
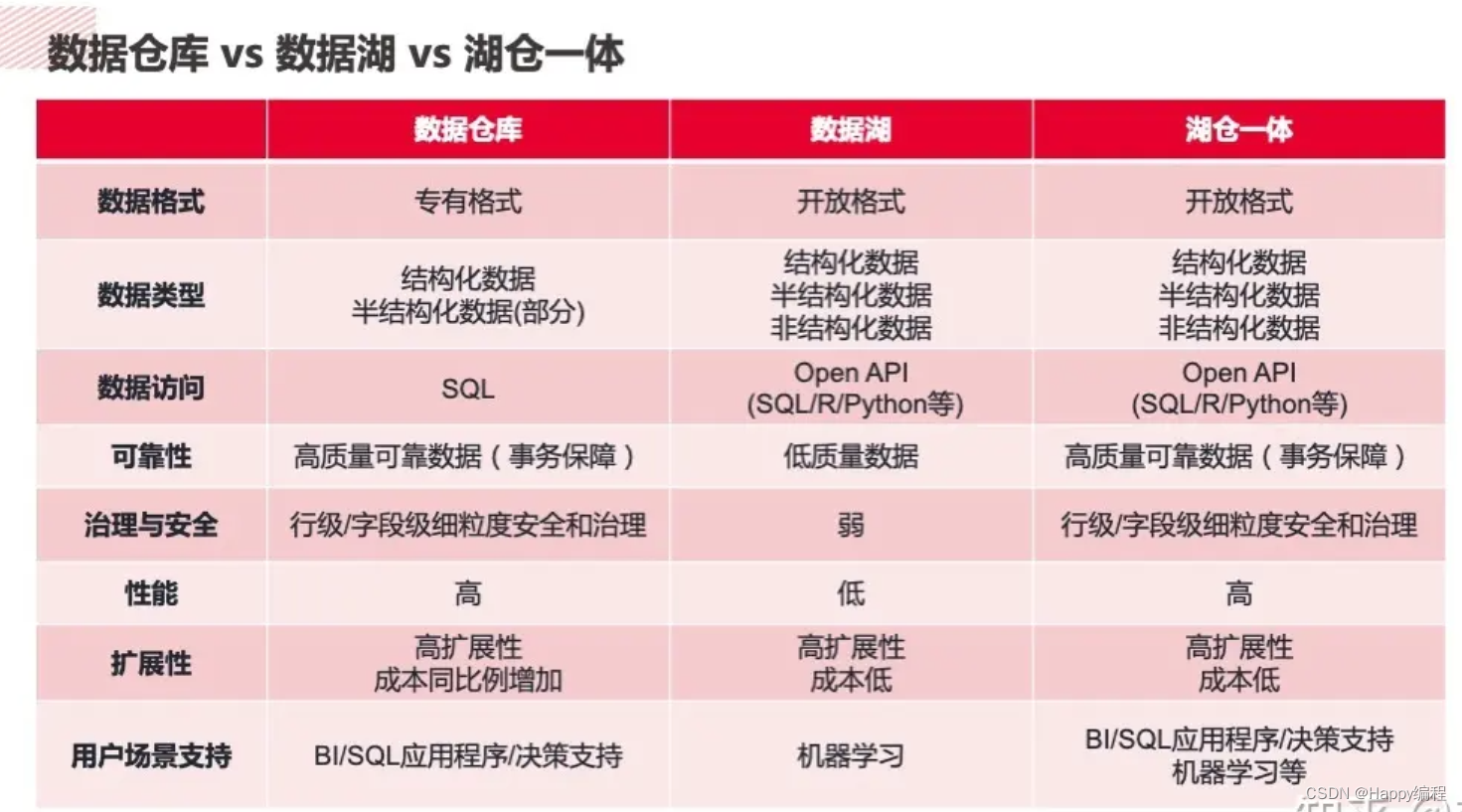
数据库早已解决了数据问题,但无法满足现代使用场景和作业的需求。数据湖的出现是为了规避数据库的局限性,Spark 是构建数据湖的最佳工具之一。但是,数据湖缺少数据库提供的一些关键功能(如 ACID 保证)。湖仓一体是下一代数据存储解决方案,旨在提供数据库与数据湖两者的优点,并满足各种使用场景和作业的需求。
一、什么是湖仓一体
湖仓一体(lakehouse)是针对 OLAP 场景且兼具数据湖和数据库优点的新范式。新的系统设计让湖仓一体成为可能,从而直接以低成本提供类似数据库的数据管理特性,同时具有数据湖的可伸缩存储的特性。
二、湖仓一体架构的特点
**支持事务**
类似数据库,湖仓一体能在并发执行作业的场景中提供 ACID 保证。
**表结构强化与治理**
湖仓一体系统禁止表结构不对的数据插入表内,必要时也可以显式调整表结构来适应不断变化的数据。这种系统可以推理数据完整性,需要有可靠的治理和审计机制。
**支持开放格式的各种数据类型**
湖仓一体可以存储、优化、分析和访问所有类型的数据,无论数据是结构化的、半结构化的,还是非结构化的,这一点和数据库不同,但和数据湖差不多。为了使各种工具可以直接且高效地访问数据,必须提供具备标准化读写接口的开放格式来存储数据。
湖仓一体(lakehouse)是针对 OLAP 场景且兼具数据湖和数据库优点的新范式。新的系统设计让湖仓一体成为可能,从而直接以低成本提供类似数据库的数据管理特性,同时具有数据湖的可伸缩存储的特性。
具体来说,湖仓一体架构具有下列特性。
**支持事务**
类似数据库,湖仓一体能在并发执行作业的场景中提供 ACID 保证。
**表结构强化与治理**
湖仓一体系统禁止表结构不对的数据插入表内,必要时也可以显式调整表结构来适应不断变化的数据。这种系统可以推理数据完整性,需要有可靠的治理和审计机制。
** **支持开放格式的各种数据类型
湖仓一体可以存储、优化、分析和访问所有类型的数据,无论数据是结构化的、半结构化的,还是非结构化的,这一点和数据库不同,但和数据湖差不多。为了使各种工具可以直接且高效地访问数据,必须提供具备标准化读写接口的开放格式来存储数据。
**支持各种作业类型 **
湖仓一体系统支持对其中的数据执行各种类型的作业,因为有各种使用开放接口读取数据的工具提供支持,数据不需要导来导去。从传统的 SQL 查询和流式分析到机器学习,湖仓一体系统避免了数据孤岛(也就是将不同类别的数据放在不同系统中),允许开发人员更轻松地构建各种复杂的数据解决方案。
支持插入更新和删除
变更数据捕获(change data capture,CDC)和慢变更维度(slowly changing dimension,SCD)等复杂使用场景要求表中的数据能持续更新。通过事务保证,湖仓一体系统允许数据并发删除和更新。
**数据治理 **
湖仓一体系统提供用于推理数据完整性和审计所有数据变更的工具,可以用于合规。
三、常见框架
*1、*Apache Hudi **
Apache Hudi 最初由 Uber 工程部门开发,是一种专为键值数据的增量插入更新和删除而设计的数据存储格式。它的名字是 Hadoop Update Delete and Incremental(Hadoop 更新删除与增量)的缩写。数据以列存格式(如 Parquet 文件)和行存格式(如记录对 Parquet 文件增量修改的 Avro 文件)的组合进行存储。
除了前面提到的那些特性,Hudi 还支持以下操作。
插入更新,以及快速可插拔的索引。
原子性的数据发布,并且支持回滚。
读取表的增量修改部分。
数据恢复的保存点。
用统计信息提供文件大小和布局管理。
异步整合行数据和列数据。
2、Apache Iceberg
Apache Iceberg 最初由 Netflix 构建,是海量数据集的另一个开放存储格式。但与专注更新键值数据的 Hudi 有所不同,Iceberg 更关注单表扩展到 PB 级的通用数据存储,并且具有更新表结构的特性。
具体来说,除了共有的那些特性,它还具有下列特性。
通过对表结构中列、字段以及嵌套结构的添加、删除、更新、改名、重排来修改表结构。
隐藏分区机制,在内部为表中的行创建分区值。
修改分区结构,随着数据量或查询模式改变,自动执行元数据操作以更新表的布局。
时间旅行,允许用户通过 ID 或时间戳查询表的某个快照的数据。
通过回滚到以前的版本来修正错误。
确保多个并发写之间的可串行化级别的隔离。
*3、*Delta Lake **
Delta Lake 是 Linux 基金会托管的开源项目,由 Apache Spark 的初创者构建。和其他几个项目类似,它也是一种提供了事务保证并支持表结构强化和更新的开放型数据存储格式。
它还提供了其他一些有意思的特性。
使用结构化流处理输入源和输出池在流计算中读写表。
即便在 Java、Scala、Python 的 API 中,也可以进行更新、删除、合并(插入更新的数据)等操作。
既可以显式修改表结构,也可以在写 DataFrame 时通过合并 DataFrame 的表结构与表原有的结构来隐式修改表结构。(实际上,Delta Lake 的合并操作支持以高级语法实现条件更新 / 插入 / 删除,同时更新所有列,本章稍后会有所涉及。)
时间旅行,允许用户根据 ID 或时间戳查询表的某个特定快照的数据。
通过回滚到以前的版本来修正错误。
执行任意 SQL、批处理、流处理操作时,确保多个并发写之间的可串行化级别的隔离。
声明:本文整理于《spark快速大数据分析》,微信读书可以阅读
版权归原作者 Happy编程 所有, 如有侵权,请联系我们删除。