

🦐博客主页:大虾好吃吗的博客 🦐MySQL专栏:MySQL专栏地址
接着第一章继续操作,部署好MHA环境后,vip配置可以采用两种方式,一种通过keepalived的方式管理虚拟ip的浮动;另外一种通过脚本方式启动虚拟ip的方式(即不需要keepalived或者heartbeat类似的软件)。
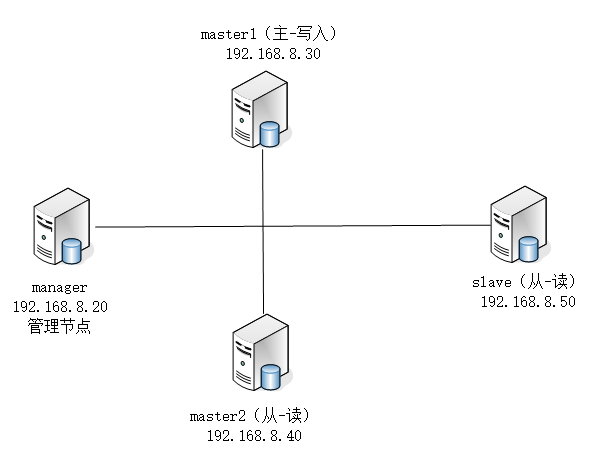
通过keepalived方式
keepalived方式管理虚拟ip,keepalived配置方法如下: 下载软件进行并进行安装(两台master,准确的说一台是master,另外一台是备选master,在没有切换以前是slave) 在master1和master2上安装软件包keepalived。
安装keepalived
在编译安装Keepalived之前,必须先安装内核开发包kernel-devel以及openssl-devel、popt-devel等支持库。
[root@master1 ~]# yum install kernel-devel popt-devel openssl-devel -y
若没有安装则通过rpm或yum工具进行安装 编译安装Keepalived 使用指定的linux内核位置对keepalived进行配置,并将安装路径指定为根目录,这样就无需额外创建链接文件了,配置完成后,依次执行make、make install进行安装。
使用keepalived服务 执行make install操作之后,会自动生成/etc/init.d/keepalived脚本文件,但还需要手动添加为系统服务,这样就可以使用service、chkconfig工具来对keepalived服务程序进行管理了。
[root@master1 ~]# yum -y install kernel-devel openssl-devel popt-devel
[root@master1 ~]# tar zxf keepalived-2.2.7.tar.gz
[root@master1 ~]# cd keepalived-2.2.7/
[root@master1 keepalived-2.2.7]# ./configure --prefix=/ && make && make install
master2主机也完成keepalived安装,与master1一样,安装过程略 注:若开启了防火墙,需要关闭防火墙或创建规则。
防火墙策略
firewall-cmd --direct --permanent --add-rule ipv4 filter OUTPUT 0 --in-interface ens33 --destination 224.0.0.18 --protocol vrrp -j ACCEPT
firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 --in-interface ens33 --destination 224.0.0.18 --protocol vrrp -j ACCEPT
firewall-cmd --reload
keep配置文件
修改Keepalived的配置文件(在master1上配置)
[root@master1 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb1
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 100
nopreempt
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.8.100
}
}
在master2上配置(192.168.8.30)
[root@master2 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 50
nopreempt
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.8.100
}
}
启动keepalived服务,在master上启动并查看日志
[root@master1 ~]# systemctl start keepalived
[root@master1 ~]# systemctl enable keepalived
[root@master1 ~]# ps -ef | grep keep
gdm 1998 1864 0 15:36 ? 00:00:00 /usr/libexec/gsd-housekeeping
root 120505 1 0 20:24 ? 00:00:00 //sbin/keepalived --dont-fork -D
root 120506 120505 0 20:24 ? 00:00:00 //sbin/keepalived --dont-fork -D
root 120536 101111 0 20:25 pts/0 00:00:00 grep --color=auto keep
[root@master1 ~]# ip a show dev ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:f8:c9:27 brd ff:ff:ff:ff:ff:ff
inet 192.168.8.30/24 brd 192.168.8.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.8.100/32 scope global ens33
valid_lft forever preferred_lft forever
[root@master1 ~]# tail -f /var/log/messages
发现已经将虚拟ip 192.168.8.100绑定了网卡ens33上
查看eth33网卡是否绑定了VIP
在另外一台服务器,候选master上启动keepalived服务,并观察
[root@master2 ~]# tail -f /var/log/messages
从上面的信息可以看到keepalived已经配置成功
注意: 上面两台服务器的keepalived都设置为了BACKUP模式,在keepalived中2种模式,分别是master----backup模式和backup----backup模式。这两种模式有很大区别。在master->backup模式下,一旦主库宕机,虚拟ip会自动漂移到从库,当主库修复后,keepalived启动后,还会把虚拟ip抢占过来,即使设置了非抢占模式(nopreempt)抢占ip的动作也会发生。在backup->backup模式下,当主库宕机后虚拟ip会自动漂移到从库上,当原主库恢复和keepalived服务启动后,并不会抢占新主的虚拟ip,即使是优先级高于从库的优先级别,也不会发生抢占。为了减少ip漂移次数,通常是把修复好的主库当做新的备库。
MHA应用keepalived
(MySQL服务进程挂掉时通过MHA 停止keepalived): 要想把keepalived服务引入MHA,我们只需要修改切换时触发的脚本文件master_ip_failover即可,在该脚本中添加在master发生宕机时对keepalived的处理。 编辑脚本/scripts/master_ip_failover,修改后如下。
推荐使用下面的脚本,原始脚本有些未知的问题,而下面的脚本只需要修改"$vip"、"$ssh_start_vip"、"$ssh_stop_vip",第一种方式重点修改IP,其他的不用修改,但是需要注意的是,脚本不要忘记给执行权限,否则不会执行。
[root@manager ~]# vim /scripts/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command,$ssh_user,$orig_master_host,$orig_master_ip,$orig_master_port, $new_master_host,$new_master_ip,$new_master_port
);
my $vip = '192.168.8.100';
my $ssh_start_vip = "systemctl start keepalived";
my $ssh_stop_vip = "systemctl stop keepalived";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
#`ssh $ssh_user\@cluster1 \" $ssh_start_vip \"`;
exit 0;
}
else {
&usage();
exit 1;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
[root@manager ~]# chmod +x /scripts/master_ip_failover
现在已经修改这个脚本了,接下来我们在/etc/masterha/app1.cnf 中调用故障切换脚本
停止MHA
[root@manager ~]# masterha_stop --conf=/etc/masterha/app1.cnf
Stopped app1 successfully.
在配置文件/etc/masterha/app1.cnf 中启用下面的参数(在[server default下面添加])
[root@manager ~]# vim /etc/masterha/app1.cnf
master_ip_failover_script=/scripts/master_ip_failover
启动MHA
[root@manager ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/tmp/mha_manager.log &
[1] 107918
检查状态
[root@manager ~]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:107918) is running(0:PING_OK), master:192.168.8.40
再检查集群状态,查看是否会报错。
[root@manager ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
#省略部分内容
Checking the Status of the script.. OK
Thu Apr 6 20:40:15 2023 - [info] OK.
Thu Apr 6 20:40:15 2023 - [warning] shutdown_script is not defined.
Thu Apr 6 20:40:15 2023 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
可以看见已经没有报错了。 /scripts/master_ip_failover添加或者修改的内容意思是当主库数据库发生故障时,会触发MHA切换,MHA Manager会停掉主库上的keepalived服务,触发虚拟ip漂移到备选从库,从而完成切换。 当然可以在keepalived里面引入脚本,这个脚本监控mysql是否正常运行,如果不正常,则调用该脚本杀掉keepalived进程。
测试
先在master2(主)上停止mysqld服务
[root@master2 ~]# systemctl stop mysqld
到slave(192.168.8.50)查看slave的状态,可以看到主已经回到8.30上。
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.8.30
Master_User: mharep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000006
Read_Master_Log_Pos: 154
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000006
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#省略部分内容
查看VIP绑定:
在master1上查看vip绑定
[root@master1 ~]# ip a show dev ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:f8:c9:27 brd ff:ff:ff:ff:ff:ff
inet 192.168.8.30/24 brd 192.168.8.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.8.100/32 scope global ens33
valid_lft forever preferred_lft forever
在master2上查看vip绑定
[root@master2 ~]# ip a show dev ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:92:14:66 brd ff:ff:ff:ff:ff:ff
inet 192.168.8.40/24 brd 192.168.8.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
从上面的显示结果可以看出vip地址漂移到了192.168.8.30 主从切换后续工作
重构: 重构就是你的主挂了,切换到master2上,master2变成了主,因此重构的一种方案原主库修复成一个新的slave 主库切换后,把原主库修复成新从库,原主库数据文件完整的情况下。
先查看主的二进制日志
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000006 | 154 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
将master2(原主库)修复成从库
[root@master2 ~]# systemctl start mysqld
[root@master2 ~]# mysql -uroot -p123
#省略登录信息
mysql> change master to
-> master_host='192.168.8.30',
-> master_port=3306,
-> master_user='mharep',
-> master_password='123',
-> master_log_file='mysql-bin.000006',
-> master_log_pos=154;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.8.30
Master_User: mharep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000006
Read_Master_Log_Pos: 154
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000006
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#省略部分内容
通过脚本实现VIP切换
通过脚本的方式管理VIP。这里是修改/scripts/master_ip_failover,也可以使用其他的语言完成,比如php语言。使用php脚本编写的failover这里就不介绍了。修 改完成后内容如下,而且如果使用脚本管理vip的话,需要手动在master服务器上绑定一个vip
网卡环境配置
把两台主机的keepalived服务停止,给master1(主)一个虚拟IP。
[root@master1 ~]# ifconfig ens33:0 192.168.8.100/24
[root@master1 ~]# systemctl stop keepalived
master2也关闭keepalived服务
[root@master2 ~]# systemctl stop keepalived
MHA应用脚本
manager主机上修改/scripts/ master_ip_failover,内容如下
[root@manager ~]# vim /scripts/master_ip_failover
#省略部分内容
#重点修改下面四行内容
my $vip = '192.168.8.100';
my $key = '0';
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key $vip down";
#省略部分内容
删掉下面文件,否则会报错app1.failover.complete、app1.failover.error
[root@manager ~]# ll /masterha/app1/
总用量 128
-rw-r--r-- 1 root root 0 4月 6 20:43 app1.failover.complete
-rw-r--r-- 1 root root 96771 4月 6 21:23 manager.log
[root@manager ~]# rm -rf /masterha/app1/app1.failover.complete
停止MHA
[root@manager ~]# masterha_stop --conf=/etc/masterha/app1.cnf
启动MHA
[root@manager ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/tmp/mha_manager.log &
[1] 108654
检查状态
[root@manager ~]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:108654) is running(0:PING_OK), master:192.168.8.30
再检查集群状态,看是否会报错。
[root@manager ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
#省略部分内容
IN SCRIPT TEST====/sbin/ifconfig ens33:0 192.168.8.100 down==/sbin/ifconfig ens33:0 192.168.8.100===
Checking the Status of the script.. OK
Thu Apr 6 21:18:49 2023 - [info] OK.
Thu Apr 6 21:18:49 2023 - [warning] shutdown_script is not defined.
Thu Apr 6 21:18:49 2023 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
测试
在master1上停掉mysql服务
[root@master1 ~]# systemctl stop mysqld
到slave(192.168.8.50)查看slave的状态:
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.8.40
Master_User: mharep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000008
Read_Master_Log_Pos: 154
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000008
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#省略部分内容
从上面可以看出slave指向了新的master服务器(192.168.40)
master1查看VIP
[root@master1 ~]# ip a show dev ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:f8:c9:27 brd ff:ff:ff:ff:ff:ff
inet 192.168.8.30/24 brd 192.168.8.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
从上面可以看到master2(原来的master)释放了VIP,master1(新的master)接管了VIP地址 主从切换后续工作 主库切换后,把原主库修复成新从库,相关操作请参考前面相关操作。 为了防止脑裂发生,推荐生产环境采用脚本的方式来管理虚拟ip,而不是使用keepalived来完成。到此为止,基本MHA集群已经配置完毕。
总结: MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下。
Manager工具包主要包括以下几个工具:
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的server信息
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具: save_binary_logs 保存和复制master的二进制日志 apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
mysql必备技能掌握:
1、MySQL架构:对mysql的架构,整体有个印象,才能不断的加深对mysql的理解和后继的学习。
2、用各种姿势备份MySQL数据库 数据备份是DBA或运维工程师日常工作之一,如果让你来备份,你会用什么方式备份,在时间时间备份,使用什么策略备份 。
3、mysql主从复制及读写分离 mysql的主从复制及读写分离是DBA必备技能之一 。
4、MySQL/MariaDB数据库基于SSL实现主从复制 加强主从复制的安全性
5、MySQL高可用 数据的高可用如何保证 。
6、数据库Sharding的基本思想和切分策略 随着数据量的不断攀升,从性能和可维护的角度,需要进行一些Sharding,也就是数据库的切分,有垂直切分和水平切分 。
7、MySQL/MariaDB 性能调整和优化技巧 掌握优化思路和技巧,对数据库的不断优化是一项长期工程。

版权归原作者 大虾好吃吗 所有, 如有侵权,请联系我们删除。