
执行JS的类库:execjs,PyV8,selenium,node
pip list

pip install selenium
pip install xlrd
pip install xlwt
pip install PyExecJS

pip install xlutils

selenium测试工具可以用来模拟用户浏览器的操作,其支持的浏览器有:PhantomJS,Firefox,Chrome等等,开发者可以根据当前的系统形式选择不同的模拟浏览器。
每种模拟浏览器都需要对应的浏览器驱动(一个以.exe为后缀的可执行文件),使用谷歌浏览器Chrome,对应的浏览器驱动可以通过下面的网址下载。要完整地安装Python-Selenium库,让Chrome浏览器实现自动化,需要完成下面4步:Chromedriver安装、Selenium库安装、测试、关闭Chrome浏览器自动更新。
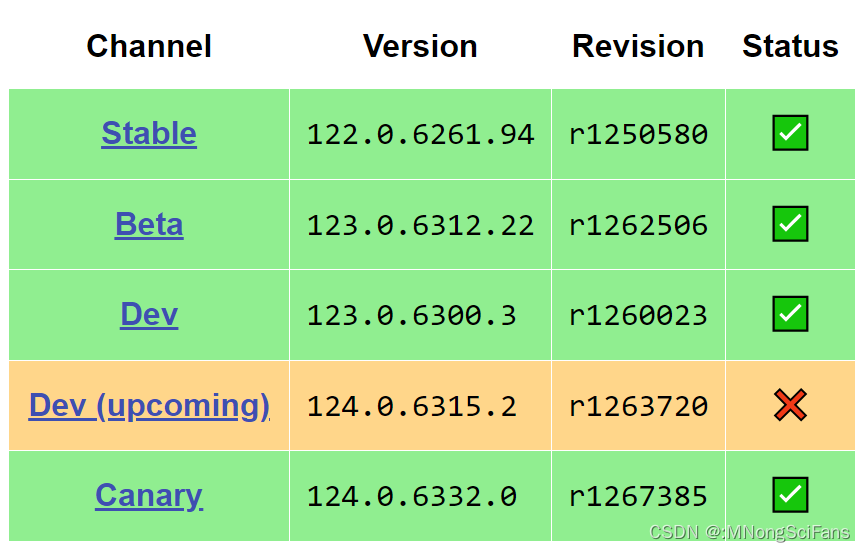
ChromeDriver - WebDriver for Chrome - Downloads
如果您使用的是Chrome 115或更新版本,请参阅Chrome测试可用性仪表板。此页面为特定的ChromeDriver版本提供下载。

# -*- coding: utf-8 -*-
"""
Created on Thu Feb 24 16:10:55 2024
@author: Administrator
"""
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import threading
from datetime import datetime
from queue import Queue
from xlrd import open_workbook
from xlutils.copy import copy
import random
import time
import re
class ShellChrome(object):
def __init__(self,count):
self.count = count
self.que = Queue(maxsize = count)
ua = self.getheaders()
#mobile_emulation = {"deviceName": "Nexus 7"}
self.options = webdriver.ChromeOptions()
# 把Chrome设置成可视化无界面模式,windows/Linux 皆可
self.options.add_argument('headless')
# 转换手机模式
#self.options.add_experimental_option("mobileEmulation", mobile_emulation)
# 全屏启动,无地址栏
self.options.add_argument('kiosk')
# 设置默认编码为 utf-8,也就是中文
self.options.add_argument('lang=zh_CN.UTF-8')
# 禁用图片加载 提升速度
self.options.add_argument('blink-settings=imagesEnabled=false')
# 隐身模式
self.options.add_argument('incognito')
# 自动打开开发者工具
self.options.add_argument("auto-open-devtools-for-tabs")
# 启动时,不激活(前置)窗口
#self.options.add_argument('no-startup-window')
# 设置窗口启动位置(左上角坐标)
self.options.add_argument('window-position=100,100')
# 禁用gpu渲染 规避bug
self.options.add_argument('disable-gpu')
# 以最高权限运行
self.options.add_argument('--no-sandbox')
# 禁用JavaScript
self.options.add_argument("--disable-javascript")
# 设置开发者模式启动,该模式下webdriver属性为正常值
self.options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 禁用浏览器弹窗
prefs = {
'profile.default_content_setting_values' : {
'notifications' : 2
}
}
self.options.add_experimental_option('prefs',prefs)
# 添加ua
self.options.add_argument('user-agent=' + ua)
self.service = Service('C:\\chromedriver.exe')
self.options.binary_location = "C:/Google/Chrome/Application/chrome.exe"
# 特别注意,windows下要带.exe
self.driver = webdriver.Chrome(options=self.options,service=self.service)
# self.driver.maximize_window()
# 根据桌面分辨率来定,主要是为了抓到验证码的截屏
self.driver.set_window_size(960, 800)
self.elements = []
self.video_titles = []
self.video_introduction = []
self.urls = []
self.url1s = []
self.url2s = []
self.video_urls = []
self.pic_urls = []
self.text_time = []
self.text_author = []
self.read_volume = []
def threadFunc(self):
#print("正在打开页面...")
try:
self.product()
self.consume()
except Exception as e:
#打印异常堆栈信息
print(e)
#print("正在关闭页面...")
self.driver.quit()
def product(self):
urlist = ['https://m.cn/video/videoinfo']
for j in range(len(urlist)):
# 让浏览器不要显示当前受自动化测试工具控制的提醒
url = urlist[j]+("{}".format(i))+'_0_0.htm'
url1 = 'https://video.cn/Video/VideoDetail.aspx?'
url1 = url1 + "vid="+format(i)
#print(url,url1)
#查看目前打开的窗口,并切换
#list_windows = self.driver.window_handles
#self.driver.switch_to.window(list_windows[1])
self.driver.get(url)
#设置隐式等待
self.driver.implicitly_wait(8) #加载等待最长8秒
time.sleep(1)
#print(self.driver.page_source)
#执行js得到整个HTML
html_content = self.driver.execute_script("return document.documentElement.outerHTML")
self.que.put(self.driver.title)
# 正则表达式匹配标题
pattern = r'<title>(.*?)</title>'
#返回的是一个列表提 [0]取出来
title = re.findall(pattern,html_content)[0]
#print(title)
# 无id,无name,先定位iframe元素
#iframe = self.driver.find_element(By.TAG_NAME, "iframe")
if(title!=''):
#print(iframe,title)
# 使用selenium进行自动化工作
pic = self.driver.find_element(by=By.CSS_SELECTOR,value='#articleContent > a > img').get_attribute('src')
#print(pic)
self.element = self.driver.find_elements(by=By.CLASS_NAME,value='articleTitle')
#print(len(self.element),type(self.element))
info = self.element[0].find_elements(by=By.TAG_NAME,value='h1')[0].text
#print(info)
url2 = 'https://video.cn/Search.aspx?type=1&key='+info
# 允许我们从html中获取文本。该方法get_attribute() 可以接受像 "textContent", "value", "innerHtml"这样的参数。
str1 = self.element[0].find_element(by=By.CSS_SELECTOR,value='.fl > p').get_attribute("textContent")
m = re.search("(\d{4}-\d{1,2}-\d{1,2})", str1, re.M|re.I)
textTime = self.parse_date(m.group(1)) or ''
#print(textTime,str1)
textAuthor = self.element[0].find_element(by=By.CLASS_NAME,value='from').text or ''
#print(textAuthor)
readVolume = self.element[0].find_element(by=By.CLASS_NAME,value='fr').text or ''
#print(readVolume)
video = self.driver.find_element(by=By.ID, value='player-container-id_html5_api').get_attribute('src')
#print(video)
content = self.driver.find_element(by=By.CSS_SELECTOR,value='#Form1 > div.p10 > article > div.articlevideo.clearfix > div.clearfix.articleContent').text
#print(content)
#self.video_titles.append(info)
#self.video_introduction.append(content)
#self.urls.append(url)
#self.url1s.append(url1)
#self.url2s.append(url2)
#self.video_urls.append(video)
#self.pic_urls.append(pic)
#self.text_time.append(textTime)
#self.text_author.append(textAuthor)
#self.read_volume.append(readVolume)
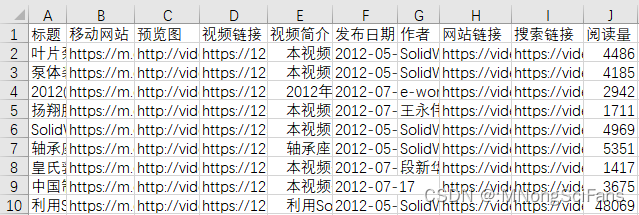
self.data_write(str(maxlist[k])+'.xls', info, url, pic, video, content, textTime, textAuthor, readVolume, url1, url2)
#self.elements = self.driver.find_elements(by=By.CLASS_NAME, value='detail')
#for k in range(len(self.elements)):
# self.elements[k].click()
# time.sleep(1)
# print('先进先出队列:{0};是否为空:{1};队列大小:{2};是否满:
# {3}'.format(self.que.queue,self.que.empty(),self.que.qsize(),self.que.full()))
else:
# 页面为空
print(format(i)+" is none!")
def consume(self):
for i in range(self.count):
#temp = self.que.get()
#print(temp)
#print(temp.current_url)
#print(temp.window_handles)
self.que.task_done()
def data_write(self, file_path, info, url, pic, video, content, textTime, textAuthor, readVolume, url1, url2):
# 将数据写入新文件
r_xls = open_workbook(file_path) # 读取excel文件
row = r_xls.sheets()[0].nrows # 获取已有的行数
excel = copy(r_xls) # 将xlrd的对象转化为xlwt的对象
table = excel.get_sheet(0) # 获取要操作的sheet
#对excel表追加一行内容
table.write(row, 0, info)
#括号内分别为行数、列数、内容
table.write(row, 1, url)
table.write(row, 2, pic)
table.write(row, 3, video)
table.write(row, 4, content)
table.write(row, 5, textTime)
table.write(row, 6, textAuthor)
table.write(row, 7, readVolume)
table.write(row, 8, url1)
table.write(row, 9, url2)
excel.save(file_path) # 保存并覆盖文件
time.sleep(1)
def parse_date(self,text):
# 使用datetime模块解析日期
formats = ['%Y-%m-%d', '%m/%d/%Y', '%d-%b-%Y']
for fmt in formats:
try:
date_obj = datetime.strptime(text, fmt)
return date_obj.strftime('%Y-%m-%d')
except ValueError:
pass
return None
def getheaders(self):
user_agent_list = ['Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1464.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.3319.102 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:17.0) Gecko/20100101 Firefox/17.0.6',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36']
UserAgent=random.choice(user_agent_list)
return UserAgent
if __name__ == '__main__':
startTime = time.perf_counter()
print(datetime.now())
#time.process_time()
#time.default_timer()
#time.perf_counter()
#count = int(input('请输入队列数:'))
# 默认开启10个队列
count = 10
# 最大页码编号
maxlist = [2000,3000,4000,5000,6000]
# 初始页码编号
for k in range(len(maxlist)):
i = maxlist[k] - 1000
while i < maxlist[k]:
try:
threads = []
for _ in range(count): # 循环创建10个线程
process = ShellChrome(count)
t = threading.Thread(target=process.threadFunc)
threads.append(t)
t.daemon=True # 给每个子线程添加守护线程
for t in threads: # 循环启动10个线程
#每个线程开启后增加1页
t.start()
i+=1
for t in threads:
t.join(10) # 设置子线程超时10秒
except Exception as e:
#打印异常堆栈信息
print(e)
time.sleep(30)
endTime = time.perf_counter()
print(int( (endTime-startTime) * 1000) / 1000)
print(datetime.now())
程序运行数据监控
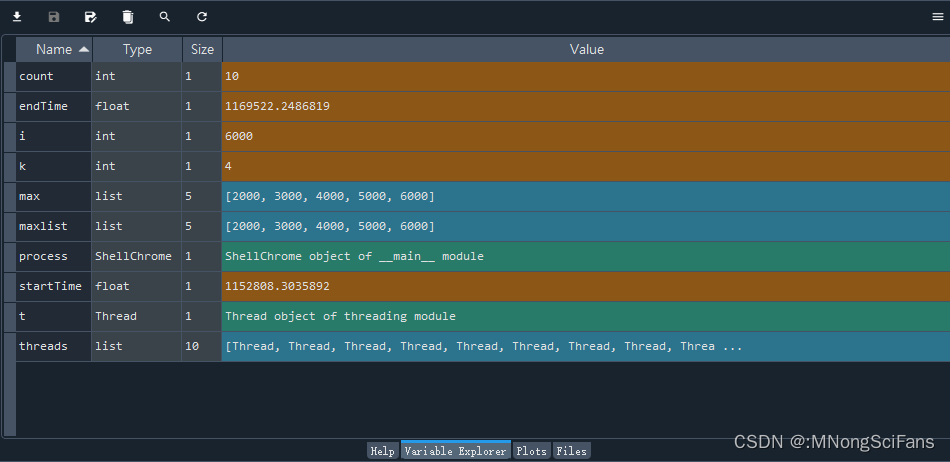
totalTime = (1169522-1152808)/(60*60) = 16714秒 = 约278.6分钟 = 约4.6小时
参见:
Welcome to Python.org
Unleash AI Innovation and Value | Anaconda
Selenium
标签:
python
本文转载自: https://blog.csdn.net/david_232656/article/details/136411677
版权归原作者 :MNongSciFans 所有, 如有侵权,请联系我们删除。
版权归原作者 :MNongSciFans 所有, 如有侵权,请联系我们删除。