
前置准备:
VMware17
Tabby:https://github.com/Eugeny/tabby/releases/tag/v1.0.207
jdk-8u401:https://www.java.com/en/download/
hbase-1.3.1:https://archive.apache.org/dist/hbase/1.3.1/
hadoop-2.7.7:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
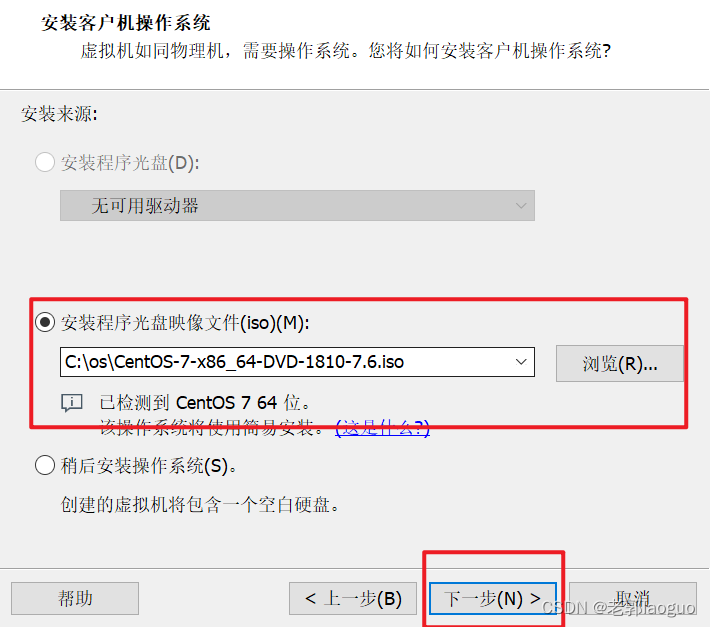
CentOS-7安装镜像:去找其他链接吧
打包在以下百度网盘链接里了
链接:https://pan.baidu.com/s/1VQGGVFOZ5uSo-9P-9reF9A?pwd=igcd
提取码:igcd
1、安装VMware17和Tabby
这里不再详细展开如何安装

2、安装centos7

3、配置静态ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33
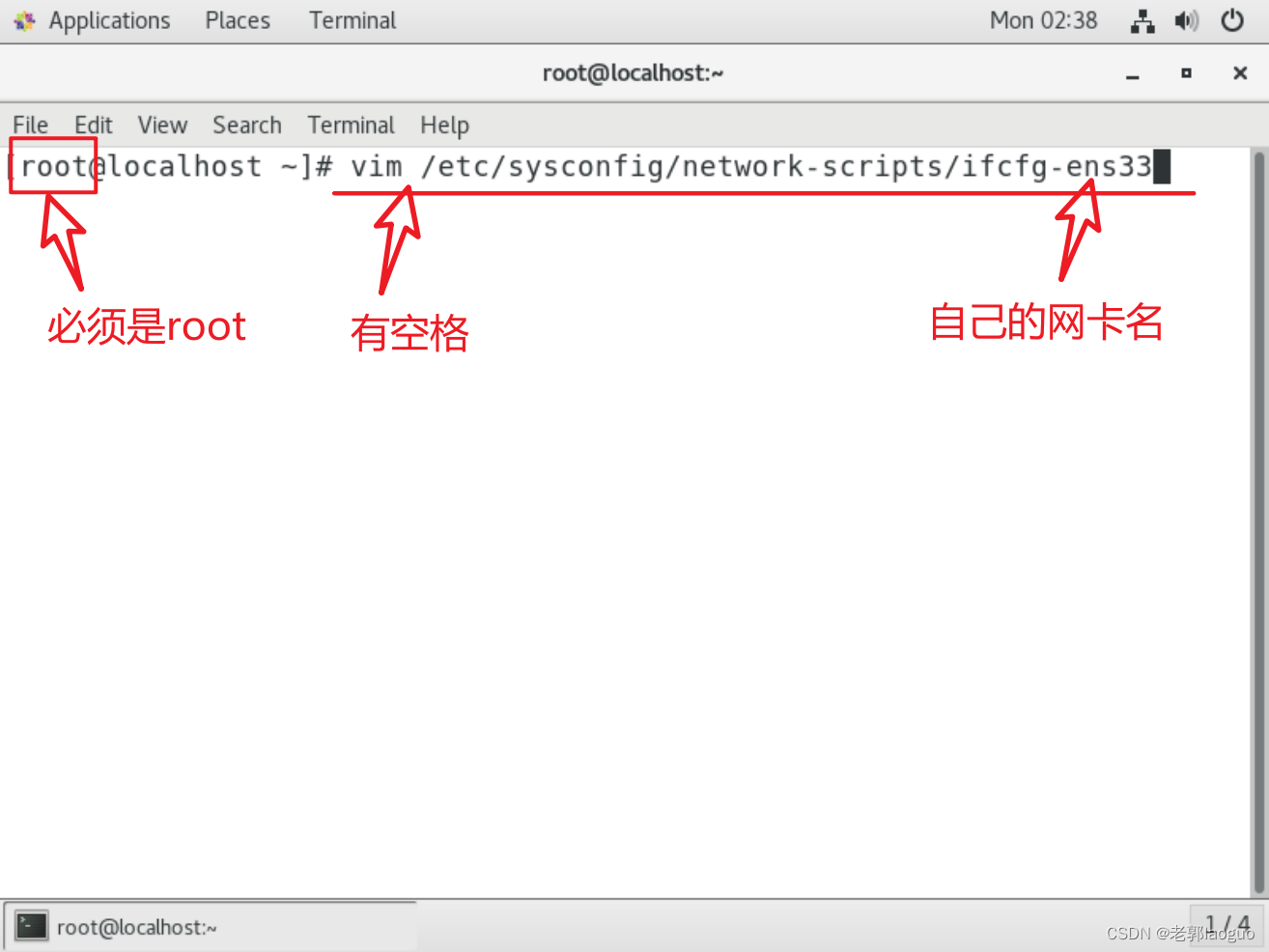
按a可以进入编辑模式
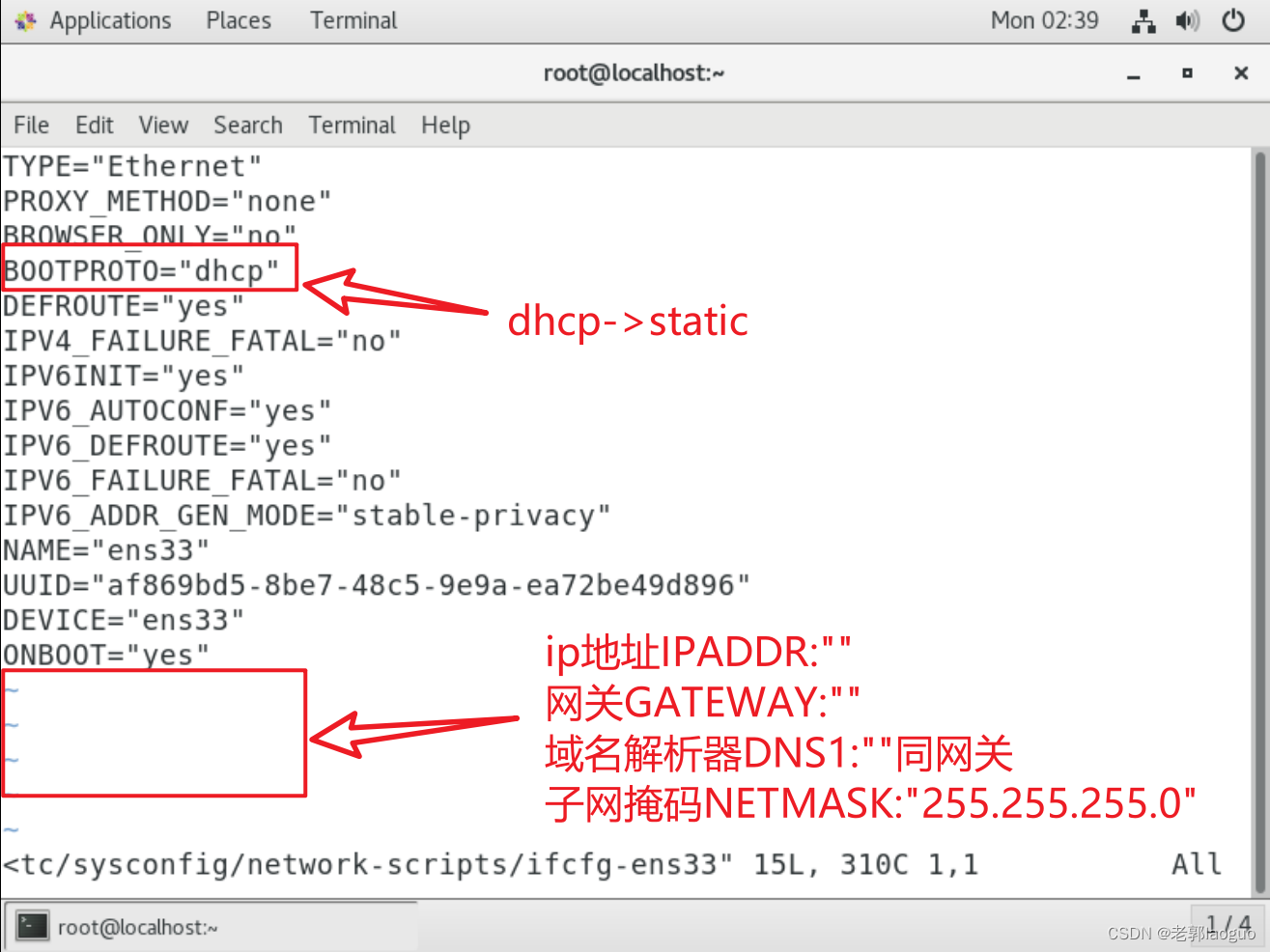
不会看自己网段的看下图

要改的
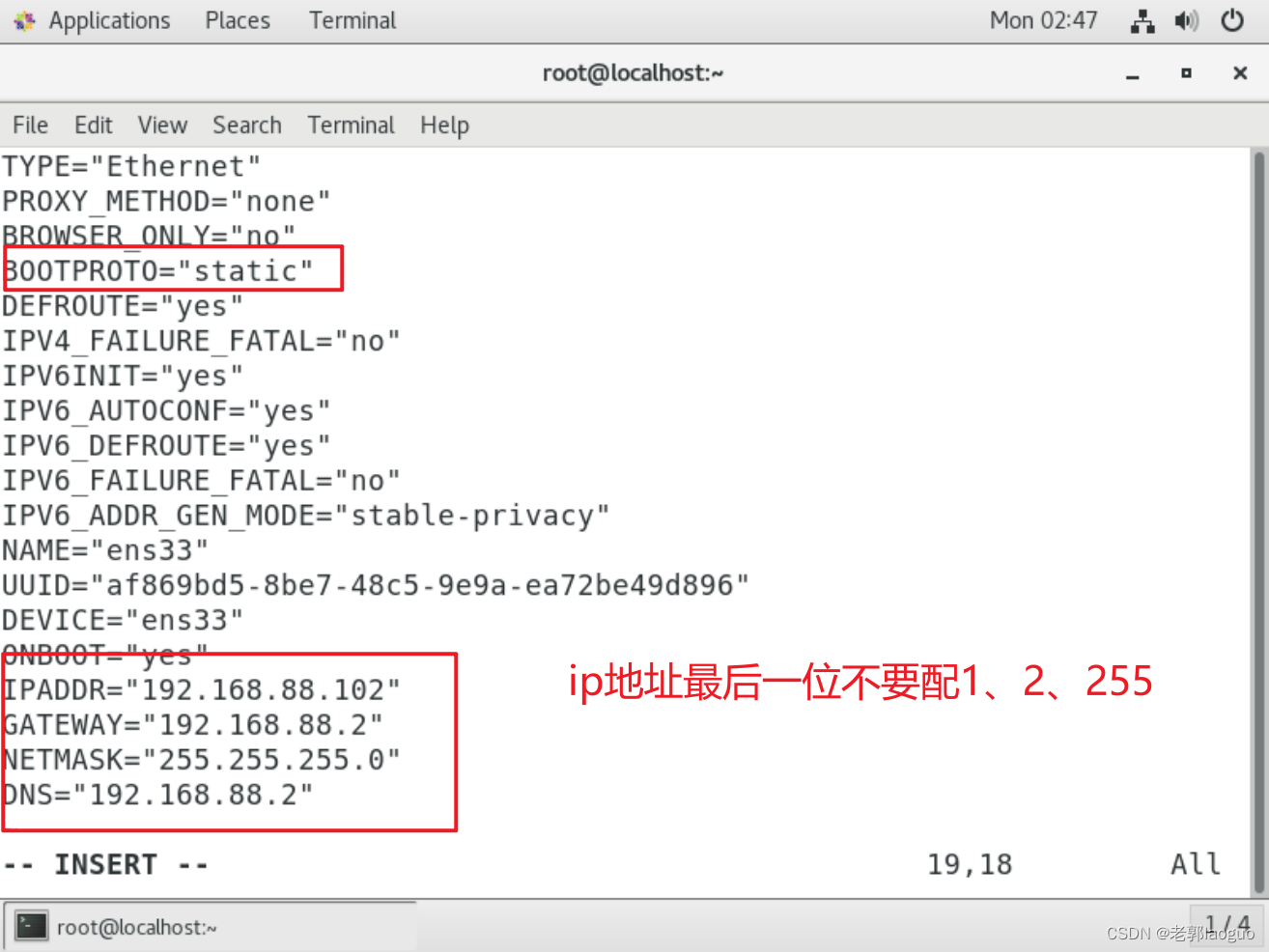
BOOTPROTO="static"
要新增的
IPADDR="192.168.88.102"
GATEWAY="192.168.88.2"
NETMASK="255.255.255.0"
DNS="192.168.88.2"
配完后如下图
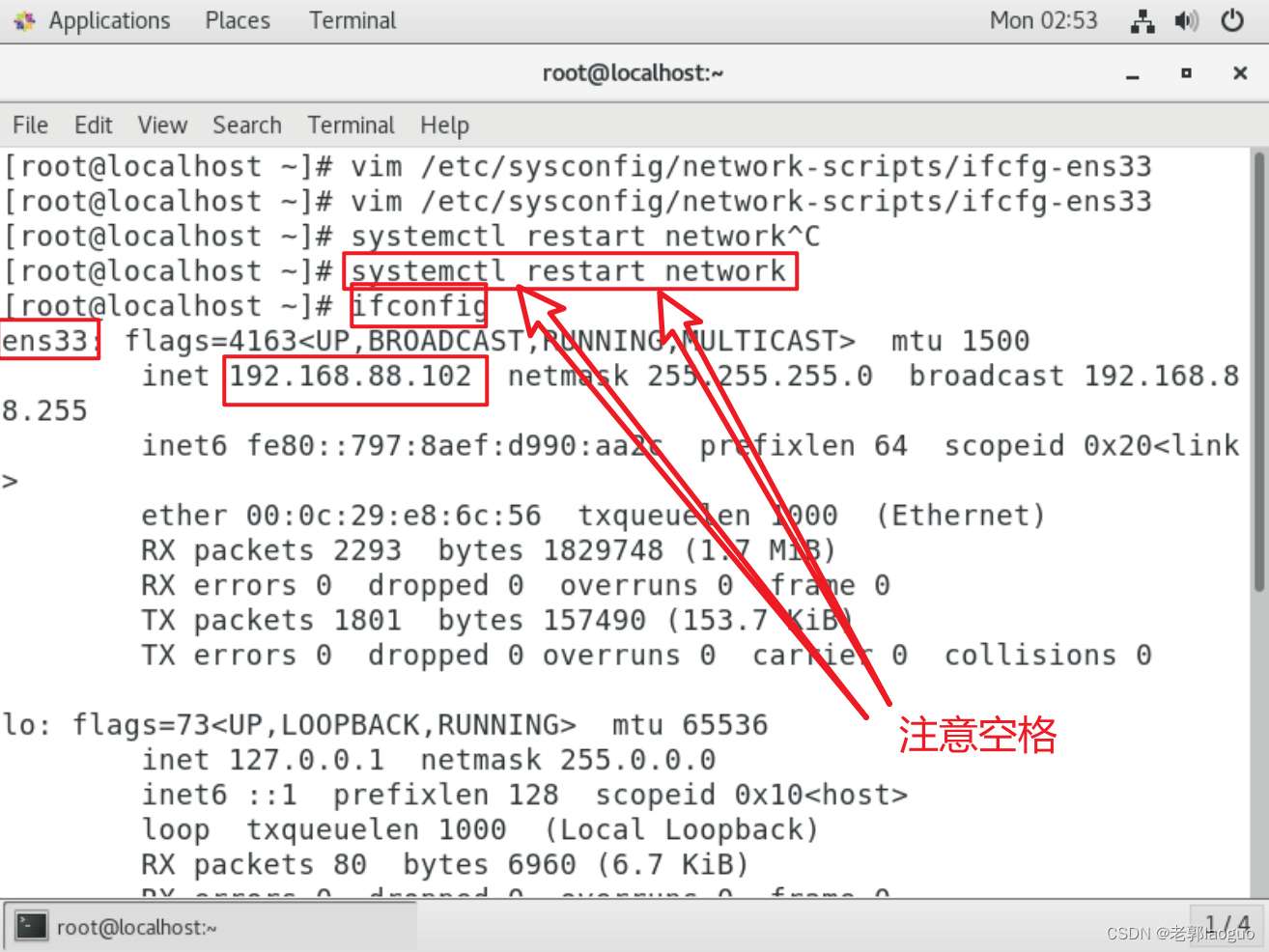
注意保存是先按esc键进入命令模式再输入:wq回车
重启网络
systemctl restart network
查看下ip
ifconfig
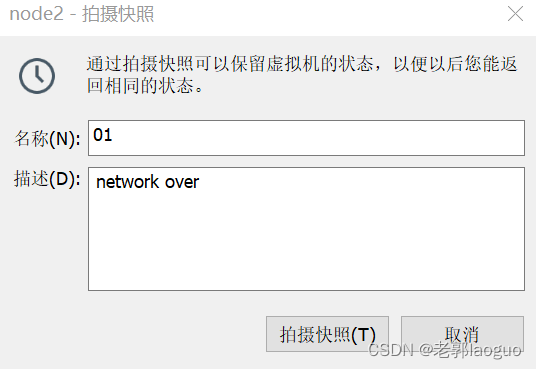
打个快照保存下,然后转战tabby
右键左侧当前虚拟机的名称选择快照->拍摄快照
4、Tabby连接虚拟机并上传文件
选择ssh连接
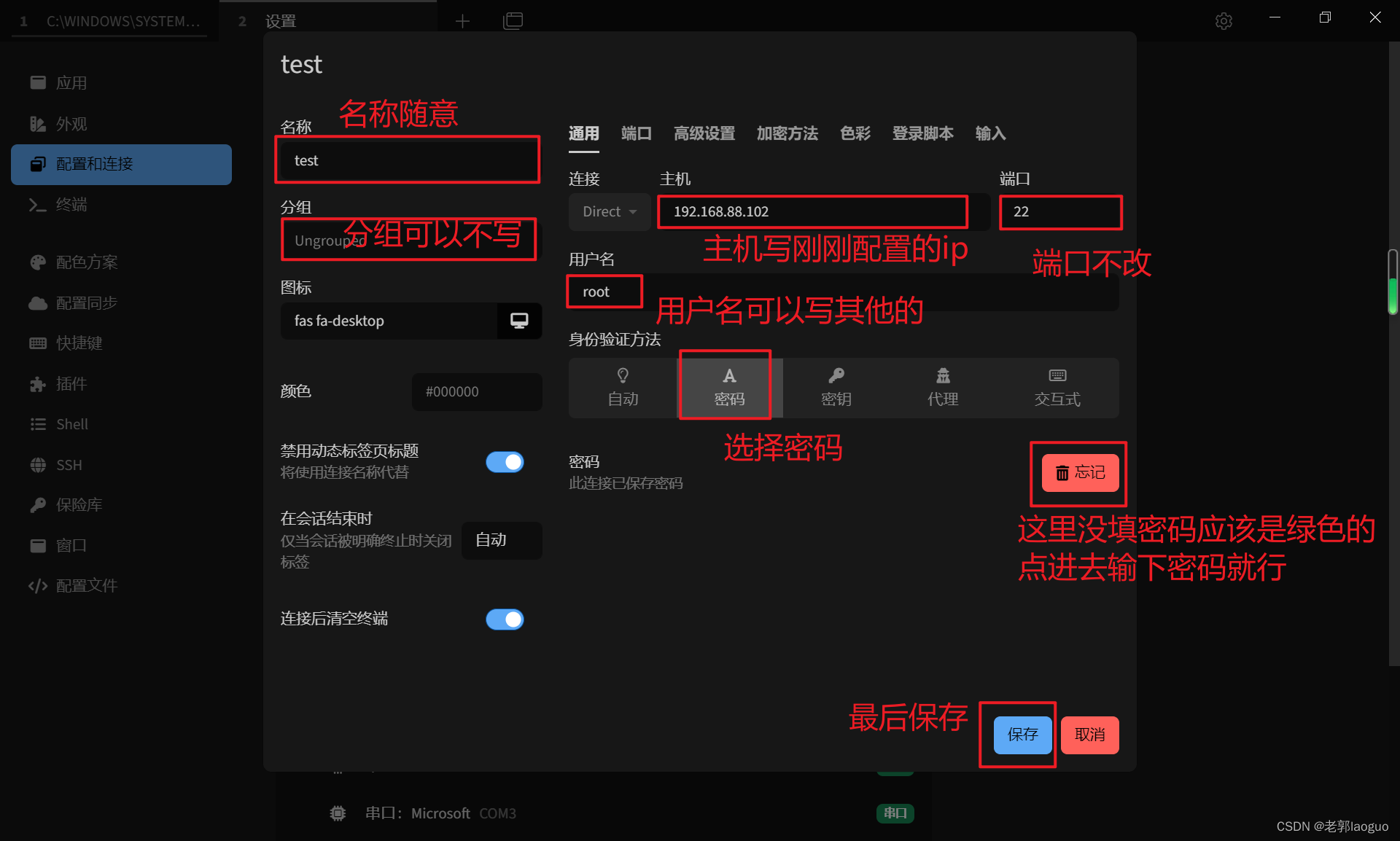
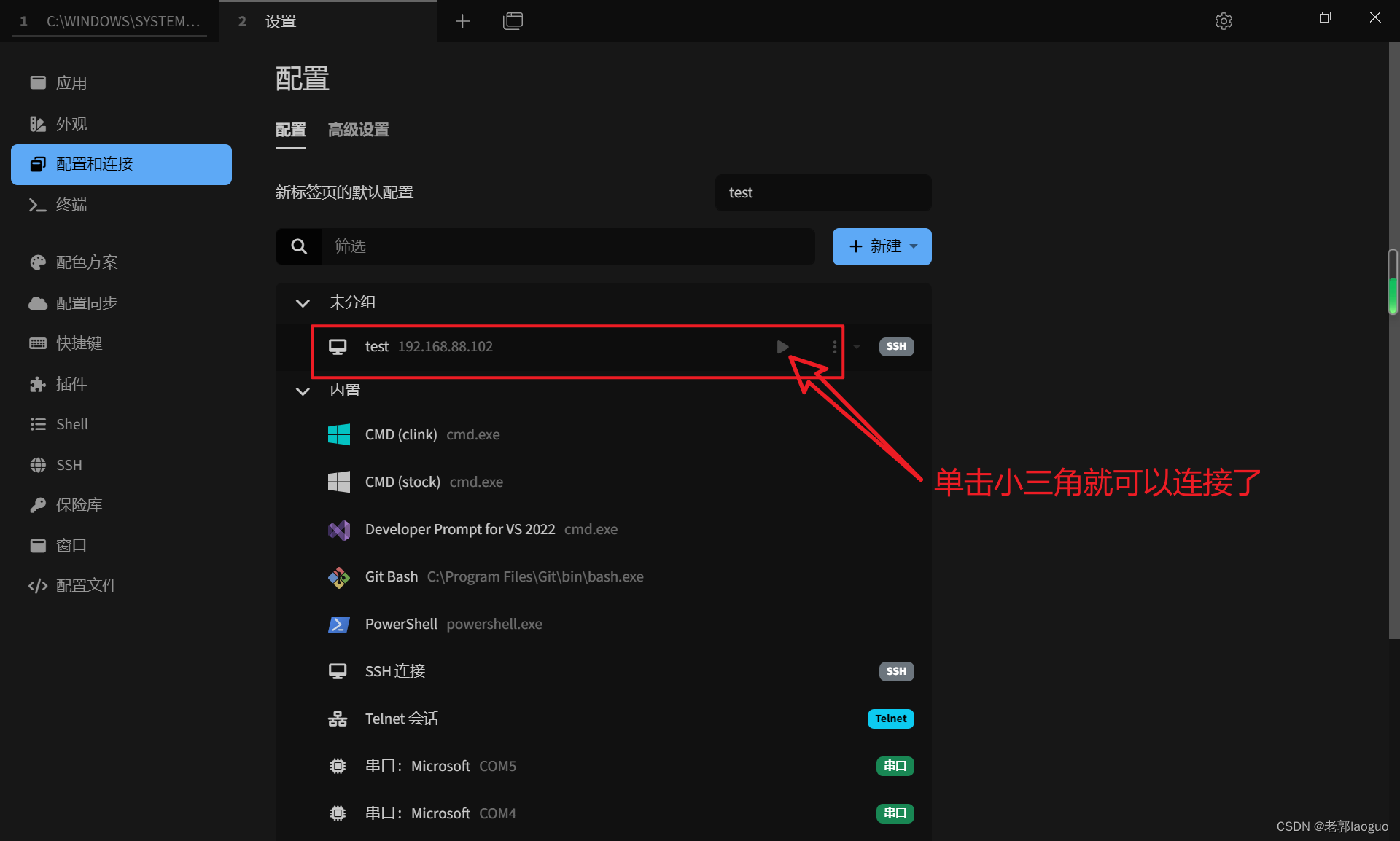
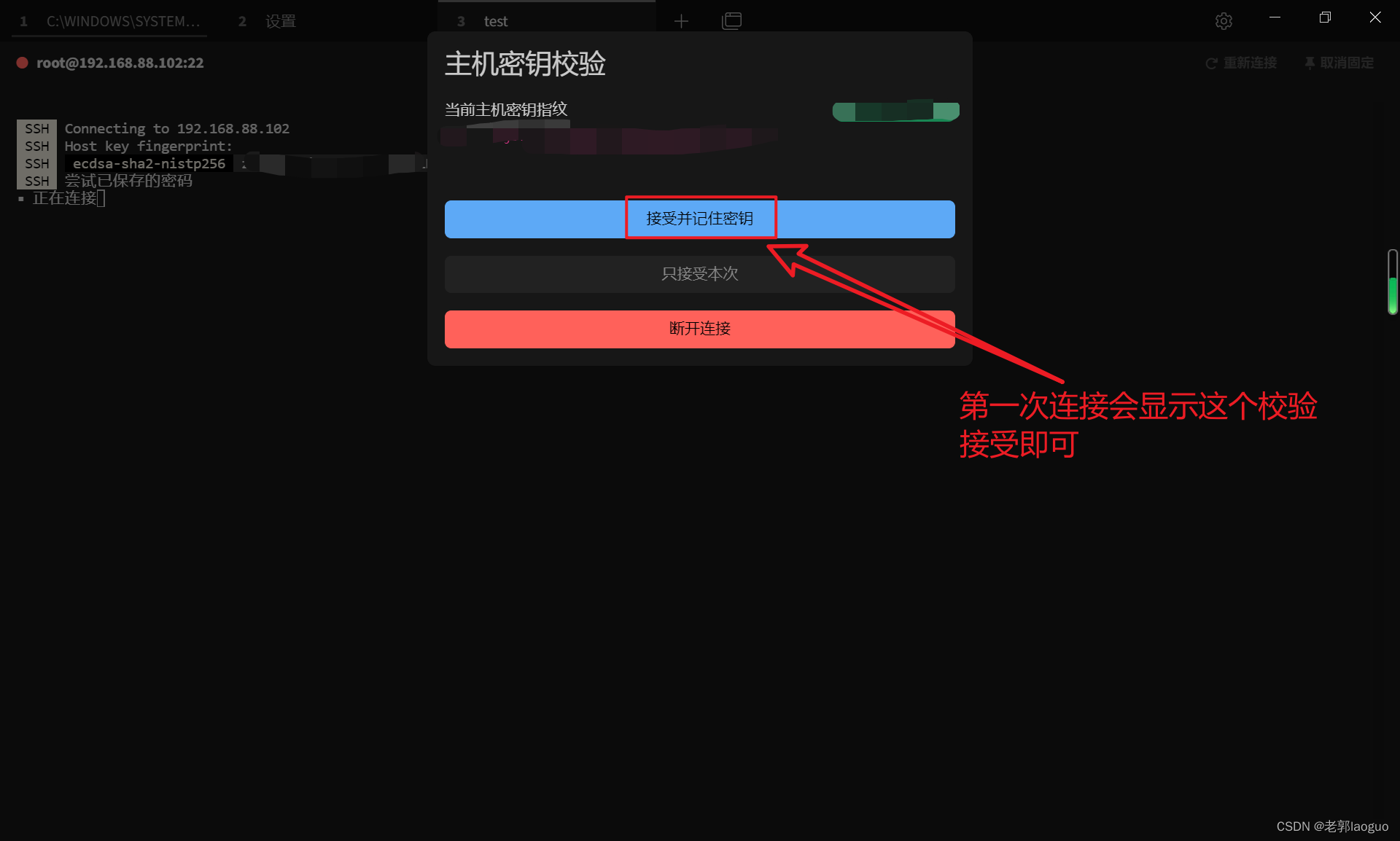
Tabby上传文件
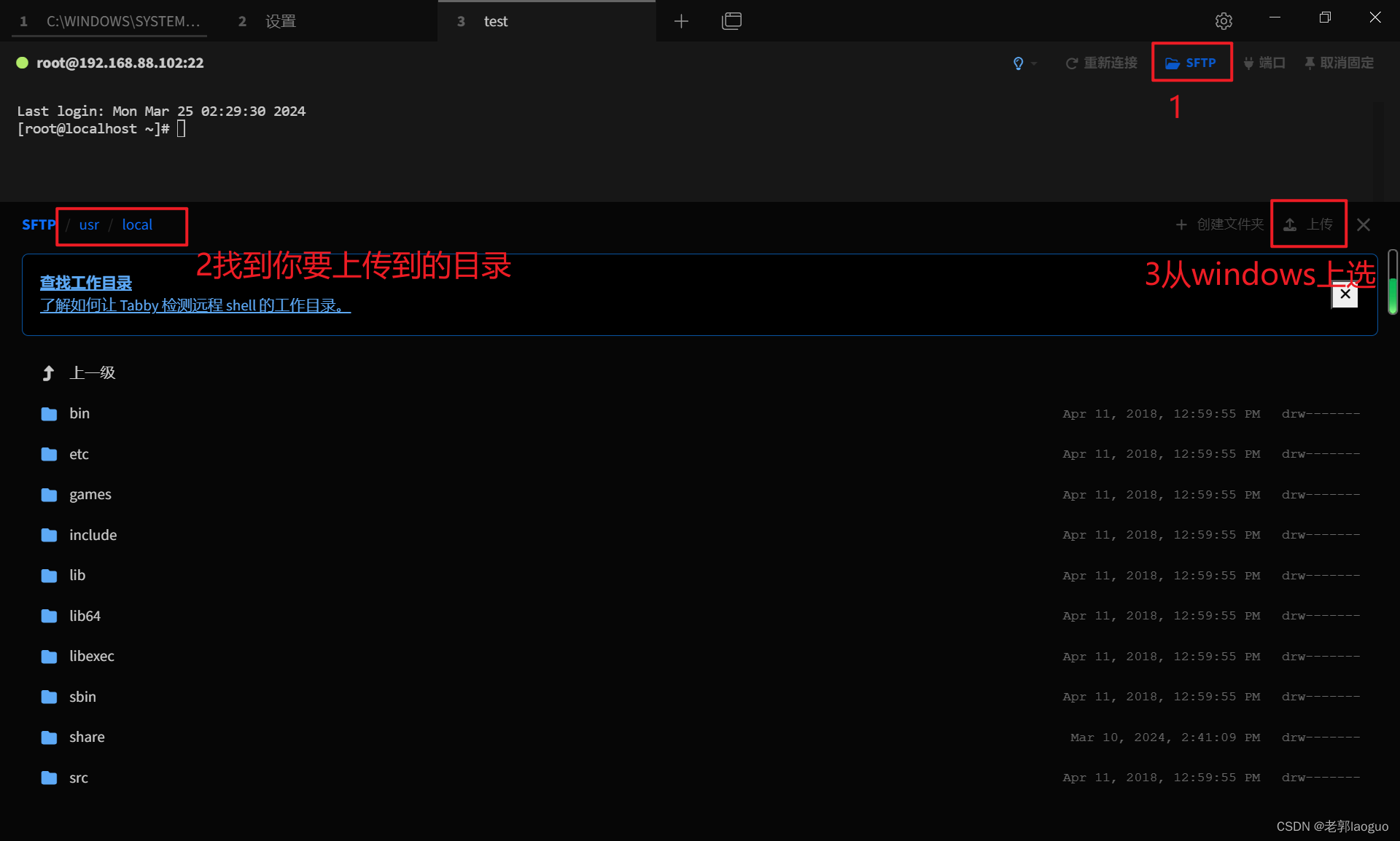
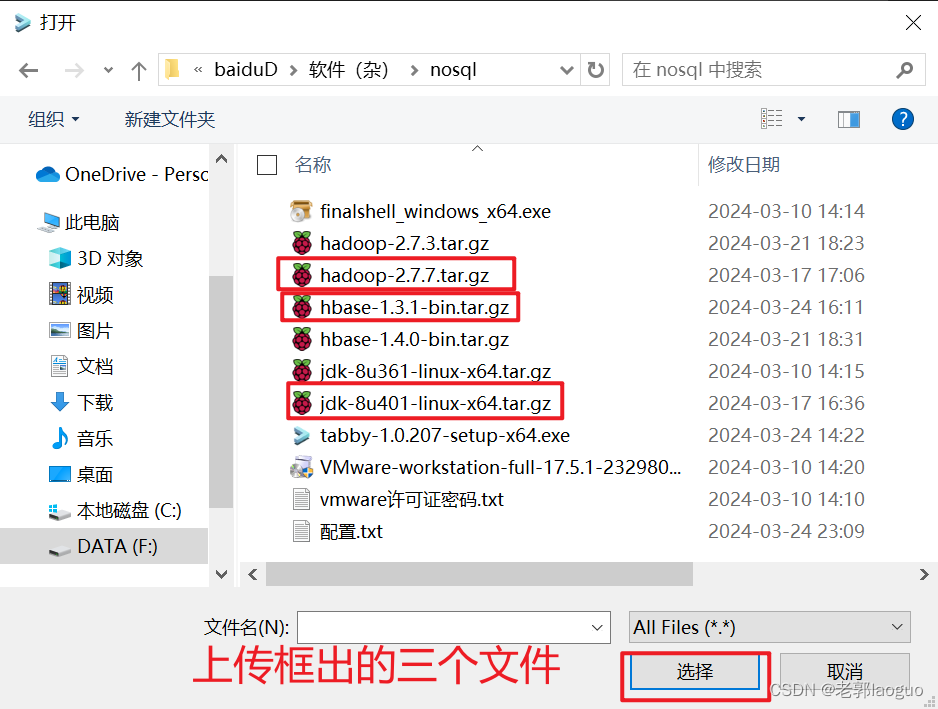
查看一下上传的目录
ls /usr/local/
5、解压并配置环境变量
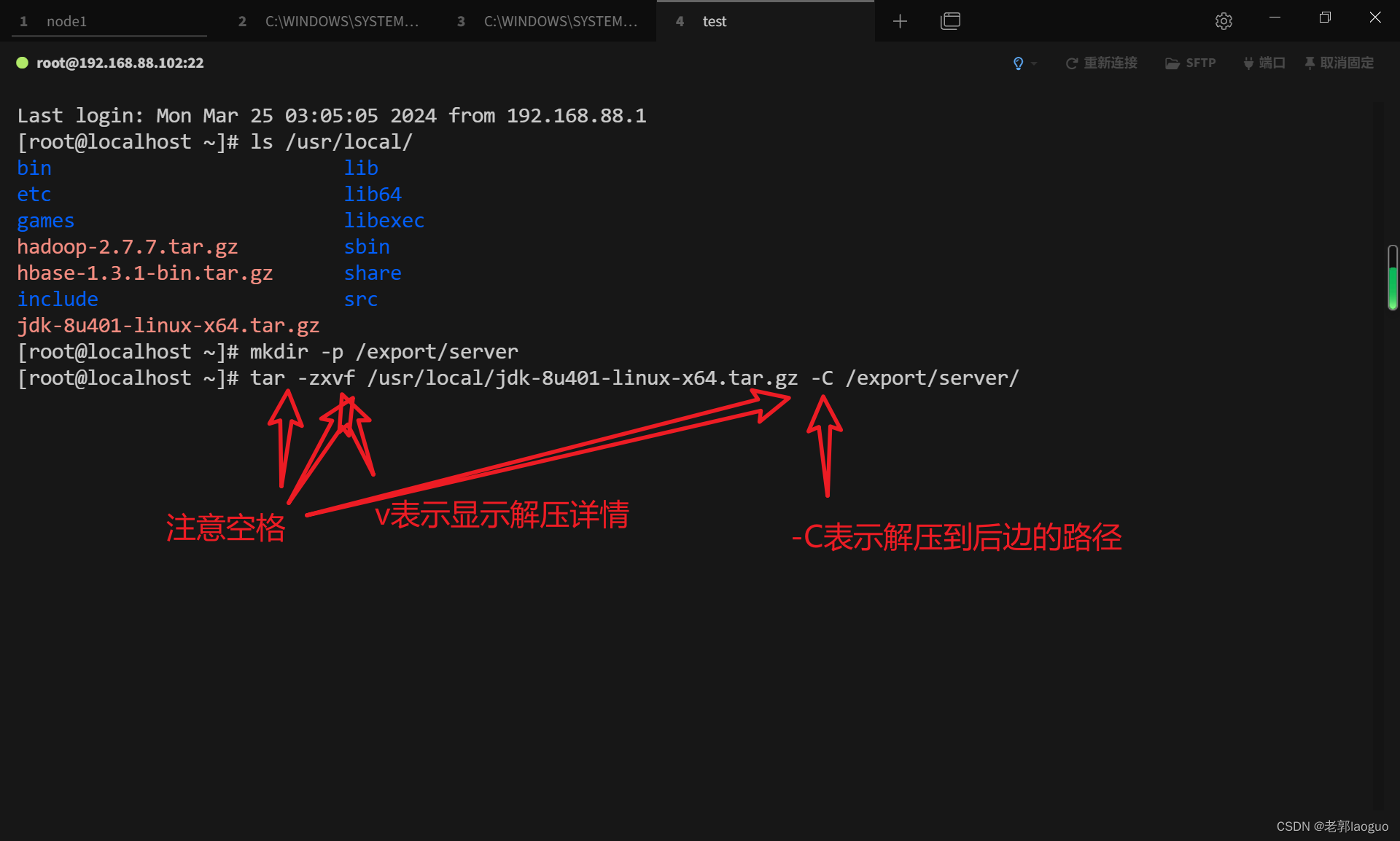
先给jdk创建一个新目录
mkdir -p /export/server
解压jdk:
tar -zxvf /usr/local/jdk-8u401-linux-x64.tar.gz -C /export/server/
解压hadoop:
tar -zxvf /usr/local/hadoop-2.7.7.tar.gz -C /usr/local/
解压hbase:
tar -zxvf /usr/local/hbase-1.3.1-bin.tar.gz -C /usr/local/
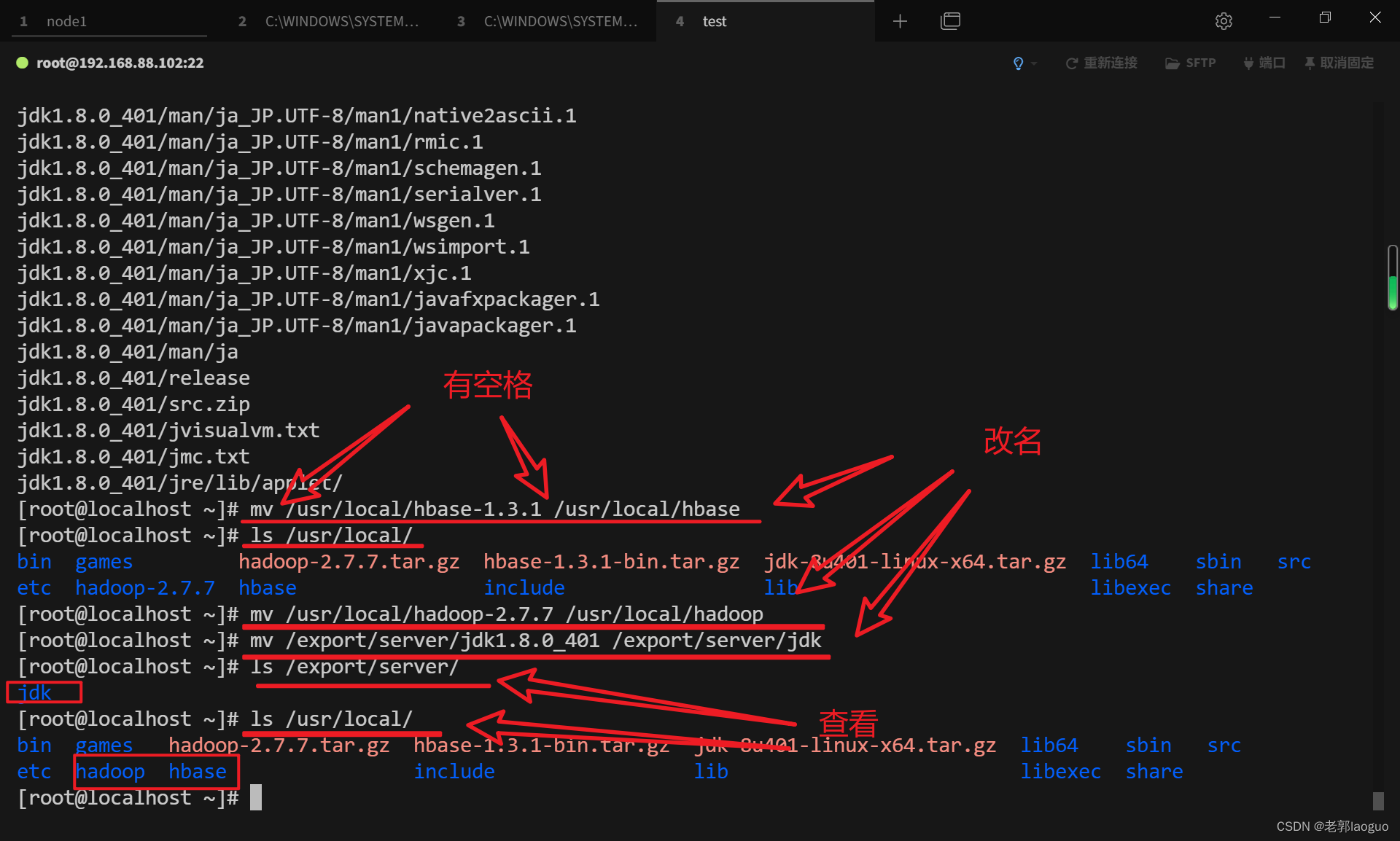
改名jdk:
mv /export/server/jdk1.8.0_401 /export/server/jdk
改名hadoop:
mv /usr/local/hadoop-2.7.7 /usr/local/hadoop
改名hbase:
mv /usr/local/hbase-1.3.1 /usr/local/hbase
进入环境变量文件:
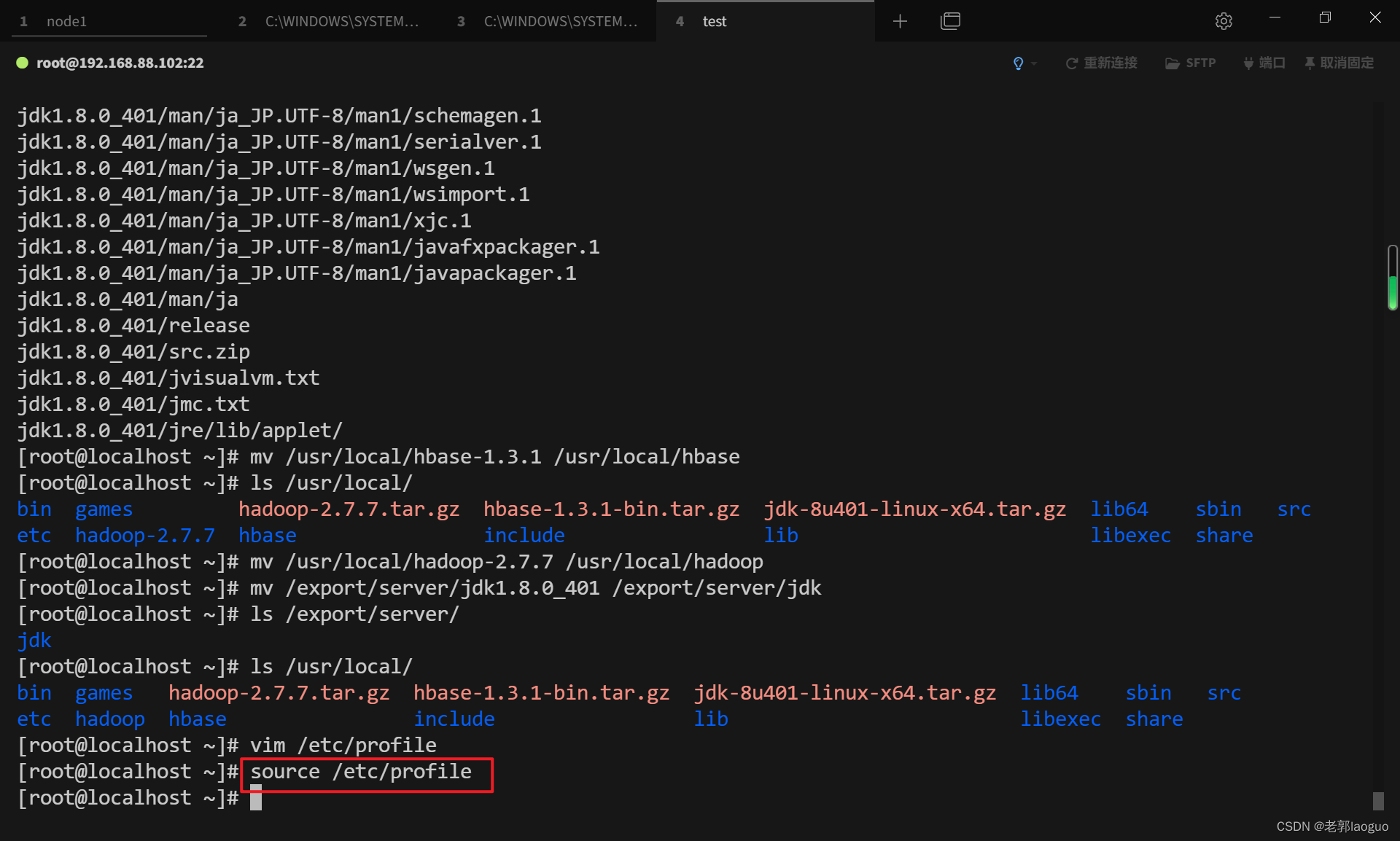
vim /etc/profile
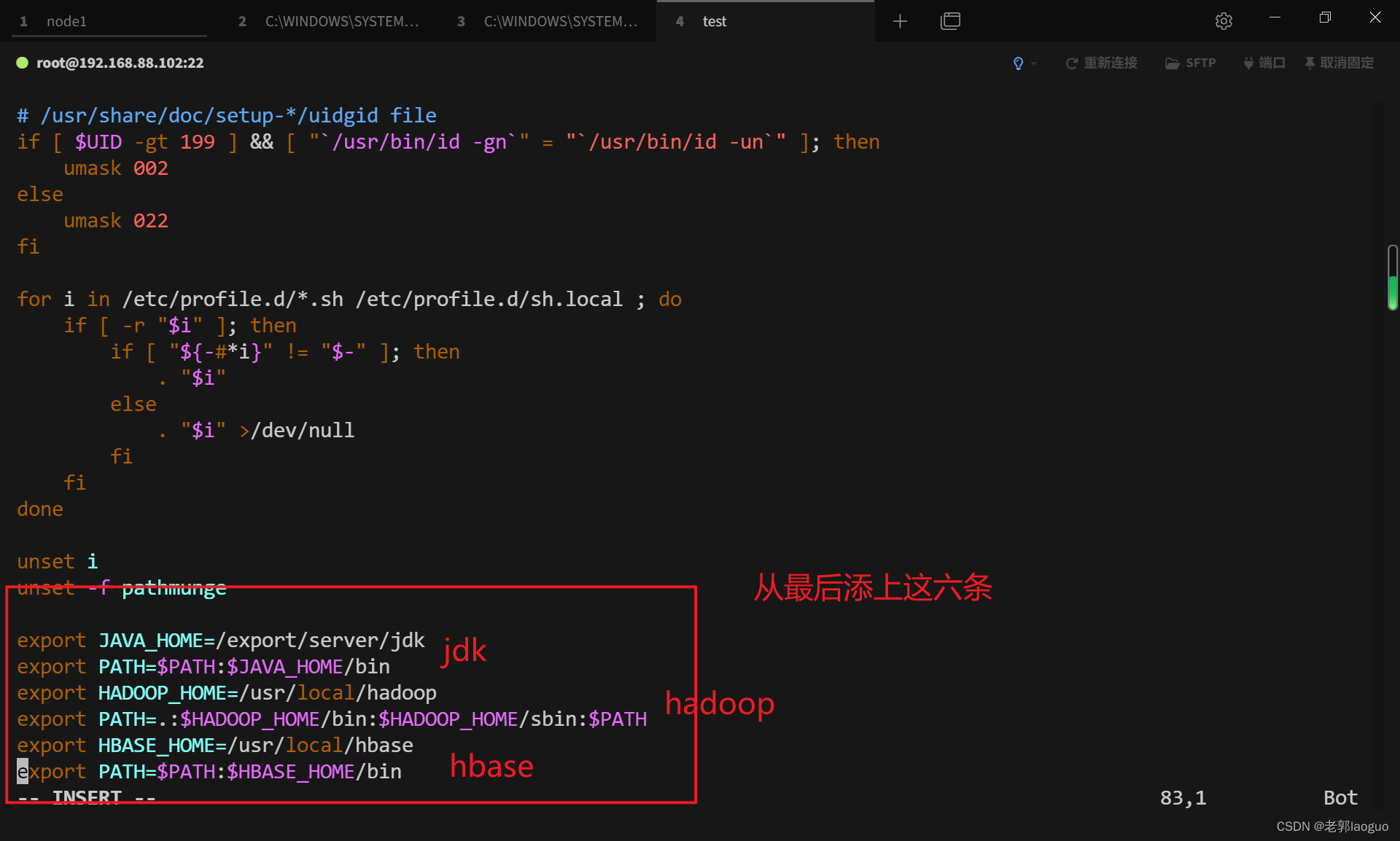
应用环境变量:
source /etc/profile
6、一些其他的基础配置
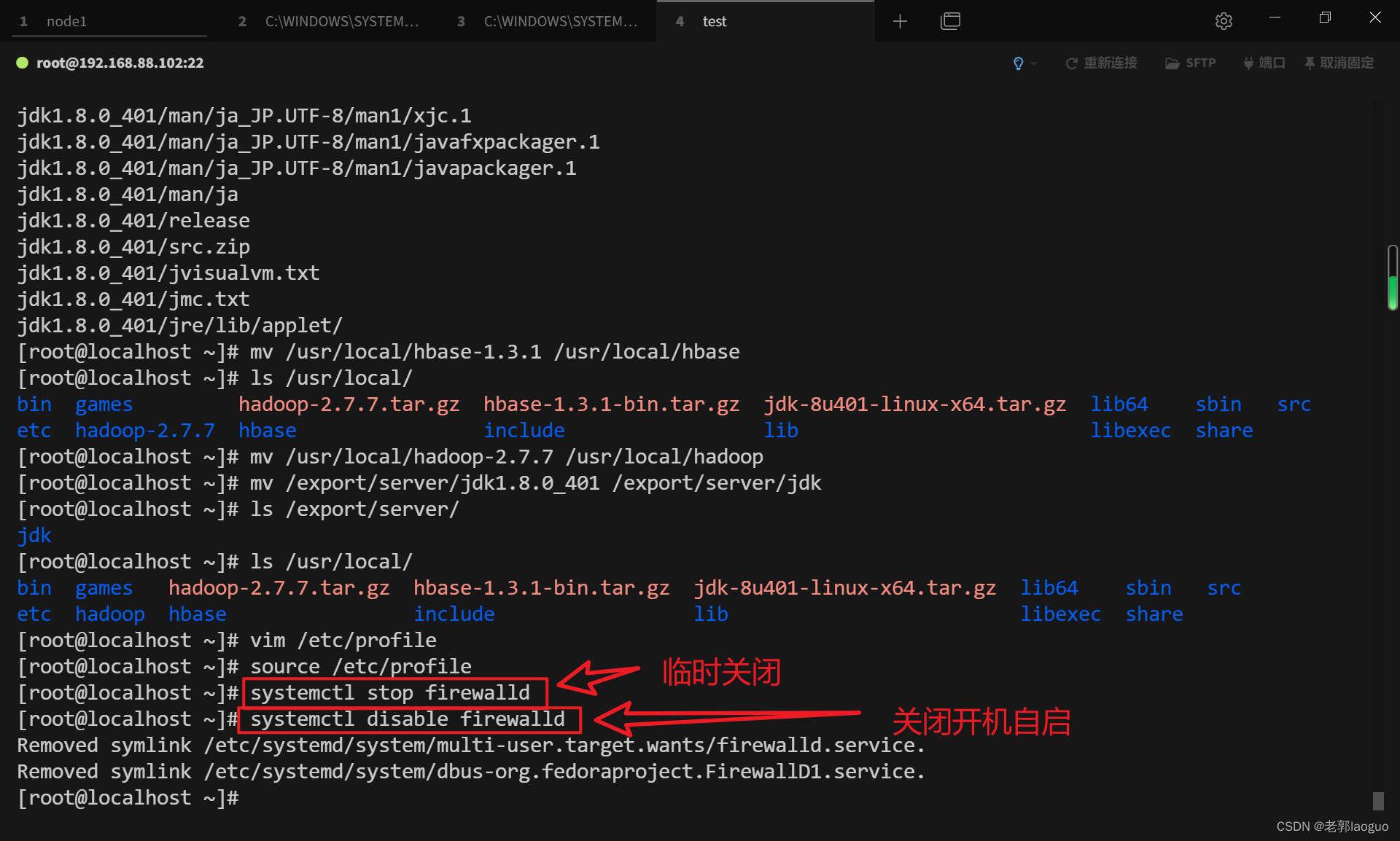
关闭防火墙
关闭本次:
systemctl stop firewalld
关闭开机自启:
systemctl disable firewalld
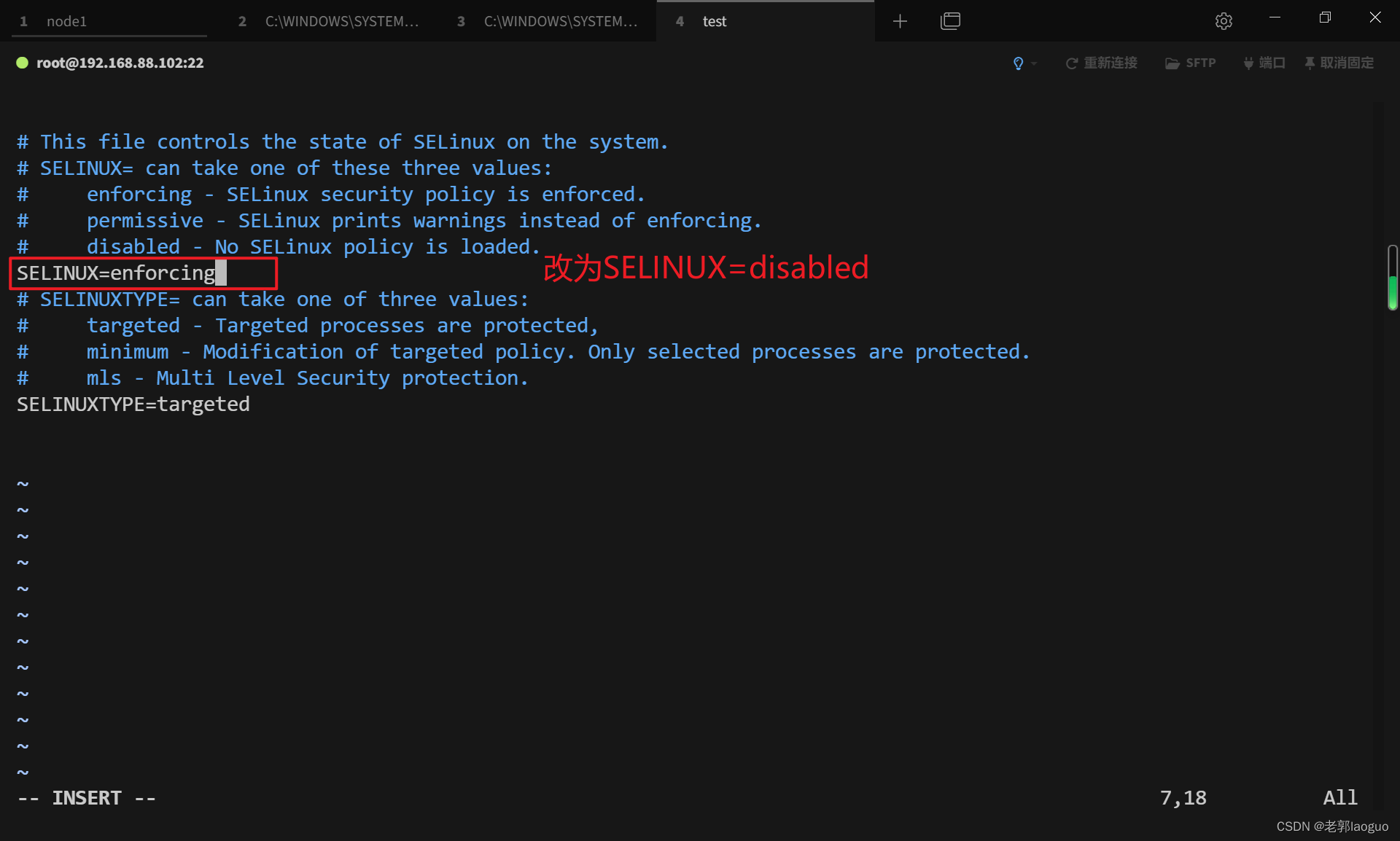
关闭selinux
临时关闭:
setenforce 0
修改配置文件:
vim /etc/sysconfig/selinux
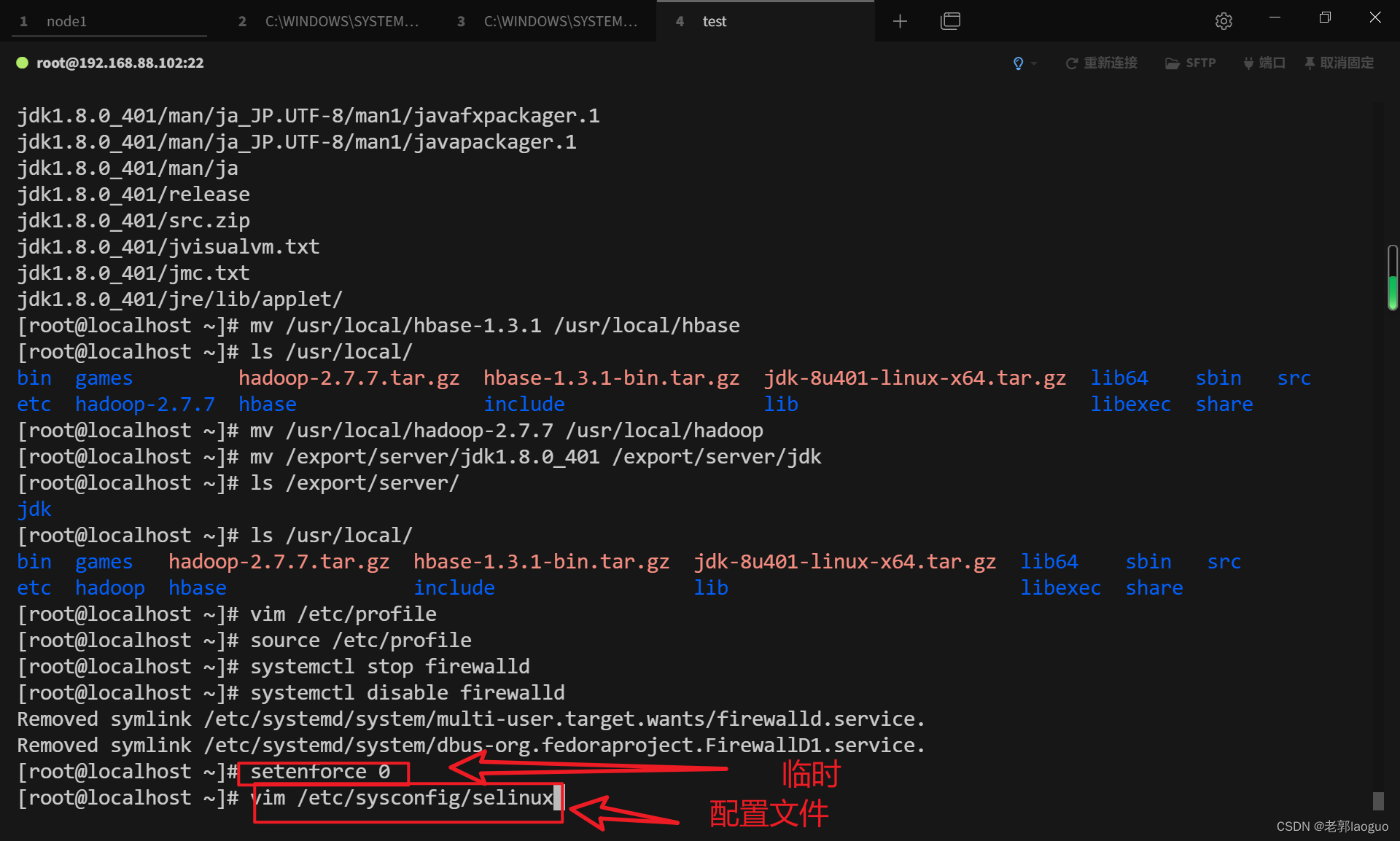
SELINUX=disabled
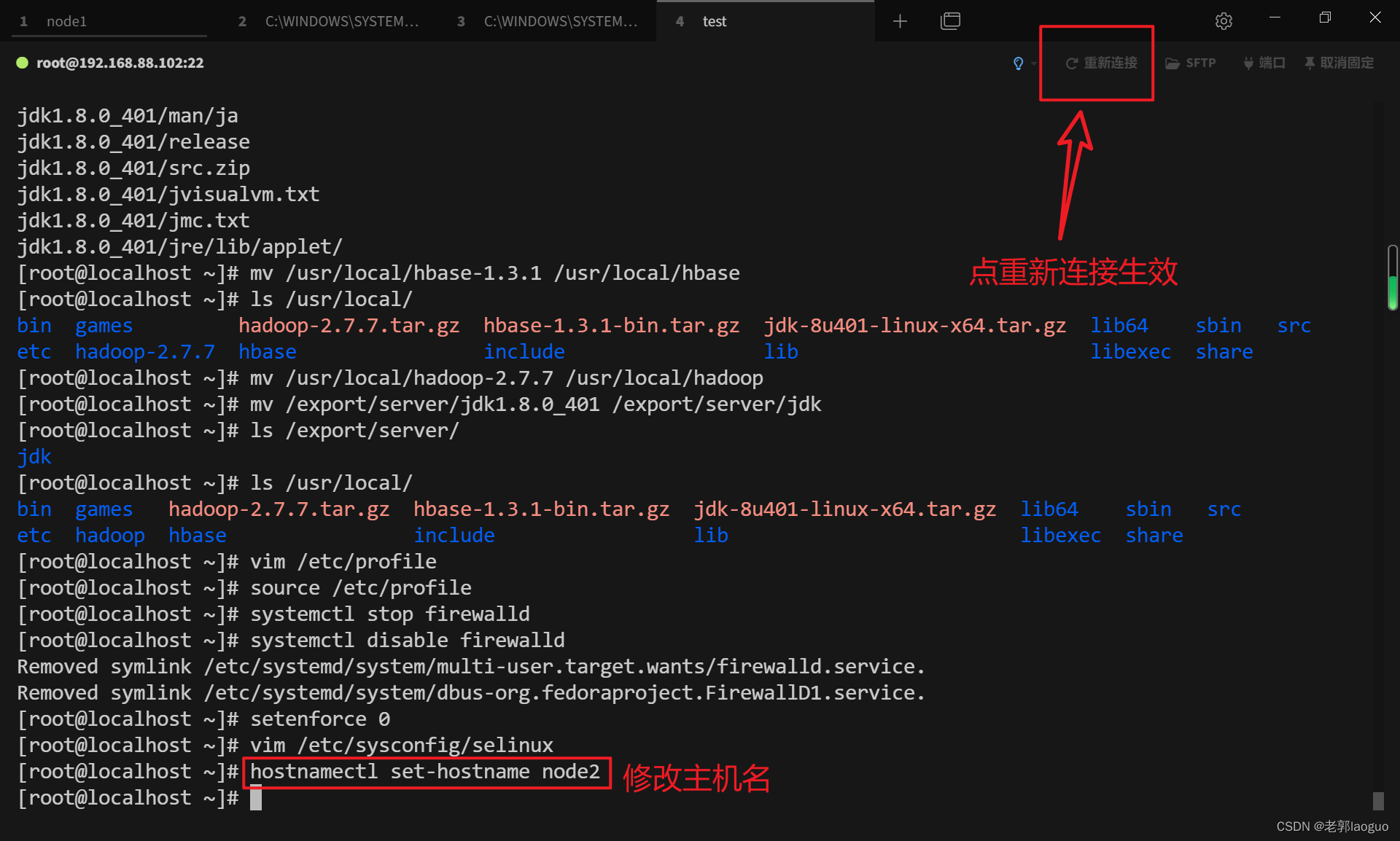
更改主机名(这里的主机名要与后边配置hadoop和hbase时完全一致):
hostnamectl set-hostname node2
修改hosts映射文件:
vim /etc/hosts
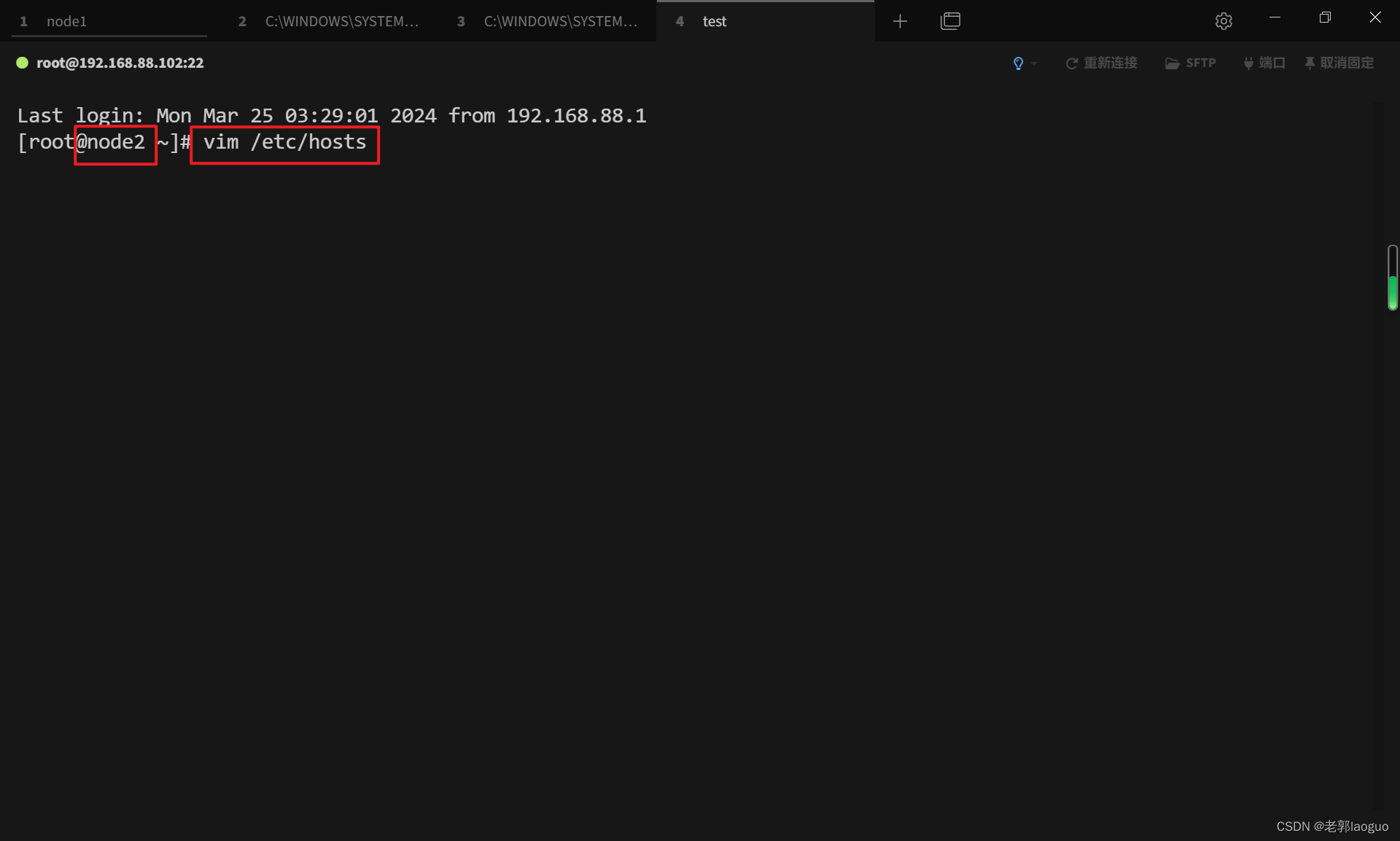
在里面添加一行:自己的ip(刚配的)+主机名
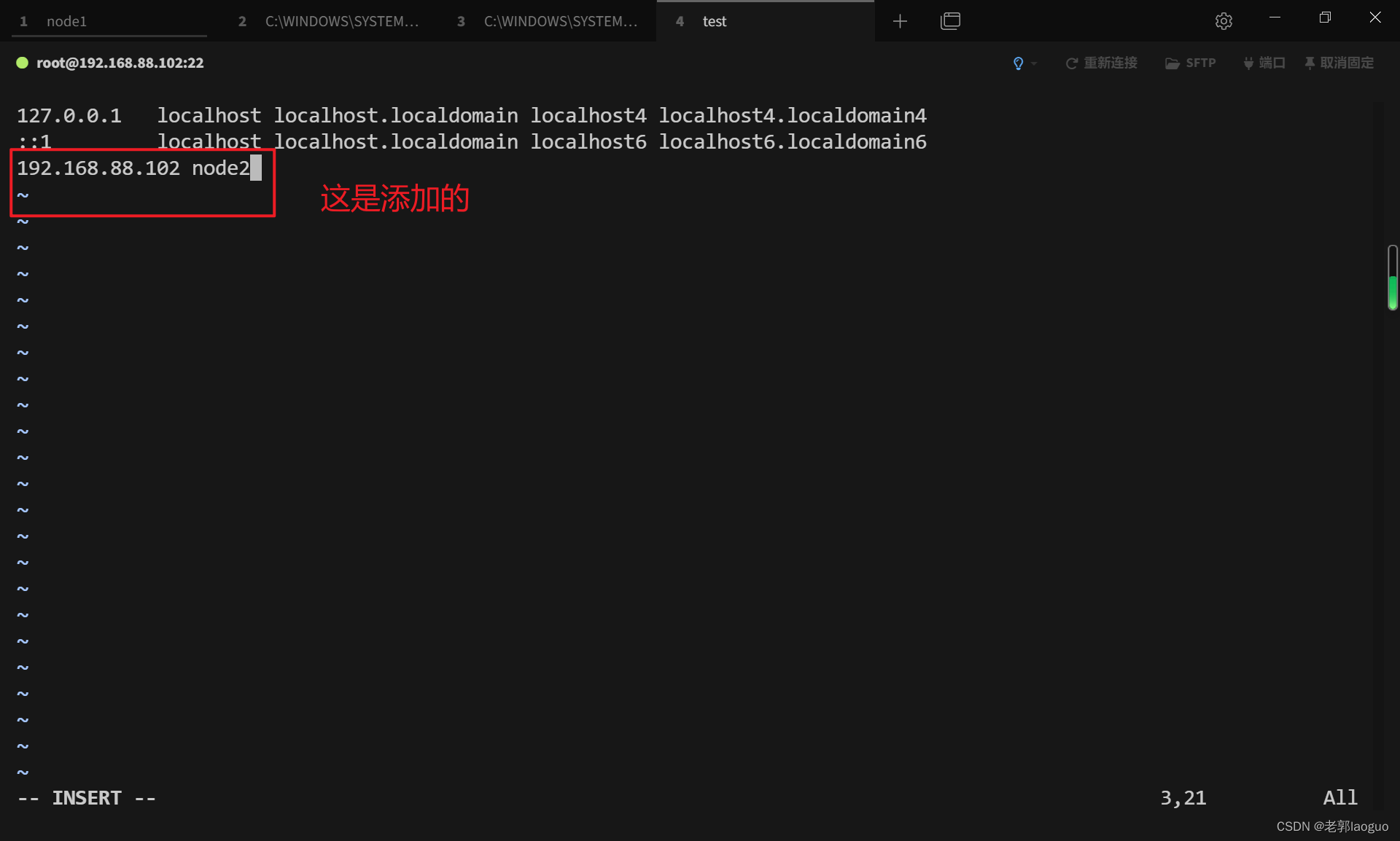
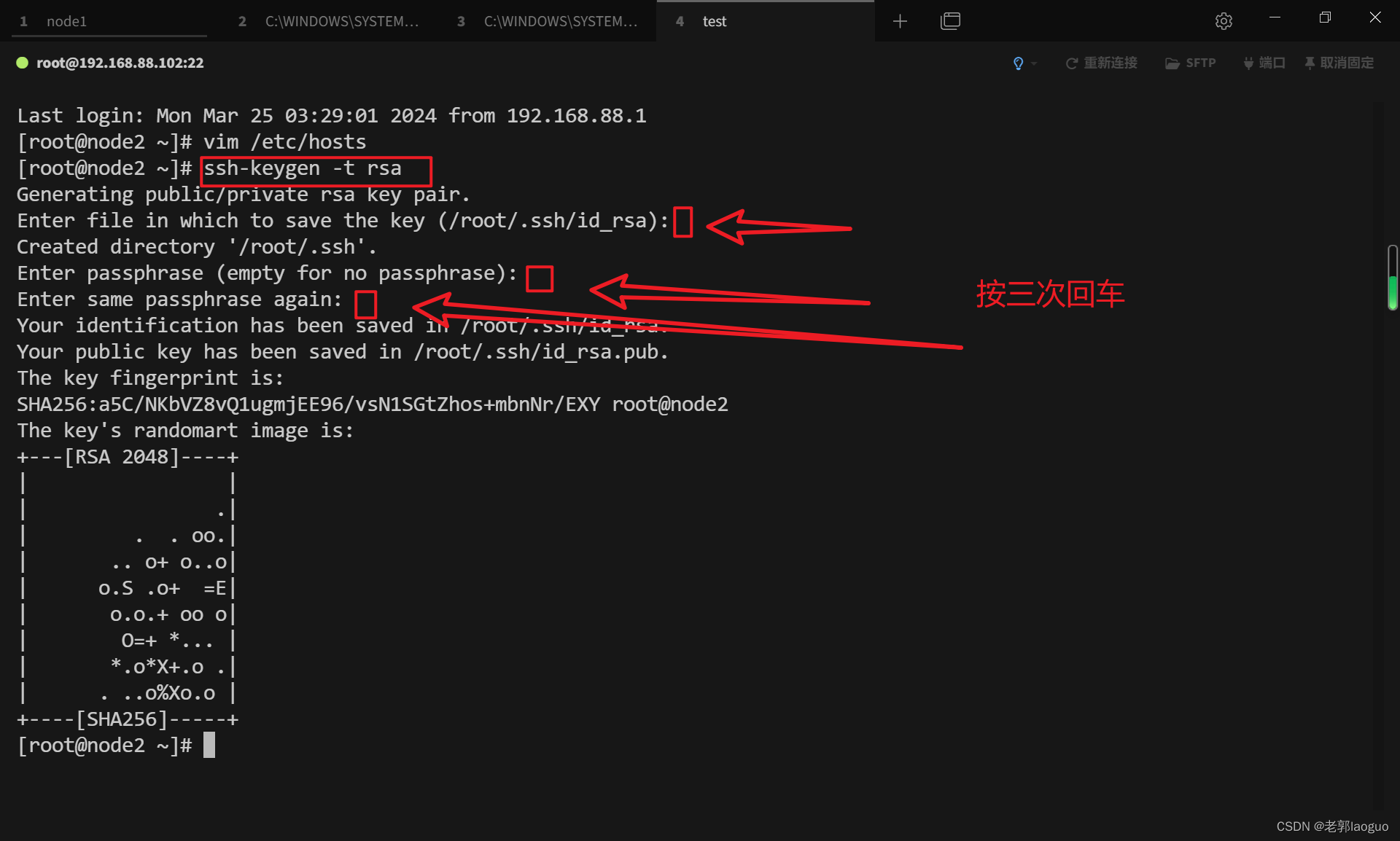
配置ssh免密登录:
ssh-keygen -t rsa
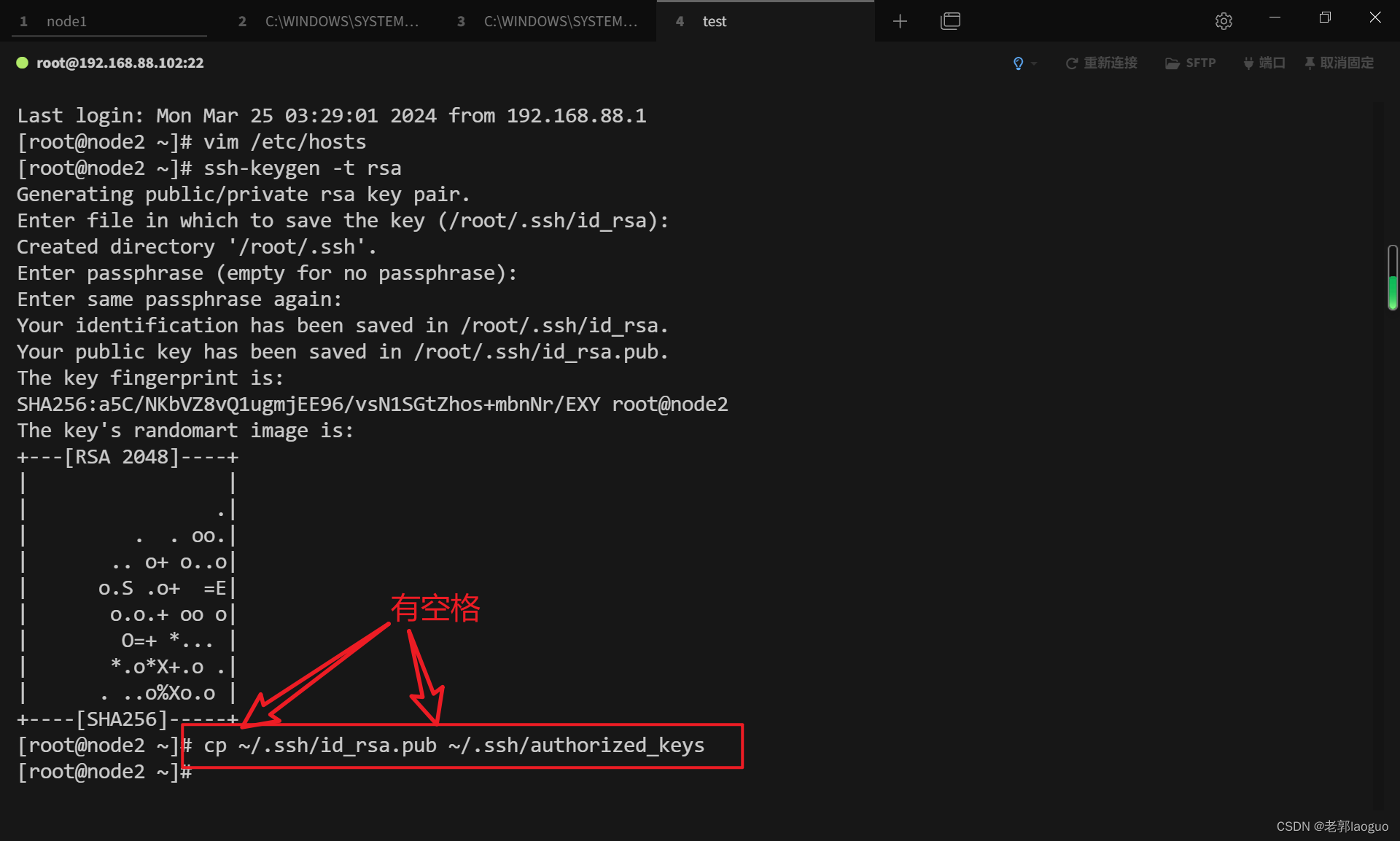
创建密钥文件:
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
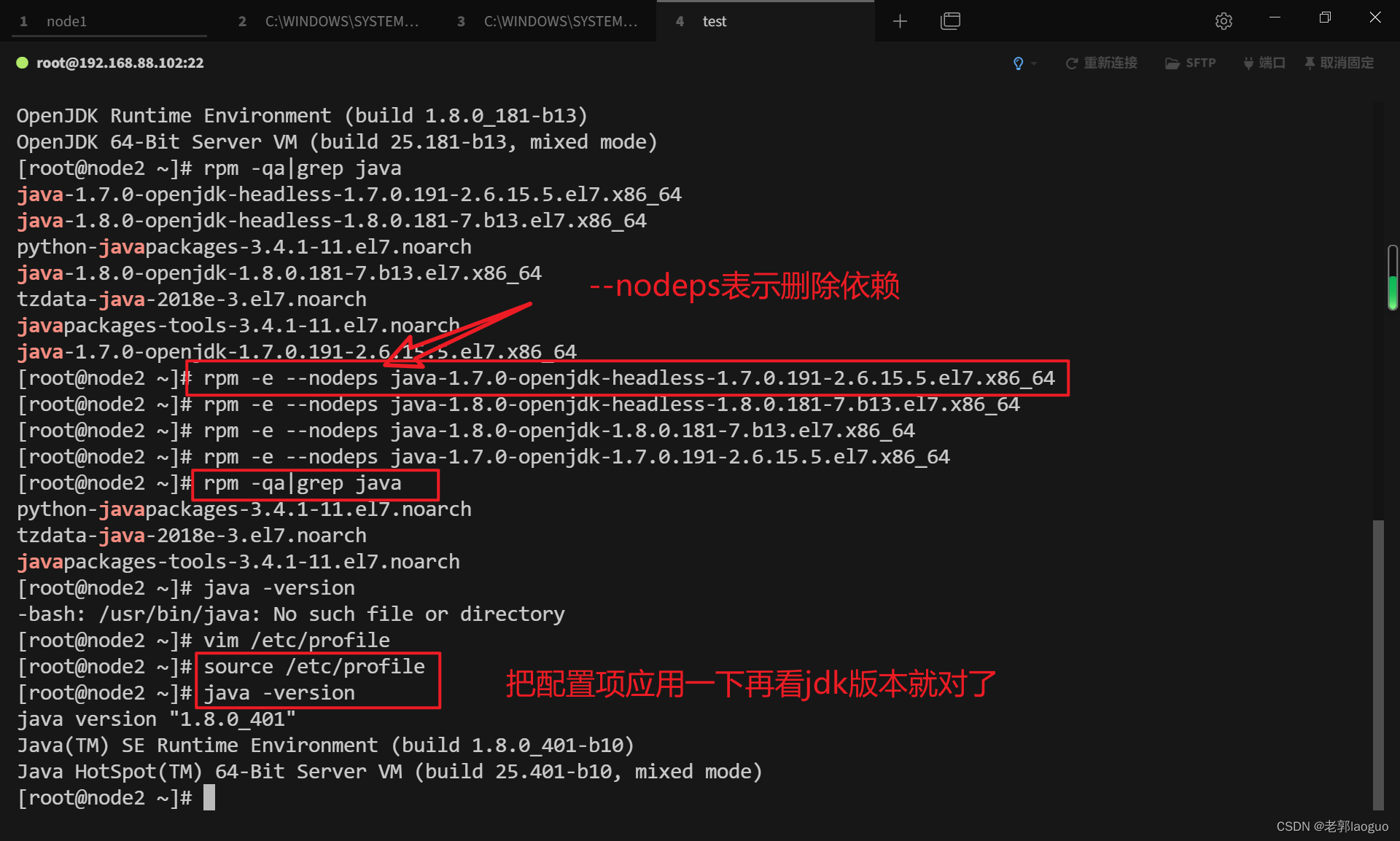
如果查看Java版本时(java -version)显示的不是1.8.0.401可以删除掉本机上自带的其他jdk
查看本机已安装jdk命令:
rpm -qa|grep java
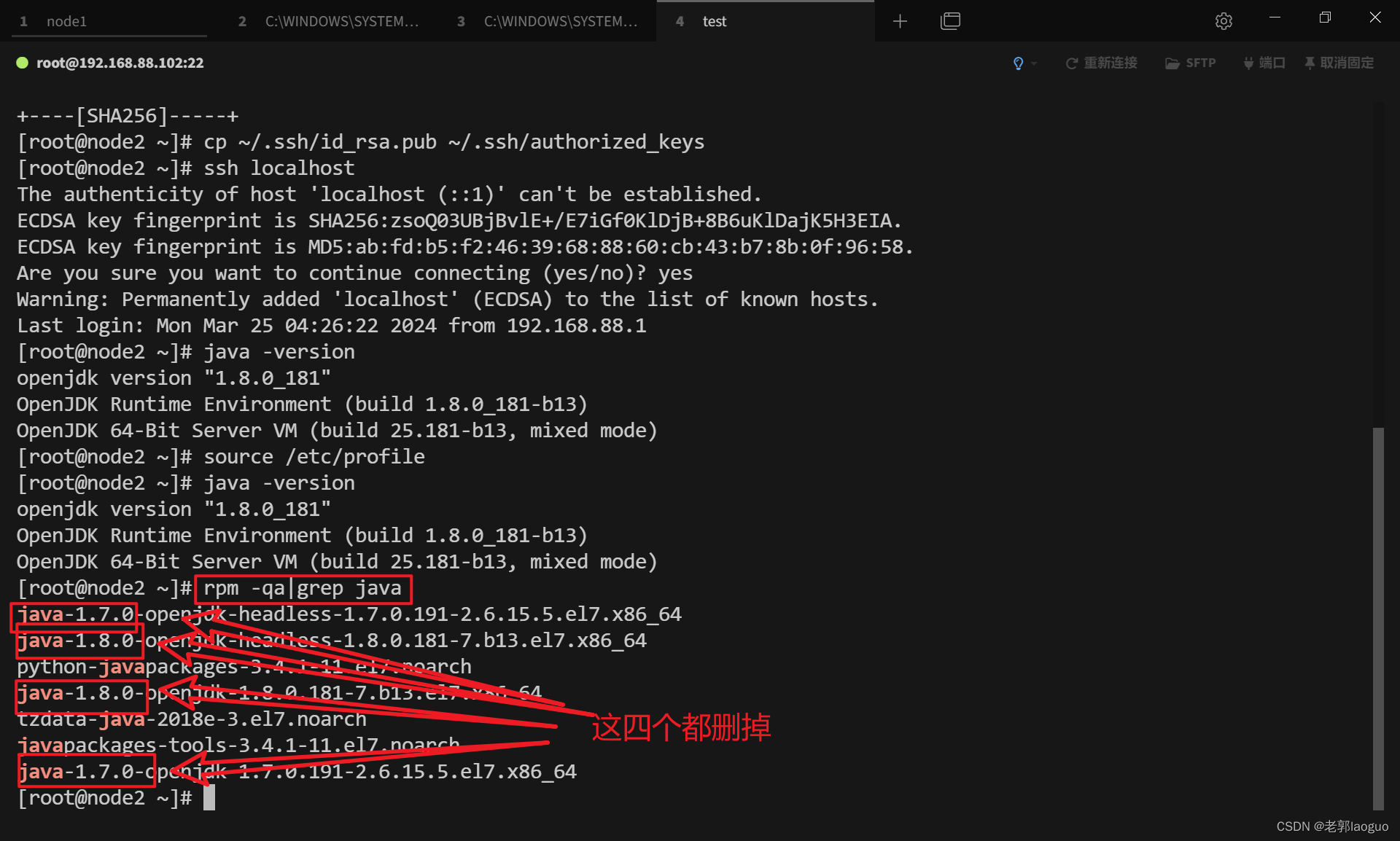
删除命令:rpm -e –nodeps xxxxxx(xxxxxx指代你要删除的软件,示例见下图)
7、配置hadoop
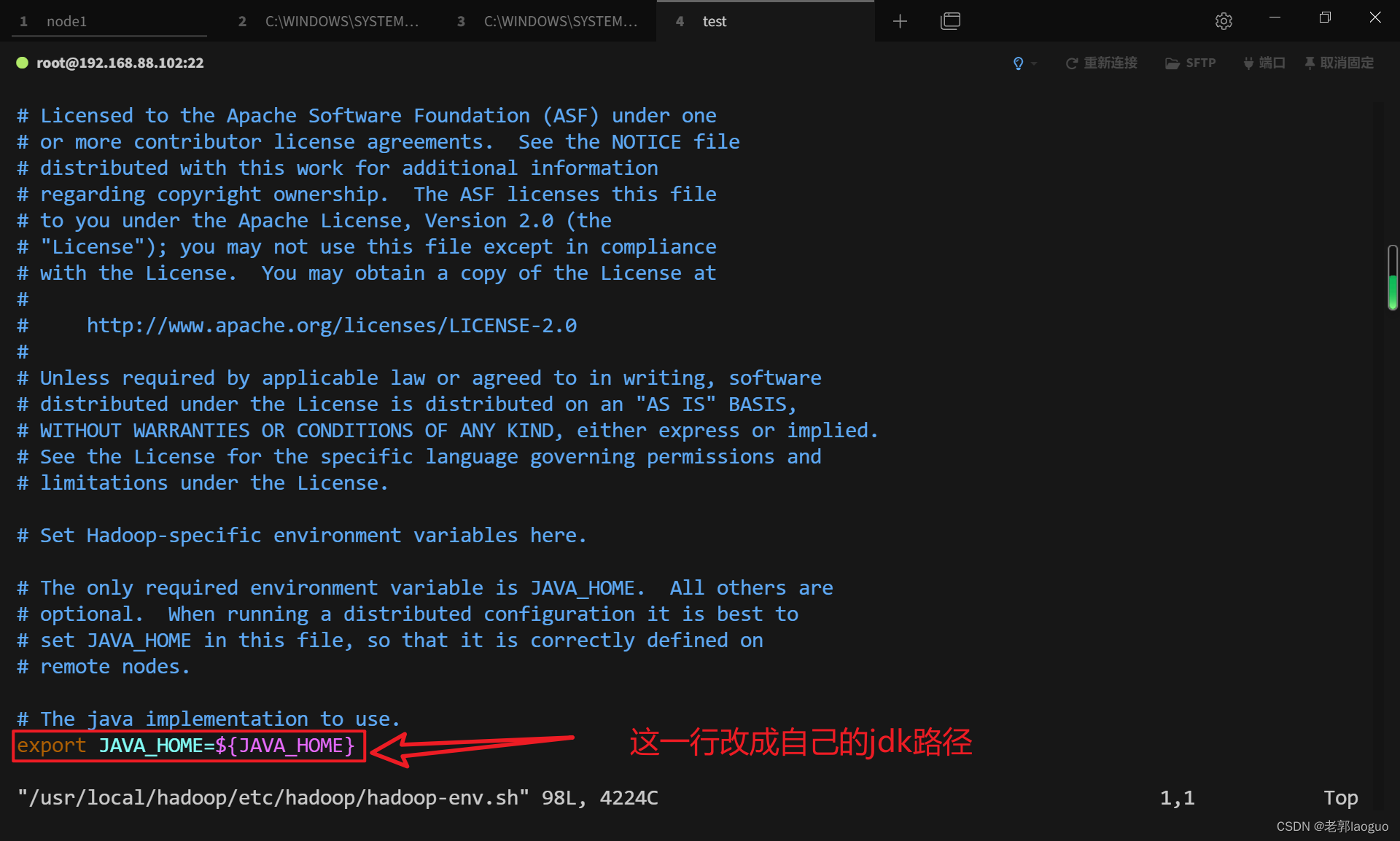
配置hadoop-env.sh:
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/export/server/jdk
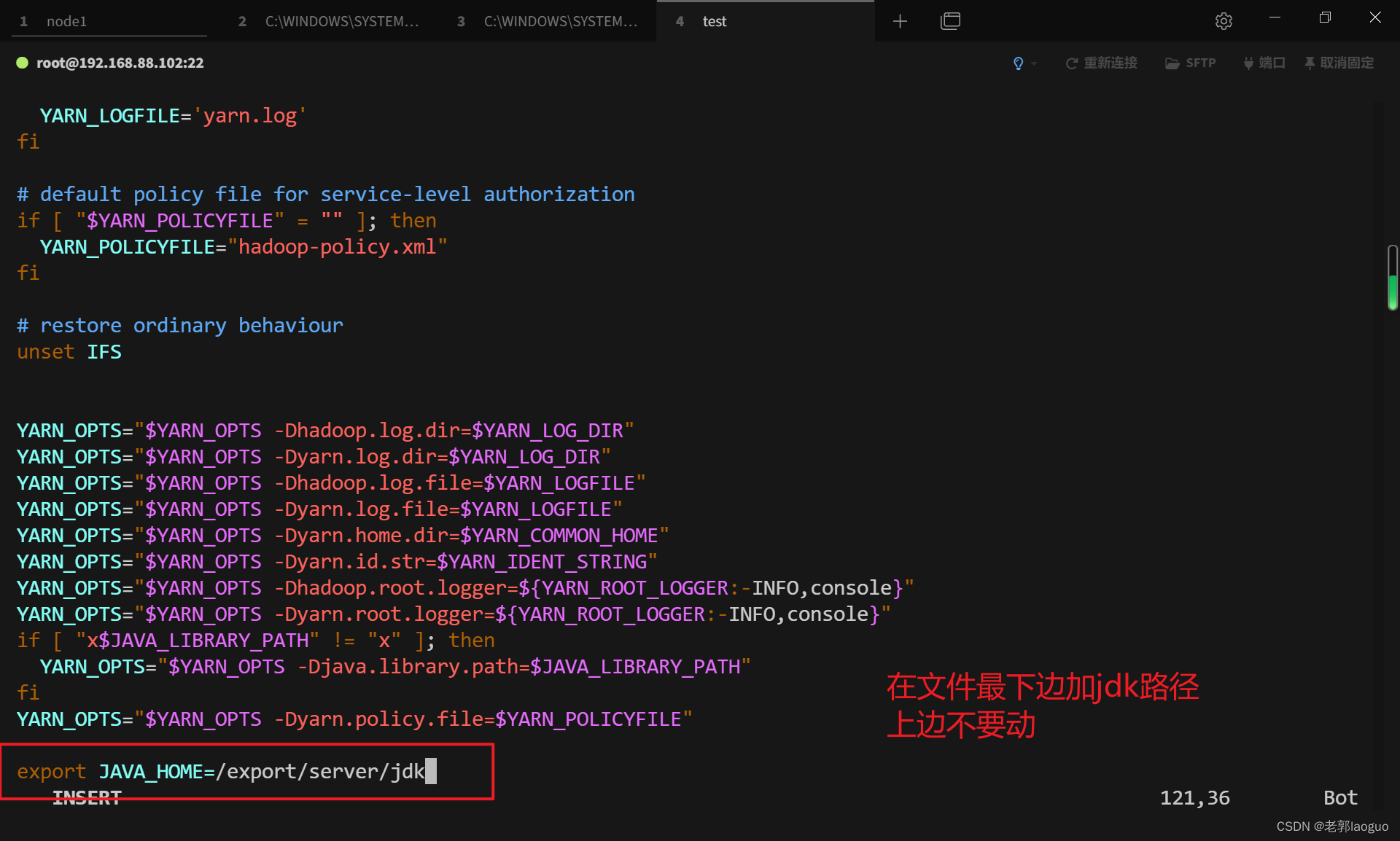
配置yarn-env.sh:
vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
export JAVA_HOME=/export/server/jdk
配置core-site.xml:
vim /usr/local/hadoop/etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.88.102:8020</value>
</property>

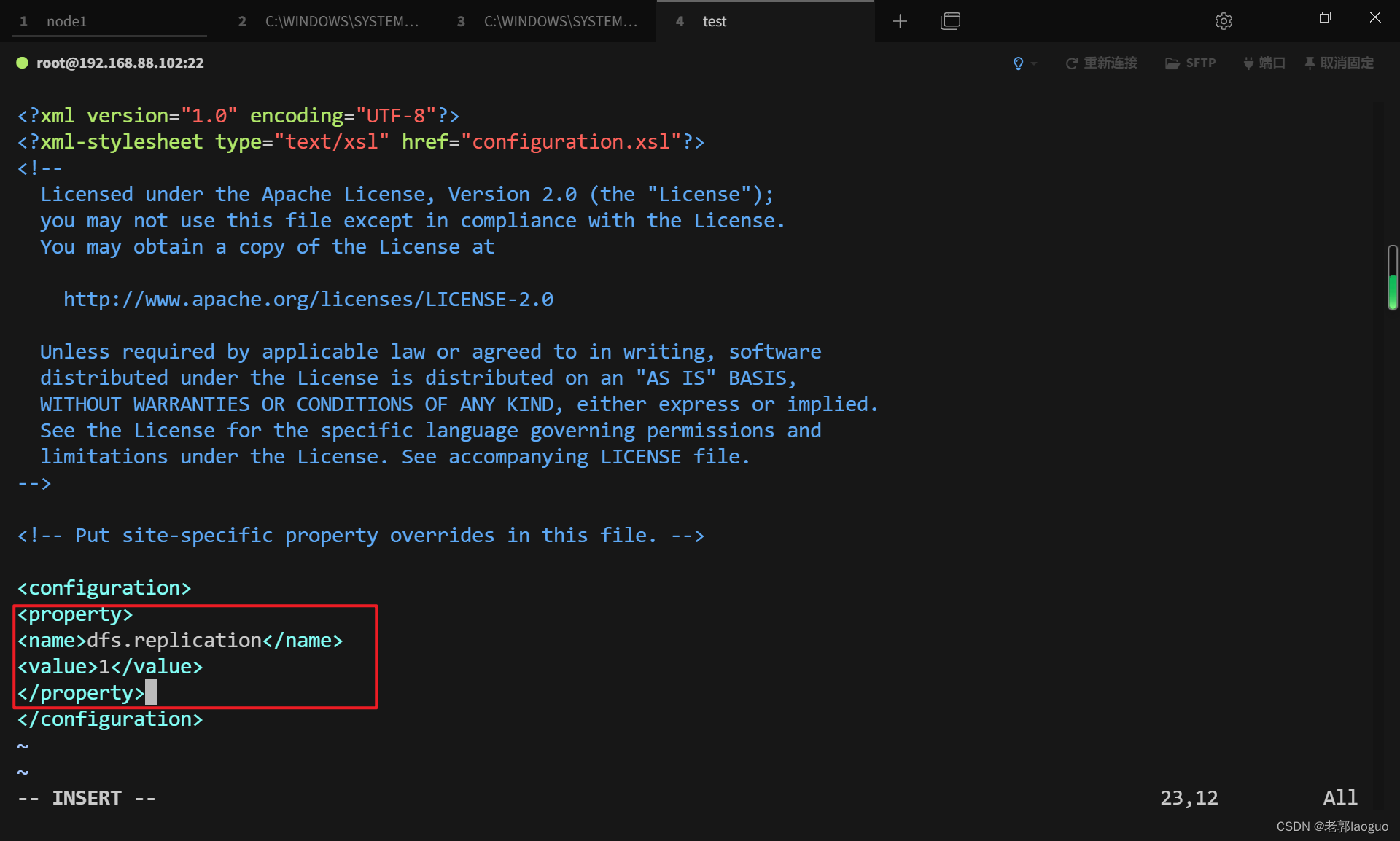
配置hdfs-site.xml:
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
因为没有mapred-site.xml只有mapred-site.xml.template所以要复制一份
命令:
cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
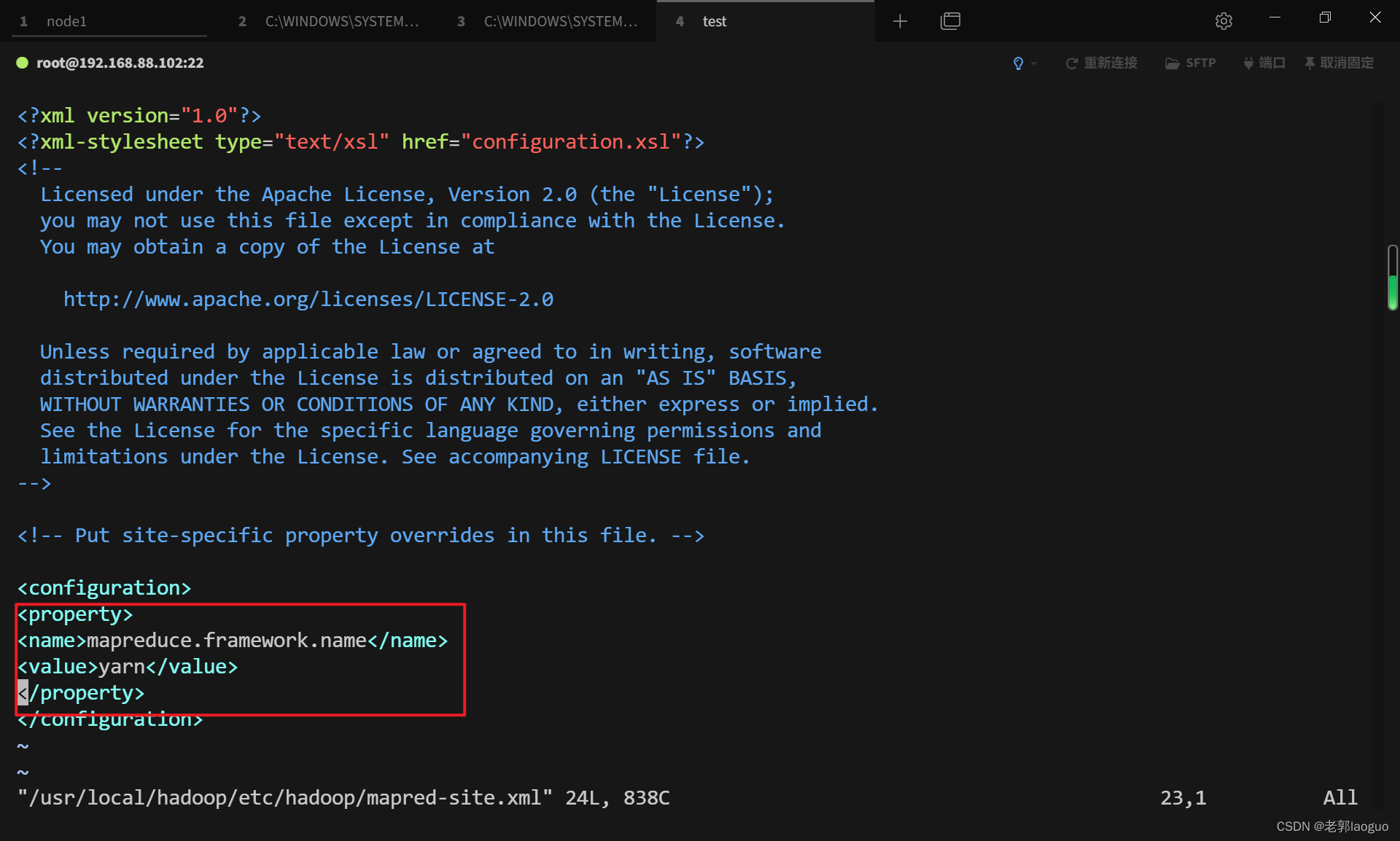
配置mapred-site.xml:
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
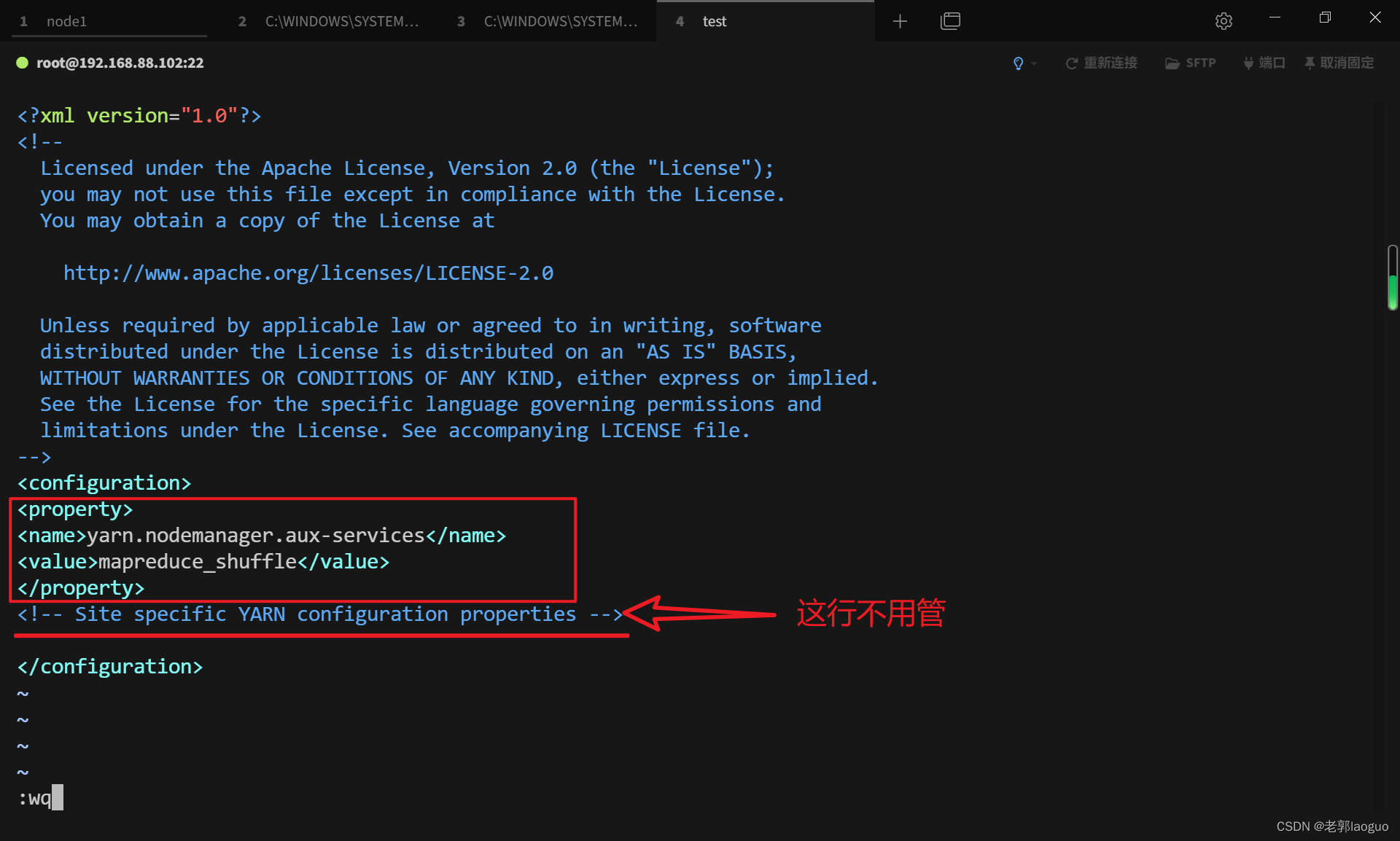
配置yarn-site.xml:
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
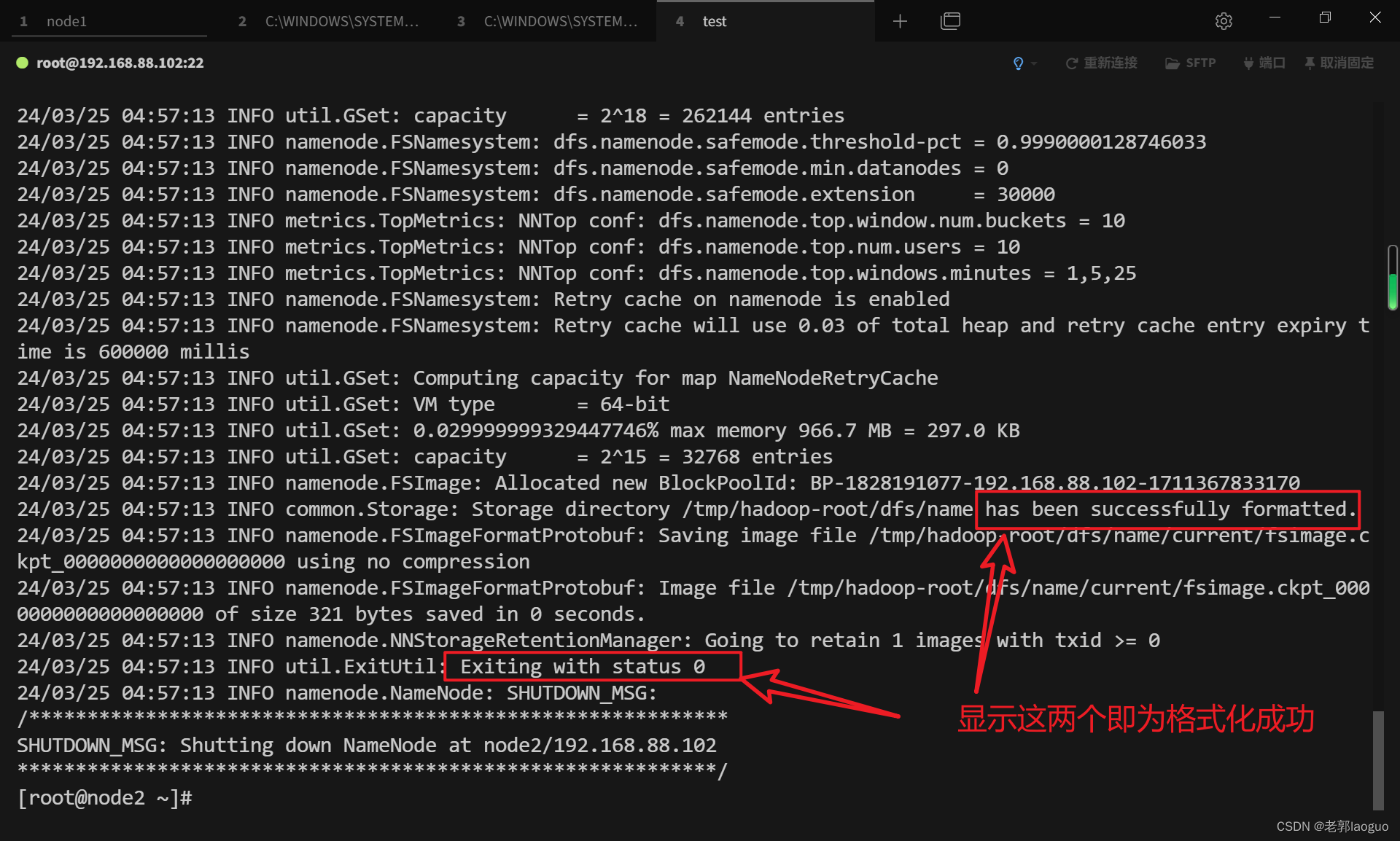
格式化hadoop:
hadoop namenode -format
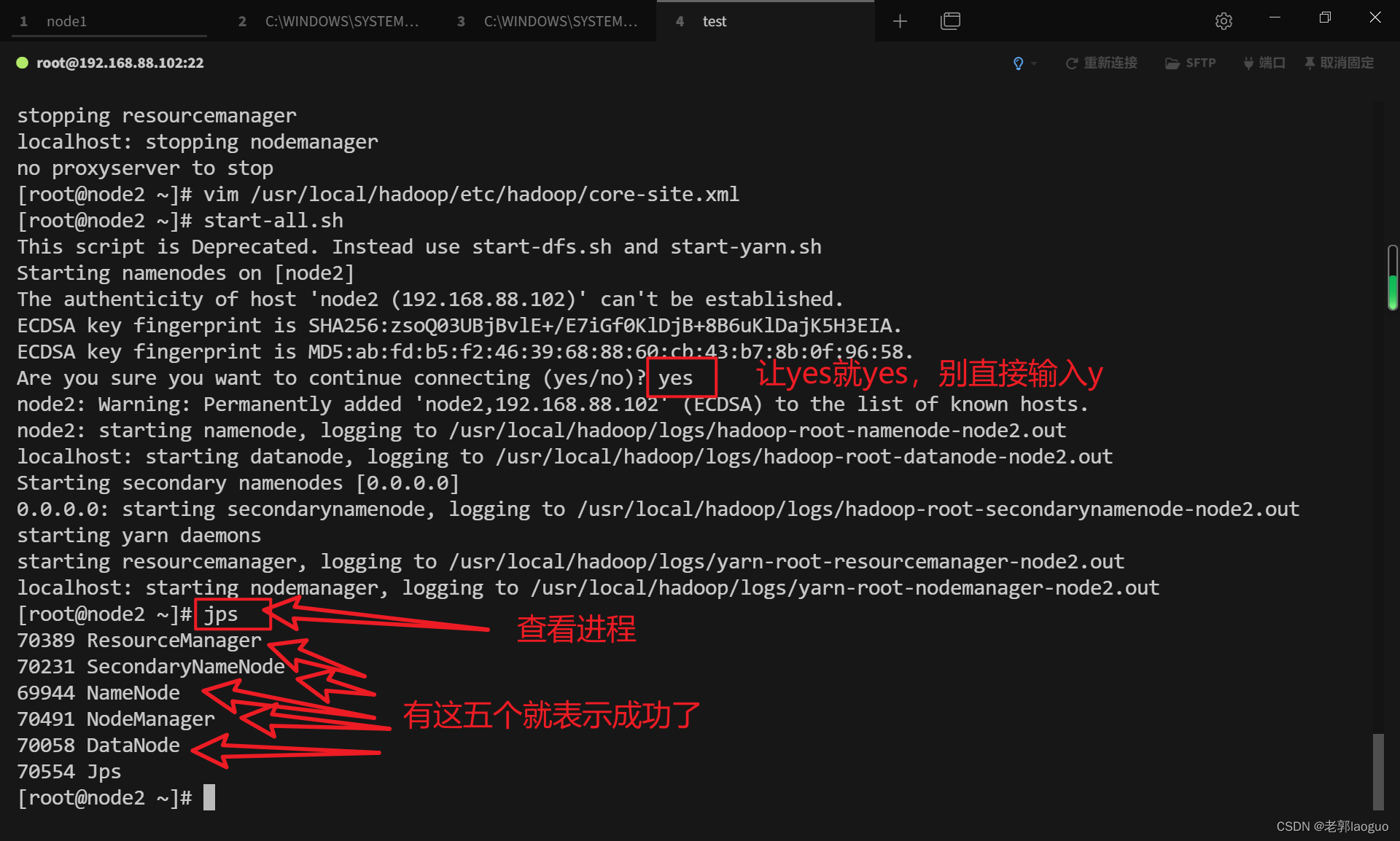
启动hadoop:
start-all.sh
查看是否成功方法1:
jps
查看是否成功方法2:浏览器内输入地址http://192.168.88.102:50070/(ip改成自己的,能ping通虚拟机的都可以访问)
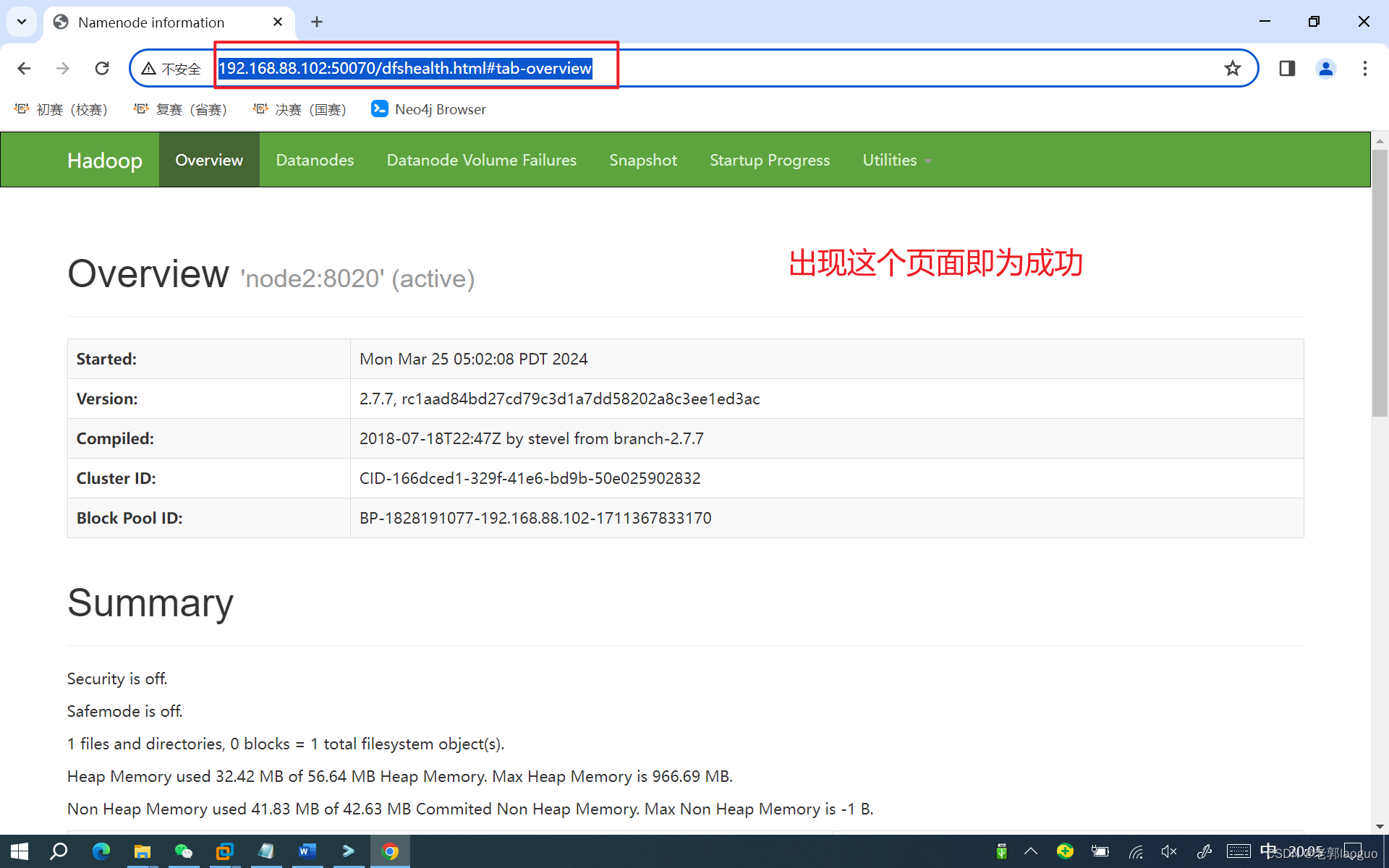
关闭hadoop命令为:
stop-all.sh
这里不做演示
配好了之后可以再拍个快照以防配错
8、配置hbase伪分布式模式
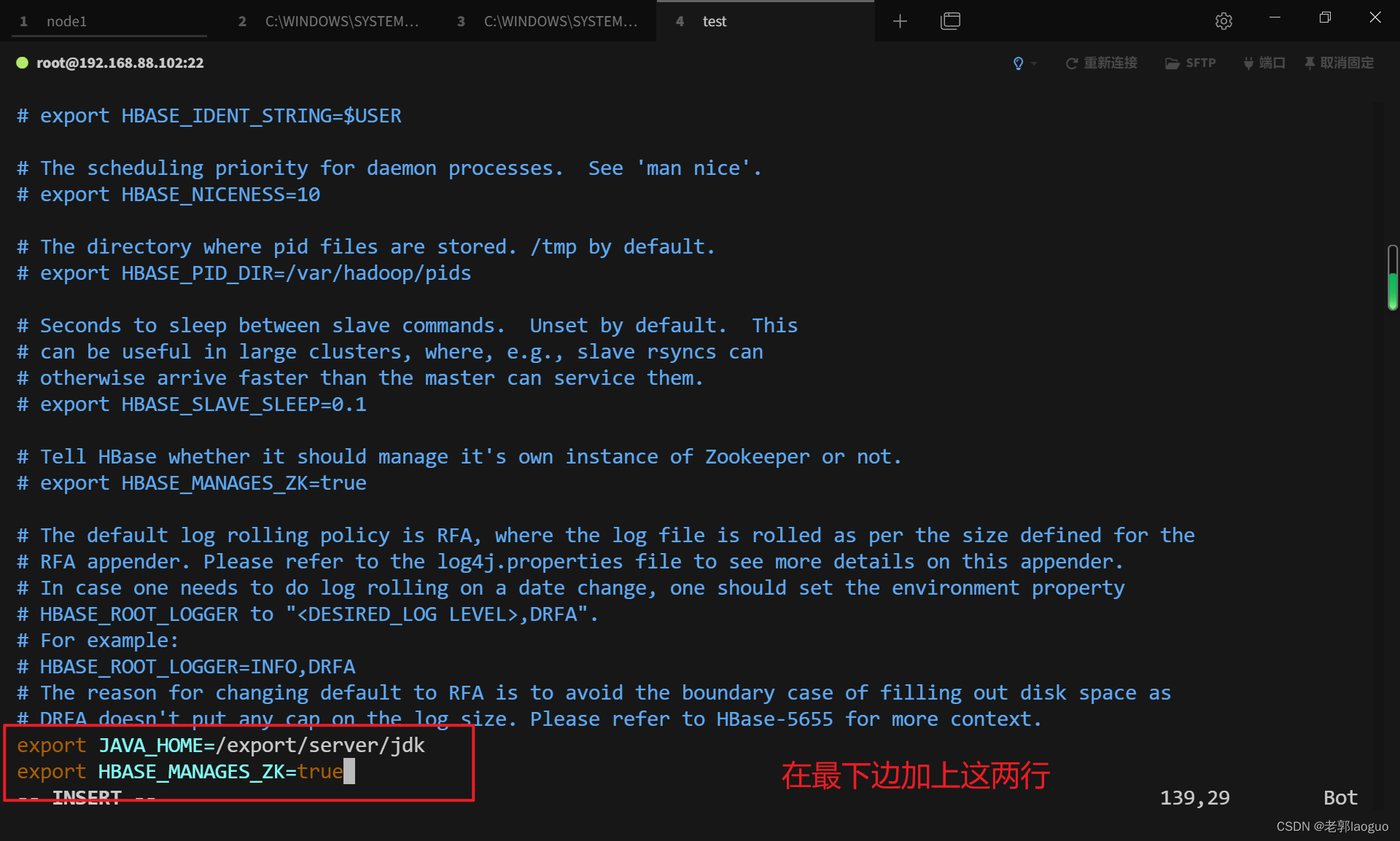
配置hbase-env.sh:
vim /usr/local/hbase/conf/hbase-env.sh
加上
export JAVA_HOME=/export/server/jdk
export HBASE_MANAGES_ZK=true
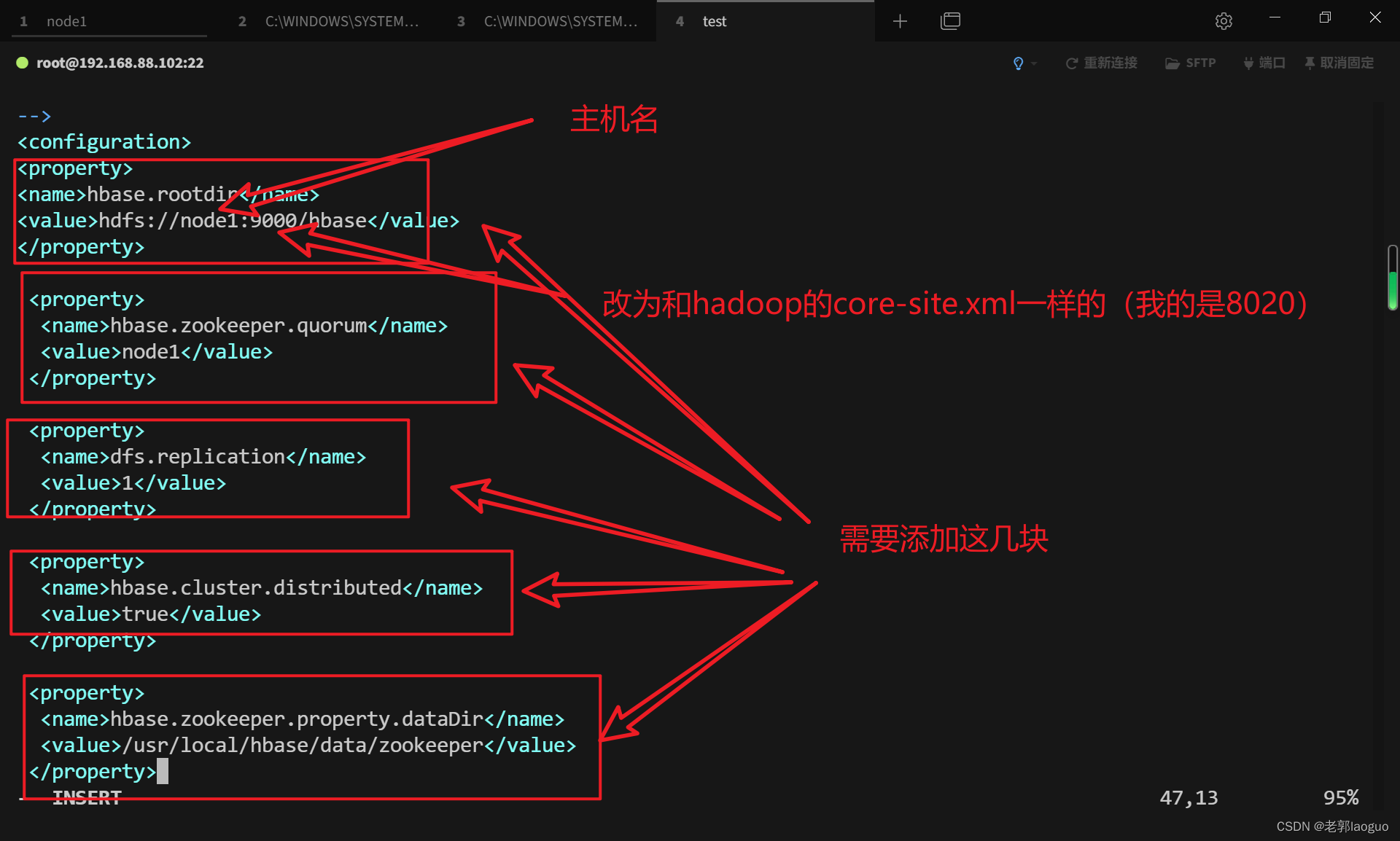
配置hbase-site.xml:
vim /usr/local/hbase/conf/hbase-site.xml
注意一定要应该修改的一定要修改
<property>
<name>hbase.rootdir</name>
<value>hdfs://node2:8020/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node2</value>
<!—改成自己的主机名,这是血的教训-->
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/hbase/data/zookeeper</value>
</property>
开启(开启前需要开启hadoop):
start-hbase.sh
查看是否成功方法1:
jps
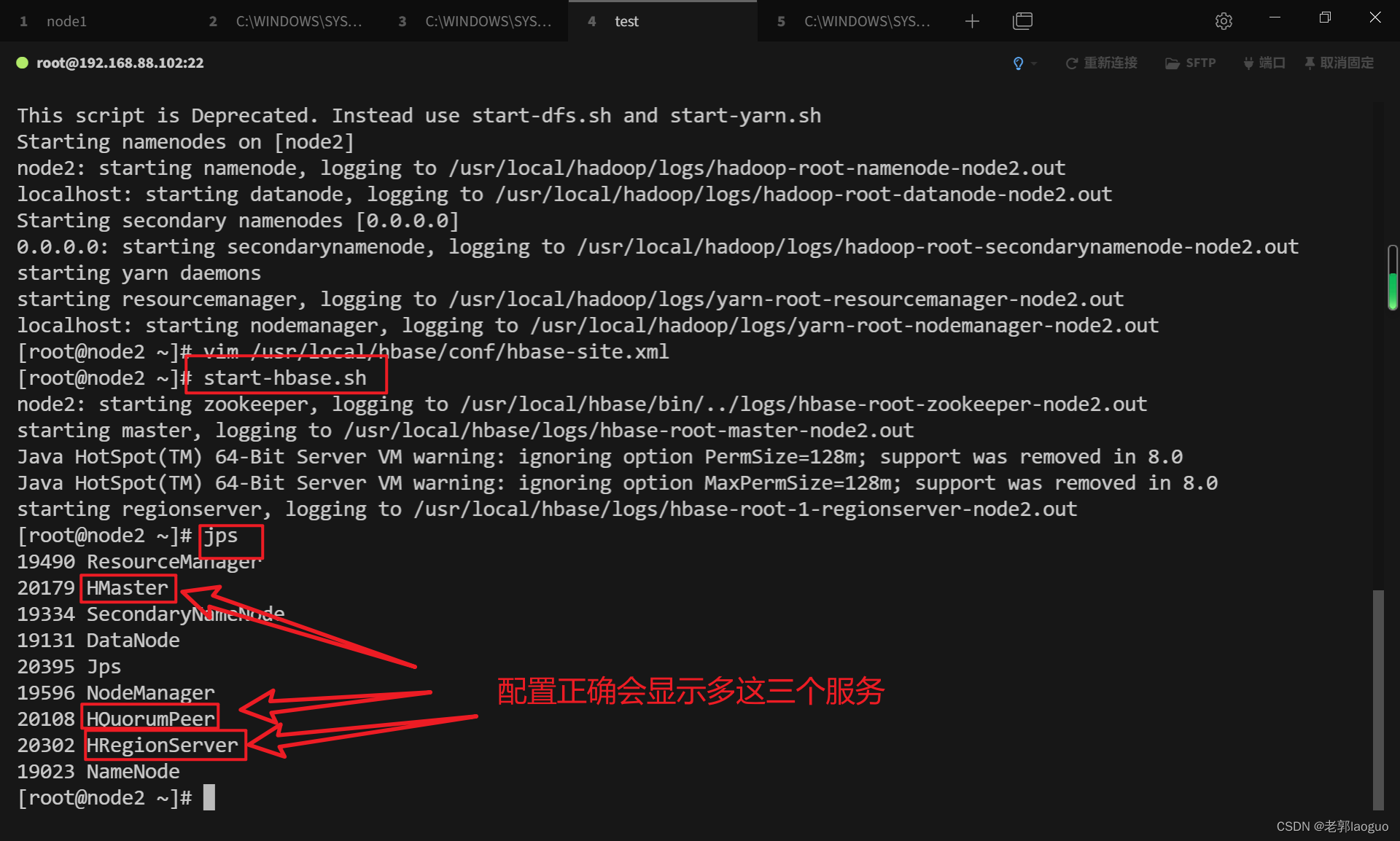
查看是否成功方法2:浏览器内输入地址http://192.168.88.102:16010/(ip改成自己的,能ping通虚拟机的都可以访问)
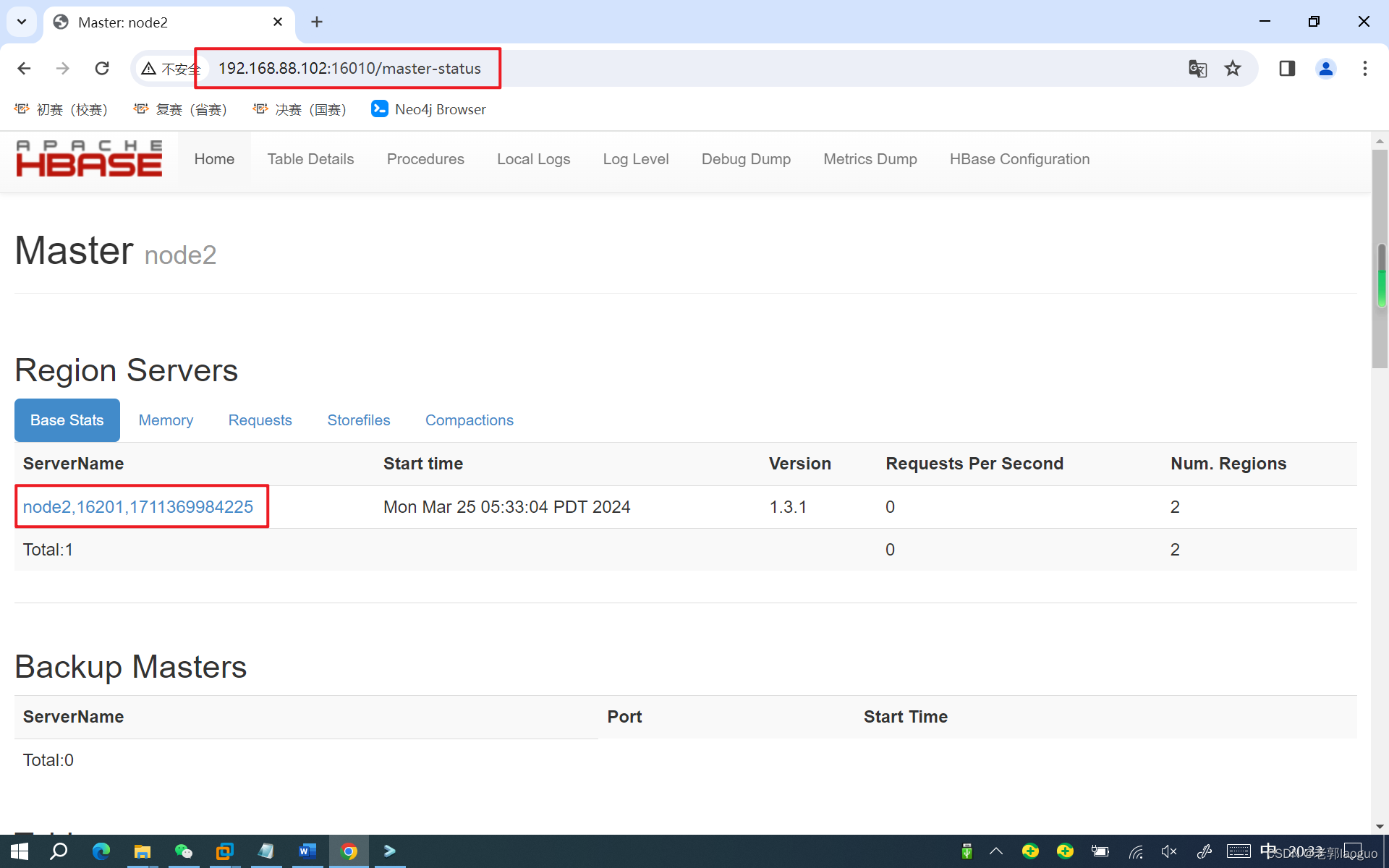
关闭时注意先关hbase再关hadoop。
配好后别忘了拍个快照备份一下
版权归原作者 老郭laoguo 所有, 如有侵权,请联系我们删除。