
Flink提供了基于JDBC的方式,可以将读取到的数据写入到MySQL中;本文通过两种方式将数据下入到MySQL数据库,其他的基于JDBC的数据库类似,另外,Table API方式的Catalog指定为Hive Catalog方式,持久化DDL操作。
另外,JDBC 连接器允许使用 JDBC 驱动程序从任何关系数据库读取数据并将数据写入其中。 本文档介绍如何设置 JDBC 连接器以针对关系数据库运行 SQL 查询。
如果 DDL 上定义了主键,则 JDBC sink 以 upsert 模式与外部系统交换 UPDATE/DELETE 消息,否则,它以 append 模式运行,不支持消费 UPDATE/DELETE 消息。
默认提供 exactly-once的保证。
MySQL配置
MySQL中创建表Events数据表
-- flink.events definition
CREATE TABLE `events` (
`user` varchar(100) DEFAULT NULL,
`url` varchar(200) DEFAULT NULL,
`timestamp` bigint(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
插入几条数据
INSERT INTO flink.events
(`user`, url, `timestamp`)
VALUES('Alice', './home', 1000);
Maven依赖,包含了Hive Catalog的相关依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.14.4</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<hadoop.version>3.1.2</hadoop.version>
<hive.version>3.1.2</hive.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Flink 的 Hive 连接器-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Hive 依赖 -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.calcite</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Hive 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- Hive 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- Hive 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
DataStream方式读写MySQL数据
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JdbcSinkExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> eventStream = env.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=1", 105 * 1000L)
);
eventStream.addSink(JdbcSink.sink(
"insert into events (user, url, timestamp) values (?, ?, ?)",
new JdbcStatementBuilder<Event>() {
@Override
public void accept(PreparedStatement preparedStatement, Event event) throws SQLException {
preparedStatement.setString(1, event.user);
preparedStatement.setString(2, event.url);
preparedStatement.setLong(3, event.timestamp);
}
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://127.0.0.1:3306/flink")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("xxx")
.build()
));
env.execute();
}
}
Table API的方式读写MySQL,其中Flink的Catalog使用Hive Catalog的方式。熟悉 Flink 或者 Spark 等大数据引擎的同学应该都知道这两个计算引擎都有一个共同的组件叫 Catalog。下面是 Flink 的 Catalog 的官方定义。
Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
Table API与SQL API实现了Apache Flink的批流统一的实现方式。Table API与SQL API的核心概念就是TableEnviroment。TableEnviroment对象提供方法注册数据源与数据表信息。那么数据源与数据表的信息则存储在CataLog中。所以,CataLog是TableEnviroment的重要组成部分。”
Apache Flink在获取TableEnviroment对象后,可以通过Register实现对数据源与数据表进行注册。注册完成后数据库与数据表的原信息则存储在CataLog中。CataLog中保存了所有的表结构信息、数据目录信息等。
简单来说,Catalog 就是元数据管理中心,其中元数据包括数据库、表、表结构等信息。
public class JDBCTable {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> eventStream = env.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=1", 105 * 1000L)
);
//获取表环境
//StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env);
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive";
String defaultDatabase = "default";
String hiveConfDir = "/opt/hive";
// 创建一个 HiveCatalog,并在表环境中注册
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tableEnv.registerCatalog("myhive", hive);
// 使用 HiveCatalog 作为当前会话的 catalog
tableEnv.useCatalog("myhive");
TableResult tableResult = tableEnv.executeSql("CREATE TABLE IF NOT EXISTS EventTable (\n" +
"`user` STRING,\n" +
"url STRING,\n" +
"`timestamp` BIGINT\n" +
") WITH (\n" +
"'connector' = 'jdbc',\n" +
"'url' = 'jdbc:mysql://127.0.0.1:3306/flink',\n" +
"'table-name' = 'events',\n" +
"'username'='root',\n" +
"'password'='xxx'\n" +
")");
tableEnv.executeSql("insert into EventTable values('Alice','./prod?id=3',106000)");
}
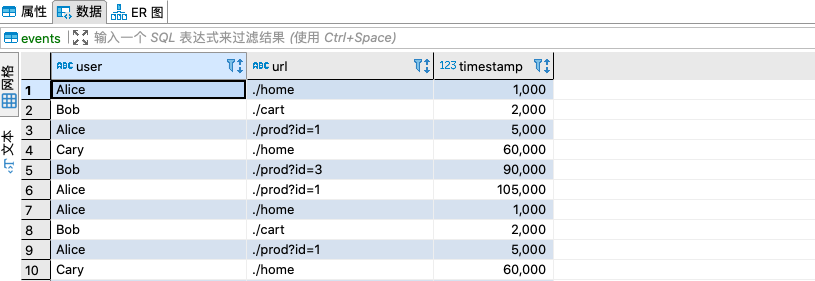
MySQL中的数据
版权归原作者 wank1259162 所有, 如有侵权,请联系我们删除。