
0.前提准备
环境
1. 准备好django2.2
2. 创建一个app
3.elasticsearch7.5启动
4.可视化工具(实在没有,也没啥)
models.py
from django.db import models
# Create your models here.
class Article(models.Model):
title = models.CharField(verbose_name='文章标题', max_length=225, db_index=True)
content = models.TextField(verbose_name='内容')
# 外键
tag = models.ForeignKey(verbose_name='标签', to='Tag', on_delete=models.DO_NOTHING)
def __str__(self):
return self.title
class Tag(models.Model):
name = models.CharField(verbose_name='标签', max_length=225)
def __str__(self):
return self.name
1.安装
pip3 install jieba -i https://pypi.douban.com/simple/
pip3 install django-haystack -i https://pypi.douban.com/simple/
pip3 install drf-haystack -i https://pypi.douban.com/simple/
pip3 install elasticsearch==7.6.0 -i https://pypi.douban.com/simple/
pip3 install django==2.2 -i https://pypi.douban.com/simple/
2.setting.py
es其他版本配置
Haystack 入门 — Haystack 2.5.0 文档 (django-haystack.readthedocs.io)https://django-haystack.readthedocs.io/en/master/tutorial.html
# 注册
INSTALLED_APPS = [
...
'haystack',
'rest_framework',
...
]
# 配置7.x
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.elasticsearch7_backend.Elasticsearch7SearchEngine',
'URL': 'http://127.0.0.1:9200/',
'INDEX_NAME': 'haystack',
},
}
3.配置 drf_haystack
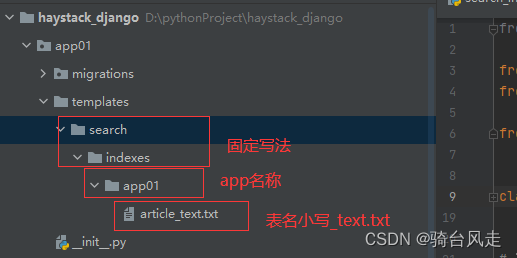
3.1 目录介绍
文字介绍
app01/templates/search/indexes/app01/article_text.txt
indexes:是你要建立的索引的app,article是你要建立索引的那个模型名(小写)
图解
3.2 article.text.txt
给这几个字段建立索引,用作全文检索
{{ object.tile}}
{{ object.tag.name}}
{{ object.content }}
4. search_indexes.py
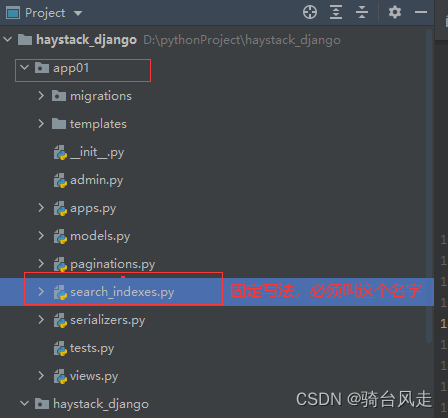
4.1 介绍
search_indexes.py固定写法,必须叫这个名字
位置:在自己的app下创建即可
4.2 search_indexes.py
索引模型类的名称必须是 模型类名称 + Index
from haystack import indexes
from .models import Article
# 必须继承 indexes.SearchIndex, indexes.Indexable
# ArticleIndex是固定格式命名,Article是你models.py中的类名
class ArticleIndex(indexes.SearchIndex, indexes.Indexable):
# document=True:将为text字段内容建立索引,此字段内容,可以由多个字段内容联合而成,有且只有一个
# use_template=True决定建立索引的字段内容,可以自定义模板
text = indexes.CharField(document=True, use_template=True)
# 下面的就是和你model里面的一样了
# python manage.py rebuild_index
# model_attr指定为对应模型的哪个字段
# 以下字段作为辅助字段,我也不知道辅助什么
id = indexes.IntegerField(model_attr='id')
title = indexes.CharField(model_attr='title')
tag = indexes.CharField(model_attr='tag')
# 必须这个写,返回的就是你的model名称
def get_model(self):
"""返回建立索引的模型类"""
# 每次查询都走这个
return Article
# 返回你的查询的结果,可以改成一定的条件的,但是格式就是这样
def index_queryset(self, using=None):
"""返回要建立索引的数据查询集"""
# 写入es的数据
query_set = self.get_model().objects.all()
return query_set
5. serializers.py
from haystack.utils import Highlighter
from rest_framework import serializers
from drf_haystack.serializers import HaystackSerializer, HighlighterMixin
from .search_indexes import *
class ArticleSerializer(serializers.ModelSerializer):
"""
序列化器
"""
tag = serializers.CharField(source='tag.name')
class Meta:
model = Article
# 返回除了搜索字段外的所需要的其他字段数据, 可以将所有需要返回的字段数据写上,便于提取
fields = ('id', 'title', 'tag', 'content')
# 写法一:普通序列化,使用内置的高亮
class ArticleIndexSerializer(HaystackSerializer):
"""
SKU索引结果数据序列化器
"""
# 变量名称必须为 object 否则无法返回
# 变量名称必须为 object 否则无法返回,
# 返回除搜索字段以外的字段,由上面ArticleSerializer自定义返回字段
object = ArticleSerializer(read_only=True) # 只读,不可以进行反序列化
class Meta:
index_classes = [ArticleIndex] # 索引类的名称,可以有多个
# text 由索引类进行返回, object 由序列化类进行返回,第一个参数必须是text
# 返回字段,不写默认全部返回
# text字段必须有,不然无法实现搜索
# 控制的是建立的索引字段
fields = ['text', object]
# fields = ['text']
# 忽略字段
# ignore_fields = ['title']
# 除了该字段,其他的都返回,
# exclude = ['title']
'''
# 写法二:自定义高亮,比内置的要慢一点
class ArticleIndexSerializer(HighlighterMixin, HaystackSerializer):
"""
SKU索引结果数据序列化器
"""
# 变量名称必须为 object 否则无法返回,
# 返回除搜索字段以外的字段,由上面ArticleSerializer自定义返回字段
object = ArticleSerializer(read_only=True) # 只读,不可以进行反序列化
# 高亮显示字段配置
# highlighter_class = Highlighter
# 前端自定义css名称
highlighter_css_class = "my-highlighter-class"
# html
highlighter_html_tag = "em"
# 最宽
highlighter_max_length = 200
class Meta:
index_classes = [ArticleIndex] # 索引类的名称,可以有多个
fields = ['text', object]
'''
6. views.py
from django.shortcuts import HttpResponse
from drf_haystack.viewsets import HaystackViewSet
from drf_haystack.filters import HaystackOrderingFilter, HaystackHighlightFilter
from .models import *
from .paginations import ArticleSearchPageNumberPagination
from .serializers import ArticleIndexSerializer
class ArticleSearchViewSet(HaystackViewSet):
"""
文章搜索
"""
index_models = [Article] # 表模型,可以添加多个
serializer_class = ArticleIndexSerializer
pagination_class = ArticleSearchPageNumberPagination
# 高亮,排序
# HaystackOrderingFilter:排序,
# HaystackHighlightFilter:内置高亮,如果使用了方式自定义高亮,就不要配置这个了
filter_backends = [HaystackOrderingFilter, HaystackHighlightFilter]
ordering_fields = ('id',)
""" """
# 重写,自己可以构造数据
def list(self, request, *args, **kwargs):
response = super(ArticleSearchViewSet, self).list(request, *args, **kwargs)
data = response.data
# 本文修改返回数据,把返回的索引字段去掉,您可以根据自己的需求,把这一句注释掉
[item.pop('text') for item in data['results']]
return response
7.urls.py
from django.contrib import admin
from django.urls import path, re_path
from app01 import views
# 路由方式一,首页即可看到数据
# http://127.0.0.1:8000/search/?text=中国&ordering=id
# http://127.0.0.1:8000/search/?text=中国
from rest_framework.routers import SimpleRouter
router = SimpleRouter()
router.register('search', views.ArticleSearchViewSet, basename='search_api')
# router.register("", views.ArticleAPIView)
urlpatterns = [
# re_path(r'^$', views.ArticleSearchViewSet.as_view({'get': 'list'})),
path('admin/', admin.site.urls),
path('update/', views.update)
]
urlpatterns += router.urls
# 路由方式二,大黄页
"""
# http://127.0.0.1:8000/search/?text=中国&ordering=id
# http://127.0.0.1:8000/search/?text=中国
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'search_one/(?P<pk>\d+)/', views.ArticleSearchViewSet.as_view({'get': 'retrieve'})),
path('search/', views.ArticleSearchViewSet.as_view({'get': 'list'})),
]
"""
8.paginations
from rest_framework.pagination import PageNumberPagination
class ArticleSearchPageNumberPagination(PageNumberPagination):
"""文章搜索分页器"""
# 每页显示几条
page_size = 10
# 最大数量
max_page_size = 5000
# 前端自定义查询的数量,?size=10
page_size_query_param = "size"
# 查询参数
page_query_param = "page"
9.执行
python manage.py makemigrations
python manage.py migrate
# 重新创建索引,删掉之前的,进行数据同步
python manage.py rebuild_index
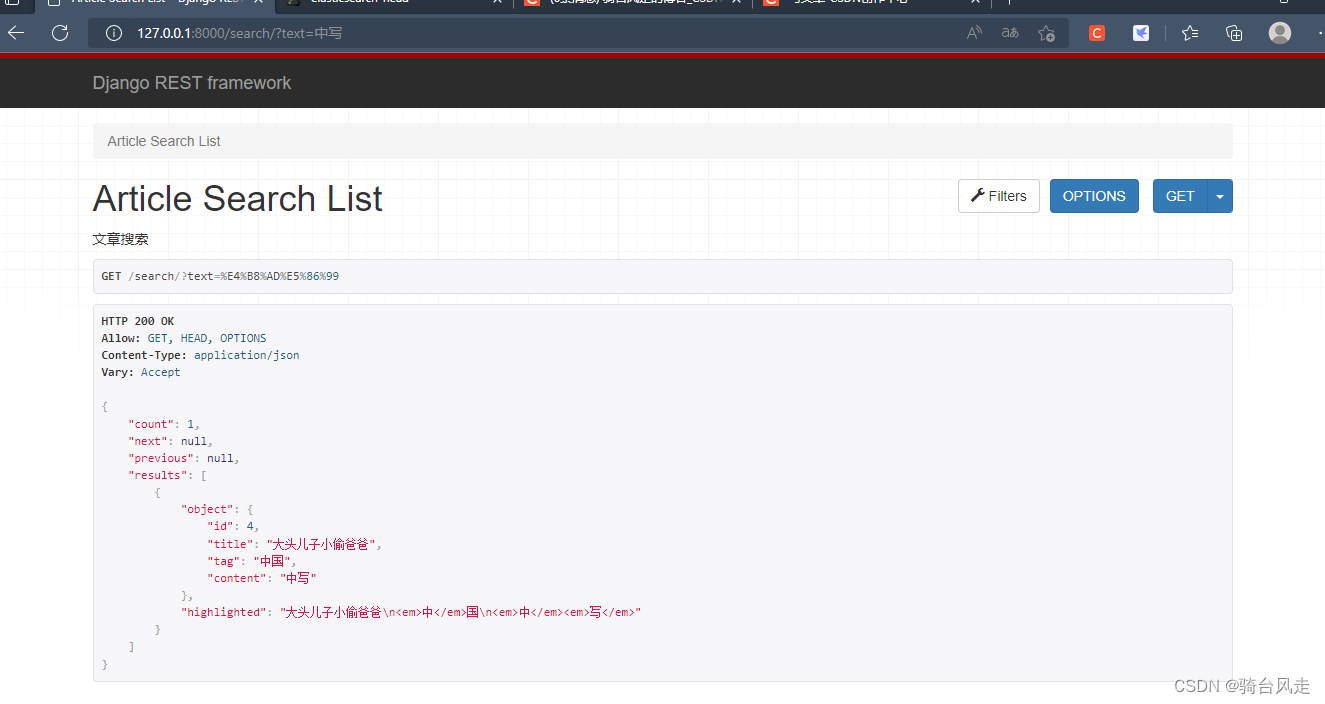
10. 验证是从es中查询的数据
1.直接修改mysql数据库数据,查看查询的数据会不会改变,不改就是es,改了就是mysql
11.换成ik分词器
11.1安装
基于docker安装Elasticsearch+ElasticSearch-Head+IK分词器_骑台风走的博客-CSDN博客基于docker安装Elasticsearch+ElasticSearch-Head+IK分词器https://blog.csdn.net/qq_52385631/article/details/126567059?spm=1001.2014.3001.5501ES--IK分词器安装_骑台风走的博客-CSDN博客ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。......https://blog.csdn.net/qq_52385631/article/details/126392092?spm=1001.2014.3001.5501
11.2 使用ik重写es7.5引擎
10.2.1 新建elasticsearch_ik_backend.py(在自己的app下)
在 blog应用下新建名为 elasticsearch7_ik_backend.py 的文件,
继承 Elasticsearch7SearchBackend(后端) 和 Elasticsearch7SearchEngine(搜索引擎) 并重写建立索引时的分词器设置
 elasticsearch7_ik_backend.py
elasticsearch7_ik_backend.py
from haystack.backends.elasticsearch7_backend import Elasticsearch7SearchBackend, Elasticsearch7SearchEngine
"""
分析器主要有两种情况会被使用:
第一种是插入文档时,将text类型的字段做分词然后插入倒排索引,
第二种就是在查询时,先对要查询的text类型的输入做分词,再去倒排索引搜索
如果想要让 索引 和 查询 时使用不同的分词器,ElasticSearch也是能支持的,只需要在字段上加上search_analyzer参数
在索引时,只会去看字段有没有定义analyzer,有定义的话就用定义的,没定义就用ES预设的
在查询时,会先去看字段有没有定义search_analyzer,如果没有定义,就去看有没有analyzer,再没有定义,才会去使用ES预设的
"""
DEFAULT_FIELD_MAPPING = {
"type": "text",
"analyzer": "ik_max_word",
# "analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
class Elasticsearc7IkSearchBackend(Elasticsearch7SearchBackend):
def __init__(self, *args, **kwargs):
self.DEFAULT_SETTINGS['settings']['analysis']['analyzer']['ik_analyzer'] = {
"type": "custom",
"tokenizer": "ik_max_word",
# "tokenizer": "ik_smart",
}
super(Elasticsearc7IkSearchBackend, self).__init__(*args, **kwargs)
class Elasticsearch7IkSearchEngine(Elasticsearch7SearchEngine):
backend = Elasticsearc7IkSearchBackend
11.3 修改settings.py(切换成功)
# es 7.x配置
HAYSTACK_CONNECTIONS = {
'default': {
# 'ENGINE': 'haystack.backends.elasticsearch7_backend.Elasticsearch7SearchEngine',
'ENGINE': 'app01.elasticsearch_ik_backend.Elasticsearch7IkSearchEngine',
'URL': 'http://127.0.0.1:9200/',
# elasticsearch建立的索引库的名称,一般使用项目名作为索引库
'INDEX_NAME': 'ha_drf',
},
}
11.4 重建索引,同步数据
python manage.py rebuild_index
11.5 补充
11.5.1 未成功切换成ik
haystack 原先加载的是 ...\venv\Lib\site-packages\haystack\backends 文件夹下的 elasticsearch7_backend.py 文件,打开即可看到 elasticsearch7 引擎的默认配置
若用上述方法建立出来的索引字段仍使用 snowball 分词器,则将原先elasticsearch7_backend.py 文件中的 DEFAULT_FIELD_MAPPING 也修改为 ik 分词器(或许是因为版本问题)
位置:D:\py_virtualenv\dj_ha\Lib\site-packages\haystack\backends\elasticsearch7_backend.py
修改内容:
DEFAULT_FIELD_MAPPING = {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
}
11.5.2 es6版本加入ik,重写引擎
from haystack.backends.elasticsearch_backend import ElasticsearchSearchBackend
from haystack.backends.elasticsearch_backend import ElasticsearchSearchEngine
class IKSearchBackend(ElasticsearchSearchBackend):
DEFAULT_ANALYZER = "ik_max_word" # 这里将 es 的 默认 analyzer 设置为 ik_max_word
def __init__(self, connection_alias, **connection_options):
super().__init__(connection_alias, **connection_options)
def build_schema(self, fields):
content_field_name, mapping = super(IKSearchBackend, self).build_schema(fields)
for field_name, field_class in fields.items():
field_mapping = mapping[field_class.index_fieldname]
if field_mapping["type"] == "string" and field_class.indexed:
if not hasattr(
field_class, "facet_for"
) and not field_class.field_type in ("ngram", "edge_ngram"):
field_mapping["analyzer"] = getattr(
field_class, "analyzer", self.DEFAULT_ANALYZER
)
mapping.update({field_class.index_fieldname: field_mapping})
return content_field_name, mapping
class IKSearchEngine(ElasticsearchSearchEngine):
backend = IKSearchBackend
版权归原作者 骑台风走 所有, 如有侵权,请联系我们删除。