
简介
-》xpath 是XML Path的简称,由于HTML文档本身就是一个标准的XML页面,所以我们可以使用Xpath 的用法来定位页面元素。
-》xpath 这种定位方式,webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素,这是个非常费时的操作,如果脚本中大量使用xpath做元素定位的话,脚本的执行速度可能会稍慢
表达式****描述/根节点开始选取//任意节点开始选取.选取当前节点..选取当前节点的父节点@选取属性表达式***描述匹配任何元素节点@*匹配任何属性节点举例/input/选取input元素下的所有子元素//input[@type]选取input元素下所有含有type属性的元素//选取文档中所有元素//input/[@]选取input元素下所有含有属性的子元素//input/[@=‘test’]选取input元素下所有包含有属性值为test的元素
使用id定位
driver.find_element_by_xpath('//input[@id="kw"]')
此处使用了相对路径//和@属性,相对路径找到所有input节点,然后找到满足id="kw"的节点
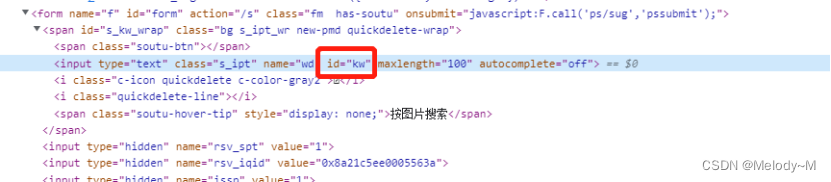
使用class定位
driver.find_element_by_xpath('//input[@class="s_ipt"]')
此处使用相对路径//和@属性,相对路径找到所有input节点,然后找到满足class="s_ipt"的节点

其他属性定位
其他元素结合xpath均可以定位(name、tag_name、link_text、partial_link_text)
相对定位
相对路径,以"//"开头,xpath从文档的任何位置开始解析
以// 开头 如://form//input[@name="wd"]

绝对定位
绝对路径,以"/"开头,让xpath从文档的根节点开始解析
比如:/html/body/div
位置索引定位
/input/book[1]选取input节点下第一个book节点/input/book[last()]选取input节点下最后一个book节点/input/book[last()-1]选取input节点下倒数第二个book节点
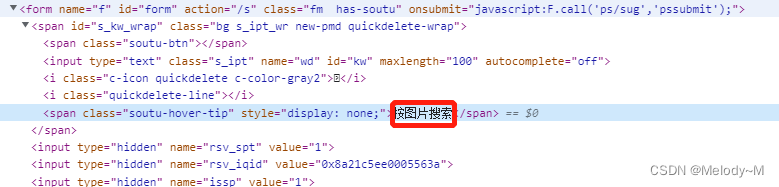
文本定位
使用text内容 如://span[text()="按图片搜索"]
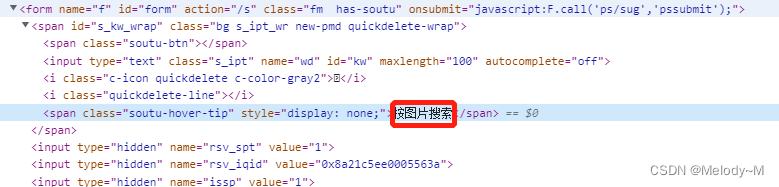
文本模糊定位
使用contains() 包含函数 如://button[contains(text(),"图片搜索")]
如://button[contains(@class,"ipt")]

属性值模糊匹配
使用starts-with 匹配以xx开头的属性值;ends-with 匹配以xx结尾的属性值
//input[starts-with(@class,"s_")]、 //input[ends-with(@class,"ipt")]

使用逻辑运算符and、or
如://input[@name="wd" and @class="s_ipt"]

版权归原作者 Melody~M 所有, 如有侵权,请联系我们删除。