
FlinkSql读取iceberg数据写入kafka
- 创建写入kafka的sink表
create table dws_mtrl_tree(
ODS_QYBM INT,
ODS_QYMC STRING,
MTRL_CODE STRING,
UPPER_MTRL_CODE STRING)
with ('connector'='kafka','topic'='dws_mtrl_tree','properties.bootstrap.servers'='xx.xxx.xxx.xxx:9092','format' = 'json','sink.partitioner'='round-robin');
- 创建catalog
CREATE CATALOG hive_catalog WITH ('type'='iceberg','catalog-type'='hive','uri'='thrift://xx.xxx.xxx.xxx:9083','clients'='5','hive-conf-dir'='/opt/softwares/hadoop-3.1.1/etc/hadoop/','warehouse'='hdfs://xx.xxx.xxx.xxx:8020/user/hive/warehouse/hive_catalog','property-version'='1');
- 插入数据
insert into dws_mtrl_tree select*from hive_catalog.dws_hgdd. dws_mtrl_tree;
发现kafka中已有数据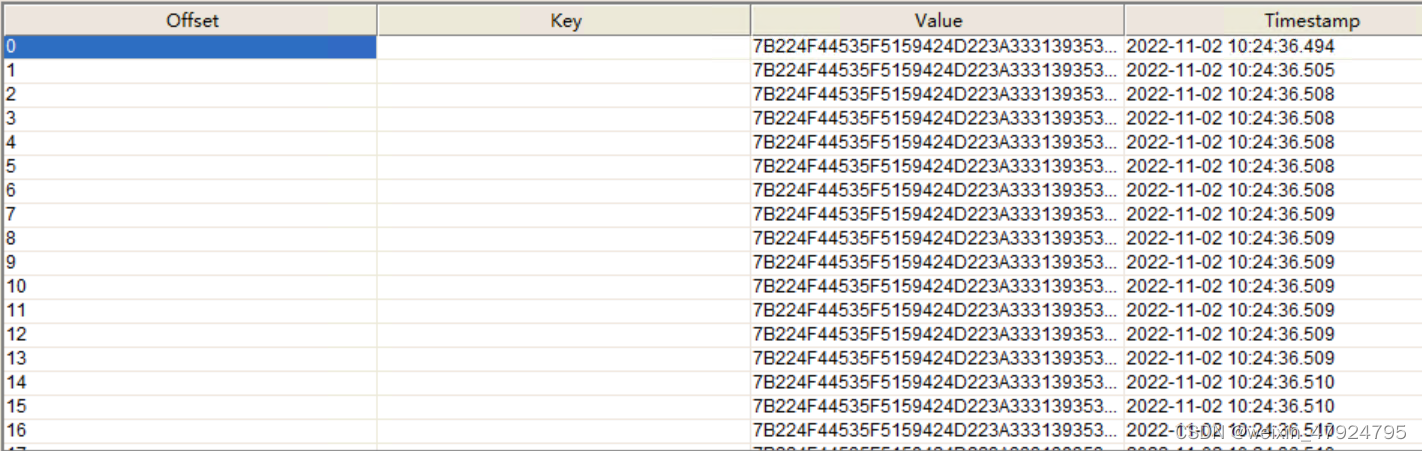
FlinkSql读取kafka数据写入iceberg
- 创建连接Kafka的Source表
CREATE TABLE kafka_dws_mtrl_tree (
ODS_QYBM INT,
ODS_QYMC STRING,
MTRL_CODE STRING,
UPPER_MTRL_CODE STRING
)with('connector' = 'kafka','topic' = 'dws_mtrl_tree','properties.bootstrap.servers' = 'xx.xxx.xxx.xxx:9092','properties.group.id' = 'consumergroup','format' = 'json','scan.startup.mode' = 'earliest-offset');
- 创建iceberg表
CREATE TABLE DWS_MTRL_TREE (
ODS_QYBM int,
ODS_QYMC string,
MTRL_CODE string,
UPPER_MTRL_CODE string
)with('connector'='iceberg','catalog-name'='hive_catalog','catalog-type'='hive','catalog-database'='DWS_HGDD','warehouse'='hdfs://xx.xxx.xxx.xxx:8020/user/hive/warehouse/hive_catalog','format-version'='2');
3.插入数据
insert into DWS_MTRL_TREE select*from kafka_dws_mtrl_tree;
- 问题: 报错如下:org.apache.flink.util.FlinkRuntimeException: Failed to send data to Kafka null with FlinkKafkaInternalProducer{transactionalId=‘null’, inTransaction=false, closed=false} Caused by: org.apache.flink.kafka.shaded.org.apache.kafka.common.errors.TimeoutException: Topic dws_mtrl_tree not present in metadata after 60000 ms.
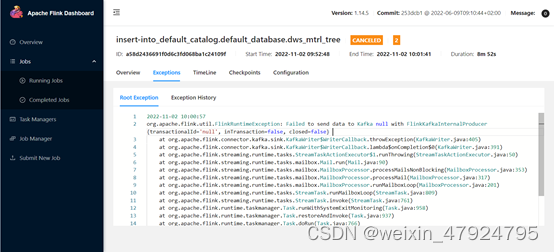

排查原因:
通过查看taskmanager的logs发现 :
Error connecting to node node02:9092 (id: 43 rack: null)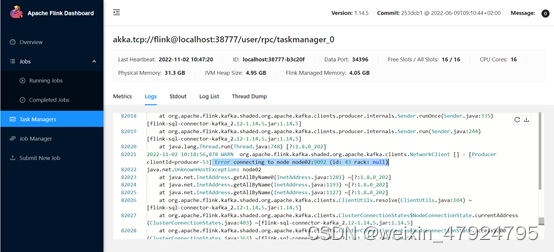
解决办法:
在/etc/hosts文件中添加映射,问题解决
xx.xxx.xxx.xxx node01
xx.xxx.xxx.xxx node02
xx.xxx.xxx.xxx node03
本文转载自: https://blog.csdn.net/weixin_47924795/article/details/127664853
版权归原作者 Xiaobai on data 开发 所有, 如有侵权,请联系我们删除。
版权归原作者 Xiaobai on data 开发 所有, 如有侵权,请联系我们删除。