
最近所在公司的项目里面想要集成AI算法实现对文档的自动学习和提炼的功能,而且需要能够实现本地化部署,搜索了一圈发现一个开源的项目叫DocsGPT比较适合,然后做了一下研究,中间踩了不少坑,记录一下,也希望能帮到其他有需要的朋友,本篇文章讲述的是通过centos服务器部署,后面也会再记录一篇基于windows服务器部署的文章。
开源项目地址:GitHub - arc53/DocsGPT: GPT-powered chat for documentation, chat with your documents
项目支持自己导入需要模型学习的文档,并且基于文档向AI提问,AI能够比较精准的找到对应的答案,实现的效果大概如下:

如果Github访问不了也可以到Gitee里面去搜一下。
部署准备:
1、一台centos服务器,用windows Hyper创建centos虚拟机也可以,官方说的模型对机器要求如下:

但实际测试下来普通的笔记本,使用CPU也能流畅运行,我使用的。
2、安装Docker和Docker-Compose
官方提供了基于Docker-Compose的一键部署脚本,需要提前装好以上两个工具
Docker安装参考CentOS Docker 安装 | 菜鸟教程
Docker-Compose安装参考Docker Compose | 菜鸟教程
3、安装python
建议使用conda安装python3.9以上版本,我用的3.11
conda安装教程centos 安装 Miniconda_centos 安装miniconda-CSDN博客
conda安装python3.11anaconda安装python 3.11_anaconda配置python3.11-CSDN博客,执行conda create -n gpt11 python=3.11 -c conda-forgem命令即可完成安装
安装完成后使用conda activate gpt11命令激活
安装完后确认版本,输入python --version和pip --version,如果输出对应版本即安装完成
4、下载DocsGPT项目代码
从github下载最新的release版本,Releases · arc53/DocsGPT · GitHub
当前我能下载到的最新版本是0.9.0,直接下载zip文件即可,并将其上传到centos的某个目录进行解压,我是直接放到了home目录下

5、下载DocsGPT的模型文件
模型包括了LLM语言模型和EMBEDDING模型,工作原理大致是通过将文档中的内容提取后使用EMBEDDING模型实现向量化并存储,当用户对文档进行提问时,将用户提问内容也进行EMBEDDING并到文档向量化模型中进行匹配,最后将匹配内容通过LLM语言模型转换成回答的内容发送给用户。
官方默认的LLM语言模型是docsgpt-7b-f16.gguf,EMBEDDING模型是all-mpnet-base-v2
LLM模型官方提供的下载地址可以直接下载,而且执行脚本时会自动下载,如果下载速度慢可以迅雷下载后再手动上传到服务器,存放目录是项目代码根目录下的models文件夹(比如我的是/home/DocsGPT-0.9.0/models)
docsgpt-7b-f16.gguf模型的下载地址:https://d3dg1063dc54p9.cloudfront.net/models/docsgpt-7b-f16.gguf
EMBEDDING模型无法下载,但是可以通过HF-Mirror - Huggingface 镜像站网站搜索并下载
all-mpnet-base-v2下载地址:sentence-transformers/all-mpnet-base-v2 at main,全部下载后存放到项目代码根目录下的sentence-transformers/all-mpnet-base-v2下,我的是路径/home/DocsGPT-0.9.0/sentence-transformers/all-mpnet-base-v2
全部下载完后整体的项目目录包含以下内容

前端是使用vite构建的,后台服务API默认是http://localhost:7091:,需要在docker-compose.yaml和docker-compose-local.yaml两个文件中修改一下前端项目调用的后台服务API,我的虚拟机IP是172.23.139.136,因此只要将这两个文件中的VITE_API_HOST参数localhost设置为虚拟机IP即可:

docker-compose.yaml和docker-compose-local.yaml两个文件都需要修改
6、项目一键部署
通过putty或者Xshell等工具登陆centos服务器,然后进入项目代码根目录,执行cd /home/DocsGPT-0.9.0进入/home/DocsGPT-0.9.0目录
项目可以通过根目录下的setup.sh脚本执行一键部署,执行前需要使用chmod +x setup.sh命令给脚本设置权限
脚本中需要使用pip安装较多的python以赖库,可以在pip install后面配置国内源地址,提高下载速度,通过执行vi setup.sh命令打开shell脚本,找到pip install的几个指令,在后面加-i https://pypi.tuna.tsinghua.edu.cn/simple指定下载源地址:

保存之后输入./setup.sh命令进行一键部署,执行命令后会有一个选择项:

选项1对应使用DocsGPT提供的免费API,选项2对应使用本地化模型,选项3对应使用OpenAI提供的接口(需要有APIkey),由于需要完全本地化部署,所以我选的2,接下来脚本会执行一系列的安装操作,安装过程预计要20-30分钟。
过程中报了一个错误: ERROR: Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based projects,是指在安装llama-cpp-python的过程中缺少pyproject.toml-based projects,可以参考Centos7 安装llama-cpp-python失败_pip llama-cpp-python错误-CSDN博客进行解决,但因为项目已经启动,需要按CTRL + C先退出,再运行pkill -f 'flask run'命令关闭flask项目,再按上述文档的建议依次执行以下命令:
yum remove gcc
yum remove gdb
yum install scl-utils
yum install centos-release-scl
yum list all --enablerepo='centos-sclo-rh' | grep "devtoolset"
yum install -y devtoolset-11-toolchain
vi ~/.bash_profile
PATH=$PATH:/opt/rh/devtoolset-11/root/usr/bin
source ~/.bash_profile
scl enable devtoolset-11 bash
gcc --version
成功后,重新执行./setup.sh命令
启动成功:
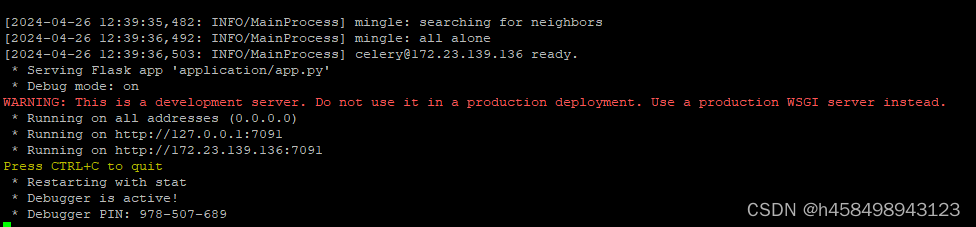
因为后台服务地址是由flask启动,需要手动通过防火墙把7091端口进行开放
启动一个新的putty或者Xshell工具连接centos服务器(建议),或者CTRL + C先退出,再运行pkill -f 'flask run'命令关闭flask项目后,执行以下命令来开启7091
firewall-cmd --add-port=7091/tcp --permanent
firewall-cmd --reload
如果是退出项目后再开端口的话,需要重新执行./setup.sh命令启动项目
7、项目访问
前端的默认端口是5173,通过虚拟机IP加端口即可访问前端项目,出现以下界面即说明部署成功:
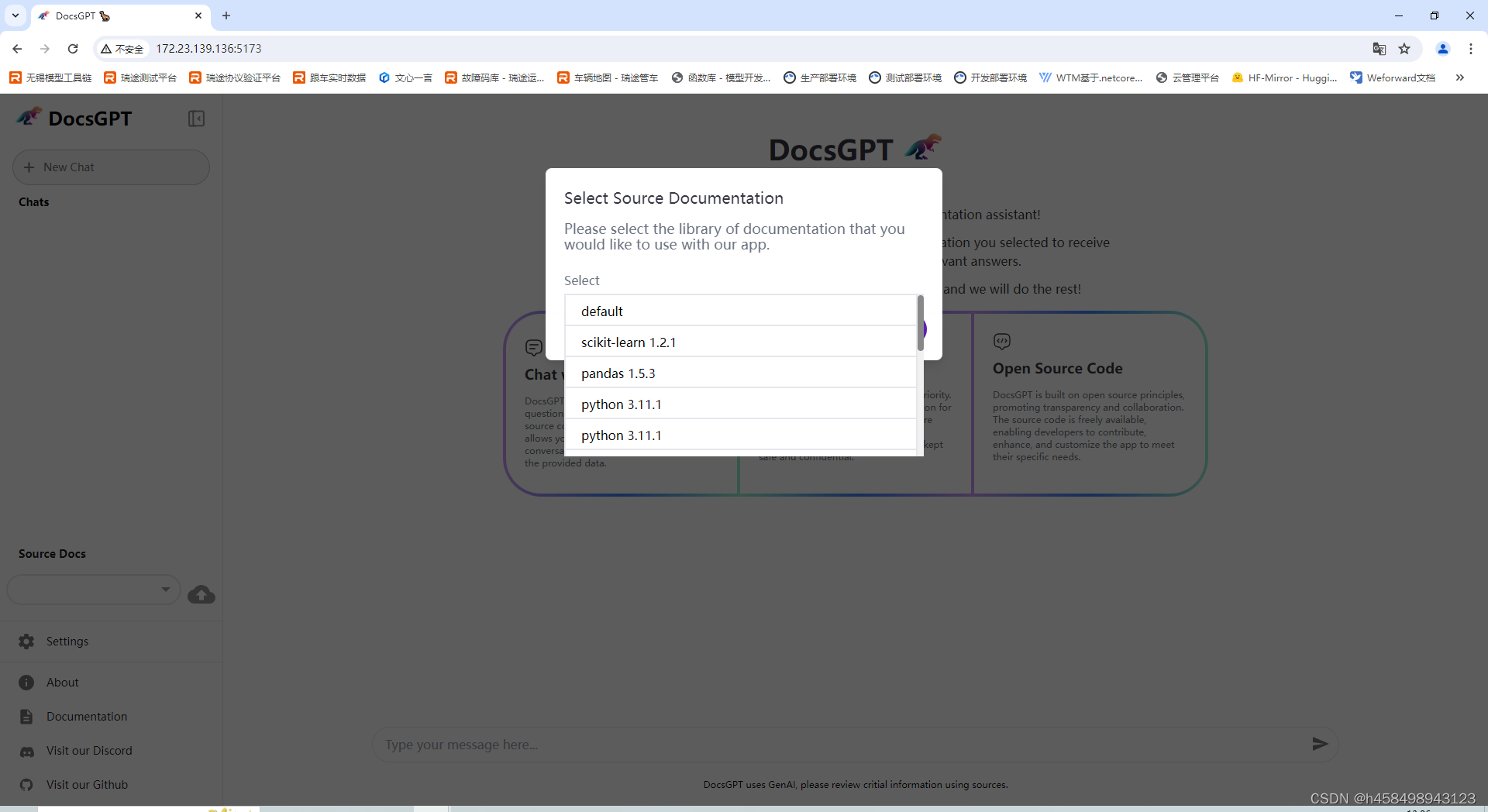
选择default文档后就可以和DocsGPT进行对话了,但是对话时发现报了一个错误:
Can't load tokenizer for 'gpt2',分析源代码发现在application下面有个utils.py文件调用了gpt2来统计历史对话已经使用的token数量,可能是因为无法访问gpt2导致的:

我们反正也不需要对token数量做限制,退出项目后找到文件做如下修改,直接屏蔽后return 0即可:

重新执行./setup.sh命令启动项目即可,页面左侧有文档上传功能,上传文档不能有中文名成,否则会报错。
8、更换模型
如果对官方提供的模型效果不满意,可以挑选其他的模型进行替换,需要将模型转成gguf格式,并上传到根目录下的models文件夹下,再进入application/core/settings.py文件中将MODEL_PATH: str = os.path.join(current_dir, "models/docsgpt-7b-f16.gguf")的"docsgpt-7b-f16.gguf"模型文件名替换为新的文件名,重启项目即可。
版权归原作者 h458498943123 所有, 如有侵权,请联系我们删除。