
第1关:Create/Alter/Drop 数据库
任务描述
本关任务:根据编程要求对数据库进行相关操作。
相关知识
为了完成本关任务,你需要掌握: 1.如何创建数据库; 2.如何修改数据库; 3.如何删除数据库。
Create 创建数据库
数据库本质上是一个目录或命名空间,用于解决表命名冲突。
创建数据库的语法为:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value,…)];
DATABASE|SCHEMA:用于限定创建数据库或数据库模式IF NOT EXISTS:目标对象不存在时才执行创建操作(可选)COMMENT:起注释说明作用LOCATION:指定数据库位于HDFS上的存储路径。若未指定,将使用${hive.metastore.warehouse.dir}定义值作为其上层路径位置WITH DBPROPERTIES:为数据库提供描述信息,如创建database的用户或时间1.创建一个名为
shopping的数据库,位于
HDFS的
/hive/shopping下,创建人为
Xiaoming,创建日期为:
2019-01-01。
CREATE DATABASE IF NOT EXISTS shopping LOCATION '/hive/shopping' WITH DBPROPERTIES('creator'='Xiaoming','date'='2019-01-01');*说明:
CREATE等关键字大小写均可。*
2.使用
exit;命令退出
hive命令行模式,然后再用
hdfs dfs -ls /hive查看
HDFS上的目录,可以看出上述
CREATE操作在
HDFS的
/hive目录下创建了一个
shopping目录。
3.使用命令查看数据库
shopping的信息(若不指定关键字
EXTENDED,则不会输出
{}里的内容)。
DESCRIBE DATABASE EXTENDED shopping;
** Alter 修改数据库**
修改数据库的语法为:
ALTER (DATABASE|SCHEMA)database_name SET DBPROPERTIES (property_name=property_value,…);
- 只能修改数据库的键值对属性值。数据库名和数据库所在的目录位置不能修改
1.修改数据库
shopping的键值对描述信息中的创建者信息,修改创建人为
Xiaohong。
ALTER DATABASE shopping SET DBPROPERTIES('creator'='Xiaohong');
2.使用命令查看修改后的数据库
shopping的信息。
DESCRIBE DATABASE EXTENDED shopping;
** Drop 删除数据库**
选择使用数据库
shopping:
use shopping;删除数据库语法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
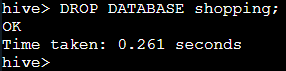
DATABASE|SCHEMA:用于限定删除的数据库或数据库模式IF EXISTS:目标对象存在时才执行删除操作(可选)RESTRICT|CASCADE:RESTRICT为 Hive 默认操作方式,当database_name中不存在任何数据库对象时才能执行DROP操作;CASCADE采用强制DROP方式,汇联通存在于database_name中的任何数据库对象和database_name一起删除(可选)1.删除数据库
shopping,该操作会删除其位于
HDFS上的
shopping目录。
DROP DATABASE shopping;





编程要求
请根据右侧命令行内的提示,在
Begin - End区域内进行
sql语句代码补充,具体任务如下:
- 创建数据库
test1,位于HDFS的/hive/test1下,创建人creator为John,创建日期date为2019-02-25- 修改数据库
test1的创建人为Marry- 删除数据库
test1*按照以上要求填写命令。每个要求对应一条命令,共
3条命令,以
;隔开。*
*由于
hive启动时间较长,测评时请耐心等待,大概需要时间:
1-3分钟。*
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
若操作成功,会显示如下信息:
test1数据库的信息如下: test1 hdfs://localhost:9000/hive/test1 root USER {data=2019-02-25, creator=John} 修改后test1数据库的信息如下: test1 hdfs://localhost:9000/hive/test1 root USER {date=2019-02-25, creator=Marry} 查看当前有哪些数据库: default
代码:
#********* Begin *********#
echo "
CREATE DATABASE IF NOT EXISTS test1
LOCATION '/hive/test1'
WITH DBPROPERTIES('creator'='John','date'='2019-02-25');
ALTER DATABASE test1 SET DBPROPERTIES('creator'='Marry');
DROP DATABASE test1;
"
#********* End *********#
第2关:Create/Drop/Truncate 表
任务描述
本关任务:根据编程要求在数据库中对表进行相应的操作。
相关知识
为了完成本关任务,你需要掌握:
1.如何创建表;
2.如何复制表;
3.如何删除表;
4.如何截断表。
Create 创建表
创建表的语法为:
CREATE [TEMPOPARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [SKEWED BY (col_name,col_name,…) ON ([(col_value,col_value,…),…|col_value,col_value,…]) [STORED AS DIRECTORIES] ] [ [ROW FORMAT DELIMITED [FIFLDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,property_name=property_value,…)] ] [STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (…)] ] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value,…)] [AS select_statement];参数说明如下:
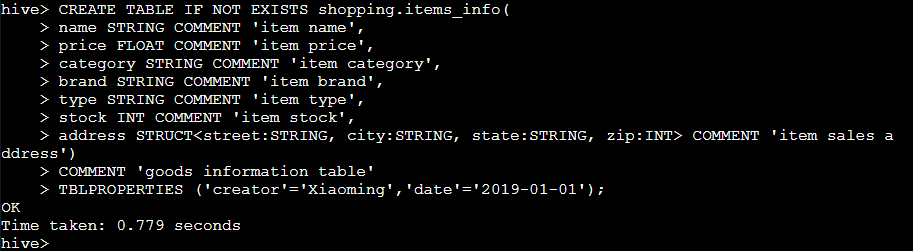
TEMPOPARY:创建临时表,若未指定,则默认创建的是普通表EXTERNAL:创建外部表,若未指定,则默认创建的是内部表IF NOT EXISTS:若表不存在才创建,若未指定,当目标表存在时,创建操作抛出异常db_name.:前缀,指定表所属于的数据库。若未指定且当前数据库非db_name,则使用default数据库COMMENT:添加注释说明,注释内容位于单引号内PARTITIONED BY:针对存储有大量数据集的表,根据表内容所具有的某些共同特征定义一个标签,将这类数据存储在该标签所标识的位置,可以提高表内容的查询速度。PARTITIONED BY中的列名为伪列或标记列,不能与表中的实体列名相同,否则 hive 表创建操作报错CLUSTERED BY:根据列之间的相关性指定列聚类在相同桶中(BUCKETS),可以对表内容按某一列进行升序(ASC)或降序(DESC)排序(SORTED BY关键字)SKEWED BY:用于过滤掉特定列col_name中包含值col_value(ON(col_value,…)关键字指定的值)的记录,并单独存储在指定目录(STORED AS DIRECTORIES)下的单独文件中ROW FORMAT:指定 hive 表行对象(ROW Object)数据与 HDFS 数据之间进行传输的转换方式(HDFS files -> Deserializer ->Row object以及Row object ->Serializer ->HDFS files),以及数据文件内容与表行记录各列的对应。在创建表时可以指定数据列分隔符(FIFLDS TERMINATED BY 子句)、对特殊字符进行转义的特殊字符(ESCAPED BY 子句)、符合数据类型值分隔符(COLLECTION ITEMS TERMINATED BY 子句)、MAP key-value类型分隔符(MAP KEYS TERMINATED BY)、数据记录行分隔符(LINES TERMINATED BY)、定义NULL字符(NULL DEFINED AS),同时可以指定自定义的SerDE(Serializer和Deserializer,序列化和反序列化),也可以指定默认的SerDE。如果ROW FORMAT未指定或指定为ROW FORMAT DELIMITED,将使用内部默认SerDeSTORED AS:指定 hive 表数据在 HDFS 上的存储方式。file_format值包括TEXTFILE(普通文本文件,默认方式)、SEQUENCEFILE(压缩模式)、ORC(ORC文件格式)和AVRO(AVRO文件格式)STORED BY:创建一个非本地表,如创建一个 HBase 表LOCATION:指定表数据在 HDFS 上的存储位置。若未指定,db_name数据库将会储存在${hive.metastore.warehouse.dir}定义位置的db_name目录下TBLPROPERTIES:为所创建的表设置属性(如创建时间和创建者,默认为当前用户和当前系统时间)AS select_statement:使用select子句创建一个复制表(包括select子句返回的表模式和表数据)1.在之前创建的
shopping数据库创建一张商品信息表(
items_info):
CREATE TABLE IF NOT EXISTS shopping.items_info( name STRING COMMENT 'item name', price FLOAT COMMENT 'item price', category STRING COMMENT 'item category', brand STRING COMMENT 'item brand', type STRING COMMENT 'item type', stock INT COMMENT 'item stock', address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT> COMMENT 'item sales address') COMMENT 'goods information table' TBLPROPERTIES ('creator'='Xiaoming','date'='2019-01-01');
2.查看
items_info表结构:
use shopping; #切换到数据库shopping中 desc items_info;
** 复制表**
按照已存在的表或视图定义一个相同结构的表或视图(使用
LIKE关键字,只复制表定义,不复制表数据)。
1.复制刚才创建的表
items_info起名为
items_info2。
CREATE TABLE IF NOT EXISTS items_info2 LIKE items_info;
Drop 删除表
删除表的语法为:
DROP TABLE [IF EXISTS] table_name;
[IF EXISTS]:关键字可选;- 若未指定且表
table_name不存在时,Hive返回错误。1.删除刚才复制的表
items_info2:
DROP TABLE IF EXISTS items_info2;
** Truncate 截断表**
大家众所周知,当我们在自己的电脑上删除某一个文件,它并没有彻底删除而是进入了回收站,你要在回收站中再将其删除才算彻底清除。截断表就相当于直接将数据从电脑上删除,而不会放入回收站。
截断表(删除表中所有行)的语法为:
TRUNCATE TABLE table_name [PARTITION partition_spec]; partition_spec: (partition_column=partition_col_value,partition_column=partition_col_value,…)



编程要求
请根据右侧命令行内的提示,在
Begin - End区域内进行
sql语句代码补充,具体任务如下:
student表结构:
INFOTYPECOMMENTSnoINTstudent snonameSTRINGstudent nameageINTstudent agesexSTRINGstudent sexscoreSTRUCT <Chinese:FLOAT,Math:FLOAT,English:FLOAT>student score
- 创建数据库
test2- 在
test2中创建表student,表结构如上所示- 使用
LIKE关键字创建一个与student表结构相同的表student_info- 删除表
student*按照以上要求填写命令。每个要求对应一条命令,共
4条命令,以
;隔开。*
*由于
hive启动时间较长,测评时请耐心等待,大概需要时间:
1-3分钟。*
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
若操作成功,会显示如下信息:
表student的结构为: sno int student sno name string student name age int student age sex string student sex score struct<Chinese:float,Math:float,English:float> student score 表student_info的结构为: sno int student sno name string student name age int student age sex string student sex score struct<Chinese:float,Math:float,English:float> student score 数据库test2中有以下表: student_info
代码:
#********* Begin *********#
echo "
CREATE DATABASE IF NOT EXISTS test2;
CREATE TABLE IF NOT EXISTS test2.student(Sno INT COMMENT 'student sno',name STRING COMMENT 'student name',age INT COMMENT 'student age',sex STRING COMMENT 'student sex',score STRUCT <Chinese:FLOAT,Math:FLOAT,English:FLOAT> COMMENT 'student score');
CREATE TABLE IF NOT EXISTS student_info
LIKE student;
DROP TABLE IF EXISTS student;
"
#********* End *********#
第3关:Alter 表/列
任务描述
本关任务:根据编程要求在数据库中对表进行相应的操作。
相关知识
为了完成本关任务,你需要掌握: 1.如何修改表; 2.如何修改列。
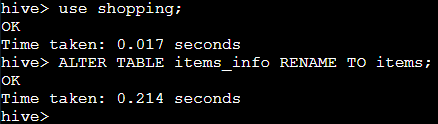
Alter 重命名表
重命名表的语法为:
ALTER TABLE table_name RENAME TO new_table_name;1.将上一关创建的
items_info表重命名为
items。
ALTER TABLE items_info RENAME TO items;
Alter 修改表
修改表列的语法为:
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUM] col_old_name col_new_name colum_type [COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
- 以上操作可以修改表的列名、列数据类型、列存储位置以及注释说明
FIRST、AFTER用于指定是否交换列的前后顺序- 该操作只改变表的
metadata(RESTRICT方式,即默认方式)CASCADE关键字用于限定修改操作同时同步到表metadata和分区metadata1.修改表
items的
price列名为
items_price。
ALTER TABLE items CHANGE price item_price FLOAT COMMENT 'items price';
Alter 修改列
增加表列和删除表列或替换表列的语法为:
ALTER TABLE table_name [PARTITION partition_spec] ADD|REPLACE COLUMNS (col_namedata_type [COMMENT col_comment],…) [CASCADE|RESTRICT]
ADD COLUMNS:用于在表中已存在实体列(existing columns)之后且分区列(partition columns,或伪列)之前添加新的列REPLACE COLUMNS:删除表中现有的全部列,添加新的列集合。该操作仅支持使用内部的SerDe(DynamicSerDe、MetadataTypedColumnsetSerDe/LazySimpleSerDe和ColumnarSerDe)的表(SerDe用于实现表数据与 HDFS 数据之间的转换方式)1.表
items添加生产日期
item_date列,数据类型为
STRING,说明为
items date:
ALTER TABLE items ADD COLUMNS (item_date STRING COMMENT 'item date');


编程要求
请根据右侧命令行内的提示,在
Begin - End区域内进行
sql语句代码补充,具体任务如下:
student表结构:
INFOTYPECOMMENTSnoINTstudent snonameSTRINGstudent nameageINTstudent agesexSTRINGstudent sexscoreSTRUCT <Chinese:FLOAT,Math:FLOAT,English:FLOAT>student score
- 创建数据库
test3- 在数据库
tets3中,创建表student,表结构如上所示,和第二关相同- 重命名表名字
student为student_info- 修改列名
age为student_age- 增加一列
birthday,数据类型为STRING,说明信息为student birthday*按照以上要求填写命令。每个要求对应一条命令,共
5条命令,以
;隔开。*
*由于
hive启动时间较长,测评时请耐心等待,大概需要时间:
1-3分钟。*
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
若操作成功,会显示如下信息:
student的表结构为: sno int student sno name string student name age int student age sex string student sex score struct<Chinese:float,Math:float,English:float> student score test3中有以下表: student_info 修改列名后的student_info表结构如下: sno int student sno name string student name student_age int student age sex string student sex score struct<Chinese:float,Math:float,English:float> student score 增加一列后的student_info表结构如下: sno int student sno name string student name student_age int student age sex string student sex score struct<Chinese:float,Math:float,English:float> student score birthday string student birthday
代码:
#********* Begin *********#
echo "
CREATE DATABASE IF NOT EXISTS test3;
CREATE TABLE IF NOT EXISTS test3.student(Sno INT COMMENT 'student sno',name STRING COMMENT 'student name',age INT COMMENT 'student age',sex STRING COMMENT 'student sex',score STRUCT <Chinese:FLOAT,Math:FLOAT,English:FLOAT> COMMENT 'student score');
ALTER TABLE student RENAME TO student_info;
ALTER TABLE student_info CHANGE age student_age INT COMMENT 'student age';
ALTER TABLE student_info ADD COLUMNS (birthday STRING COMMENT 'student birthday');
"
#********* End *********#
第4关:表分区
任务描述
本关任务:根据编程要求在数据库中对表进行相应的操作。
相关知识
为了完成本关任务,你需要掌握:
1.如何创建分区表;
2.如何添加分区;
3.如何重命名表分区;
4.如何交换表分区;
5.如何表分区信息持久化;
6.如何删除表分区。
创建分区表
使用
shopping数据库创建一张商品信息分区表
items_info2,按商品品牌
p_brand和商品分类
p_category进行分区:
CREATE TABLE IF NOT EXISTS shopping.items_info2( name STRING COMMENT 'item name', price FLOAT COMMENT 'item price', category STRING COMMENT 'item category', brand STRING COMMENT 'item brand', type STRING COMMENT 'item type', stock INT COMMENT 'item stock', address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT> COMMENT 'item sales address') COMMENT 'goods information table' PARTITIONED BY (p_category STRING,p_brand STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ',' TBLPROPERTIES ('creator'='Xiaoming','date'='2019-01-01');
添加分区
向表
items_info2添加两个分区:
ALTER TABLE items_info2 ADD PARTITION (p_category='clothes',p_brand='playboy') LOCATION '/hive/shopping/items_info2/playboy/clothes' PARTITION (p_category='shoes',p_brand='playboy') LOCATION '/hive/shopping/items_info2/playboy/shoes';
*注意:
PARTITIONED BY中的列
p_category和
p_brand为伪列,不能与表中的实体列名相同,否则hive表创建操作报错(
p_category和
p_brand分别对应表中的实体列
category、
brand)。*
重命名表分区
重命名表分区的语法为:
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;1.重命名
items_info2表的表分区
playboy/clothes为
playboy/T-shirt:
ALTER TABLE items_info2 PARTITION (p_category='clothes',p_brand='playboy') RENAME TO PARTITION (p_category='T-shirt',p_brand='playboy');
** 交换表分区**
交换表分区的语法为:
ALTER TABLE table_name_1 EXCHANGE PARTITION (partition_spec) WITH TABLE table_name_2;该操作移动表
table_name_1中特定分区下的数据到具有相同表模式且不存储在相应分区的
table_name_2中。
表分区信息持久化
表分区信息持久化的语法为:
MSCK REPAIR TABLE table_name;该操作作用于同步表
table_name在
HDFS上的分区信息到
Hive位于
RDBMS的
metastore中。
删除表分区
删除表分区的语法为:
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec,PARTITION partition_spec,…;该操作会删除与特定分区相关的数据以及
metadata。
1.删除表
items_info2的
playboy/shoes表分区:
ALTER TABLE items_info2 DROP IF EXISTS PARTITION (p_category='shoes',p_brand='playboy');




编程要求
请根据右侧命令行内的提示,在
Begin - End区域内进行
sql语句代码补充,具体任务如下:
student表结构:
INFOTYPECOMMENTSnoINTstudent snonameSTRINGstudent nameageINTstudent agesexSTRINGstudent sexscoreSTRUCT <Chinese:FLOAT,Math:FLOAT,English:FLOAT>student score
- 创建数据库
test4- 在数据库
tets4中,创建分区表student,表结构如上所示,和第二、三关相同,设置分区列为:stu_year类型STRING、subject类型STRING- 添加两个分区:
stu_year='2018',subject='Chinese'和stu_year='2018',subject='Math'- 重命名表分区:将
2018/Math分区重命名为2018/English- 删除表分区:将
2018/Chinese分区删除*按照以上要求,在代码栏填写命令。每个要求对应一条命令,共
5条命令,以
;隔开。*
*由于
hive启动时间较长,测评时请耐心等待,大概需要时间:
1-3分钟。*
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
预期输出:
student分区的表结构为: sno int student sno name string student name age int student age sex string student sex score struct<Chinese:float,Math:float,English:float> student score stu_year string subject string # Partition Information # col_name data_type comment stu_year string subject string 添加的分区为: stu_year=2018/subject=Chinese stu_year=2018/subject=Math 重命名后的分区为: stu_year=2018/subject=Chinese stu_year=2018/subject=English 删除后分区为: stu_year=2018/subject=English
代码:
#********* Begin *********#
echo "
CREATE DATABASE IF NOT EXISTS test4;
CREATE TABLE IF NOT EXISTS test4.student(Sno INT COMMENT 'student sno',name STRING COMMENT 'student name',age INT COMMENT 'student age',sex STRING COMMENT 'student sex',score STRUCT <Chinese:FLOAT,Math:FLOAT,English:FLOAT> COMMENT 'student score') PARTITIONED BY (stu_year STRING,subject STRING);
ALTER TABLE student ADD PARTITION (stu_year='2018',subject='Chinese') PARTITION (stu_year='2018',subject='Math');
ALTER TABLE student PARTITION (stu_year='2018',subject='Math') RENAME TO PARTITION (stu_year='2018',subject='English');
ALTER TABLE student DROP IF EXISTS PARTITION (stu_year='2018',subject='Chinese');
"
#********* End *********#
补充:以上部分代码大写字母理论上可以换成小写字母,如:ALTER TABLE。
版权归原作者 半爿天穹 所有, 如有侵权,请联系我们删除。