
背景:目前国内有大量的公司都在使用 Elasticsearch,包括阿里、京东、滴滴、今日头条、小米、vivo等诸多知名公司。除了搜索功能之外,Elasticsearch还结合Kibana、Logstash、Elastic Stack还被广泛运用在大数据近实时分析领域,包括日志分析、指标监控等多个领域。
1、节点(Node)
节点是指Elasticsearch可单独运行的实例。一个物理机可以有多个节点,物理机:节点数=1:N。

2、集群(Cluster)
由一个或多个节点组成。 集群为整个数据提供跨所有节点的集合索引和搜索功能。其中有一个为主节点,这个主节点是通过选举产生的。

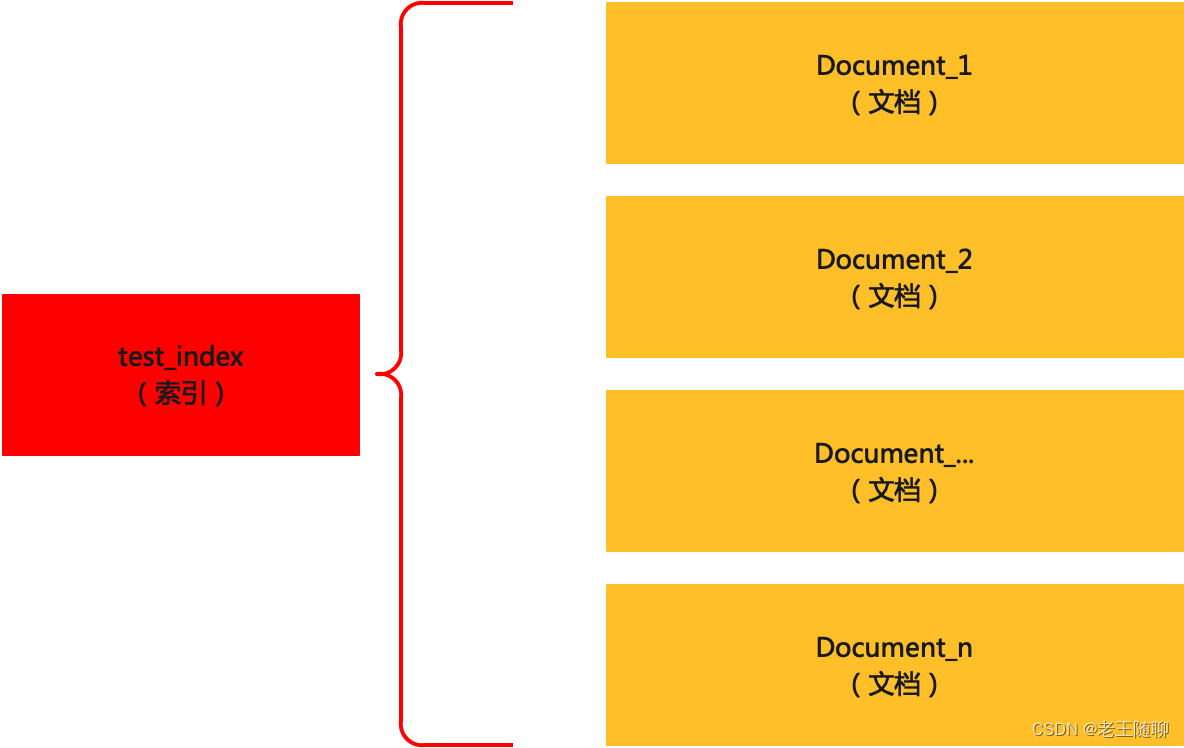
3、索引(Index)
索引是不同类型的文档和文档属性的集合(类似于MYSQL表)。其中索引会使用分片的机制来提高检索性能。
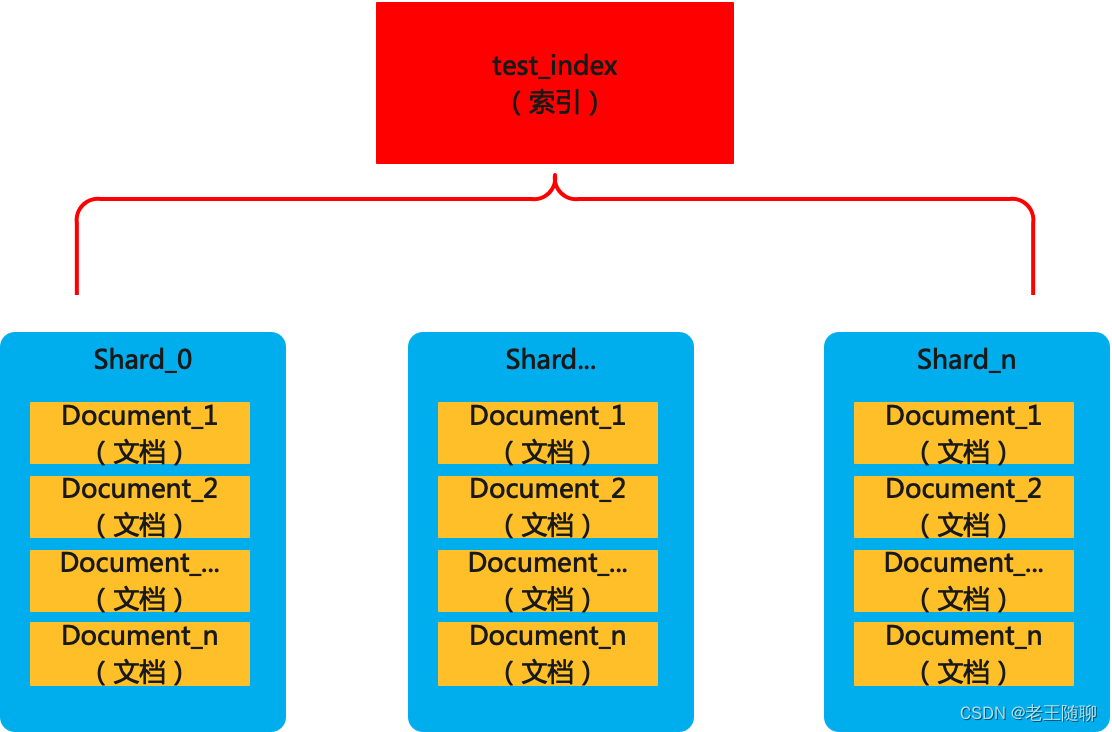
4、分片(Shards)
分片是用于分布式的形式存储索引数据,一个索引分可能被分成多个分片,目的是减少单独节点的压力,提高检索性能。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
5、映射(Mapping)
映射是定义一个文档以及其所包含的字段以及被存储和索引的方法。其中包含:元数据字段、字段列表或属性等信息。

6、文档(Document)
它是以JSON格式定义的特定方式的字段集合,每个文档都有一个唯一标识。

7、副本(Replica)
可以创建索引和分片的副本, elasticsearch可以设置多个索引的副本。主要用于负责容错,以及承担读请求负载,通过在这些副本中执行并行搜索来提高搜索的性能。当某个节点某个分片损坏或丢失时可以从副本中恢复。

8、网关(Gateway)
Gateway 是 Elasticsearch 索引的持久化存储方式,ES 默认是先把索引存放到内存中,当内存满了之后,再持久化到硬盘里。当这个 Elasticsearch 集群关闭或者再次重新启动时就会从 Gateway 中读取索引数据。 Gateway支持多种类型:本地文件系统(默认)、分布式文件系统Hadoop 以及 AMZ 的S3云存储服务。

本文转载自: https://blog.csdn.net/wangyongfei5000/article/details/124559765
版权归原作者 老王随聊 所有, 如有侵权,请联系我们删除。
版权归原作者 老王随聊 所有, 如有侵权,请联系我们删除。