
一、Spark资源调度源码
1、Spark资源调度源码过程
Spark资源调度源码是在Driver启动之后注册Application完成后开始的。Spark资源调度主要就是Spark集群如何给当前提交的Spark application在Worker资源节点上划分资源。Spark资源调度源码在Master.scala类中的schedule()中进行的。
2、Spark资源调度源码结论
- Executor在集群中分散启动,有利于task计算的数据本地化。
- 默认情况下(提交任务的时候没有设置--executor-cores选项),每一个Worker为当前的Application启动一个Executor,这个Executor会使用这个Worker的所有的cores和1G内存。
- 如果想在Worker上启动多个Executor,提交Application的时候要加--executor-cores这个选项。
- 默认情况下没有设置--total-executor-cores,一个Application会使用Spark集群中所有的cores。
- 启动Executor不仅和core有关还和内存有关。
3、资源调度源码结论验证
使用Spark-submit提交任务演示。也可以使用spark-shell来验证。
1、默认情况每个worker为当前的Application启动一个Executor,这个Executor使用集群中所有的cores和1G内存。
./spark-submit
--master spark://node1:7077
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
2、在workr上启动多个Executor,设置--executor-cores参数指定每个executor使用的core数量。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
3、内存不足的情况下启动core的情况。Spark启动是不仅看core配置参数,也要看配置的core的内存是否够用。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--executor-memory 3g
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
--total-executor-cores集群中共使用多少cores
注意:一个进程不能让集群多个节点共同启动。
./spark-submit
--master spark://node1:7077
--executor-cores 1
--executor-memory 2g
--total-executor-cores 3
--class org.apache.spark.examples.SparkPi
../lib/spark-examples-1.6.0-hadoop2.6.0.jar
10000
二、Spark任务调度源码
Spark任务调度源码是从Spark Application的一个Action算子开始的。action算子开始执行,会调用RDD的一系列触发job的逻辑。其中也有stage的划分过程:
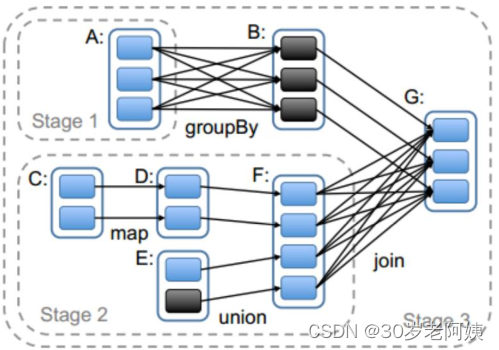
三、Spark二次排序和分组取topN
1、二次排序
大数据中很多排序场景是需要先根据一列进行排序,如果当前列数据相同,再对其他某列进行排序的场景,这就是二次排序场景。例如:要找出网站活跃的前10名用户,活跃用户的评测标准就是用户在当前季度中登录网站的天数最多,如果某些用户在当前季度登录网站的天数相同,那么再比较这些用户的当前登录网站的时长进行排序,找出活跃用户。这就是一个典型的二次排序场景。
解决二次排序问题可以采用封装对象的方式,对象中实现对应的比较方法。
1.SparkConf sparkConf = new SparkConf()
2..setMaster("local")
3..setAppName("SecondarySortTest");
4.final JavaSparkContext sc = new JavaSparkContext(sparkConf);
5.
6.JavaRDD<String> secondRDD = sc.textFile("secondSort.txt");
7.
8.JavaPairRDD<SecondSortKey, String> pairSecondRDD = secondRDD.mapToPair(new PairFunction<String, SecondSortKey, String>() {
9.
10. /**
11. *
12. */
13. private static final long serialVersionUID = 1L;
14.
15. @Override
16. public Tuple2<SecondSortKey, String> call(String line) throws Exception {
17. String[] splited = line.split(" ");
18. int first = Integer.valueOf(splited[0]);
19. int second = Integer.valueOf(splited[1]);
20. SecondSortKey secondSortKey = new SecondSortKey(first,second);
21. return new Tuple2<SecondSortKey, String>(secondSortKey,line);
22. }
23.});
24.
25.pairSecondRDD.sortByKey(false).foreach(new
26.VoidFunction<Tuple2<SecondSortKey,String>>() {
27.
28. /**
29. *
30. */
31. private static final long serialVersionUID = 1L;
32.
33. @Override
34. public void call(Tuple2<SecondSortKey, String> tuple) throws Exception {
35. System.out.println(tuple._2);
36. }
37.});
38.
39.
40.
41.public class SecondSortKey implements Serializable,Comparable<SecondSortKey>{
42. /**
43. *
44. */
45. private static final long serialVersionUID = 1L;
46. private int first;
47. private int second;
48. public int getFirst() {
49. return first;
50. }
51. public void setFirst(int first) {
52. this.first = first;
53. }
54. public int getSecond() {
55. return second;
56. }
57. public void setSecond(int second) {
58. this.second = second;
59. }
60. public SecondSortKey(int first, int second) {
61. super();
62. this.first = first;
63. this.second = second;
64. }
65. @Override
66. public int compareTo(SecondSortKey o1) {
67. if(getFirst() - o1.getFirst() ==0 ){
68. return getSecond() - o1.getSecond();
69. }else{
70. return getFirst() - o1.getFirst();
71. }
72. }
73.}
2、分组取topN
大数据中按照某个Key进行分组,找出每个组内数据的topN时,这种情况就是分组取topN问题。
解决分组取TopN问题有两种方式,第一种就是直接分组,对分组内的数据进行排序处理。第二种方式就是直接使用定长数组的方式解决分组取topN问题。
1.SparkConf conf = new SparkConf()
2..setMaster("local")
3..setAppName("TopOps");
4.JavaSparkContext sc = new JavaSparkContext(conf);
5.JavaRDD<String> linesRDD = sc.textFile("scores.txt");
6.
7.JavaPairRDD<String, Integer> pairRDD = linesRDD.mapToPair(new PairFunction<String, String, Integer>() {
8.
9. /**
10. *
11. */
12. private static final long serialVersionUID = 1L;
13.
14. @Override
15. public Tuple2<String, Integer> call(String str) throws Exception {
16. String[] splited = str.split("\t");
17. String clazzName = splited[0];
18. Integer score = Integer.valueOf(splited[1]);
19. return new Tuple2<String, Integer> (clazzName,score);
20. }
21.});
22.
23.pairRDD.groupByKey().foreach(new
24.VoidFunction<Tuple2<String,Iterable<Integer>>>() {
25.
26. /**
27. *
28. */
29. private static final long serialVersionUID = 1L;
30.
31. @Override
32. public void call(Tuple2<String, Iterable<Integer>> tuple) throws Exception {
33. String clazzName = tuple._1;
34. Iterator<Integer> iterator = tuple._2.iterator();
35.
36. Integer[] top3 = new Integer[3];
37.
38. while (iterator.hasNext()) {
39. Integer score = iterator.next();
40.
41. for (int i = 0; i < top3.length; i++) {
42. if(top3[i] == null){
43. top3[i] = score;
44. break;
45. }else if(score > top3[i]){
46. for (int j = 2; j > i; j--) {
47. top3[j] = top3[j-1];
48. }
49. top3[i] = score;
50. break;
51. }
52. }
53. }
54. System.out.println("class Name:"+clazzName);
55. for(Integer sscore : top3){
56. System.out.println(sscore);
57. }
58.}
59.});
版权归原作者 30岁老阿姨 所有, 如有侵权,请联系我们删除。