
主要包括:
- 核心组件的运行机制(Master,Worker,SparkContext等)
- 任务调度的原理
- Shuffile的原理
- 内存管理
- 数据倾斜处理
- Spark优化
核心组件的运行机制
Spark 执行任务的原理:
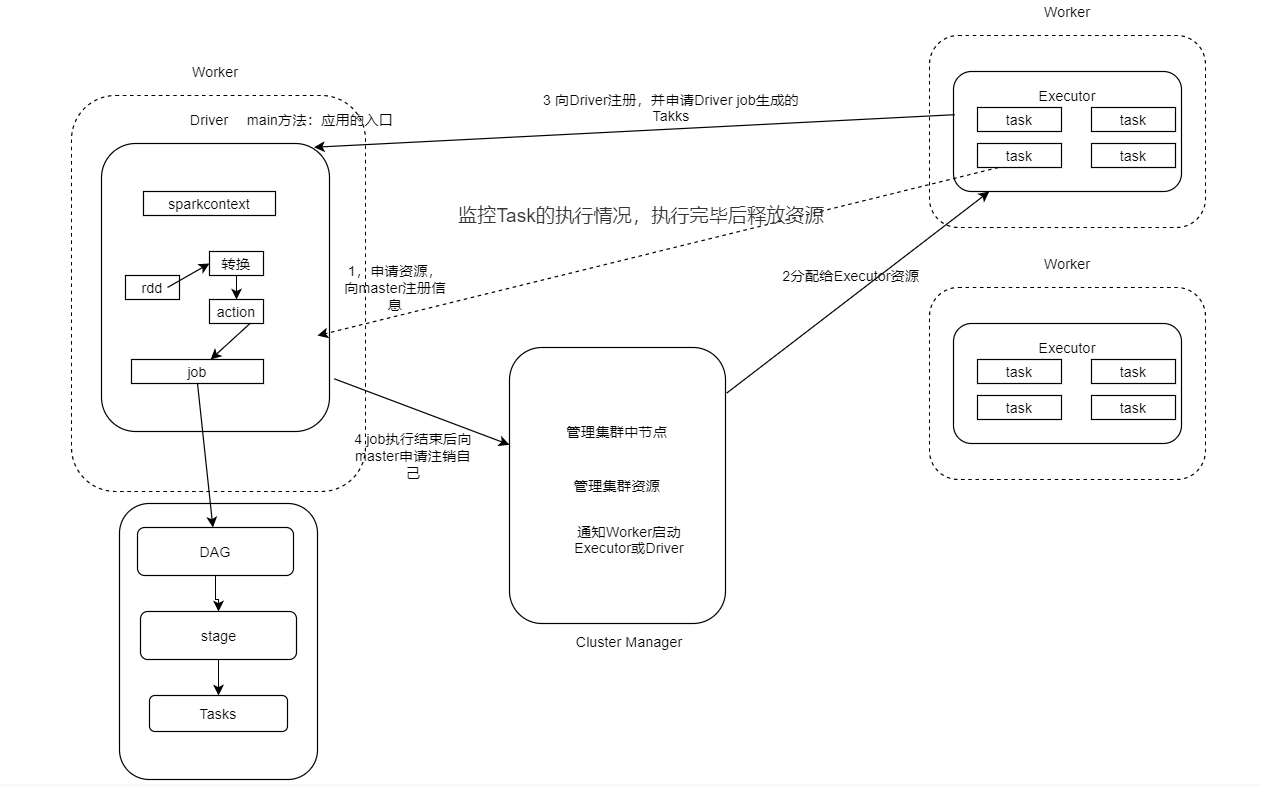
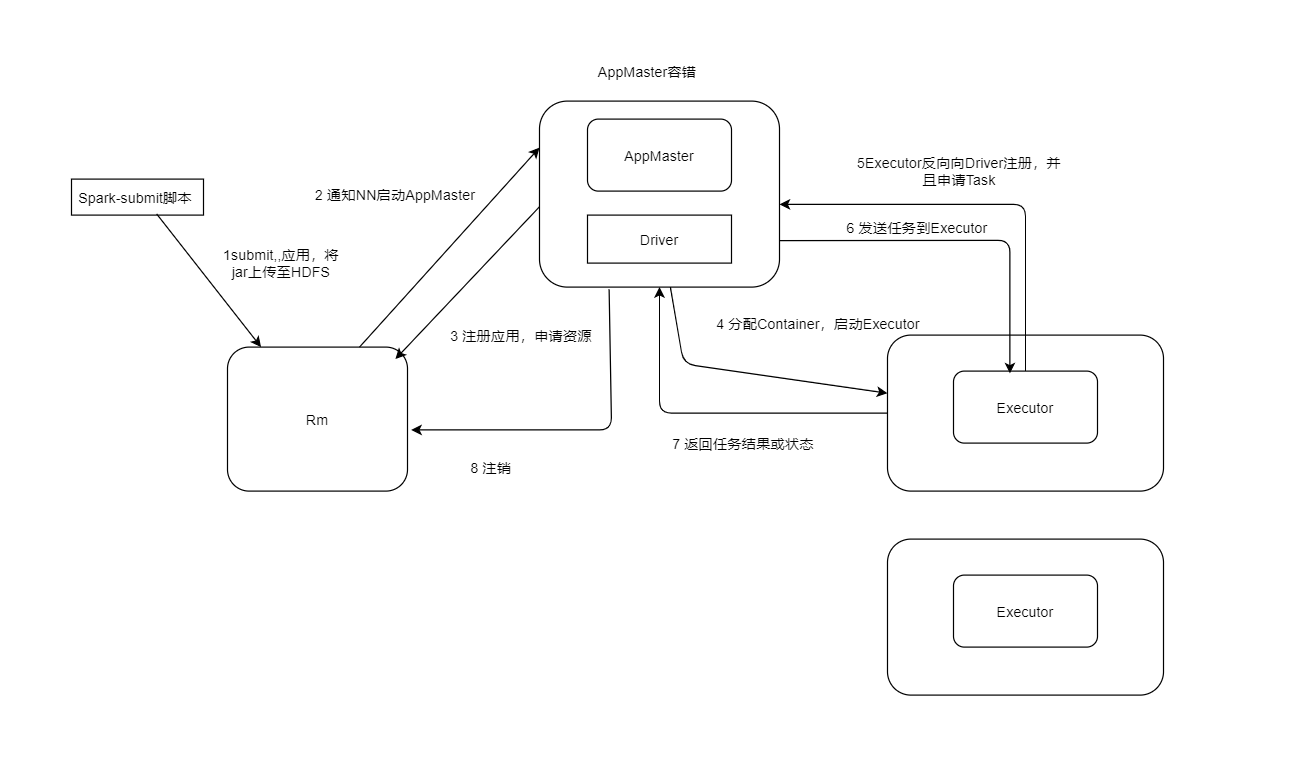
Spark on Yarn:
Cluster模型:
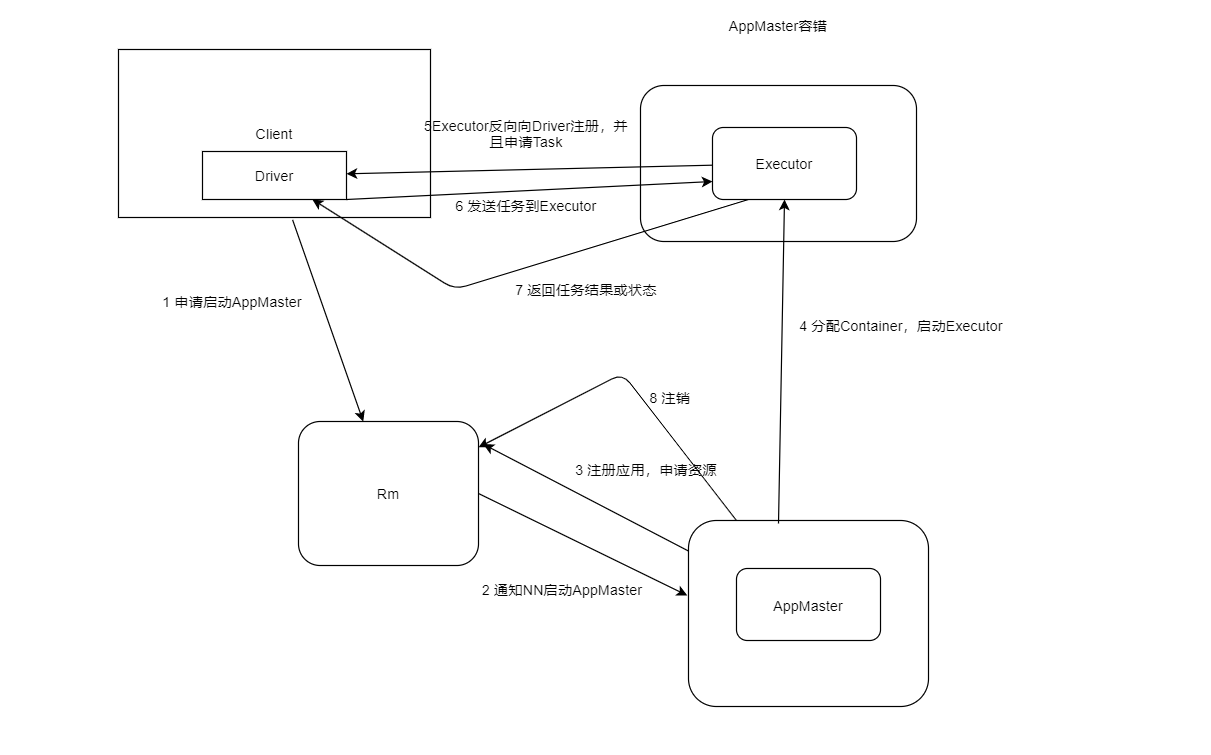
Client模型:
Master Worker通信原理
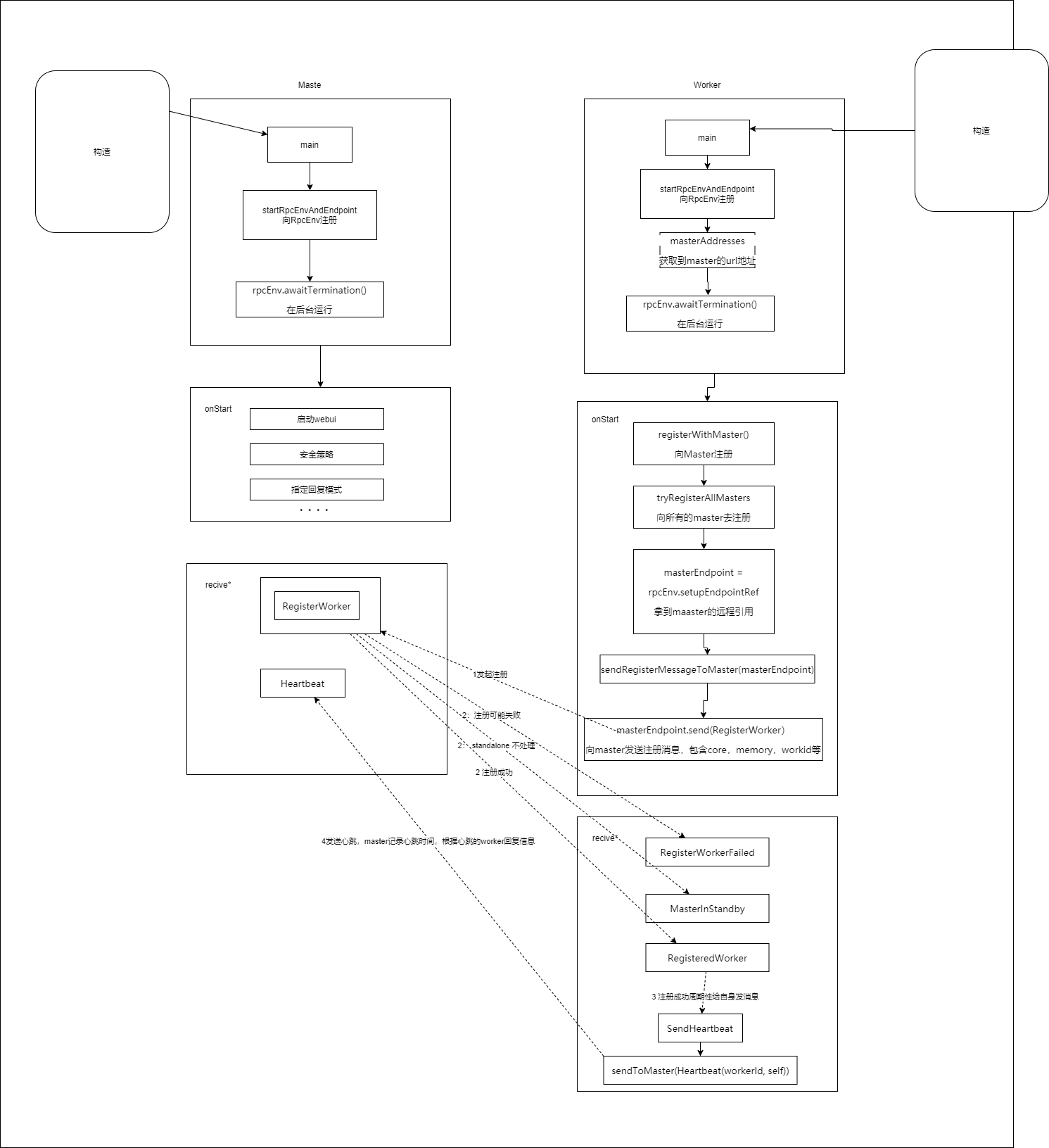
RpcEnv是RPC的环境对象,管理着整个 RpcEndpoint 的生命周期,其主要功能有:根据name或uri注册endpoints、管理各种消息的处理、停止endpoints。其中RpcEnv只能通过RpcEnvFactory创建得到。 RpcEnv中的核心方法:
// RpcEndpoint 向 RpcEnv 注册
def setupEndpoint(name: String, endpoint: RpcEndpoint): RpcEndpointRef
// 根据参数信息,从 RpcEnv 中获得一个远程的RpcEndpoint
def setupEndpointRef(address: RpcAddress, endpointName: String): RpcEndpointRef
RpcEndpoint****:是一个特质,表示一个消息通信体,可以接收、发送、处理消息
生命周期为:construct(构建)->onStart(运行)->receive*(接收消息)->onStop(停止)
Spark的Master和Worker都实现了RpcEn****dpoint这个特征
RpcEndPointRef:RpcEndPointRef是对远程RpcEndpoint的一个引用,当需要向一个具体的RpcEndpoint发送消息时,需要获取到该RpcEndpoint的引用,然后通过该引用发送消息。
备注*:在Spark源码中,看到private[spark],意思是在spark的包是私有的,除了在spark之外包不能使用
SparkEnv
SparkEnv是Spark计算层的基石,不管是Driver还是Executor,都需要依赖SparkEnv来进行计算,它是Spark的运行环境对象。
看下SparkEnv源码中的构造方法:
class SparkEnv (
val executorId: String,---------------------->Executor 的id
private[spark] val rpcEnv: RpcEnv, ---------------------->通信组件,使SparkEnv具备通信能力
val serializer: Serializer,
val closureSerializer: Serializer,
val serializerManager: SerializerManager,---------------------->序列化管理器
val mapOutputTracker: MapOutputTracker,---------------------->map阶段输出追踪器
val shuffleManager: ShuffleManager,---------------------->Shuffle管理器
val broadcastManager: BroadcastManager,---------------------->广播管理器
val blockManager: BlockManager,---------------------->块管理器
val securityManager: SecurityManager,---------------------->安全管理器
val metricsSystem: MetricsSystem,---------------------->度量系统
val memoryManager: MemoryManager,---------------------->内存管理器
val outputCommitCoordinator: OutputCommitCoordinator,---------------------->输出提交协调器
val conf: SparkConf
从SparkEnv的成员变量可以验证,SparkEnv包含了Spark运行的很多重要组件
SparkEnv的单例对象:
SparkEnv单例对象在JVM是单例的,集群情况下Driver和Executor独自的jvm进程,它们都有各自的SparkEnv单例对象
SparkContext
SparkContext使Spark功能的主要入口点,主要代标与spark的连接,能够用来在集群上创建RDD、累加器、广播变量。每个JVM里之恶能存在一个处于激活状态的SparkContext,在创建新的SparkContext之前必须调用stop()来关闭之前的SparkContext。
源码里SparkContext的一些成员变量
//spark的配置,本质上是一个并行map集合
private var _conf: SparkConf = _
private var _eventLogDir: Option[URI] = None
private var _eventLogCodec: Option[String] = None
private var _listenerBus: LiveListenerBus = _
//构建整个环境,从上面分析的SparkEnv源码可知,SparkContext具备通信,广播,度量等能力
private var _env: SparkEnv = _
//状态追踪
private var _statusTracker: SparkStatusTracker = _
//进度条
private var _progressBar: Option[ConsoleProgressBar] = None
private var _ui: Option[SparkUI] = None
private var _hadoopConfiguration: Configuration = _
private var _executorMemory: Int = _
private var _schedulerBackend: SchedulerBackend = _
private var _taskScheduler: TaskScheduler = _
//通信
private var _heartbeatReceiver: RpcEndpointRef = _
@volatile private var _dagScheduler: DAGScheduler = _
//应用id
private var _applicationId: String = _
private var _applicationAttemptId: Option[String] = None
private var _eventLogger: Option[EventLoggingListener] = None
//动态资源分配
private var _executorAllocationManager: Option[ExecutorAllocationManager] = None
//资源的清理
private var _cleaner: Option[ContextCleaner] = None
private var _listenerBusStarted: Boolean = false
private var _jars: Seq[String] = _
private var _files: Seq[String] = _
private var _shutdownHookRef: AnyRef = _
private var _statusStore: AppStatusStore = _
SparkContext初始化
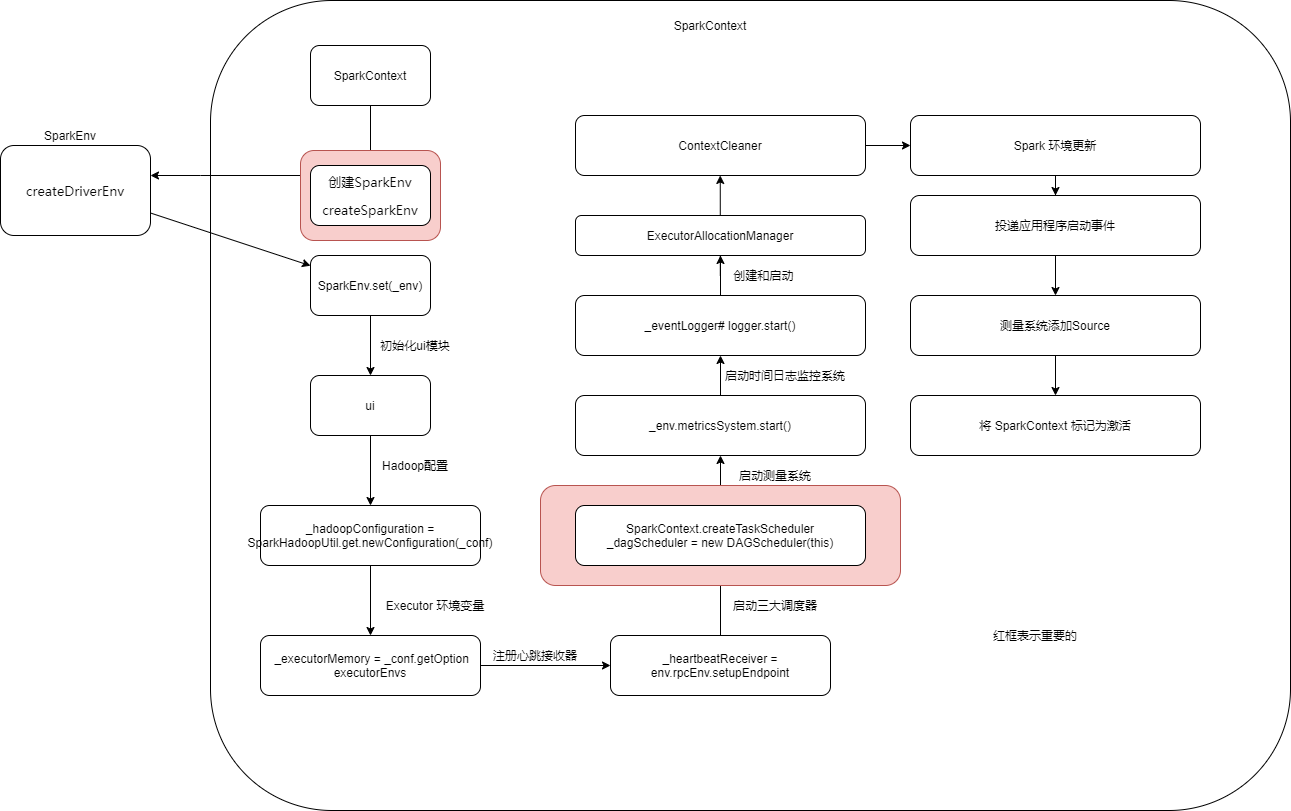
调度的三大组件启动流程
DAGScheduler(高层调度器,class):负责将DAG拆分成不同Stage(TaskSet),然后提交给TaskScheduler进行具体处理
TaskScheduler(底层调度器,trait,只有一种实现TaskSchedulerImpl):负责实际每个具体Task的物理调度执行
SchedulerBackend(trait):有多种实现,分别对应不同的资源管理器
- Standalone模式下,其实现为:StandaloneSchedulerBackend- 对应Yarn- 。。。。
启动流程:
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
------>SparkContext.createTaskScheduler#
-----------> case SPARK_REGEX(sparkUrl) =>
-----------> val scheduler = new TaskSchedulerImpl(sc)//创建scheduler
-----------> val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
----------->scheduler.initialize(backend)
----------------->TaskSchedulerImpl#initialize //初始化
-----------------------> this.backend = backend//赋值SchedulerBackend
-----------------------> schedulableBuilder={match}//选择调度策略
----------->(backend, scheduler)
------>_schedulerBackend = sched//给_schedulerBackend赋值
------>_taskScheduler = ts//给_taskScheduler赋值
------>_dagScheduler = new DAGScheduler(this)//_dagScheduler
------>_taskScheduler.start()//启动_taskScheduler
----------->TaskSchedulerImpl#start()
----------------->backend.start()//启动backend
----------------------->StandaloneSchedulerBackend#start//启动
---------------------------->super.start()
----------------------------------->CoarseGrainedSchedulerBackend#start
--------------------------------------->driverEndpoint = createDriverEndpointRef(properties)//创建Driver的Endpoint
---------------------------------------------->DriverEndpoint#onStart//自动执行onStart
---------------------------------------------------->reviveThread.scheduleAtFixedRate//间隔1s执行
----------------------------------------------------------> Option(self).foreach(_.send(ReviveOffers))//自己给自己发消息
---------------------------------------------->case ReviveOffers =>makeOffers()//接收搭配ReviveOffers这个消息触发
---------------------------------------------->makeOffers()//调度的是底层的资源 只有资源没有任务 offer-》Taskschedule(负责将底层的资源和任务结合起来)
-------------------------------------------------->scheduler.resourceOffers(workOffers)//将集群的资源以Offer的方式发给上层的TaskSchedulerImpl。
-----------------> client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)//创建 StandaloneAppClient
----------------->client.start()
----------------->ClientEndpoint#oNstart=>registerWithMaster(1)//应用程序向 Master 注册
根据以上的方法执行栈可以得出:SparkContext初始化的过程中完成了TaskScheduler,SchedulerBackend,DAGScheduler三个组件的初始化,在初始化的过程中会向master发送注册消息,Driver会周期性的给自己发送消息,调度底层的资源,将集群中的资源以offer的形式发给TaskSchedulerImpl,TaskSchedulerImpl拿到DAGScheduler分配的TaskSet,给task分配资源
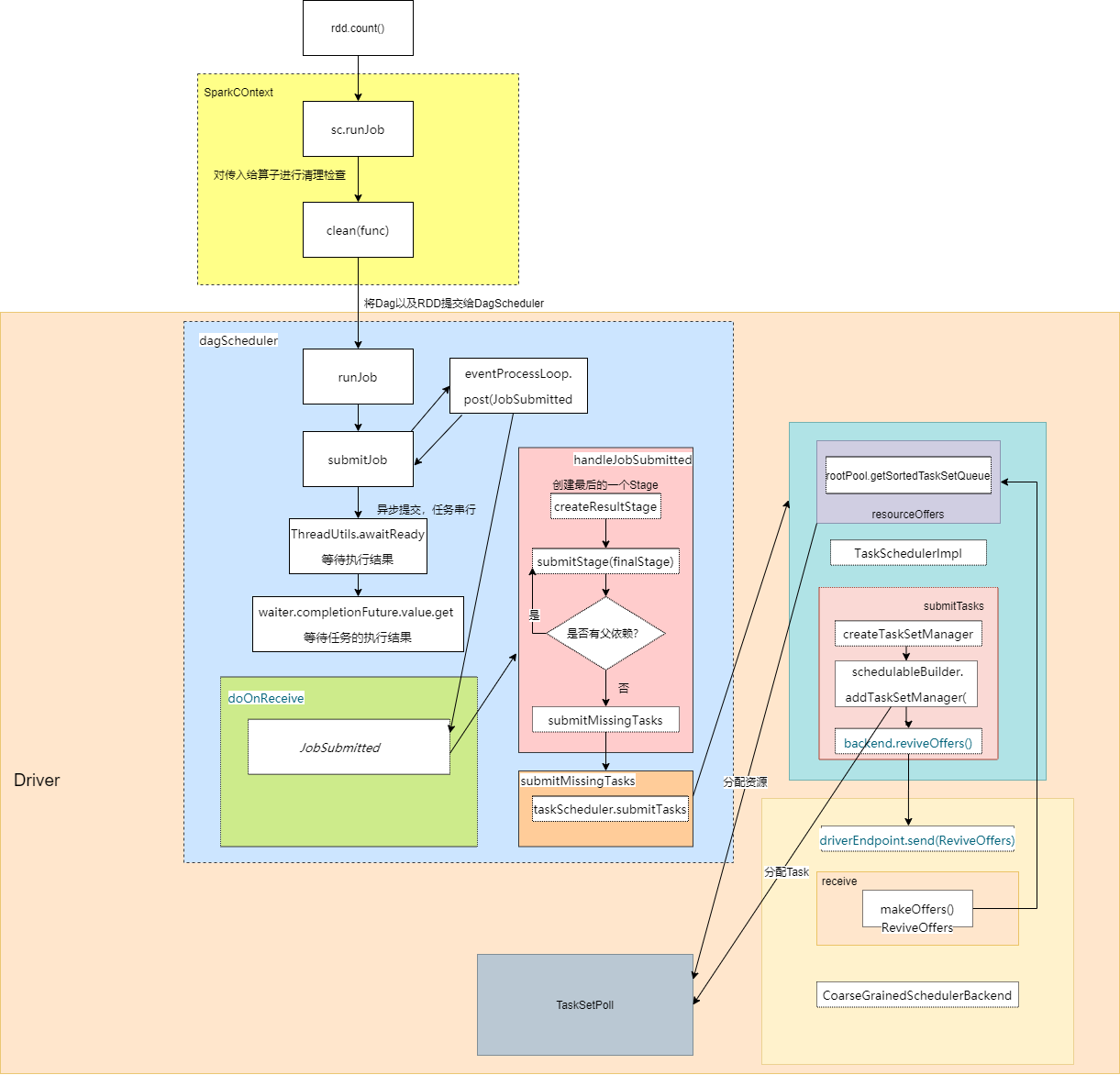
作业执行流程(追源码绘制):
版权归原作者 橙子qyfftf 所有, 如有侵权,请联系我们删除。