
创建虚拟机及导入安装包
使用软件:VMware Workstation Pro
系统:Liunx
环境:Count OS 7
链接:https://pan.baidu.com/s/1uia69iL9Uf3WcHyV2qOI-Q?pwd=2022
提取码:2022 (这个是所需要用到的Jdk安装包和Hadoop安装包)
注:从开始安装Jdk到最后搭建伪分布式环境,我本人是全程在root用户下进行的主要是为了防止权限不够的原因
- 首先第一步新建虚拟机点击左上角文件→新建虚拟机
这里选择典型,然后点击下一步

这里选择稍后安装操作系统,然后点击下一步。
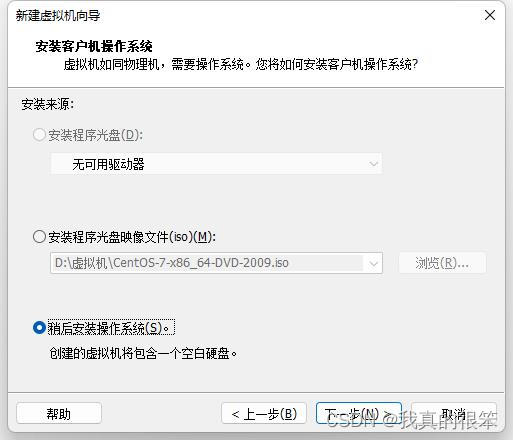
这里选择Linux操作系统版本选择CentOS 7 64位(这里你使用的是Linux中CentOS 7 64位的系统之后你下载导入的所有安装包必须为64位的)32位的同理。
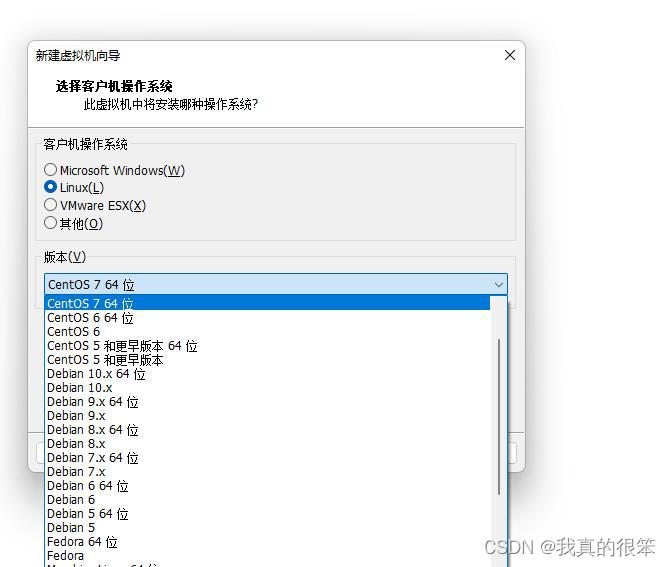
这里的名称可以随便起我们这里就叫dayuanzhong把路径的话也可以改,不过我用的是默认路径
接下来选择多个文件夹内存方面搭建伪分布式环境20G是足够的了。
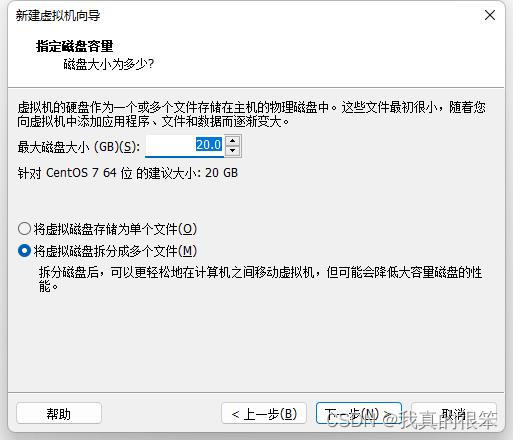
这里直接点击完成
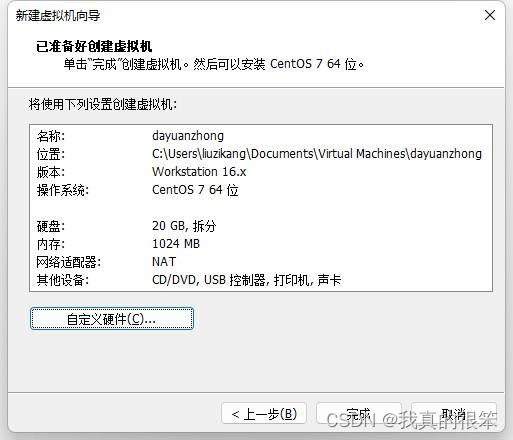
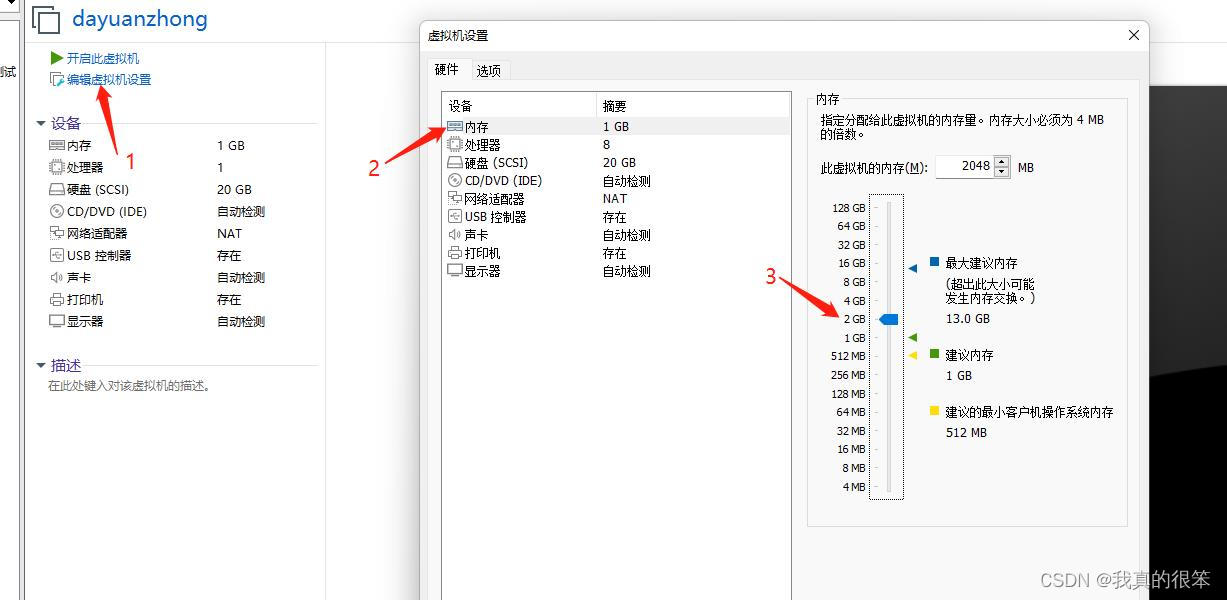
下一步点击虚拟机编辑点击内存设置为2G
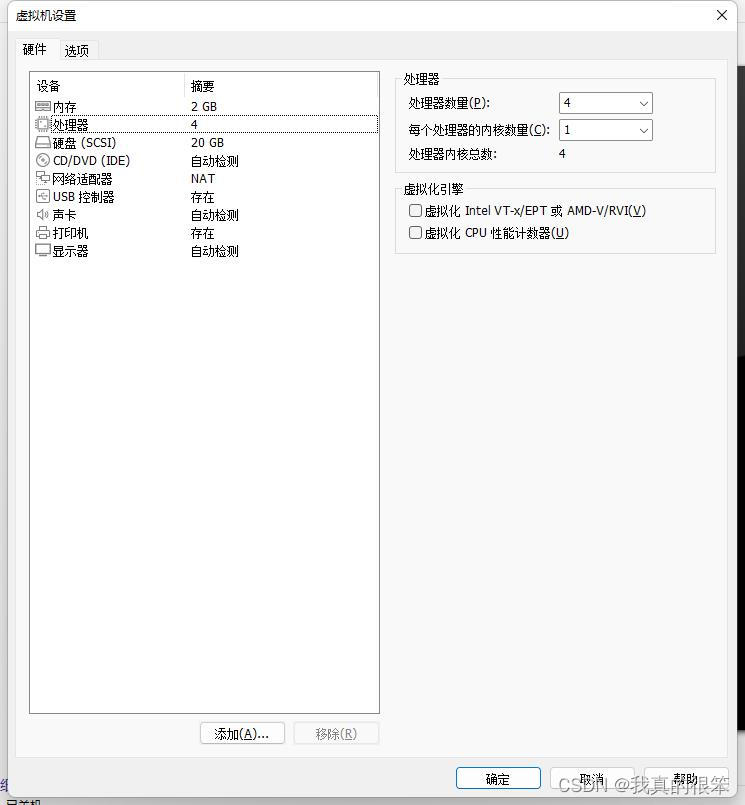
然后再点击处理器,将处理器数量设置为4个然后点击完成。
然后点击CD/DVD使用ISO映像文件选择2009点击确定,下一步启动dayuanzhong
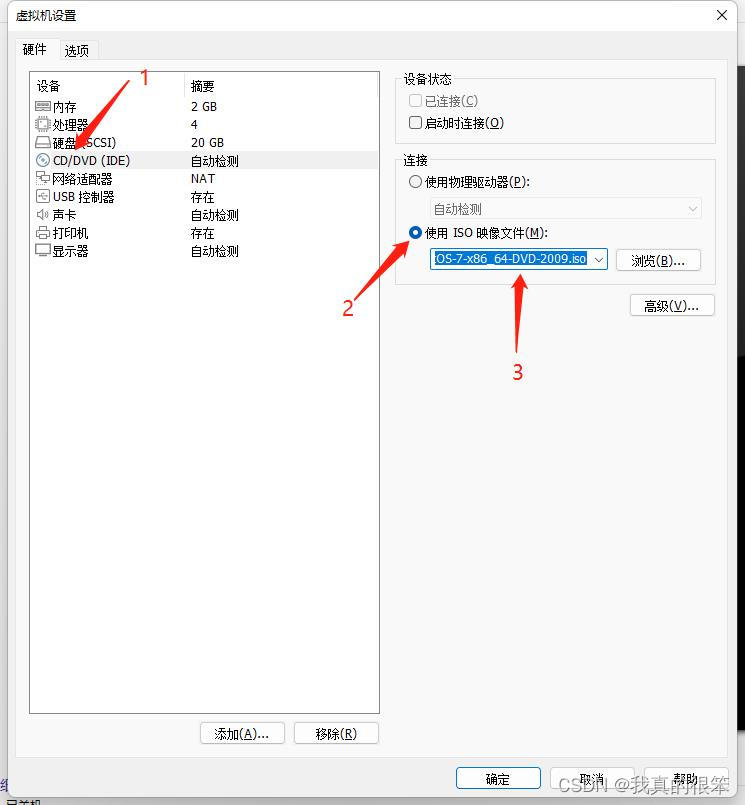
** 这里一定要选择第一个**
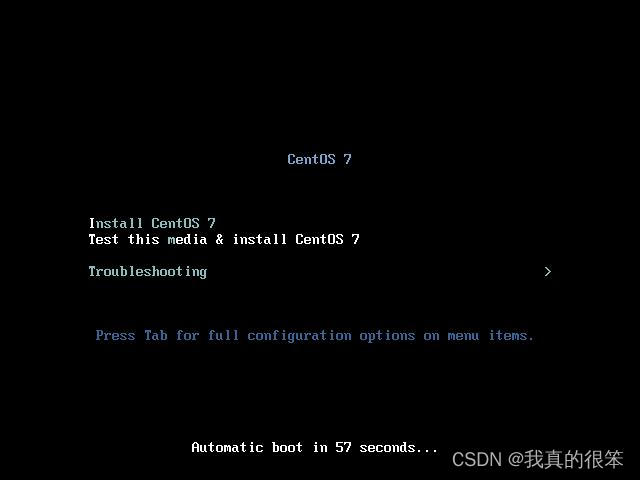
这里的安装语言选择默认的第一个 直接Continue
接下里我们一步步来设置虚拟机
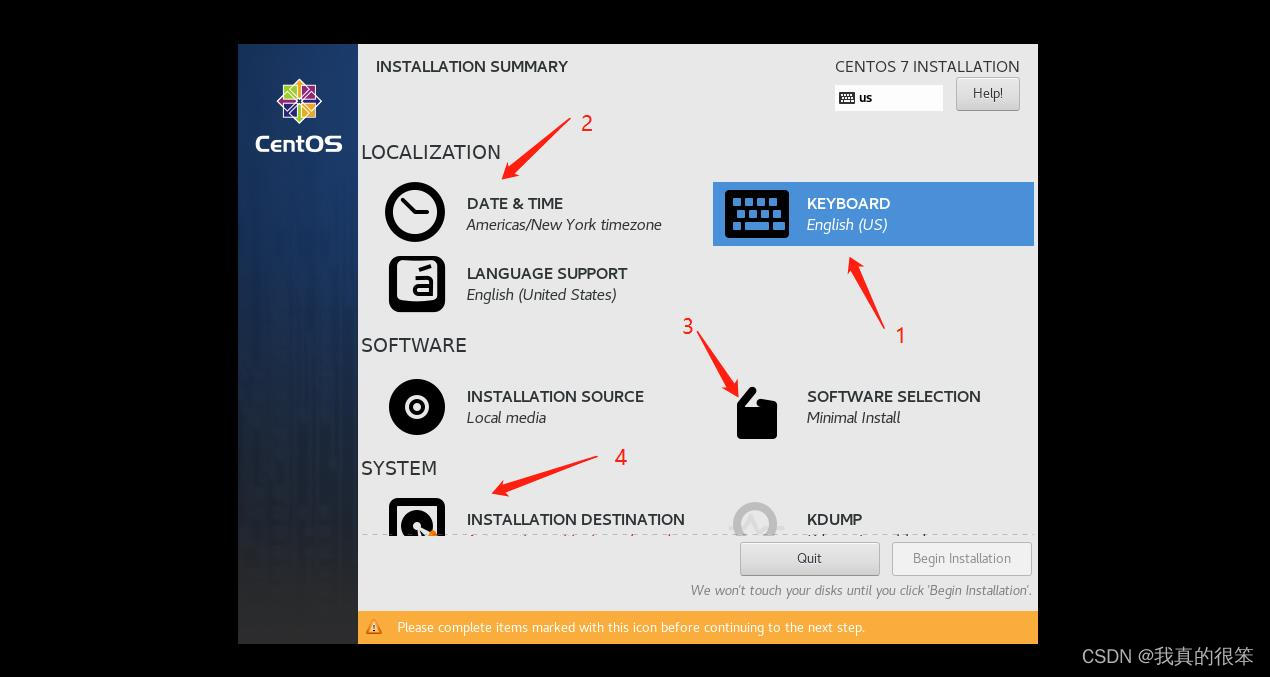
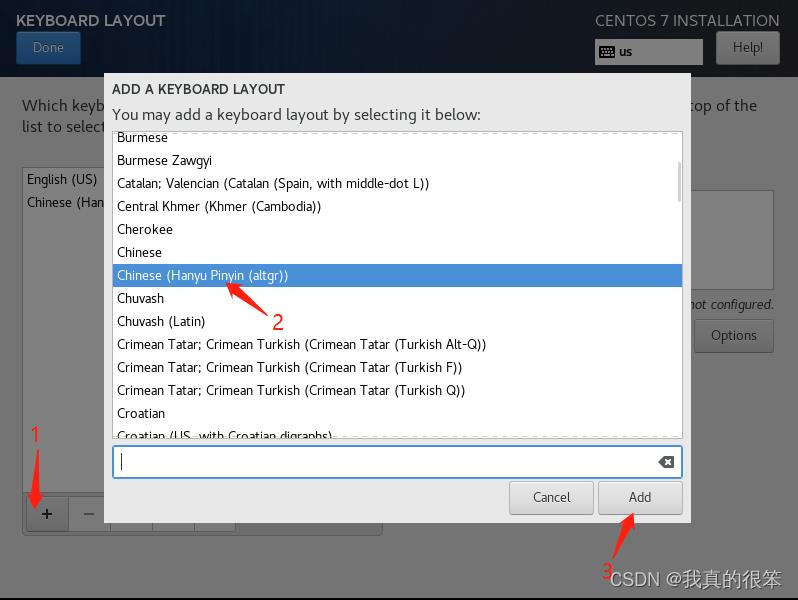
第一步键盘输入
分3.1步走战略 第一步点击加号 第二步找到chinese(pinyin)并选择 第三步点击Add添加
第3.1不Done保存退出
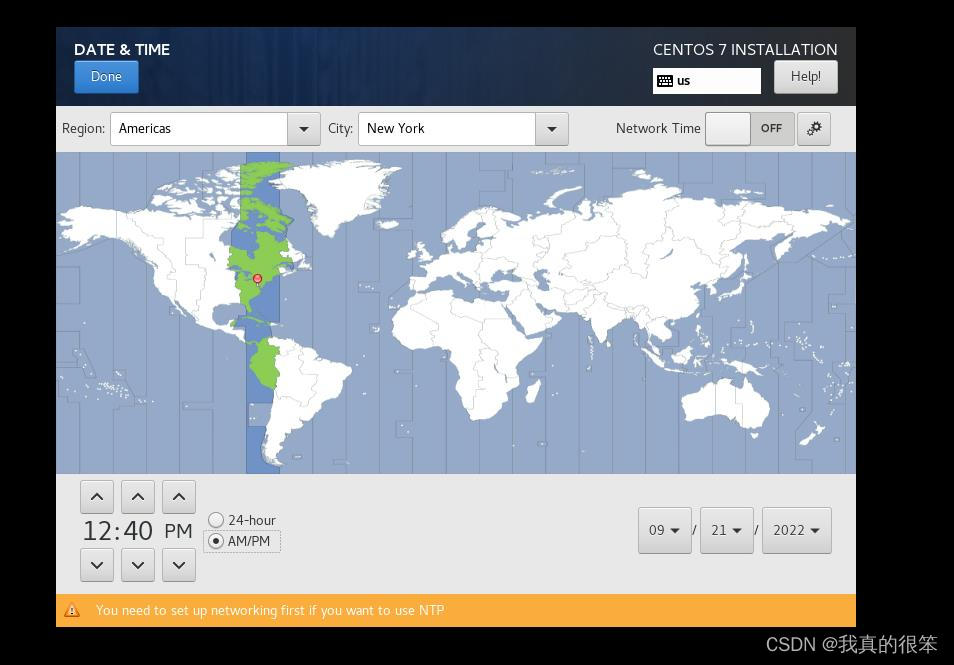
第二个时间
进去后直接点Done出来就行
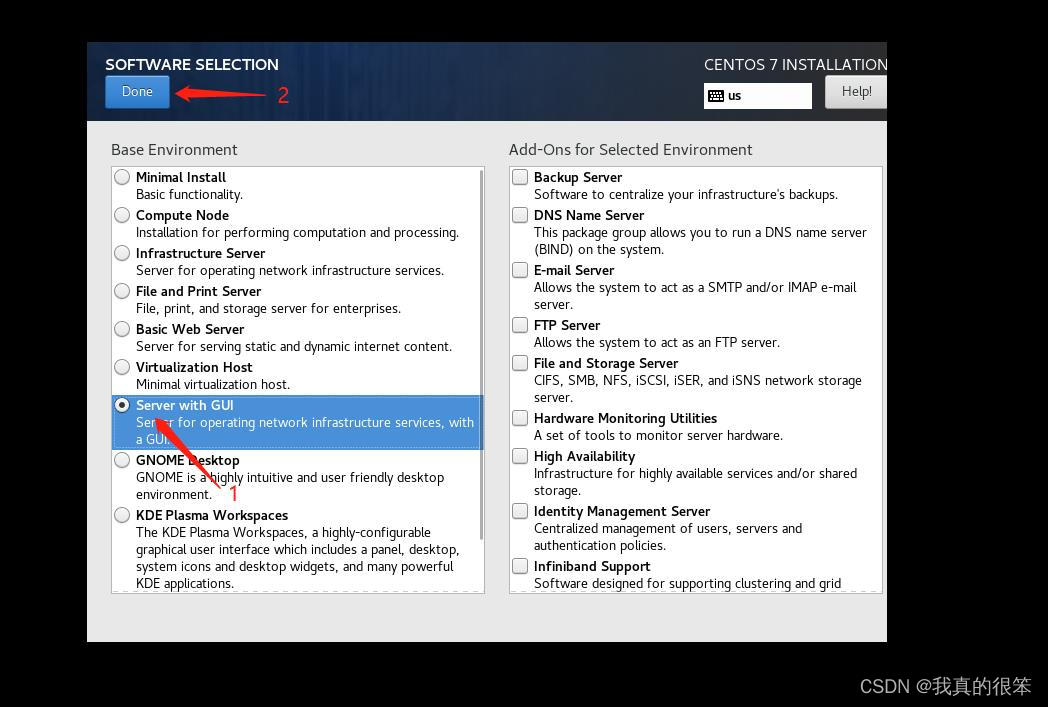
第三步
点进去后选择GUI然后点击Done就ok了
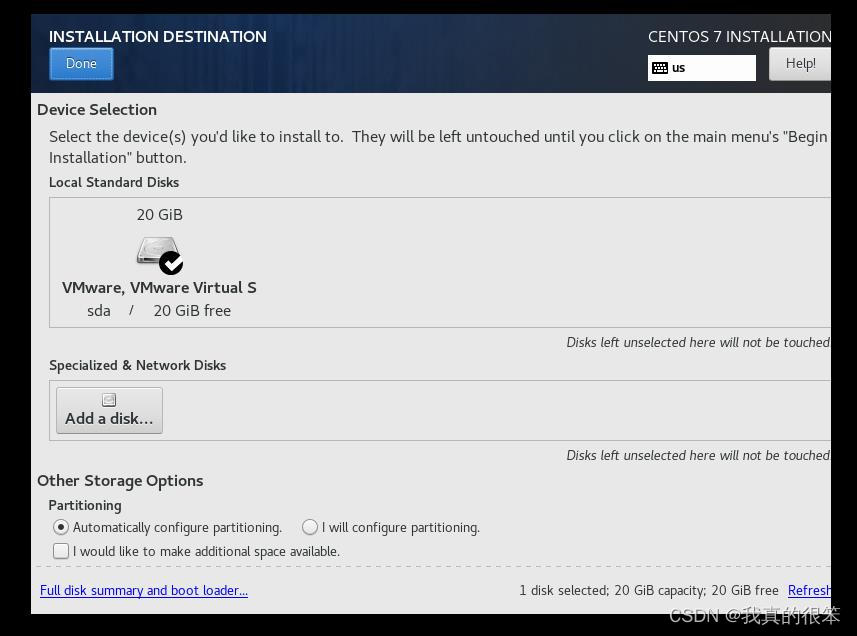
第四步
这个和那个时间一样点进去后再点击Done出来就可以了
之后就是网络配置
首先点击NETWORK&HOST NAME进入到里面
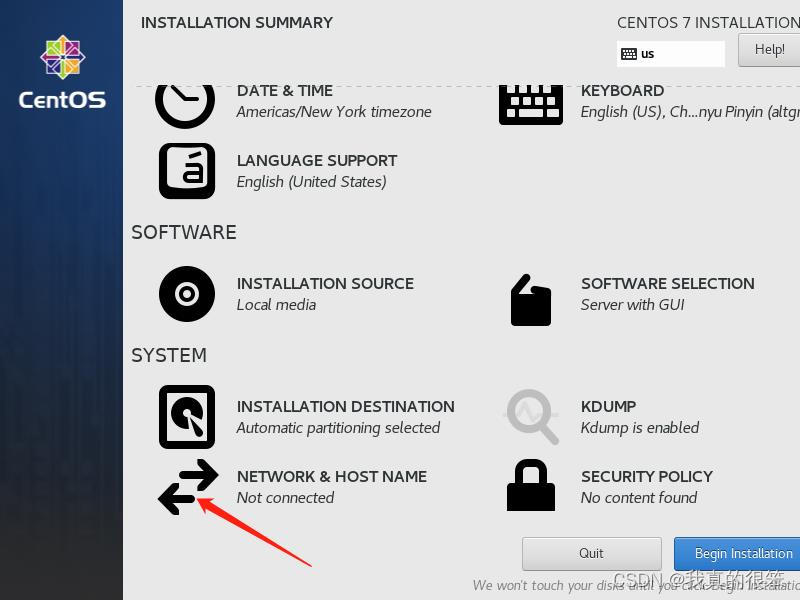
进去之后打开nes33网络然后点击Done退出即可
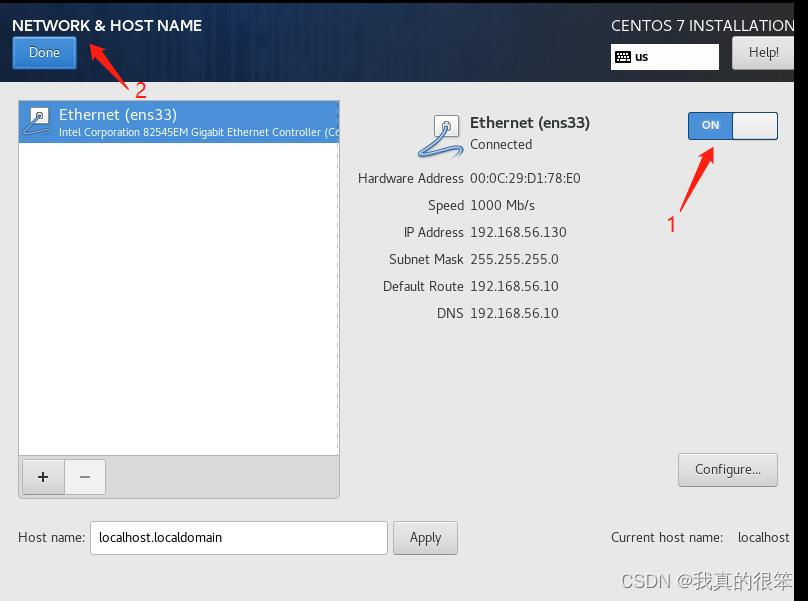 然后点击下一步
然后点击下一步
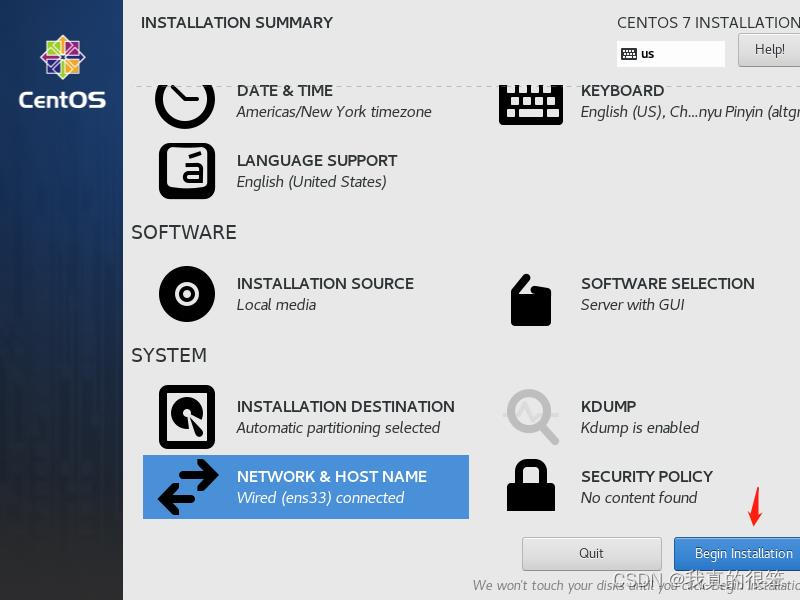
这里要等一会,在等待的时候可以先设置root密码,另一个不用管他
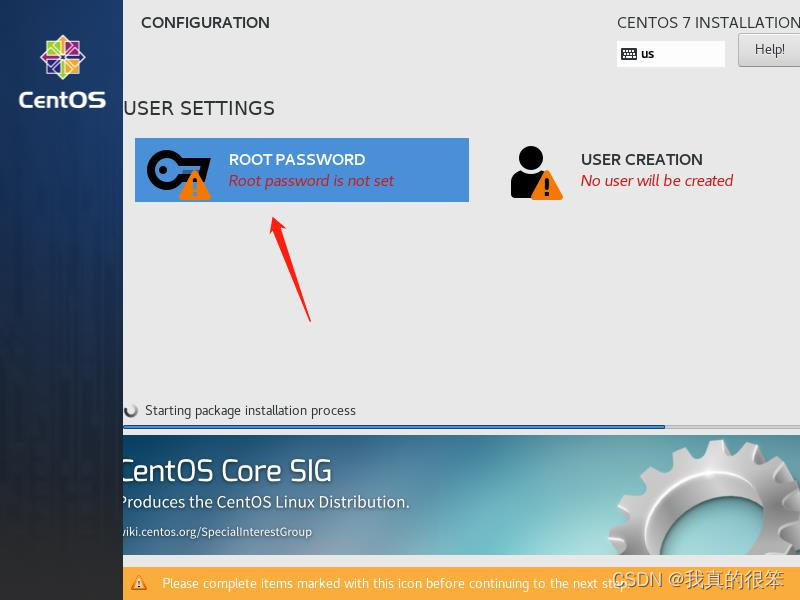
然后这里密码使用123456不用管他同不同意直接双击Done
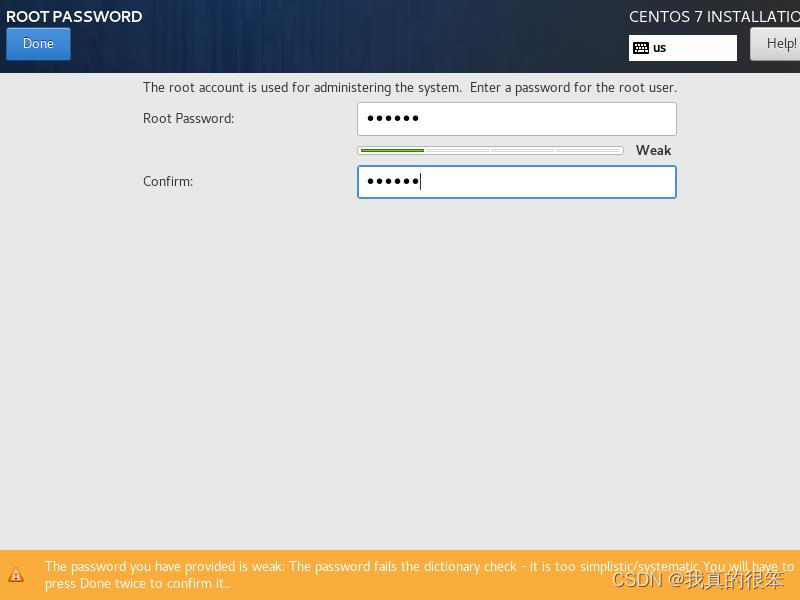
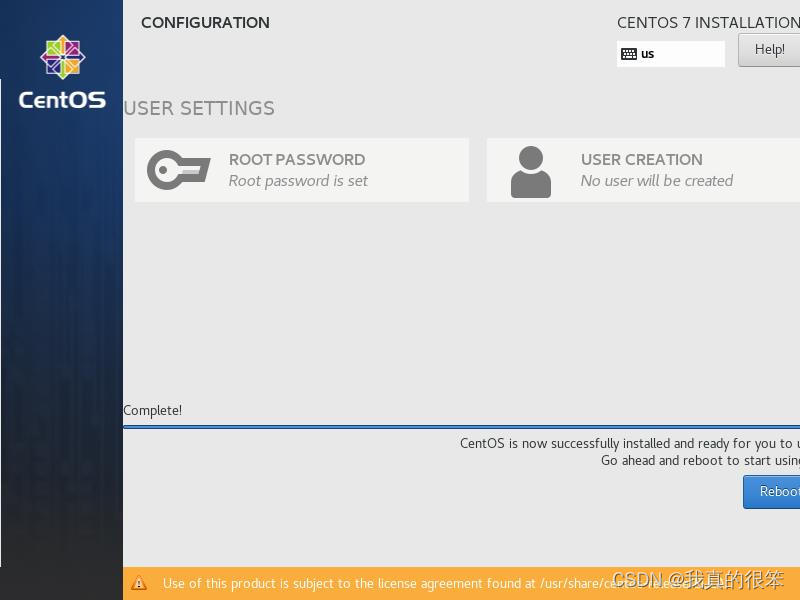
这就好了点击Reboot
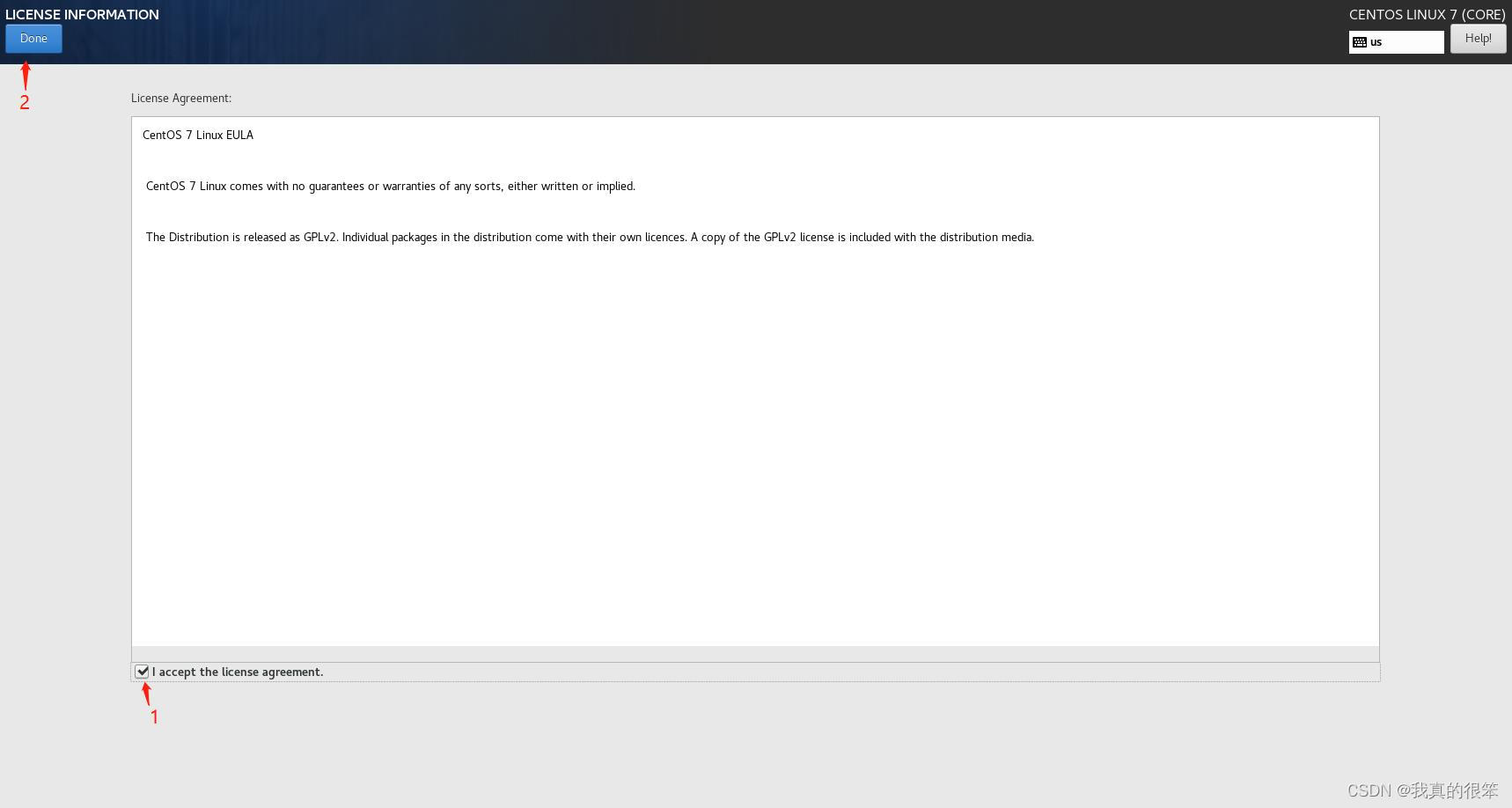
下一步点击LICENSE进入其中在下面把协议打上√然后点击Done退出
点击下一步
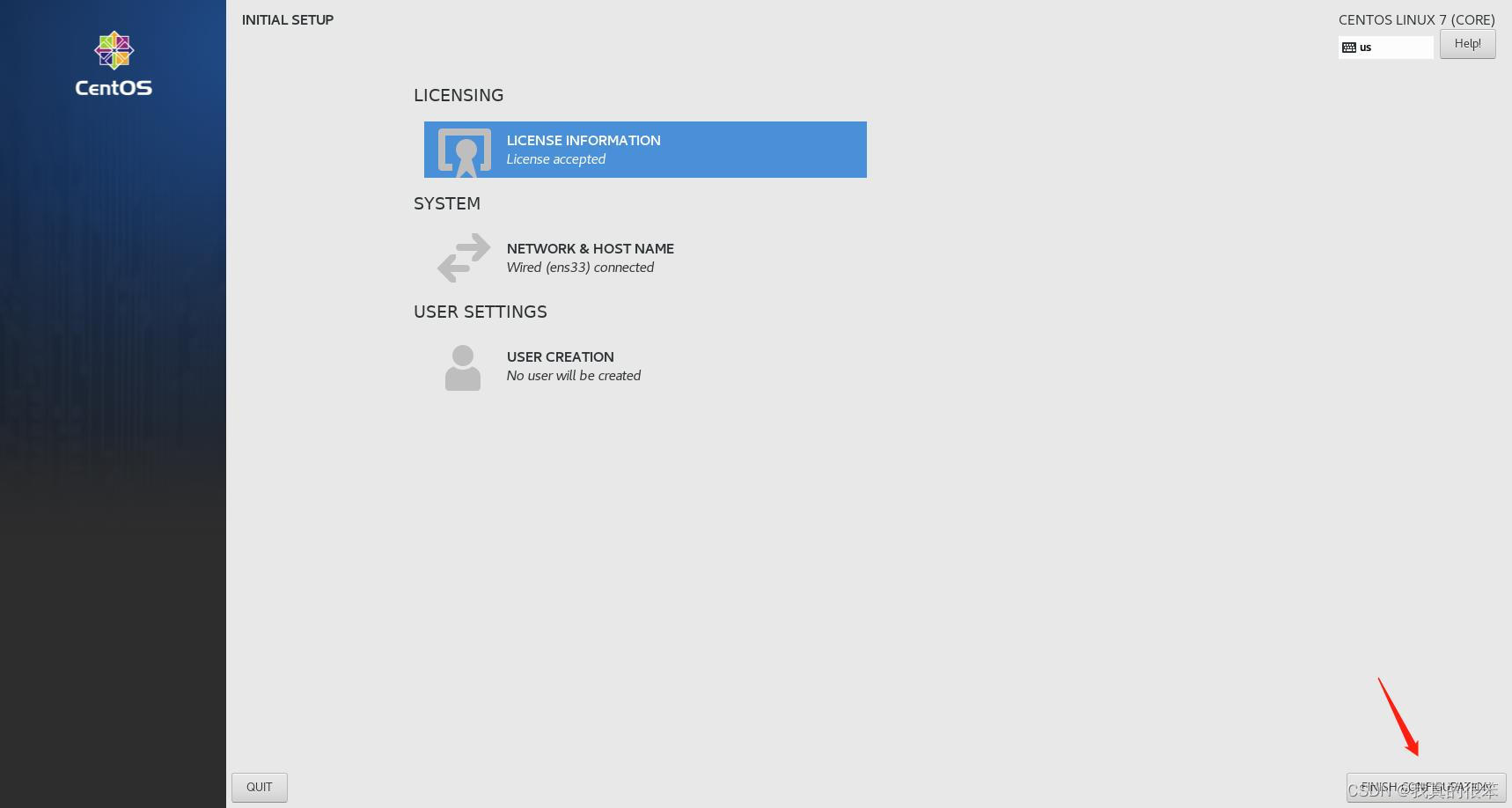
完成上面操作后第一步语言选择汉语
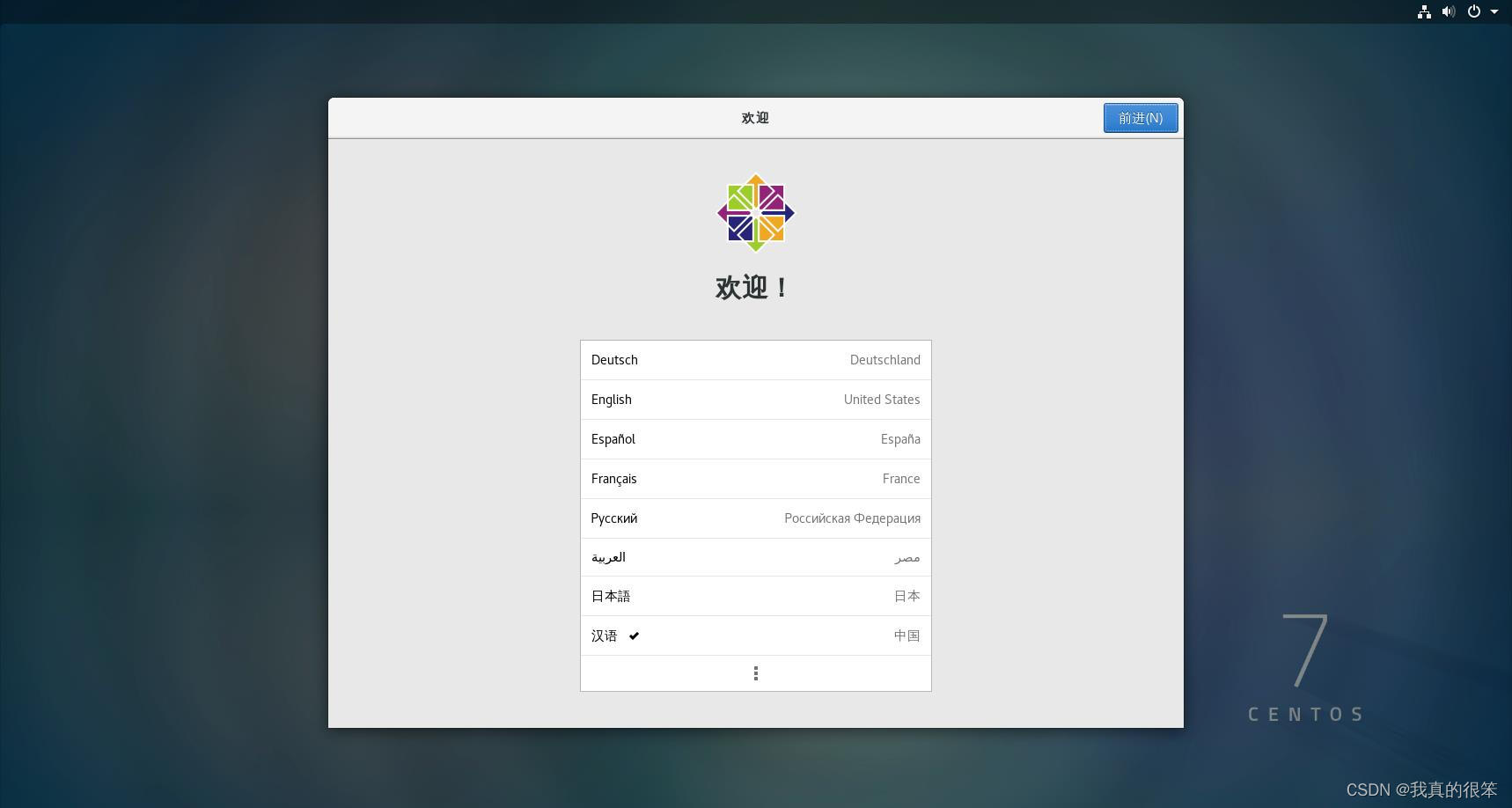
键盘语言选择汉语(pinyin)
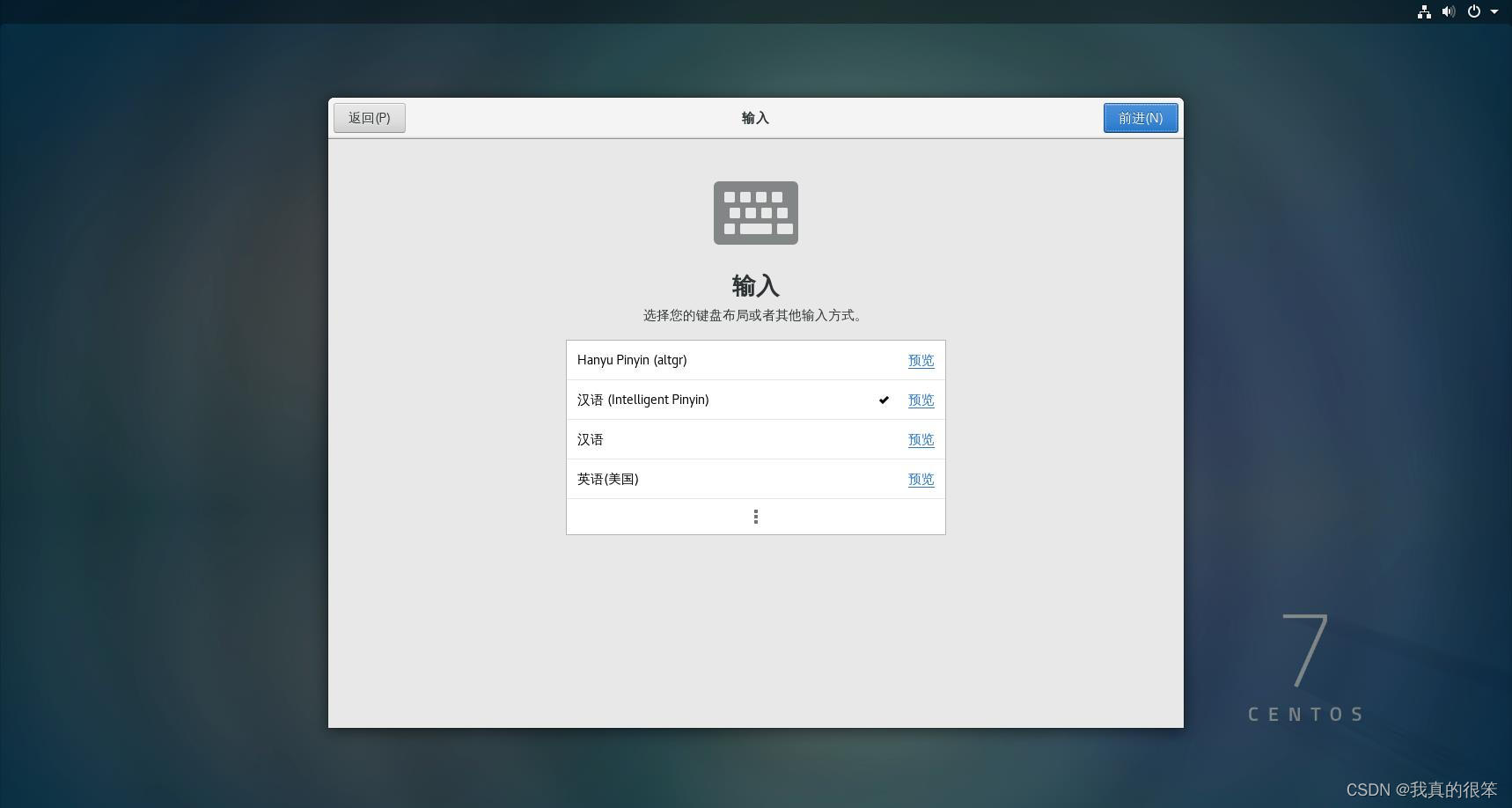
接下来三步直接选择前进或是跳过,直接来到设置用户名和密码
用户名为user
密码自己设置(这里设置的是user用户密码不是root用户不要搞混)
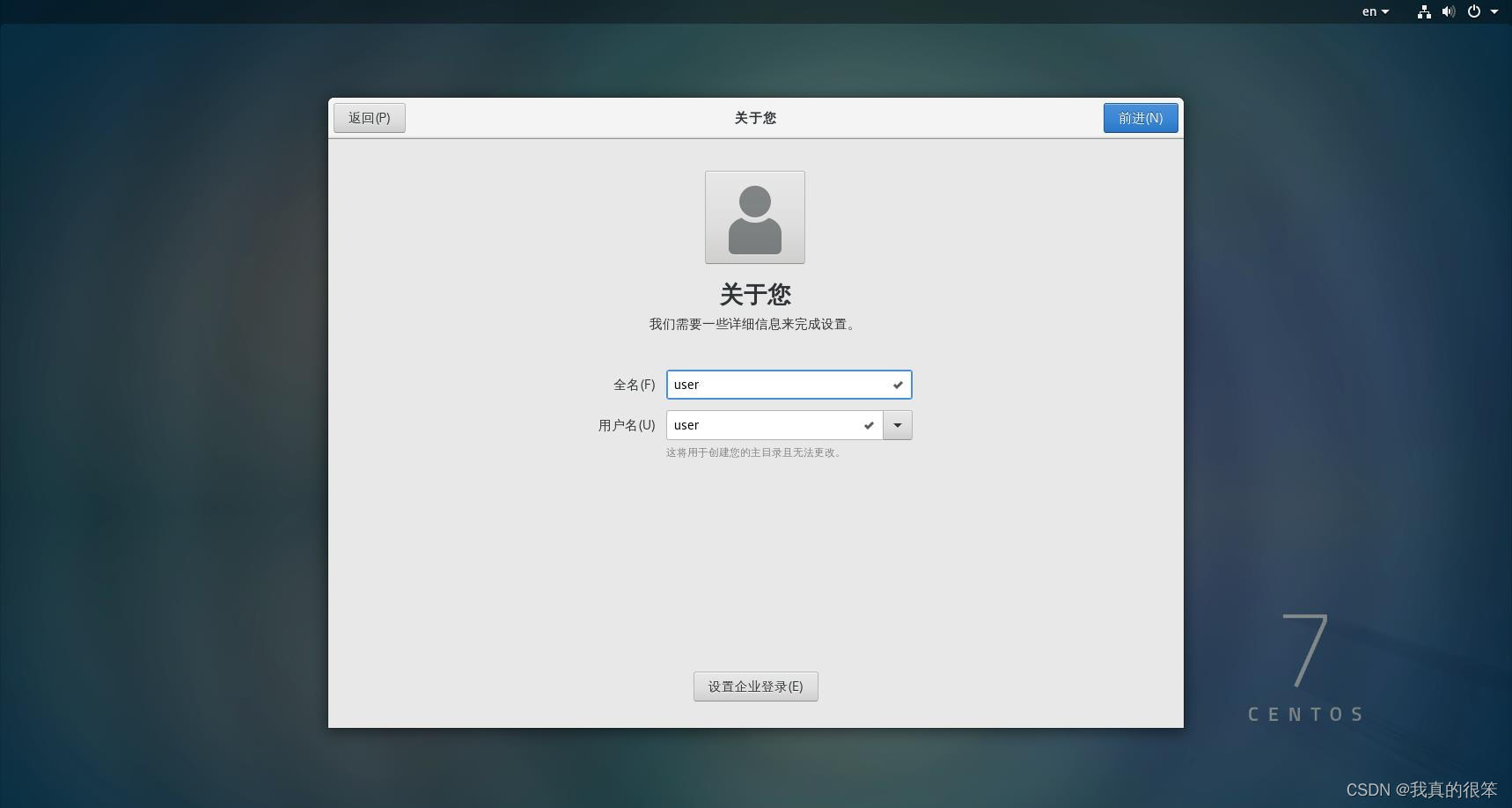
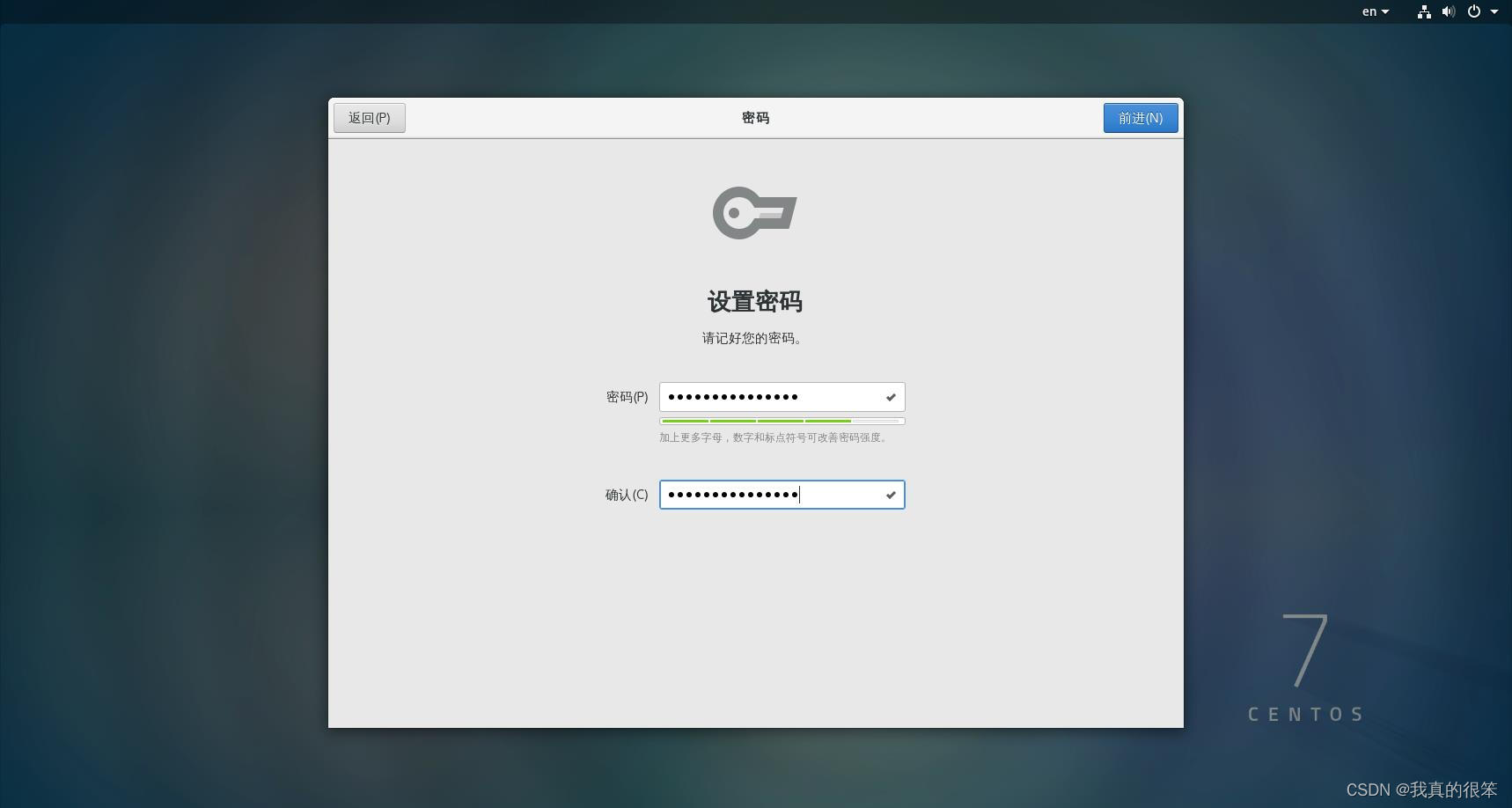
接下来导入我们需要的各种安装包
首先打开虚拟机设置点击选项下的共享文件夹然后点击总是开启
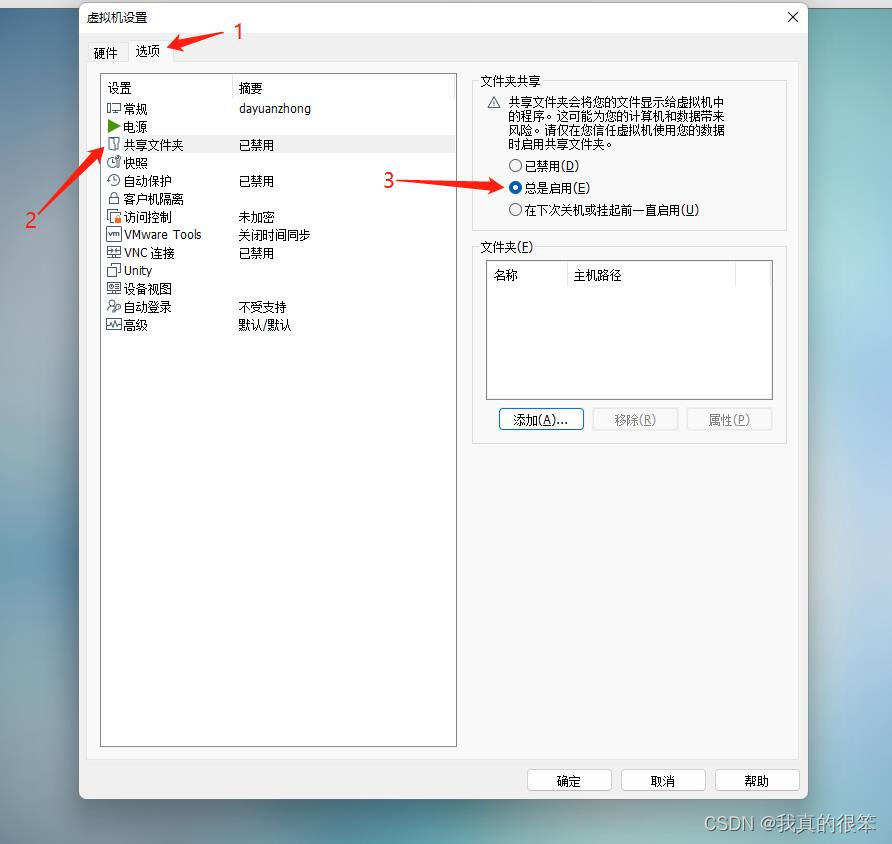
点击添加 →下一步→选择自己存放安装包的文件夹点击下一步
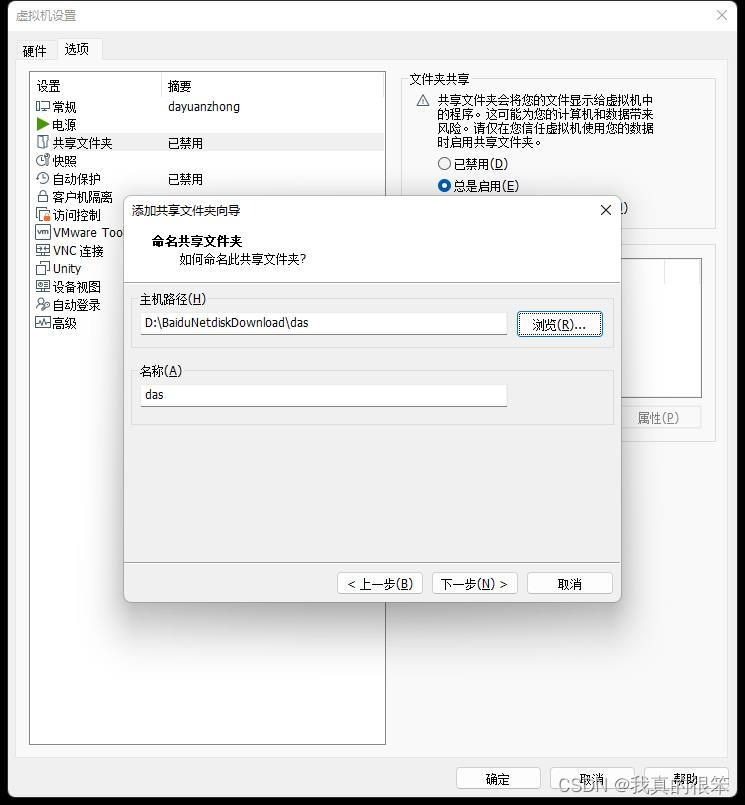
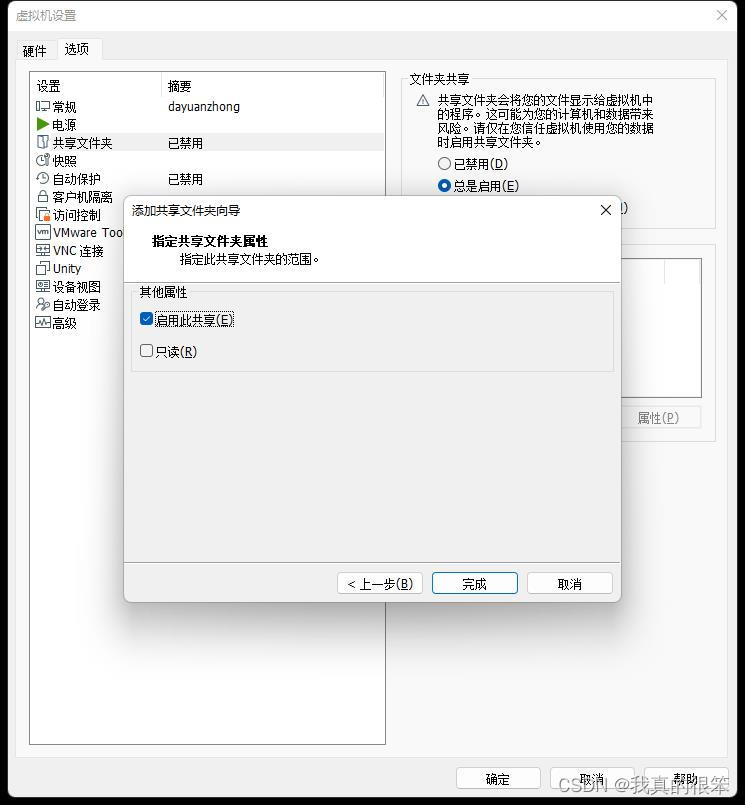
选择启用此共享然后点击完成点击确定
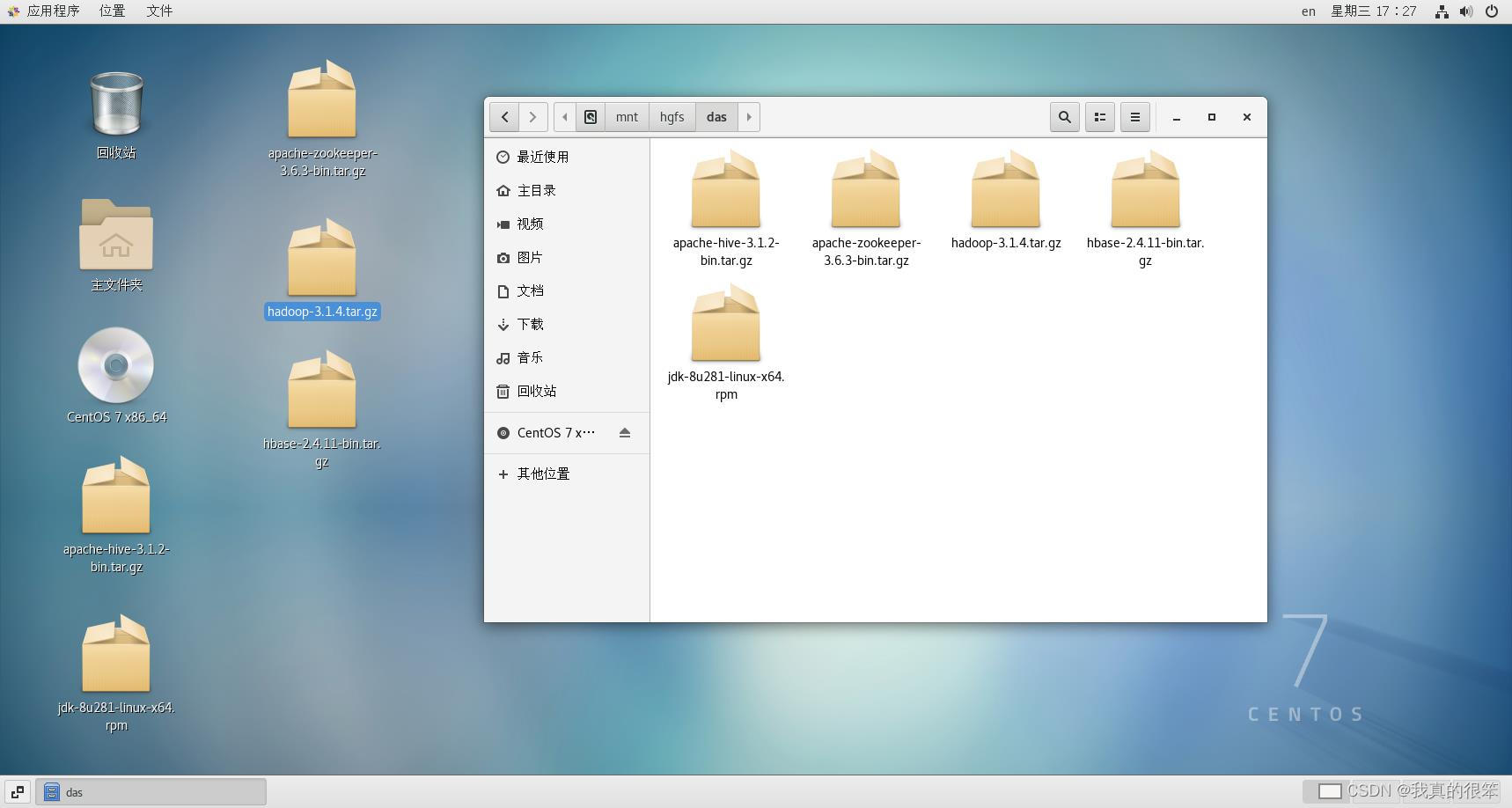
完成共享后安装包会放在我们的主文件及→其他位置→计算机→mnt文件夹里面然后将他们都拖到桌面上
搭建伪分布式环境之安装JDK
首先关闭防火墙
关闭防火墙指令:systemctl stop firewalld.service
接下来是修改主机名
输入命令:hostnamectl set-hostnam master
然后输入vi /etc/hostname查看(推出的话按esc键之后输入:wq就可以了)
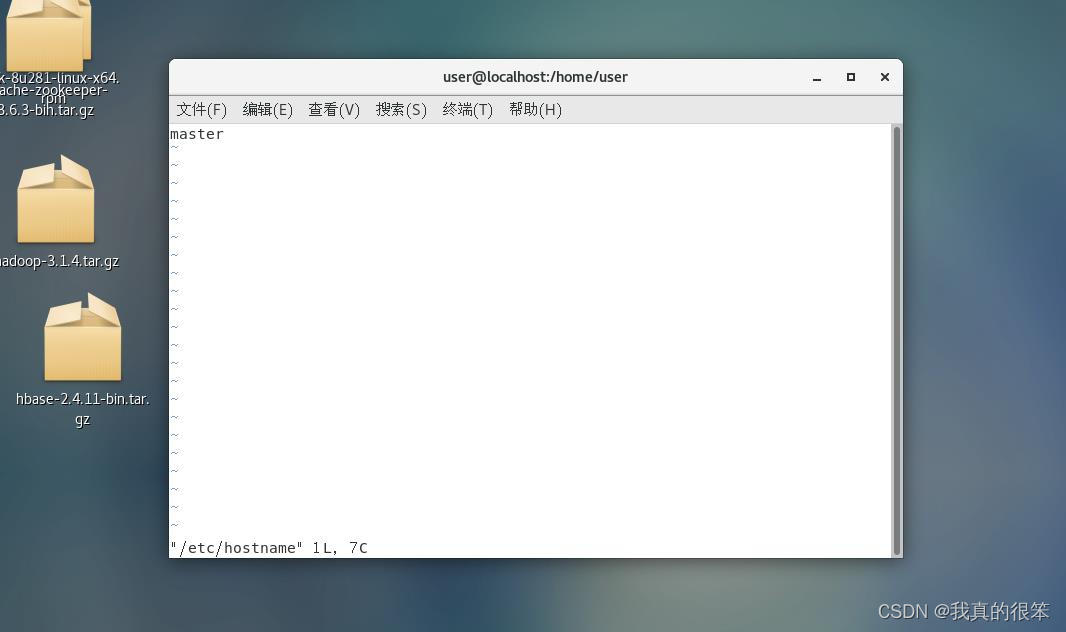
接下来检测一下虚拟机自带的JDK
使用java -version指令
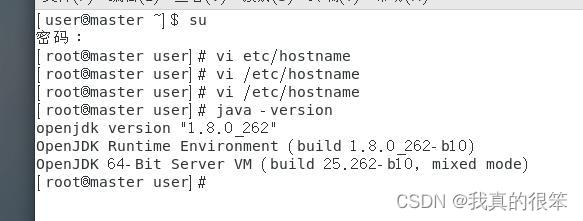
下面这个就是虚拟机自带的JDK在安装自己的之前需要先将他卸载
第一步先查看Java的相关信息用rpm -qa |grep java指令可以实现
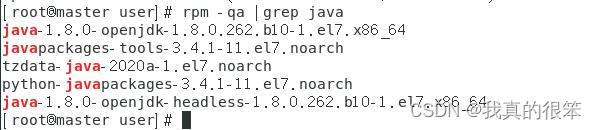
然后开始卸载
卸载指令为rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64
标红的地方要根据自己虚拟机的情况写
然后使用java -version指令查看一下
当看到以下信息就证明卸载成功了

开始安装自己的jdk
先在usr目录下建立一个java文件夹,方法为在usr目录下右键打开终端输入
mkdir java 就建好了
使用mv jdk-8u281-linux-x64.rpm usr/java/命令将JDK移动到usr下的Java文件夹下(我的终端就不看了太不好解释了,所有的移动文件命令都失败了他自己却过去了,很神奇。)
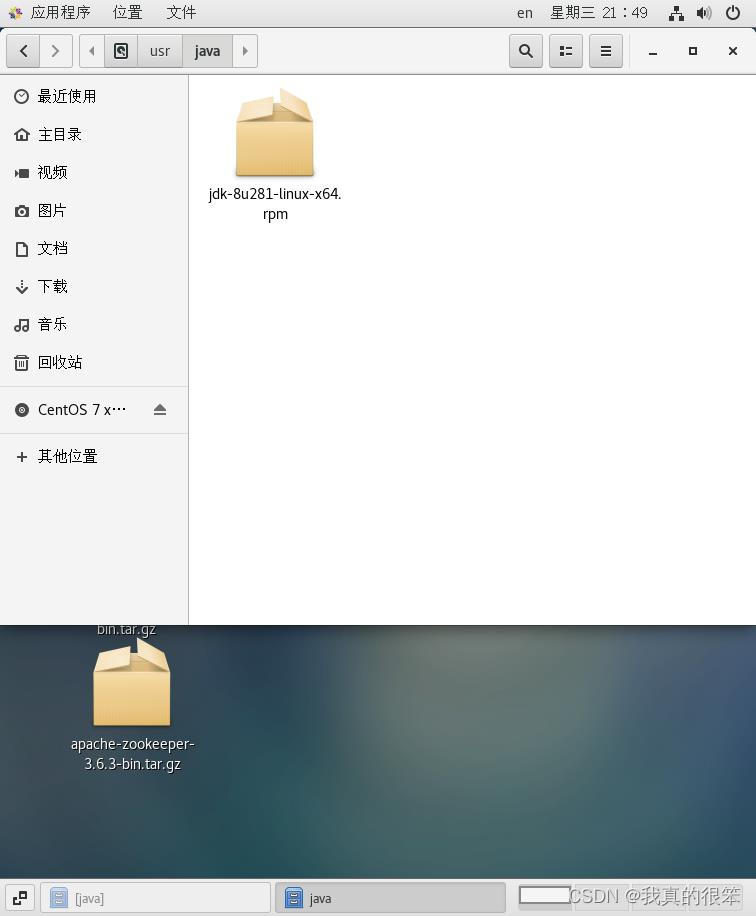
开始解压安装JDK
首先在他这个文件夹下直接右键打开终端
不同类型的安装包用不同的指令,rpm用-ivh tar用-zxvf 我们这里是rpm的安装包所以完整命令是
rpm -ivh jdk-8u281-linux-x64.rpm 最后用java -version检查一下
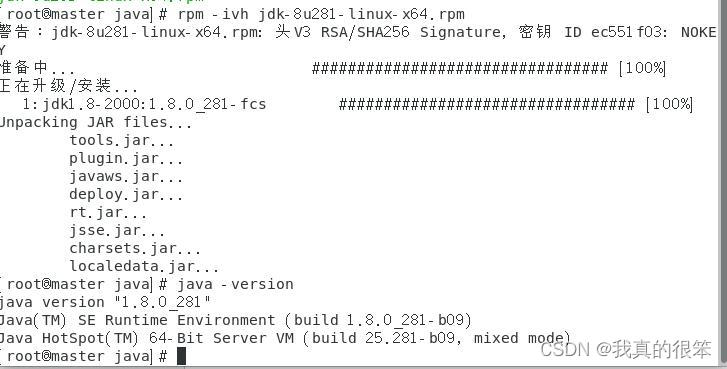
下一步配置环境变量
命令为vi ~/.bash_profile (进入之后按i可以编辑同样的按esc键之后输入:wq保存退出)完成后输入source ~/.bash_profile释放一下配置文件
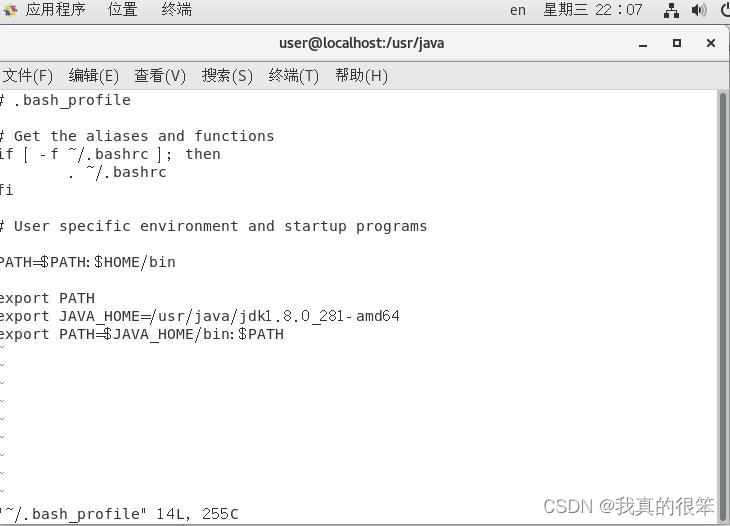
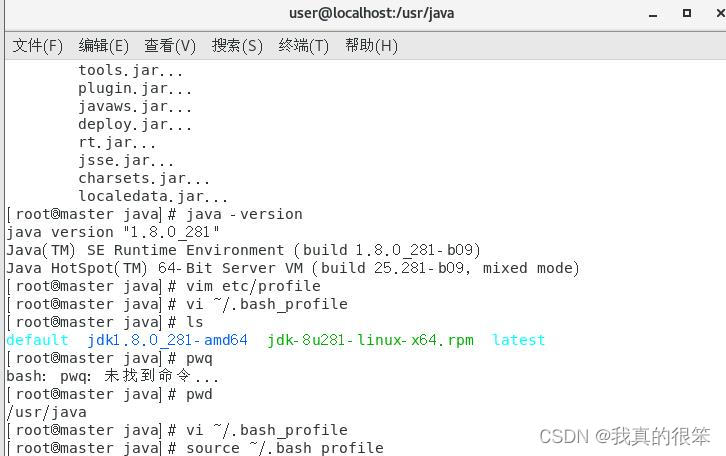
完成后我们的JDK就安装完成了
Hadoop单节点式环境搭建
第一步同样先将我们的hadoop安装包移动到home/user/hadoop文件夹下
首先在user文件夹里创建一个hadoop文件夹
mkdir /home/user/hadoop
然后将安装包移动到hadoop文件夹里
mv hadoop-3.1.4.tar.gz /home/user/hadoop/
之后进入hadoop文件夹下查看

接下来就开始解压安装因为我们的Hadoop安装包和之前的JDK不一样,hadoop是tar的安装包所以我们的命令应该是
tar -zxvf hadoop-3.1.4.tar.gz
然后使用 vi ~/.bash_profile 来对hadoop进行变量配置,最后同样的source ~/.bash_profile命令释放配置

然后使用hadoop version检查一下hadoop版本
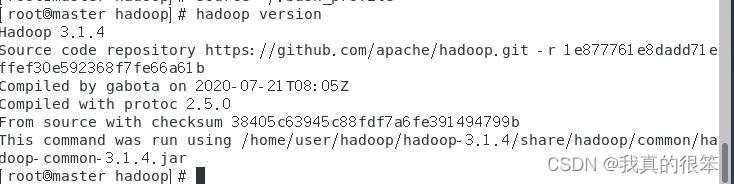
接下来测试一下 mapreduce程序首先(cd ..)退回到user目录,创建一个input1文件夹在input1里面再创建一个test.txt文件
创建文件命令为
touch 文件名
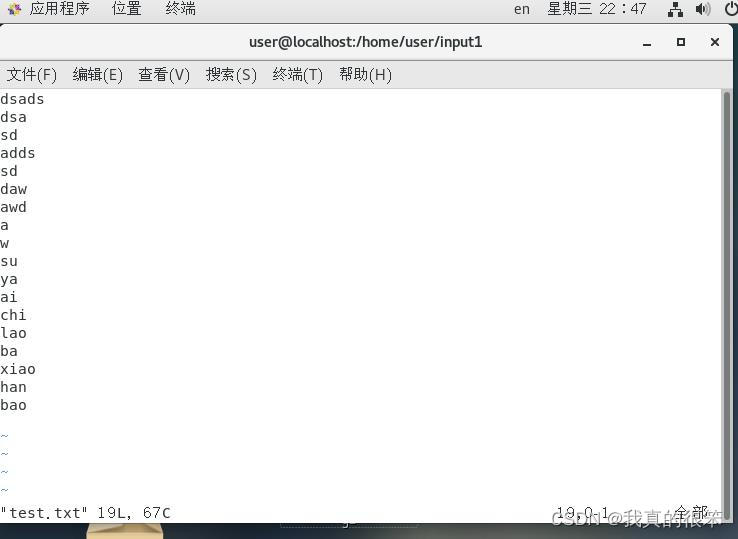
接下来编辑一下test.txt文件
编辑命令为
vim 文件名
编辑完成后保存退出就可以了(与环境变量同理)
最后一步就是输入命令开始测试mapreduce程序
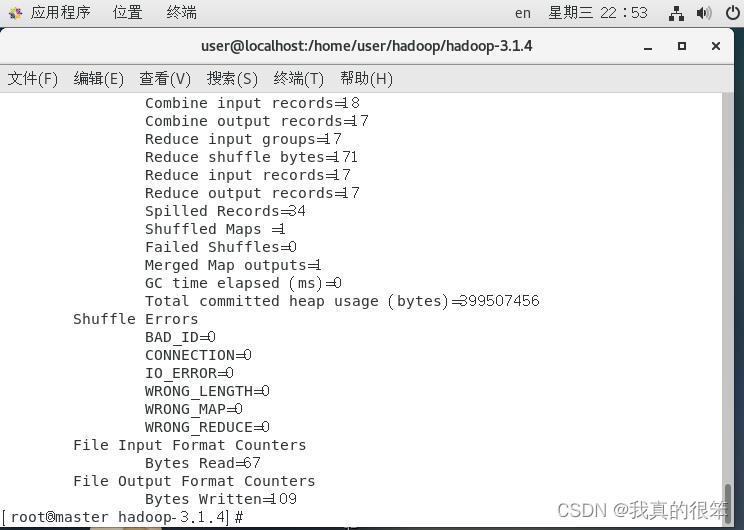
完成后我们的hadoop单节点环境就搭建完成了。
搭建伪分布式环境
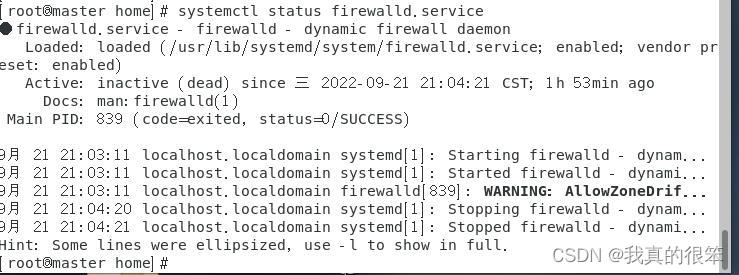
第一步检查防火墙是否为关闭状态
检查命令为systemctl status firewalld.service
绿色为开启灰色为关闭
检查完后在终端进入我们的hadoop-3.1.4文件夹下
配置环境变量
命令为
vi ./etc/hadoop/hadoop-env.sh
首先是7条export配置命令 (用截图是因为我不想让你们养成复制粘贴的习惯,锻炼你们的代码速度)
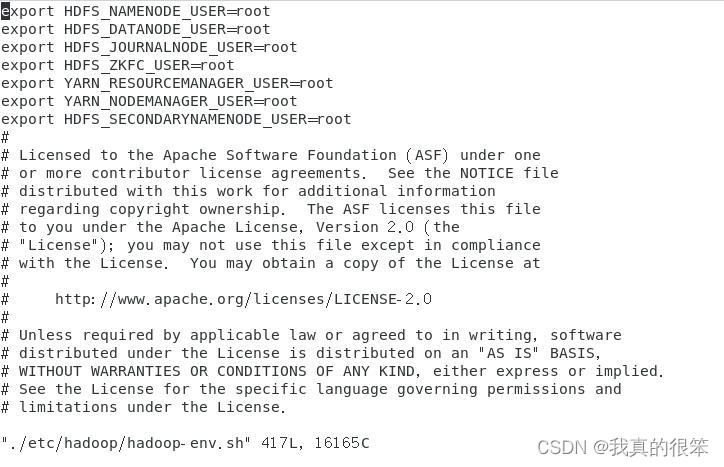
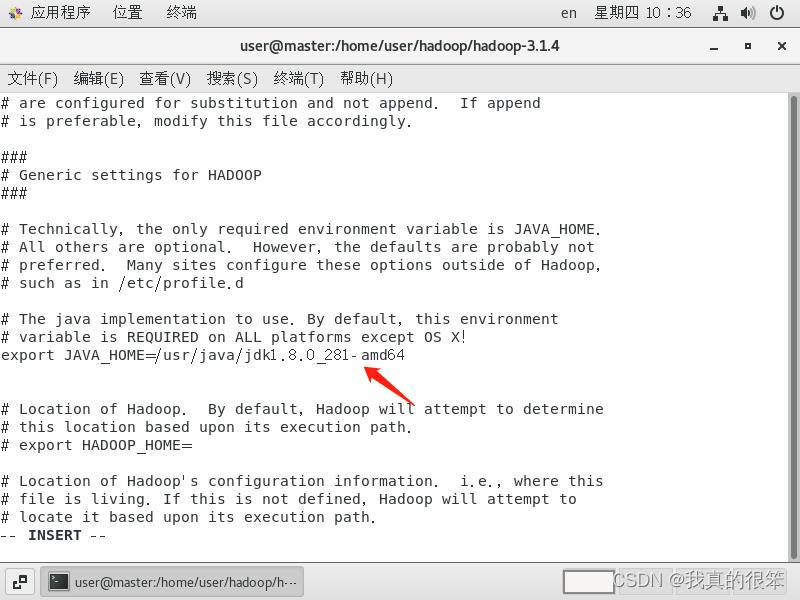
然后就是将JAD的路径复制到下面大概是在第54行。
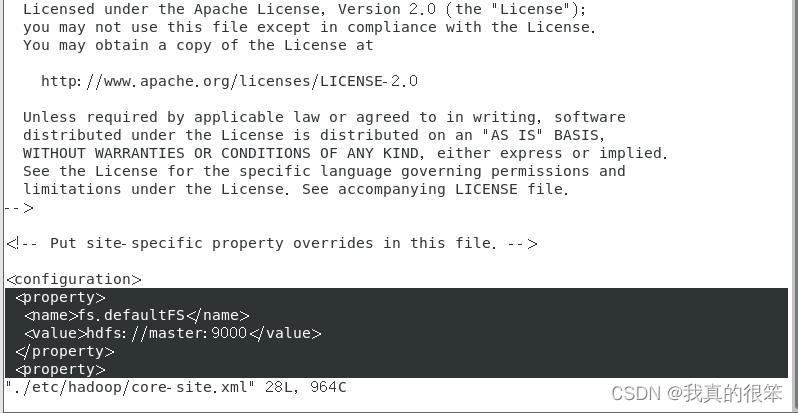
下一步配置vi ./etc/hadoop/core-site.xm 变量
如下图所示更改(记得手打哦)
接下里配置vi ./etc/hadoop/hdfs-site.xml 变量
同样如下图更改所示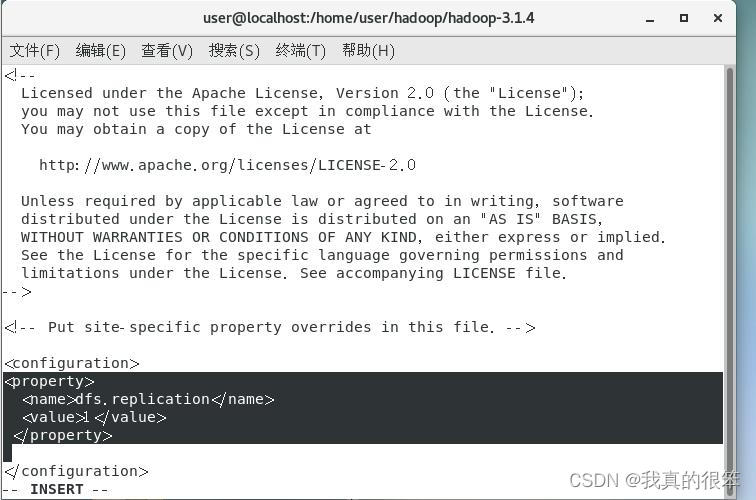
之后配置vi ./etc/hadoop/yarn-site.xml 变量
如下图(下面有可以复制粘贴,这个太多了让你们手打我怕你们把我打一顿)
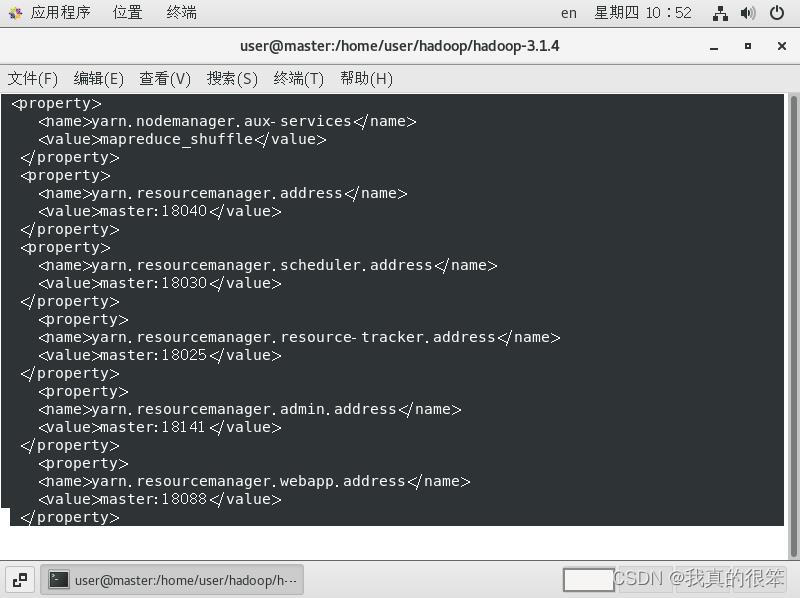
<property></property> <property><name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property> <property><name>yarn.resourcemanager.address</name> <value>master:18040</value></property><name>yarn.resourcemanager.scheduler.address</name> <value>master:18030</value></property><property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:18025</value></property><property> <name>yarn.resourcemanager.admin.address</name> <value>master:18141</value></property><property> <name>yarn.resourcemanager.webapp.address</name> <value>master:18088</value>
之后配置vi ./etc/hadoop/mapred-site.xml 变量
(说了这么多手打吧)
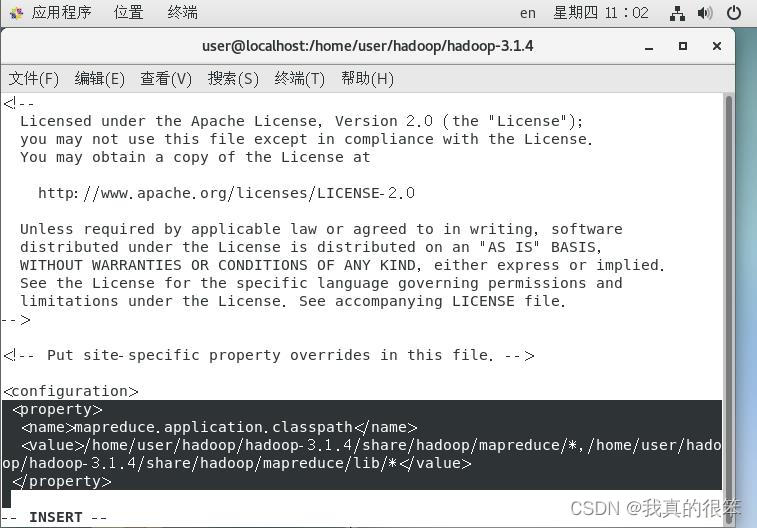
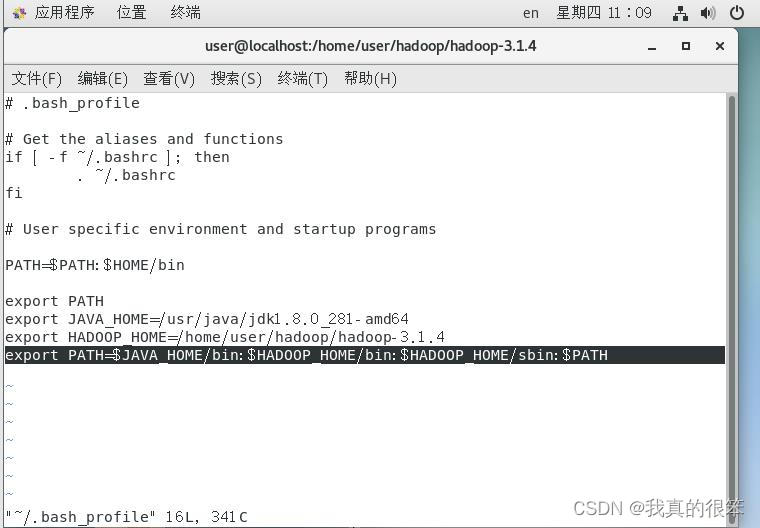
最后配置环境变量
输入命令
vi ~/.bash_profile
然后进行以下更改,更改完成后使用source ~/.bash_profile 命令进行释放
环境配置编辑完成后,创建一个hadoopdata文件夹
命令为
mkdir /home/user/hadoop/hadoopdata
创建完成后在终端进入hadoop-3.1.4/bin目录下
输入以下命令对namenode进行格式化
./hdfs namenode -format (下面图片是格式化完成后的样子)
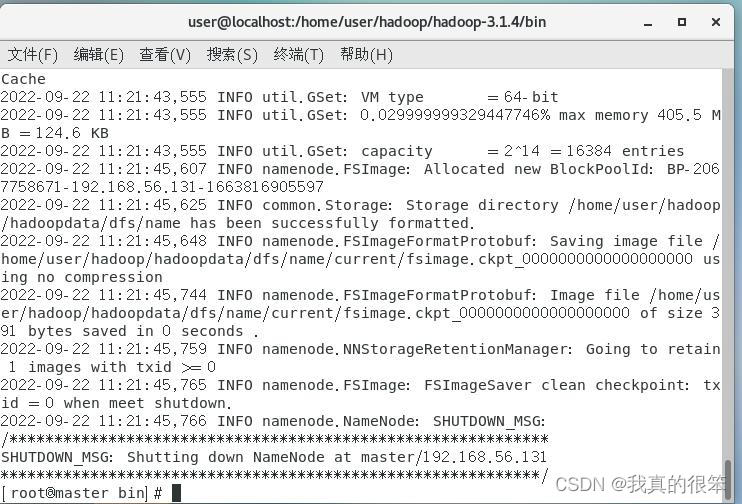
接下来就进行测试首先输入以下命令转入到sbin目录下
cd /home/user/hadoop/hadoop-3.1.4/sbin/
然后使用 start-all.sh 指令启动所有进程但初次启动可能只会启动RM进程然后输入 jps 查看之后
输入命令:./hadoop-daemon.sh start datanode 启动datanode
输入命令:./yarn-daemon.sh start nodemanager 启动nodemanager
输入命令:./hadoop-daemon.sh start namenode 启动namenode
全部启动完成后输入 jps 查看
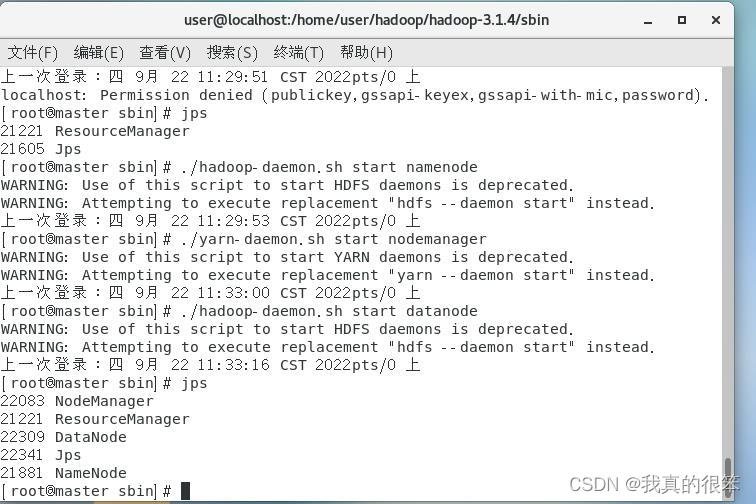
然后输入命令 hadoop fs -mkdir -p /home/user/hadoop/input 在集群的文件系统中建立一个文件夹
完成之后输入命令:hadoop fs -ls -R / 查看 这里可以看到已经创建完成了
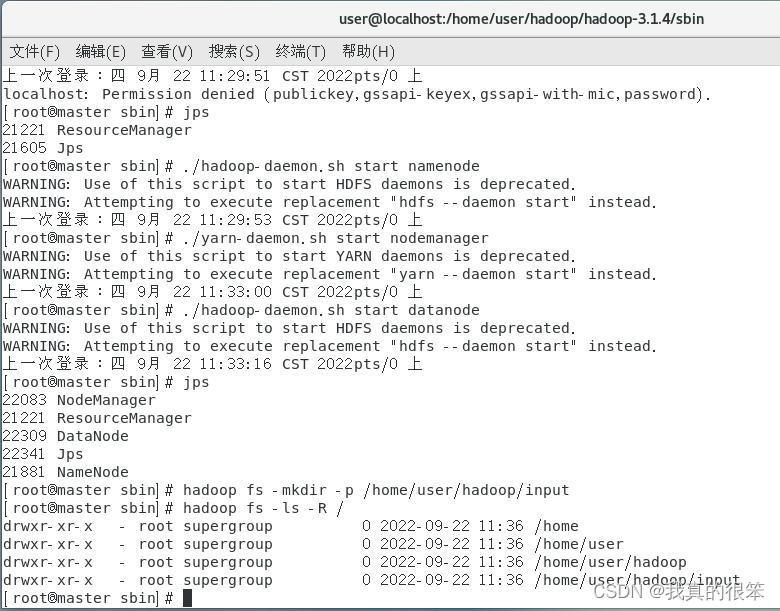
下一步将我们在hadoop单节点环境中创建的test.txt文件传输到input下 (不知道啥时候创建的tset.txt文件的往上翻)
输入下面命令进行传输
hadoop fs -put /home/user/input1/test.txt /home/user/hadoop/input 完成后输入hadoop fs -ls -R /查看
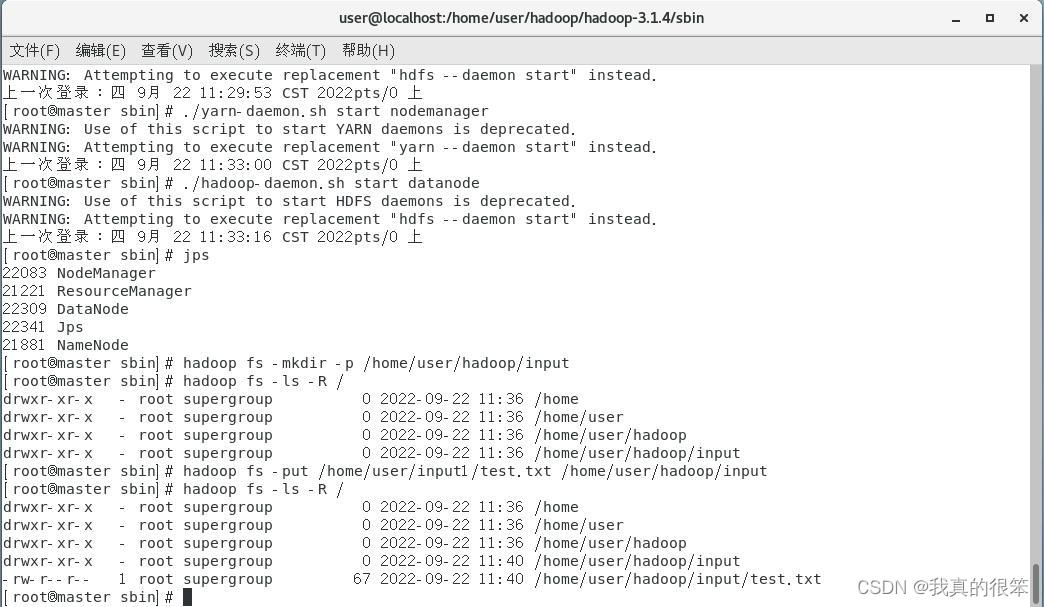
然后输入cd /home/user/hadoop/hadoop-3.1.4 命令转回到我们的hadoop-3.1.4文件夹下输入以下命令
./bin/hadoopjar ./share**/hadoop/mapreduce/**
**hadoop-mapreduce-examples-3.1.4.jar ** wordcount /home/user
/hadoop/input/test.txt /home/user/hadoop/output 这里的名字最好是手打(其中标红的内容最好使用Tab键自动补全,否则可能会有路径报错问题)然后回到sbin 目录下使用hadoop fs -ls -R /查看
可以看到output的文件夹下多了一个part-r-00000文件
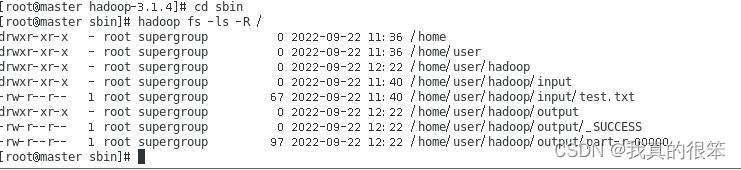
接下来就是最后一步在sbin下输入
hadoop fs -cat /home/user/hadoop/output/part-r-00000
命令查看part-r-00000文件内容,得出wordcount的运行结果
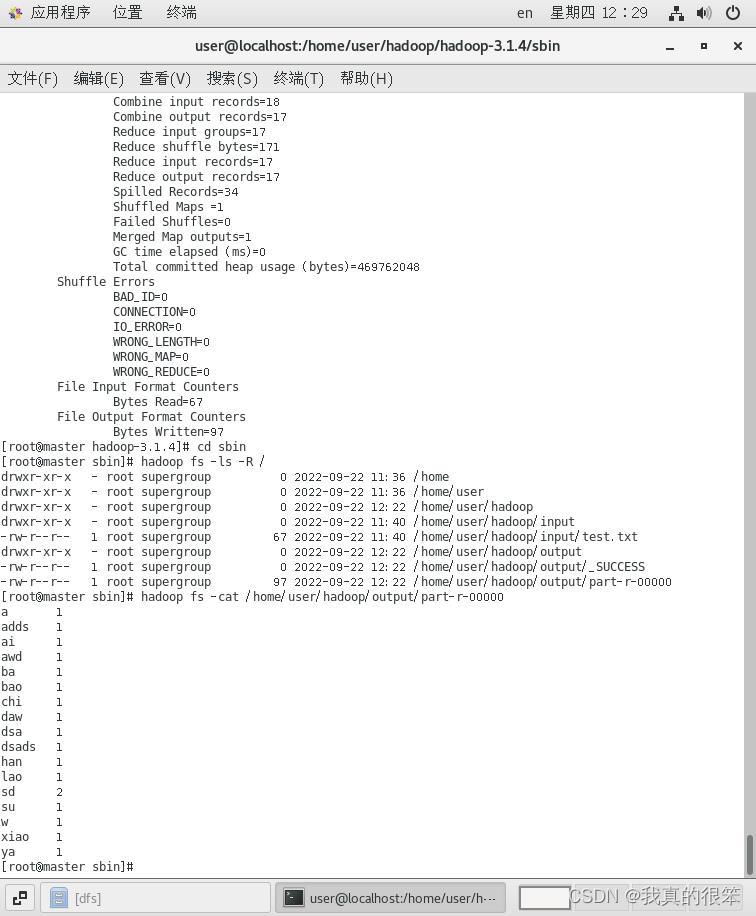
好了这样我们的hadoop伪分布式环境搭建就完成了
版权归原作者 我真的很笨 所有, 如有侵权,请联系我们删除。