
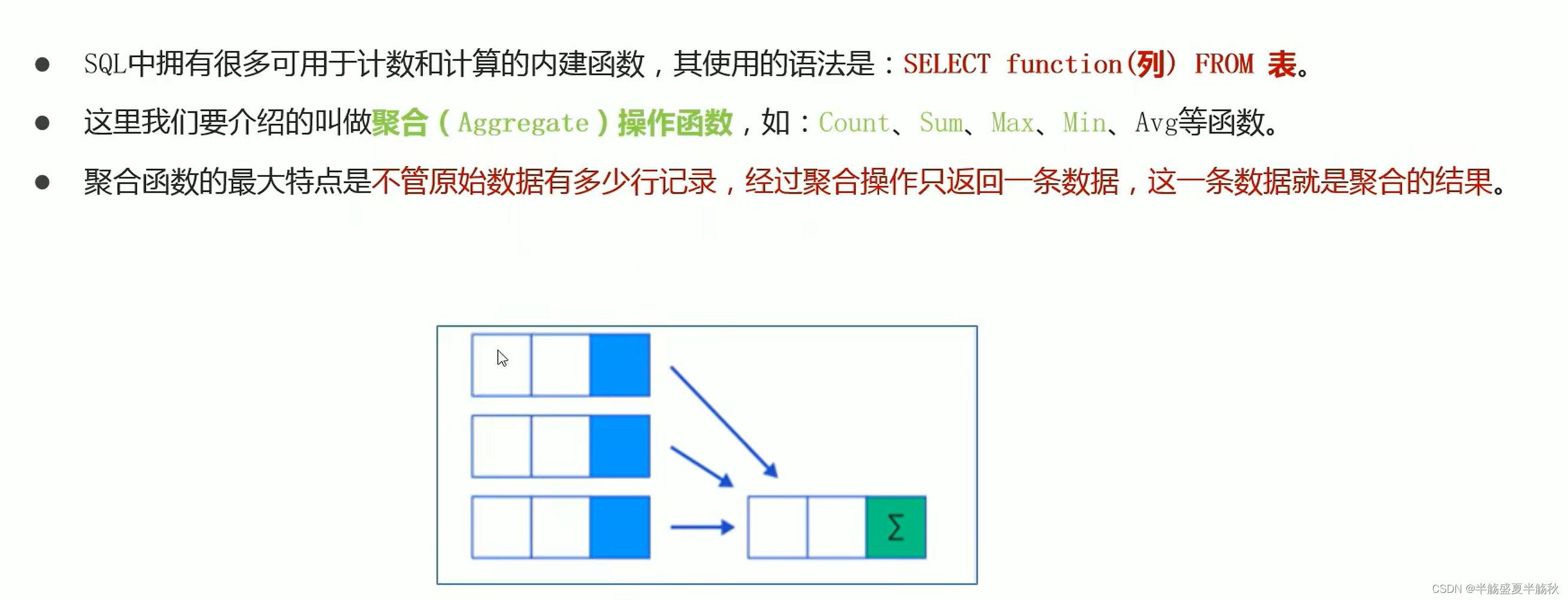
1.聚合函数
- 常见的聚合函数:Count、Sum、Max、Min和Avg
- 特点:不管原始数据多少条,聚合之后只有一条
- Count(column)返回某列的行数,不包括NULL值
2.GROUP BY

- select中的字段要么是GROUP BY字段,要么是被聚合函数应用的字段
2.HAVING
- WHERE中无法出现聚合函数,所以有了HAVING
- WHERE是分组前过滤,HAVING是分组后过滤
为什么WHERE中不能使用聚合函数?
- 因为使用WHERE的时候,只能从表格字段中直接查找然后过滤,如果用到计算函数,不是表格现有的直接可以查到的,就不可以作为过滤条件,对于表格现有的 length() 等函数还是可以的
- 而且因为WHERE的执行顺序在GROUP BY之前,而聚合函数只有在GROUP BY之后才能进行,因此WHERE中不能有聚合函数

使用having时一定要注意和select中的某个聚合函数一样,且可以使用其别名。虽然having在select之前,但是就是可以,这样SQL的性能更好,不用执行两遍聚合函数了
3.ORDER BY
- 默认按照升序(ASC),降序使用DESC
select*from t orderby name desc, age asc;--先根据name降序,再根据age升序
4.LIMIT
- 用于限制SELECT语句返回的行数
- 接收一个或者两个参数,都是非负整数
- 第一个参数指定要返回的第一行的偏移量,第二个参数指定要返回的最大行数。单个参数时,偏移量默认为0。
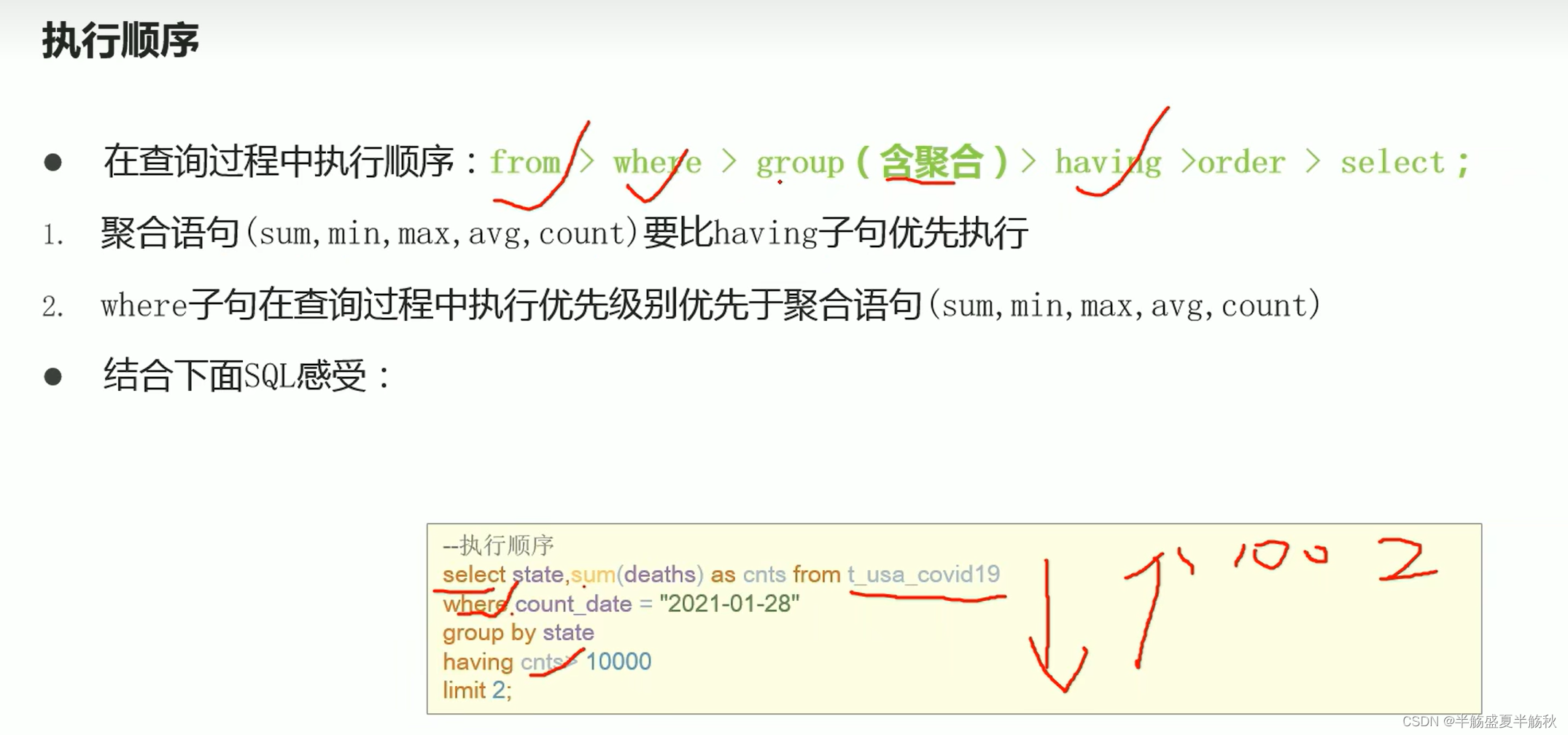
5.执行顺序
6.Join

内连接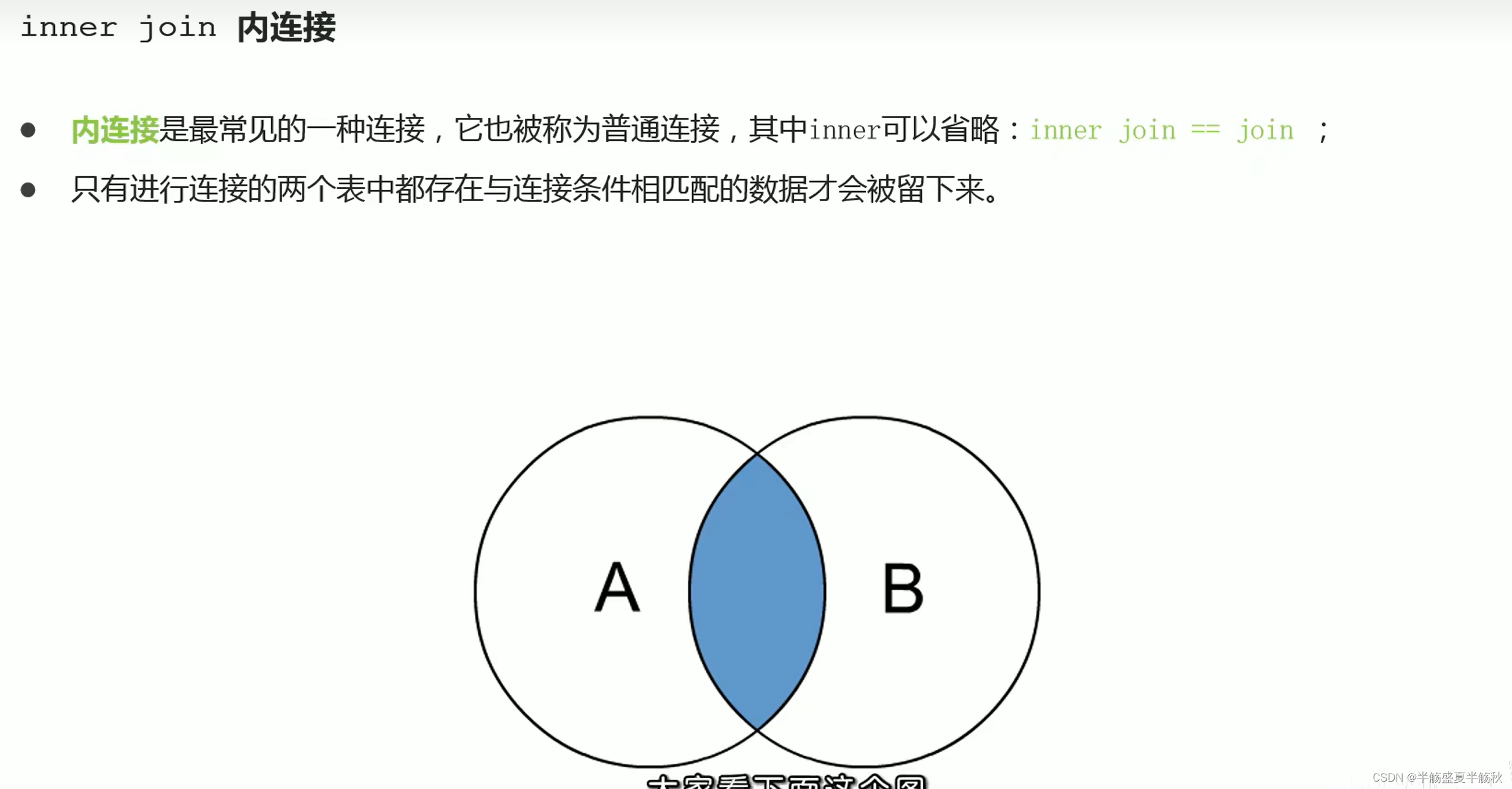
左连接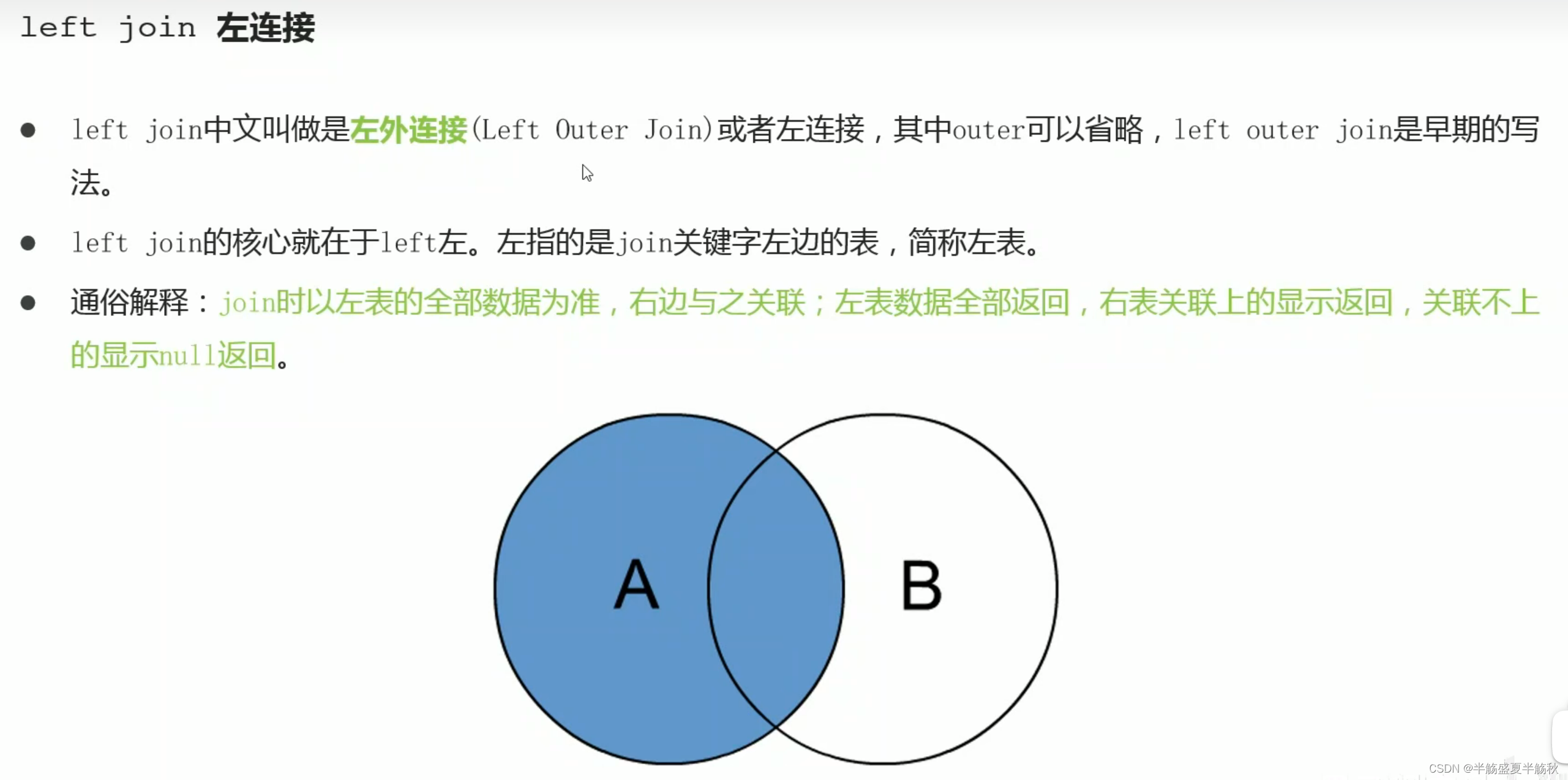
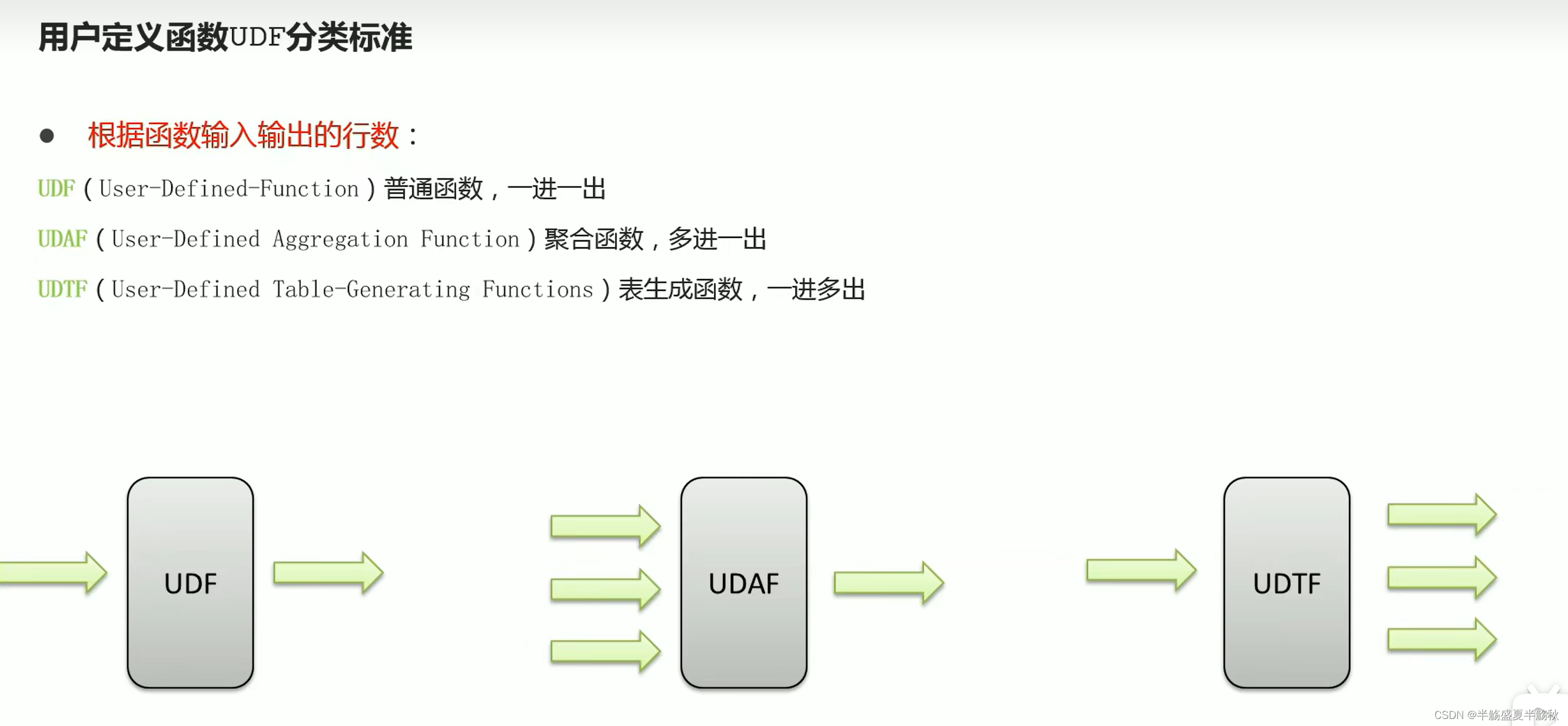
7.函数分类(UDF,UDAF,UDTF)
show functions;//查看当下可用的所有函数describefunctionextended funcname;//查看funcname的使用

8.常用内置函数
------------String Functions 字符串函数------------select length("itcast");select reverse("itcast");select concat("angela","baby");--带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)select concat_ws('.','www', array('itcast','cn'));--字符串截取函数:substr(str, pos[, len]) 或者 substring(str, pos[, len])select substr("angelababy",-2);--pos是从1开始的索引,如果为负数则倒着数select substr("angelababy",2,2);--分割字符串函数: split(str, regex)--split针对字符串数据进行切割 返回是数组array 可以通过数组的下标取内部的元素 注意下标从0开始的select split('apache hive',' ');select split('apache hive',' ')[0];select split('apache hive',' ')[1];----------- Date Functions 日期函数 -------------------获取当前日期: current_dateselectcurrent_date();--获取当前UNIX时间戳函数: unix_timestampselect unix_timestamp();--日期转UNIX时间戳函数: unix_timestampselect unix_timestamp("2011-12-07 13:01:03");--指定格式日期转UNIX时间戳函数: unix_timestampselect unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss');--UNIX时间戳转日期函数: from_unixtimeselect from_unixtime(1618238391);select from_unixtime(0,'yyyy-MM-dd HH:mm:ss');--日期比较函数: datediff 日期格式要求'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'select datediff('2012-12-08','2012-05-09');--日期增加函数: date_addselect date_add('2012-02-28',10);--日期减少函数: date_subselect date_sub('2012-01-1',10);----Mathematical Functions 数学函数---------------取整函数: round 返回double类型的整数值部分 (遵循四舍五入)selectround(3.1415926);--指定精度取整函数: round(double a, int d) 返回指定精度d的double类型selectround(3.1415926,4);--取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数select rand();--指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列select rand(3);-----Conditional Functions 条件函数--------------------使用之前课程创建好的student表数据select*from student limit3;--if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)selectif(1=2,100,200);selectif(sex ='男','M','W')from student limit3;--空值转换函数: nvl(T value, T default_value)select nvl("allen","itcast");select nvl(null,"itcast");--条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] ENDselectcase100when50then'tom'when100then'mary'else'tim'end;selectcase sex when'男'then'male'else'female'endfrom student limit3;
本文转载自: https://blog.csdn.net/qq_43601664/article/details/129475759
版权归原作者 半觞盛夏半觞秋 所有, 如有侵权,请联系我们删除。
版权归原作者 半觞盛夏半觞秋 所有, 如有侵权,请联系我们删除。