻辑处理
*
* @param key 键,Map阶段输出的键
* @param values 输入进这个方法之前,MapReduce会按照键进行分组,将相同的键对应的所有值聚合到一起
* @param context 上下文
* @throws IOException
* @throws InterruptedException
*/@Overrideprotectedvoidreduce(Text key,Iterable<IntWritable> values,Reducer<Text,IntWritable,Text,IntWritable>.Context context)throwsIOException,InterruptedException{//1、定义一个变量,来记录单子出现的总次数int timeCount =0;for(IntWritable value : values){
timeCount += value.get();}
context.write(key,newIntWritable(timeCount));}}
packagecom.ms.mshadoop.mapreduce;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;importjava.io.IOException;/**
* 驱动类:主要功能
* 1、创建Job
* 2、Job属性配置
* 3、Job提交
*/publicclassWordCountDriver{publicstaticvoidmain(String[] args)throwsIOException,InterruptedException,ClassNotFoundException{//1、创建JobConfiguration conf =newConfiguration();
conf.set("fs.defaultFS","hdfs://hadoop01:9820");Job job =Job.getInstance();//2、设置Job属性//在MapReduce程序中,用于处理Map任务的类
job.setMapperClass(WordCountMapper.class);//在MapReduce程序中,用于处理Reduce任务的类
job.setReducerClass(WordCountReducer.class);//在MapReduce程序中,用于处理驱动的类
job.setJarByClass(WordCountDriver.class);//Map阶段输出的键值对的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);//Reduce阶段输出的键值对的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);//设置输入和输出的路径FileInputFormat.setInputPaths(job,newPath(args[0]));FileOutputFormat.setOutputPath(job,newPath(args[1]));//3、提交任务System.exit(job.waitForCompletion(true)?0:-1);}}
注意:需要生成多个文件数量时,代码中增加
//设置ReduceTask的数量,决定了最终生成的文件数量。这个数量最好和分区的数量保持一致。/**
* 1、如果ReduceTask的数量多于分区的数量:会出现多余的ReduceTask空占资源,
* 不去处理任何的数据,浪费资源,且生成空的结果文件
* 2、如果ReduceTask的数量少于分区的数量:会出现某个分区的数据暂时无法处理,
* 需要等待某ReduceTask任务处理结束后再1处理这个分区的数据,无法高效并发
*/
job.setNumReduceTasks(2);
3.2 执行程序
1、IDE中将项目打包成jar,上传到linux 的hadoop集群中
2、运行程序
# hadoop jar 打包上传到服务器的jar 程序中WordCountDriver的包路径 /输入文件路径 /输出文件路径
hadoop jar MapReduceApi-1.0-SNAPSHOT.jar com.ms.mshadoop.mapreduce.WordCountDriver /input /output
4、分区器(Partitioner)
需求:将单词a-g开头的存一个文件,h-o存一个文件,其他存一个
4.1、在IDE中需要依次创建WordCountMapper、WordCountReducer、WordCountDriver、WordCountPartitioner,其中WordCountMapper、WordCountReducer与3.1相同
packagecom.ms.mshadoop.partitioner;importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Partitioner;/**
* Partitioner : 分区器,可以将map阶段输出的键值对,按照规则进行分区
* 泛型,对应的是map方法输出的键值对类型
*/publicclassWordCountPartitionerextendsPartitioner<Text,IntWritable>{/**
* 每一个map方法输出的键值对,都会调用该方法进行分区,来确定分区号
* @param text map 阶段输出的 键
* @param intWritable map 阶段输出的 值
* @param i ReduceTask 的数量
* @return 分区号,从零开始,且必须连续
*/@OverridepublicintgetPartition(Text text,IntWritable intWritable,int i){char c = text.toString().charAt(0);if(c >='a'&& c <='g'){return0;}elseif(c >='h'&& c <='o'){return1;}else{return2;}}}
WordCountDriver中增加如下代码
//应用分区器
job.setPartitionerClass(WordCountPartitioner.class);//设置ReduceTask的数量,决定了最终生成的文件数量。这个数量最好和分区的数量保持一致。/**
* 1、如果ReduceTask的数量多于分区的数量:会出现多余的ReduceTask空占资源,
* 不去处理任何的数据,浪费资源,且生成空的结果文件
* 2、如果ReduceTask的数量少于分区的数量:会出现某个分区的数据暂时无法处理,
* 需要等待某ReduceTask任务处理结束后再1处理这个分区的数据,无法高效并发
*/
job.setNumReduceTasks(3);
5、IDE运行MapReduce的模式
在IDEA中运行MapReduce的程序,可以选择计算资源,也可以选择文件系统
计算资源:mapreduce.framework.name
local:使用本地计算资源(CPU、内存)
yarn:使用集群的计算资源
文件系统:fs.defaultFS
hdfs://hadoop01:9820 使用分布式文件系统
file:/// 使用本地文件系统
本地调试时可使用local模式进行,正常推荐使用yarn模式进行
5.1、local 模式测本地文件
原理:
1、将MapReduce的任务资源调度设置为local,不使用YARN进行资源调度
2、将文件系统设置为本地文件系统,不使用HDFS
Configuration conf =newConfiguration();
conf.set("mapreduce.framework.name","local");//设置为本地运行模式,任务不会在YARN上运行
conf.set("fs.defaultFS","file:///");//设置为本地文件系统,不使用HDFS。Job job =Job.getInstance(conf );//设置输入和输出的路径FileInputFormat.setInputPaths(job,newPath("/输入:本地文件路径"));FileOutputFormat.setOutputPath(job,newPath("/输出:本地文件路径"));
5.2、local 模式测集群文件
原理:
1、将MapReduce的任务资源调度设置为local,不使用YARN进行资源调度。
2、将文件系统设置为HDFS
System.setProperty("HADOOP_USER_NAME","root");//设置hadoop的操作用户Configuration conf =newConfiguration();
conf.set("mapreduce.framework.name","local");//设置为本地运行模式,任务不会在YARN上运行
conf.set("fs.defaultFS","hdfs://hadoop01:9820");//设置为分布式文件系统Job job =Job.getInstance(conf );//设置输入和输出的路径FileInputFormat.setInputPaths(job,newPath("/输入:hdfs文件路径"));FileOutputFormat.setOutputPath(job,newPath("/输出:dhfs文件路径"));
5.3、YARN模式测集群
原理:
1、将MapReduce的任务资源调度设置为YARN
2、将文件系统设置为HDFS
System.setProperty("HADOOP_USER_NAME","root");//设置hadoop的操作用户//1、创建JobConfiguration conf =newConfiguration();//local 模式测本地文件/*conf.set("mapreduce.framework.name","local");//设置为本地运行模式,任务不会在YARN上运行
conf.set("fs.defaultFS","file:///");//设置为本地文件系统,不使用HDFS。*///local 模式测集群文件/*conf.set("mapreduce.framework.name","local");//设置为本地运行模式,任务不会在YARN上运行
conf.set("fs.defaultFS","hdfs://hadoop01:9820");//设置为分布式文件系统*///yarn 模式测集群文件
conf.set("mapreduce.framework.name","yarn");//设置为本地运行模式,任务不会在YARN上运行
conf.set("yarn.resourcemanager.hostname","hadoop01");//设置ResourceManager
conf.set("fs.defaultFS","hdfs://hadoop01:9820");//设置为分布式文件系统
conf.set("yarn.app.mapreduce.am.env","HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.6");//用于指定MapReduce应用程序的ApplicationMaster(AM)启动时的环境变量。
conf.set("mapreduce.map.env","HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.6");//用于指定MapReduce应用程序的Map启动时的环境变量。
conf.set("mapreduce.reduce.env","HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.6");//用于指定MapReduce应用程序的Reduce启动时的环境变量。
conf.set("hadoop.security.authentication","simple");
conf.set("mapreduce.app-submission.cross-platform","true");//跨平台提交任务
注意事项:
在上述的配置都完成后,将程序打jar包,然后将jar包添加到classpath,才可以运行程序
在jar包上右键-> Add As Library
6 Hadoop 序列化
packagecom.ms.mshadoop.writable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.io.Writable;importjava.io.DataInput;importjava.io.DataOutput;importjava.io.IOException;importjava.io.Serializable;publicclassStudentimplementsWritable,Serializable{privateString name;privateint age;// private Text remarks;publicStudent(){}publicStudent(String name,int age,Text remarks){this.name = name;this.age = age;// this.remarks = remarks;}/**
* 序列化:将内存对象,序列化为一个字节序列
* @param dataOutput
*/@Overridepublicvoidwrite(DataOutput dataOutput)throwsIOException{//该方法中依次将所有属性序列化//当属性非hadoop中的序列类型时//将String 序列化
dataOutput.writeUTF(name);//将int 序列化
dataOutput.writeInt(age);//当属性为hadoop中的序列化类型时// remarks.write(dataOutput);}/**
* 反序列化:将字节序列转 内存对象
* 注意:反序列化时,读取属性顺序 必须 和序列化时顺序一致
* @param dataInput
*/@OverridepublicvoidreadFields(DataInput dataInput)throwsIOException{//当属性非hadoop中的序列类型时//将String 反序列化
name = dataInput.readUTF();//将int 反序列化
age = dataInput.readInt();//当属性为hadoop中的序列化类型时// remarks.readFields(dataInput);}}packagecom.ms.mshadoop.writable;importorg.apache.hadoop.io.Text;importjava.io.*;publicclassTest{publicstaticvoidmain(String[] args)throwsIOException{Student student =newStudent("张三丰",100,newText("11111111"));File file =newFile("C:\\Users\\xazyh\\Desktop\\1111.txt");ObjectOutputStream outputStream =newObjectOutputStream(newFileOutputStream(file));
outputStream.writeObject(student);
outputStream.close();File file1=newFile("C:\\Users\\xazyh\\Desktop\\2222.txt");DataOutputStream dataOutputStream =newDataOutputStream(newFileOutputStream(file1));
student.write(dataOutputStream);
dataOutputStream.close();}}

7 Mapreduce 实现统计流量
packagecom.ms.mshadoop.phoneFlow;importorg.apache.hadoop.io.Writable;importjava.io.DataInput;importjava.io.DataOutput;importjava.io.IOException;publicclassPhoneFlowBeanimplementsWritable{privateString phone;privateint flowDown;privateint flowUp;publicPhoneFlowBean(){}publicPhoneFlowBean(String phone,int flowDown,int flowUp){this.phone = phone;this.flowDown = flowDown;this.flowUp = flowUp;}@Overridepublicvoidwrite(DataOutput dataOutput)throwsIOException{
dataOutput.writeUTF(phone);
dataOutput.writeInt(flowDown);
dataOutput.writeInt(flowUp);}@OverridepublicvoidreadFields(DataInput dataInput)throwsIOException{
phone = dataInput.readUTF();
flowDown = dataInput.readInt();
flowUp = dataInput.readInt();}publicintgetSumFlow(){return flowDown + flowUp;}publicStringgetPhone(){return phone;}publicvoidsetPhone(String phone){this.phone = phone;}publicintgetFlowDown(){return flowDown;}publicvoidsetFlowDown(int flowDown){this.flowDown = flowDown;}publicintgetFlowUp(){return flowUp;}publicvoidsetFlowUp(int flowUp){this.flowUp = flowUp;}}
packagecom.ms.mshadoop.phoneFlow;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Mapper;importjava.io.IOException;publicclassPhoneFlowMapperextendsMapper<LongWritable,Text,Text,PhoneFlowBean>{@Overrideprotectedvoidmap(LongWritable key,Text value,Context context)throwsIOException,InterruptedException{String line = value.toString();//根据数据格式进行数据分割String[] split = line.split("\t");//手机号String phone = split[0];//下行流量String flowDown = split[1];//上行流量String flowUp = split[2];PhoneFlowBean phoneFlowBean =newPhoneFlowBean(phone,Integer.parseInt(flowDown),Integer.parseInt(flowUp));//写入 K2 V2
context.write(newText(phone),phoneFlowBean);}}
packagecom.ms.mshadoop.phoneFlow;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Reducer;importjava.io.IOException;publicclassPhoneFlowReudcerextendsReducer<Text,PhoneFlowBean,Text,Text>{@Overrideprotectedvoidreduce(Text key,Iterable<PhoneFlowBean> values,Reducer<Text,PhoneFlowBean,Text,Text>.Context context)throwsIOException,InterruptedException{//总下行流量int sumFlowDown =0;//总上行流量int sumFlowUp =0;for(PhoneFlowBean value : values){
sumFlowDown += value.getFlowDown();
sumFlowUp += value.getFlowUp();}String flowInfo =String.format("总上行流量:%d,总下行流量:%d,总流量:%d。", sumFlowUp, sumFlowDown,(sumFlowUp + sumFlowDown));//写入 K3 V3
context.write(key,newText(flowInfo));}}
packagecom.ms.mshadoop.phoneFlow;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;importjava.io.IOException;publicclassPhoneFlowDirver{publicstaticvoidmain(String[] args)throwsIOException,InterruptedException,ClassNotFoundException{Configuration configuration =newConfiguration();
configuration.set("fs.defaultFS","file:///");
configuration.set("mapreduce.framework.name","local");Job job =Job.getInstance(configuration);
job.setMapperClass(PhoneFlowMapper.class);
job.setReducerClass(PhoneFlowReudcer.class);
job.setJarByClass(PhoneFlowDirver.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PhoneFlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);//设置输入和输出的路径FileInputFormat.setInputPaths(job,newPath("输入文件路径"));//为防止文件已存在,可先进行判断,存在则删除文件FileOutputFormat.setOutputPath(job,newPath("输出文件路径"));System.exit( job.waitForCompletion(true)?0:1);}}
版权归原作者 天空阁楼 所有, 如有侵权,请联系我们删除。