
1. 在上节数据流上执行转换操作,或者使用 sink 将数据写入外部系统。
本教程使用 FileSink 将结果数据写入文件中。
def split(line):
yield from line.split()
# compute word count
ds = ds.flat_map(split) \
.map(lambda i: (i, 1), output_type=Types.TUPLE([Types.STRING(), Types.INT()])) \
.key_by(lambda i: i[0]) \
.reduce(lambda i, j: (i[0], i[1] + j[1]))
ds.sink_to(
sink=FileSink.for_row_format(
base_path=output_path,
encoder=Encoder.simple_string_encoder())
.with_output_file_config(
OutputFileConfig.builder()
.with_part_prefix("prefix")
.with_part_suffix(".ext")
.build())
.with_rolling_policy(RollingPolicy.default_rolling_policy())
.build()
)
sink_to函数,将DataStream数据发送到自定义sink connector,仅支持FileSink,可用于batch和streaming执行模式。
2. File Sink
Streaming File Sink是Flink1.7中推出的新特性,是为了解决如下的问题:
大数据业务场景中,经常有一种场景:外部数据发送到kafka中,flink作为中间件消费kafka数据并进行业务处理;处理完成之后的数据可能还需要写入到数据库或者文件系统中,比如写入hdfs中。
Streaming File Sink就可以用来将分区文件写入到支持 Flink FileSystem 接口的文件系统中,支持Exactly-Once语义。这种sink实现的Exactly-Once都是基于Flink checkpoint来实现的两阶段提交模式来保证的,主要应用在实时数仓、topic拆分、基于小时分析处理等场景下。
Streaming File Sink 是社区优化后添加的connector,推荐使用。
Streaming File Sink更灵活,功能更强大,可以自己实现序列化方法
Streaming File Sink有两个方法可以输出到文件:行编码格式forRowFormat 和 块编码格式forBulkFormat。
forRowFormat 比较简单,只提供了SimpleStringEncoder写文本文件,可以指定编码。
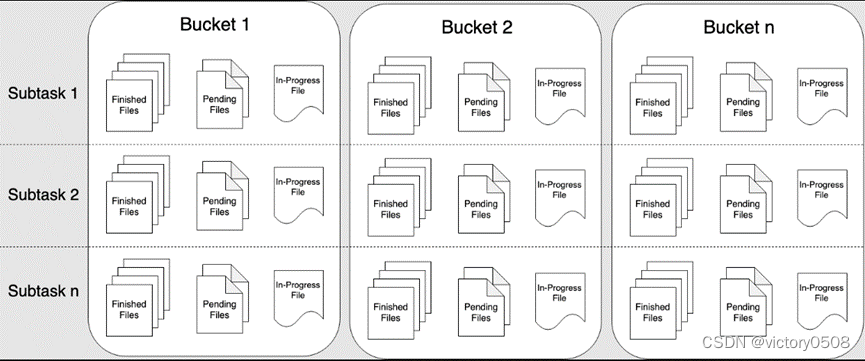
由于流数据本身是无界的,所以,流数据将数据写入到分桶(bucket)中。默认使用基于系统时间(yyyy-MM-dd--HH)的分桶策略。在分桶中,又根据滚动策略,将输出拆分为 part 文件。
Flink 提供了两个分桶策略,分桶策略实现了
org.apache.flink.streaming.api.functions.sink.filesystem.BucketAssigner 接口:
BasePathBucketAssigner,不分桶,所有文件写到根目录;
DateTimeBucketAssigner,基于系统时间(yyyy-MM-dd--HH)分桶。
除此之外,还可以实现BucketAssigner接口,自定义分桶策略。
Flink 提供了两个滚动策略,滚动策略实现了
org.apache.flink.streaming.api.functions.sink.filesystem.RollingPolicy 接口:
DefaultRollingPolicy 当超过最大桶大小(默认为 128 MB),或超过了滚动周期(默认为 60 秒),或未写入数据处于不活跃状态超时(默认为 60 秒)的时候,滚动文件;
OnCheckpointRollingPolicy 当 checkpoint 的时候,滚动文件。
File Sink
File Sink 将传入的数据写入存储桶中。考虑到输入流可以是无界的,每个桶中的数据被组织成有限大小的 Part 文件。完全可以配置为基于时间的方式往桶中写入数据,比如可以设置每个小时的数据写入一个新桶中。这意味着桶中将包含一个小时间隔内接收到的记录。
桶目录中的数据被拆分成多个 Part 文件。对于相应的接收数据的桶的 Sink 的每个 Subtask,每个桶将至少包含一个 Part 文件。将根据配置的滚动策略来创建其他 Part 文件。对于
Row-encoded Formats
默认的策略是根据 Part 文件大小进行滚动,需要指定文件打开状态最长时间的超时以及文件关闭后的非活动状态的超时时间。对于
Bulk-encoded Formats
在每次创建 Checkpoint 时进行滚动,并且用户也可以添加基于大小或者时间等的其他条件。
重要: 在
STREAMING
模式下使用
FileSink
需要开启 Checkpoint 功能。文件只在 Checkpoint 成功时生成。如果没有开启 Checkpoint 功能,文件将永远停留在
in-progress
或者
pending
的状态,并且下游系统将不能安全读取该文件数据。
**Format Types **
FileSink
不仅支持 Row-encoded 也支持 Bulk-encoded,例如 Apache Parquet。这两种格式可以通过如下的静态方法进行构造:
- Row-encoded sink:
FileSink.forRowFormat(basePath, rowEncoder) - Bulk-encoded sink:
FileSink.forBulkFormat(basePath, bulkWriterFactory)
不论创建 Row-encoded Format 或者 Bulk-encoded Format 的 Sink 时,都必须指定桶的路径以及对数据进行编码的逻辑。
**Row-encoded Formats **
Row-encoded Format 需要指定一个
Encoder
,在输出数据到文件过程中被用来将单个行数据序列化为
Outputstream
。
除了 bucket assigner,RowFormatBuilder 还允许用户指定以下属性:
- Custom RollingPolicy :自定义滚动策略覆盖 DefaultRollingPolicy
- bucketCheckInterval (默认值 = 1 min) :基于滚动策略设置的检查时间间隔
data_stream = ...
sink = FileSink \
.for_row_format(OUTPUT_PATH, Encoder.simple_string_encoder("UTF-8")) \
.with_rolling_policy(RollingPolicy.default_rolling_policy(
part_size=1024 ** 3, rollover_interval=15 * 60 * 1000, inactivity_interval=5 * 60 * 1000)) \
.build()
data_stream.sink_to(sink)
这个例子中创建了一个简单的 Sink,默认的将记录分配给小时桶。例子中还指定了滚动策略,当满足以下三个条件的任何一个时都会将 In-progress 状态文件进行滚动:
- 包含了至少15分钟的数据量
- 从没接收延时5分钟之外的新纪录
- 文件大小已经达到 1GB(写入最后一条记录之后)
**Bulk-encoded Formats **
Bulk-encoded 的 Sink 的创建和 Row-encoded 的相似,但不需要指定
Encoder
,而是需要指定
BulkWriter.Factory
。
BulkWriter
定义了如何添加和刷新新数据以及如何最终确定一批记录使用哪种编码字符集的逻辑。
Flink 内置了5种 BulkWriter 工厂类:
- ParquetWriterFactory
- AvroWriterFactory
- SequenceFileWriterFactory
- CompressWriterFactory
- OrcBulkWriterFactory
重要 Bulk-encoded Format 仅支持一种继承了
CheckpointRollingPolicy
类的滚动策略。在每个 Checkpoint 都会滚动。另外也可以根据大小或处理时间进行滚动。
桶分配
桶的逻辑定义了如何将数据分配到基本输出目录内的子目录中。
Row-encoded Format 和 Bulk-encoded Format使用了
DateTimeBucketAssigner
作为默认的分配器。默认的分配器
DateTimeBucketAssigner
会基于使用了格式为
yyyy-MM-dd--HH
的系统默认时区来创建小时桶。日期格式( 即 桶大小)和时区都可以手动配置。
还可以在格式化构造器中通过调用
.withBucketAssigner(assigner)
方法指定自定义的
BucketAssigner
。
Flink 内置了两种 BucketAssigners:
DateTimeBucketAssigner:默认的基于时间的分配器BasePathBucketAssigner:分配所有文件存储在基础路径上(单个全局桶)
PyFlink 只支持
DateTimeBucketAssigner
和
BasePathBucketAssigner
。
滚动策略
RollingPolicy
定义了何时关闭给定的 In-progress Part 文件,并将其转换为 Pending 状态,然后在转换为 Finished 状态。 Finished 状态的文件,可供查看并且可以保证数据的有效性,在出现故障时不会恢复。在
STREAMING
模式下,滚动策略结合 Checkpoint 间隔(到下一个 Checkpoint 成功时,文件的 Pending 状态才转换为 Finished 状态)共同控制 Part 文件对下游 readers 是否可见以及这些文件的大小和数量。在
BATCH
模式下,Part 文件在 Job 最后对下游才变得可见,滚动策略只控制最大的 Part 文件大小。
Flink 内置了两种 RollingPolicies:
DefaultRollingPolicyOnCheckpointRollingPolicy
PyFlink 只支持
DefaultRollingPolicy
和
OnCheckpointRollingPolicy
。
3. 如何输出结果
ds**.print()**
Collect results to client
集合数据到客户端,execute_and_collect方法将收集数据到客户端内存
with ds**.execute_and_collect()as results:**
**for** result **in** results**:**
**print****(**result**)**
将结果发送到DataStream sink connector
add_sink函数,将DataStream数据发送到sink connector,此函数仅支持FlinkKafkaProducer, JdbcSink和StreamingFileSink,仅在streaming执行模式下使用
from pyflink.common.typeinfo import Types
from pyflink.datastream.connectors import FlinkKafkaProducer
from pyflink.common.serialization import JsonRowSerializationSchema
serialization_schema = JsonRowSerializationSchema.builder().with_type_info(
type_info=Types.ROW([Types.INT(), Types.STRING()])).build()
kafka_producer = FlinkKafkaProducer(
topic='test_sink_topic',
serialization_schema=serialization_schema,
producer_config={'bootstrap.servers': 'localhost:9092', 'group.id': 'test_group'})
ds.add_sink(kafka_producer)
sink_to函数,将DataStream数据发送到自定义sink connector,仅支持FileSink,可用于batch和streaming执行模式
from pyflink.datastream.connectors import FileSink, OutputFileConfig
from pyflink.common.serialization import Encoder
output_path = '/opt/output/'
file_sink = FileSink \
.for_row_format(output_path, Encoder.simple_string_encoder()) \ .with_output_file_config(OutputFileConfig.builder().with_part_prefix('pre').with_part_suffix('suf').build()) \
.build()
ds.sink_to(file_sink)
将结果发送到Table & SQL sink connector
Table & SQL connectors也被用于写入DataStream. 首先将DataStream转为Table,然后写入到 Table & SQL sink connector.
from pyflink.common import Row
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(stream_execution_environment=env)
# option 1:the result type of ds is Types.ROW
def split(s):
splits = s[1].split("|")
for sp in splits:
yield Row(s[0], sp)
ds = ds.map(lambda i: (i[0] + 1, i[1])) \
.flat_map(split, Types.ROW([Types.INT(), Types.STRING()])) \
.key_by(lambda i: i[1]) \
.reduce(lambda i, j: Row(i[0] + j[0], i[1]))
# option 1:the result type of ds is Types.TUPLE
def split(s):
splits = s[1].split("|")
for sp in splits:
yield s[0], sp
ds = ds.map(lambda i: (i[0] + 1, i[1])) \
.flat_map(split, Types.TUPLE([Types.INT(), Types.STRING()])) \
.key_by(lambda i: i[1]) \
.reduce(lambda i, j: (i[0] + j[0], i[1]))
# emit ds to print sink
t_env.execute_sql("""
CREATE TABLE my_sink (
a INT,
b VARCHAR
) WITH (
'connector' = 'print'
)
""")
table = t_env.from_data_stream(ds)
table_result = table.execute_insert("my_sink")
4. 执行 PyFlink DataStream API 作业。
PyFlink applications 是懒加载的,并且只有在完全构建之后才会提交给集群上执行。
要执行一个应用程序,你只需简单地调用 env.execute()。
env**.execute()**
版权归原作者 victory0508 所有, 如有侵权,请联系我们删除。