
文章目录
(一)图像分类的发展历程
ILSVRC是一项基于 ImageNet 数据库的国际大规模视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)
(1)1958年,Rosenblatt发明了感知机。用于对输入的多维数据进行二分类且能够使用梯度下降法自动更新权值。缺点:只能处理线性分类问题。
(2)1986年,Geoffrey Hinton发明了多层感知机(multi-layer perceptron,MLP)的反向传播(back propagation,BP)算法,并使用 sigmoid 函数进行非线性映射,有效解决了非线性分类问题。被称为" 深度学习之父 "。缺点:存在梯度消失问题。
序号年份提出者模型网络层数特点用途11998LeCunLeNet-58层定义了CNN最基本架构:卷积层、池化层、全连接层。解决手写数字识别的视觉任务22012AlexAlexNet-88层提出训练深度网络的重要方法:Dropout、ReLU、GPU(硬件支持)、数据增强等。ImageNet竞赛:以超过第二名10.9%的绝对优势夺冠(83.6%)32014牛津大学VGG(Visual Geometry Group)VGGNet-16/1916/19层采用 1x1 和 3x3 的卷积核以及 2x2 的最大池化,使得层数变得更深。ImageNet竞赛:定位任务的第一名、分类任务的第二名(92.7%)42014Google 团队GoogleNet(Inception-v1234)22层(1)引入了Inception模块;(2)采用全局平均池化替换所有的全连接层。 ImageNet竞赛:分类任务的第一名(93.3%)52015何恺明ResNet-152152层引入了ResNet残差模块,通过高速网络的跨层连接让神经网络变得非常深。
ImageNet竞赛:分类任务的第一名(93.3%)52015何恺明ResNet-152152层引入了ResNet残差模块,通过高速网络的跨层连接让神经网络变得非常深。 ISLVRC和COCO竞赛:横扫所有选手,获得冠军(96.43%)。CVPR2016最佳论文奖62017Gao HuangDenseNet-121/169/201/264121/169/201/264层引入了Dense Block模块,即每层都会接受其前面所有层作为额外的输入。
ISLVRC和COCO竞赛:横扫所有选手,获得冠军(96.43%)。CVPR2016最佳论文奖62017Gao HuangDenseNet-121/169/201/264121/169/201/264层引入了Dense Block模块,即每层都会接受其前面所有层作为额外的输入。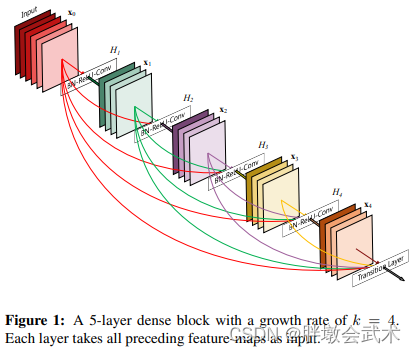 CVPR2017最佳论文奖72017/2018/2019谷歌MobileNet(V1/V2/V3)224层V1引入了深度可分离卷积。在准确率小幅度降低的代价下大幅度减少参数量。
CVPR2017最佳论文奖72017/2018/2019谷歌MobileNet(V1/V2/V3)224层V1引入了深度可分离卷积。在准确率小幅度降低的代价下大幅度减少参数量。 轻量级、移动端网络模型
轻量级、移动端网络模型
(二)模型框架
(2.1)LeNet-5
论文地址:Gradient-Based Learning Applied to Document Recognition
模型结构:LeNet-5共8层网络:1个输入层、2个卷积层、2个池化层、3个全连接层。 实际只有五层:去掉1个输入层和2个池化层。
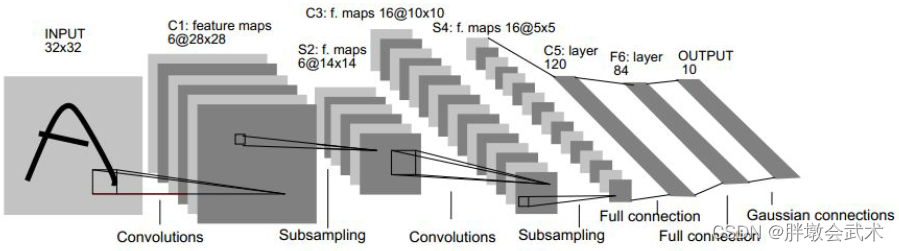
- 卷积层:所有卷积层的kernel=5x5,stride=1。
- 池化层:采用平均池化kernel=2x2,stride=2。 (3)在每个卷积层 + 池化层的后面会跟一个Sigmod激活函数,而现在多用ReLU。
- 全连接层:C5/C6/OUTPUT的节点分别为120/84/10。对应的权重参数(与连接数相同)分别为:(5x5x16+1)x120 = 48120、(120 + 1)x84=10164、84x10=840。
- 备注1:LeNet卷积神经网络,共约有60,840个训练参数,340,908个连接。
- 备注2:LeNet 会随着网络的加深,宽度逐渐降低,通道逐渐增多。 CNN卷积神经网络 LeNet-5详解
(2.2)AlexNet-8
论文地址:ImageNet Classification with Deep Convolutional Neural Networks
模型结构:5个卷积层 + 2个全连接层(隐藏) + 1层全连接层(输出)
- 卷积层: 第一个卷积层(kernel=11x11、stride=4、Padding=0); 第二个卷积层(kernel=5x5、stride=1、Padding=2); 其余的卷积核(kernel=3x3、stride=1、Padding=1)。
- 池化层:第一个, 第二个, 第五个卷积层的后面分别使用一个最大池化层(kernel=3x3,stride=2)。
- 全连接层: 全连接层1(隐藏):神经元个数输出为4096; 全连接层2(隐藏):神经元个数输出为4096; 全连接层3(输出):神经元个数输出为1000(分类)。
- 激活函数:每个卷积层后面跟一个激活函数
ReLU(替换Sigmod)。- 过拟合:使用
Dropout、图像增强来防止过拟合。


(2.3)VGGNet-16/19
论文地址:Very Deep Convolutional Networks for Large-Scale Image Recognition


(2.4)GoogleNet-22(Inception:V1-V2-V3-V4)
论文地址:Going deeper with convolutions
github链接
2.4.1、InceptionV1
GoogLeNet网络的基础模块:Inception模块。
在每个Inception模块中,包含4条并行线路:
- (1)前3条线:分别使用1x1、3x3、5x5的卷积层,抽取不通空间尺度下的特征信息;
- (2)第二条和第三条线:先使用了1x1的卷积层,减少输入通道数,以降低模型复杂度。
- (3)最后一条线:使用3x3的最大池化层 + 1x1的卷积层来改变通道数。 备注:4条线都使用合适的填充Padding来保证输入和输出的高宽一致。
结构图(横向):
结构图(纵向):


(2.5)ResNet-152
论文地址:Deep Residual Learning for Image Recognition
github链接
经典语句:再差不会比原来差(恒等映射)。
- (1)图像是比较复杂的数据,只有足够深的网络层次才能提取充分信息。
- (2)激活函数的输入来自于神经网络一层层计算的输出结果。但是随着网络层的不断加深,误差并不会越来越小,容易出现梯度不稳定(如:梯度爆炸、梯度消失)。
残差块的目的:通过一种高速通道的连接方式,让输出结果同时参考输入结果x,解决梯度的不稳定性。
残差模块:

模型架构:

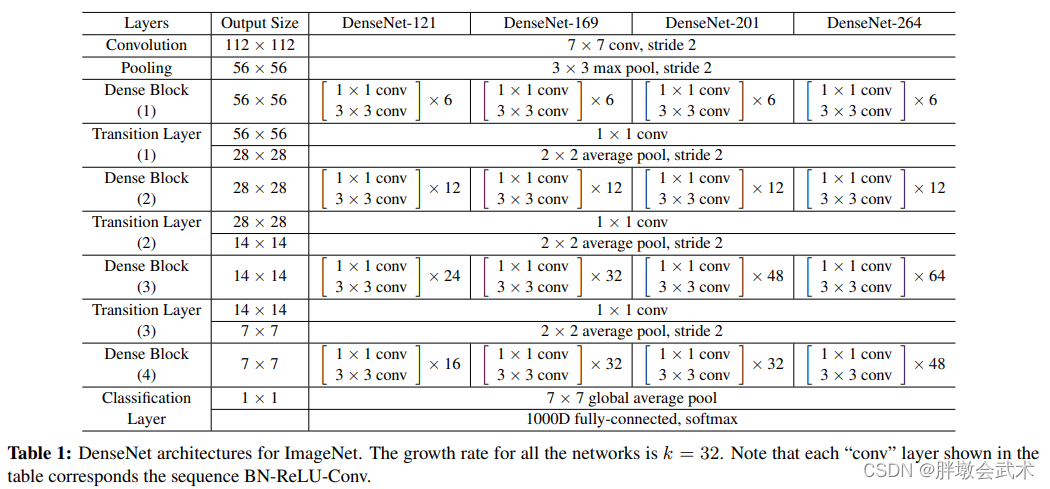
(2.6)DenseNet-264
论文地址:Densely Connected Convolutional Networks
github链接(附有详细教程)
Dense Block模块:每层都会接受其前面所有层作为额外的输入
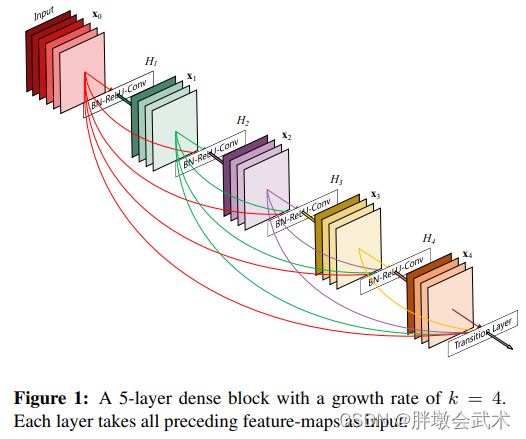
DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络模型使用 DenseBlock + Transition Layers 结构。
- Dense Block:包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式:BN + ReLU + Conv(3x3) + Dropout(0.2) 。
- (1)与ResNet十分相似,主要区别在于feature map融合的方式不同。 - ResNet将前一个模块的输出,直接加到模块的输出上- DenseNet将前一个模块的输出,直接在通道上进行叠加。
- (2)与ResNet不同,所有Dense Block中各个层卷积均采用 k 个卷积核,所有每个卷积层输出的feature map的channel都为k。k在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的 k(论文里k=32),就可以得到较佳的性能。
- 过渡层:连接两个相邻的DenseBlock,并进行1x1卷积和2x2 平均池化,降低特征图大小。 即使k设的很小,但由于特征重用(通道叠加),后面层的输入仍会非常大,故需要降低模型的复杂度。【论文复现】DenseNet
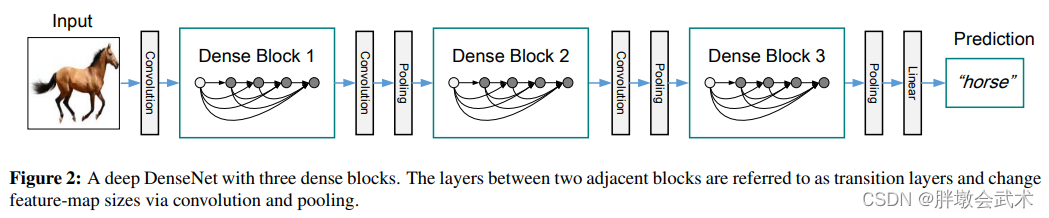
模型架构:
- 输入分辨率为224x224,使用SGD训练
- DenseNet:设置4个Dense block模块,每个block的层数相同。在第一个block的前面,放置一个7x7卷积和3x3最大池化。在最后一个block后面接global平均池化,全连接,softmax。
- (1)每个block:使用3x3卷积,1x1卷积,zero-padding。
- (2)两个block之间:使用1x1卷积、2x2平均池化作为过渡层(transition layers)。
优缺点
- 优点:(1)网络结构参数看起来很多,但实际上参数更少,提高了训练效率。(2)特征重用增强了特征在各个层之间的流动,因为每一层都与初始输入层还有最后的由loss function得到的梯度直接相连。(3)进行反向传播的时候,减轻了梯度弥散的问题,使模型不容易过拟合。(4)由于每层可以直达最后的误差信号,误差信号可以很容易地传播到较早的层,所以较早的层可以从最终分类层实现隐式的deep supervision。
- 缺点:(1)由于需要进行多次Concatnate操作,数据需要被复制多次,显存容易增加得很快,需要一定的显存优化技术。(2)DenseNet是一种特殊网络,而ResNet相对一般化些,因此ResNet的应用范围更广泛。
(2.7)MobileNet(V1-V2-V3)
论文地址(V1):MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
论文地址(V2):MobileNetV2: Inverted Residuals and Linear Bottlenecks
论文地址(V3):Searching for MobileNetV3
MobileNet网络专注于移动端或者嵌入式设备中的轻量级CNN,相比于传统卷积神经网络,在准确率小幅度降低的前提下大大减少模型参数与运算量。
MobileNet可以在移动终端实现众多的应用,包括目标检测,目标分类,人脸属性识别和人脸识别等。

2.7.1、MobileNetV1(深度可分离卷积)
模型架构:
- 除第一层是普通卷积层,其余都是深度可分离卷积层。
- 除最后的全连接层没有ReLU层,其余每个网络层后都有BN层和ReLU非线性激活层。
- 在全连接层前,使用全局池化将张量的尺寸变为1×1。在全连接层后,使用softmax层进行分类。
- 下采样通过带步长的卷积层来实现。
- 采用RMSprop优化器。
- 不使用正则化和数据增广。由于MobileNet为轻量级网络,且小网络通常不会过拟合。

MobileNetV1:提出使用深度可分离卷积替代普通卷积来减少模型参数。由两部分组成:深度卷积(Depthwise convolution,DW)和点卷积(Pointwise Convolution,PW)
(1)深度卷积与传统卷积的区别MobileNet网络详解
- 在传统卷积中,每个卷积核的channel与输入特征矩阵的channel相等(每个卷积核都会与输入特征矩阵的每一个维度进行卷积运算),输出特征矩阵channel等于卷积核的个数。
- 在DW卷积中,每个卷积核的channel都是等于1的(每个卷积核只负责输入特征矩阵的一个channel,卷积核的个数=输入特征矩阵的channel数=输出特征矩阵的channel数)
(2)深度可分离卷积=深度卷积+点卷积:PW卷积是大小为1×1的普通的卷积,主要用于改变输出特征矩阵的channel。
(3)参数计算比较
(4)深度可分离卷积与传统卷积的区别



MobileNetV2在MobileNetV1的基础上,提出了2点创新:
(1)使用linear bottleneck捕获manifold of interest
(2)逆残差模块;
MobileNetV3的3个特点:
(1)MobileNetV3的网络结构是NAS搜索出来的;
(2)在bottleneck结构中引入了轻量级注意力模块;
(3)使用swish激活函数而不是relu;
(三)应用领域
人工智能(Artificial Intelligence,AI)主要分为三个部分:机器学习ML、深度学习DL、强化学习RL。
(1)机器学习算法包括:逻辑回归、支持向量机SVM、决策树、随机森林和神经网络等等。深度学习是神经网络中的一种。强化学习是机器学习中的一种。
(2)机器学习可分为三大类:有监督学习(supervised learning)、无监督学习(unsupervised learning)和强化学习。
(3)深度强化学习是深度学习和强化学习的结合。
11、有监督学习四个典型应用:图像分类、目标检测、人脸识别、语音识别。
22、无监督学习最常使用的场景:聚类和降维。常见的简单的无监督学习算法总结
- 聚类:k-均值聚类(k-means clustering)、层次聚类(Hierarchical Clustering)、基于密度聚类Mean Shift、基于密度聚类DBSCAN、高斯混合模型(GMM)与EM、基于图论聚类。
- 降维:主成分分析(PCA)、独立成分分析(ICA)、奇异值分解(SVD)、t-分布领域嵌入式算法(t-SNE)
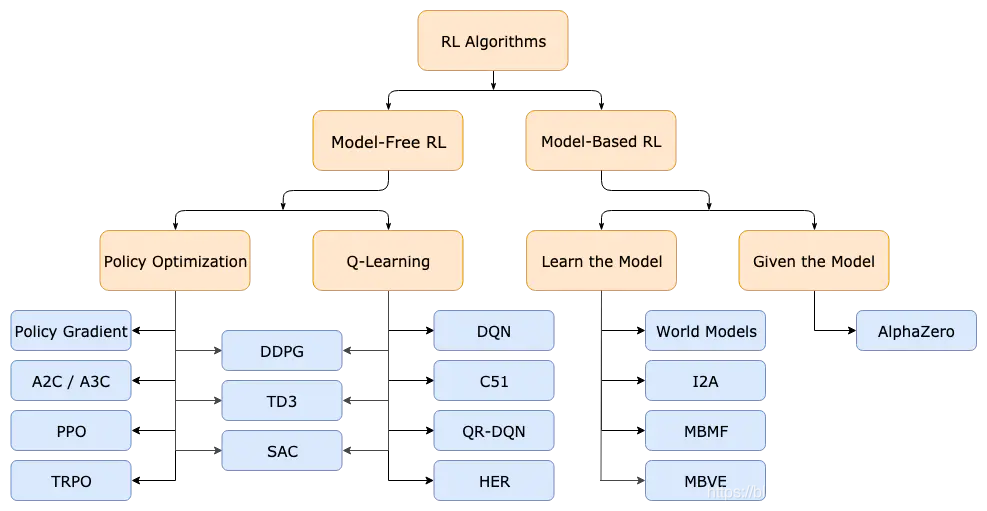
33、强化学习分为两大类:无模型(Model-Free)、有模型(Model-based)。
强化学习的算法分类
参考文献
1.ImageNet大规模视觉识别挑战(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)
2.CNN卷积神经网络 LeNet-5详解
3.卷积神经网络超详细介绍
4.卷积神经网络模型
5.卷积神经网络经典模型及其改进点学习汇总
6.卷积神经网络CNN(Convolutional Neural Network)
版权归原作者 胖墩会武术 所有, 如有侵权,请联系我们删除。