
webdriver API
复习上一篇博客(自动化测试selenium_妖风吹不倒小熊栽的树的博客-CSDN博客)提到的:
input form span div 都属于 tag ,代表一种样式
CSS selector xpath(这个元素在这个页面的位置,而且都不一样) 基于对前端非常了解的基础上可以自己去写,最好可以自己去写,需要好好了解一下。
2.等待的两种方式(即等待API)
问题:写了一个脚本,代码没有问题,但是在运行时找不到页面的元素了?
原因:页面加载太慢,但是自动化执行的时候太快了,打开页面就立马去找元素,这是还没有等到页面加载出来。
解决办法:在打开页面之后先不去定位它,而是先去等待一些时间
固定等待和智能等待的区别?(前面博客查找)


1.定位一组元素
a.如何打开本地的html的页面
首先拼成一个本地的url :file:+/// +文件的绝对路径
其次 import os
最后 url ="file:///" +os.path.abspath("c:\......)
driver.get(url)
上面的元素要怎么定位呢?
先定位出同一类元素(tag name name class name等),然后根据需要定位的元素的特征(type)去甄别出要定位的具体元素进行操作。
定位ID driver.find_element_id("c1").click() driver.find_element_id("c2").click() driver.find_element_id("c3").click() 用input定位

2.多层框架的定位

3.层级定位

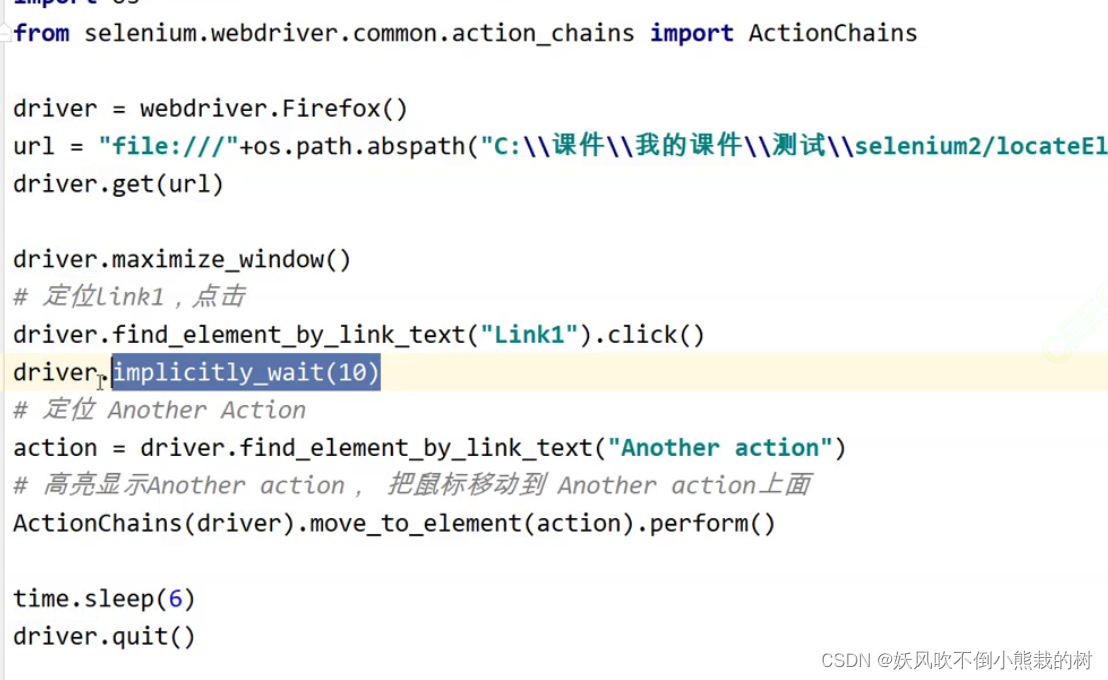
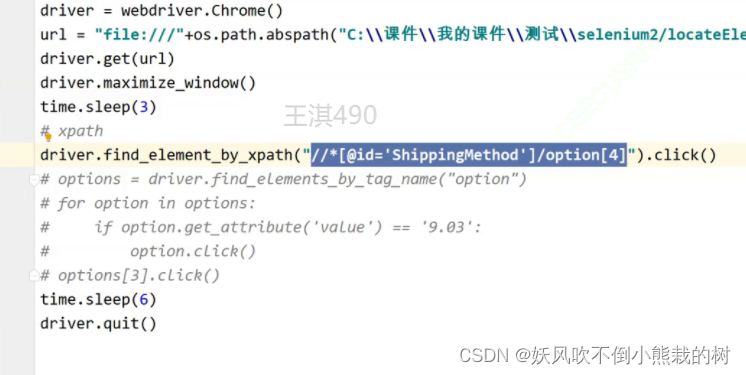
4.下拉框的处理
1.直接用xpath定位
2.先用tag_name再根据元素的特殊属性进行过滤和筛选,再进行操作
3.用数组下标访问(索引从0开始)
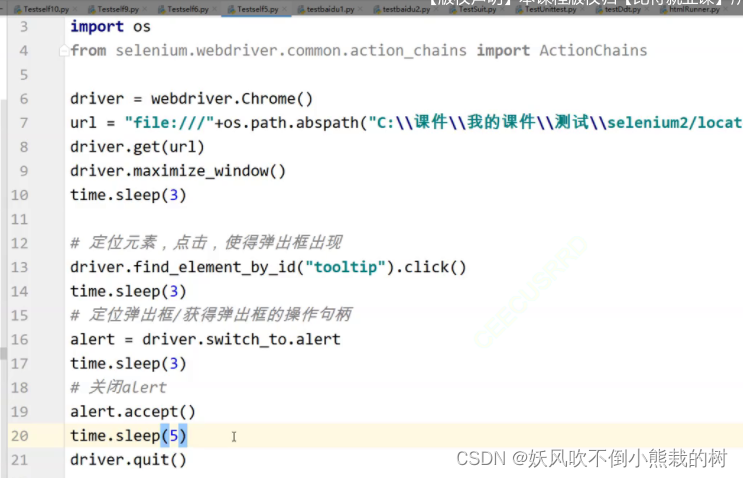
5.alert弹框的处理
#定位弹出框的操作句柄
alert =driver.switch_to.alert
#关闭alert
alert.accept()
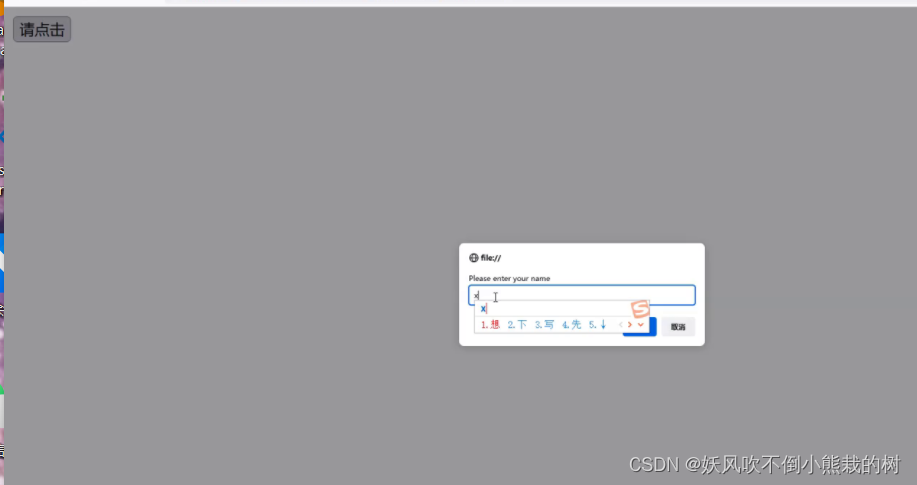
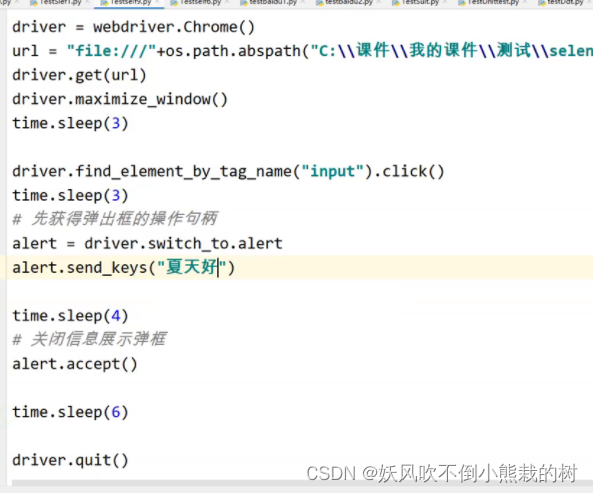
在alert弹窗输入相应信息
#先获得弹出框的操作句柄
alert =driver.switch_to.alert
再用send_keys去输入信息
alert.send_keys("夏天好")
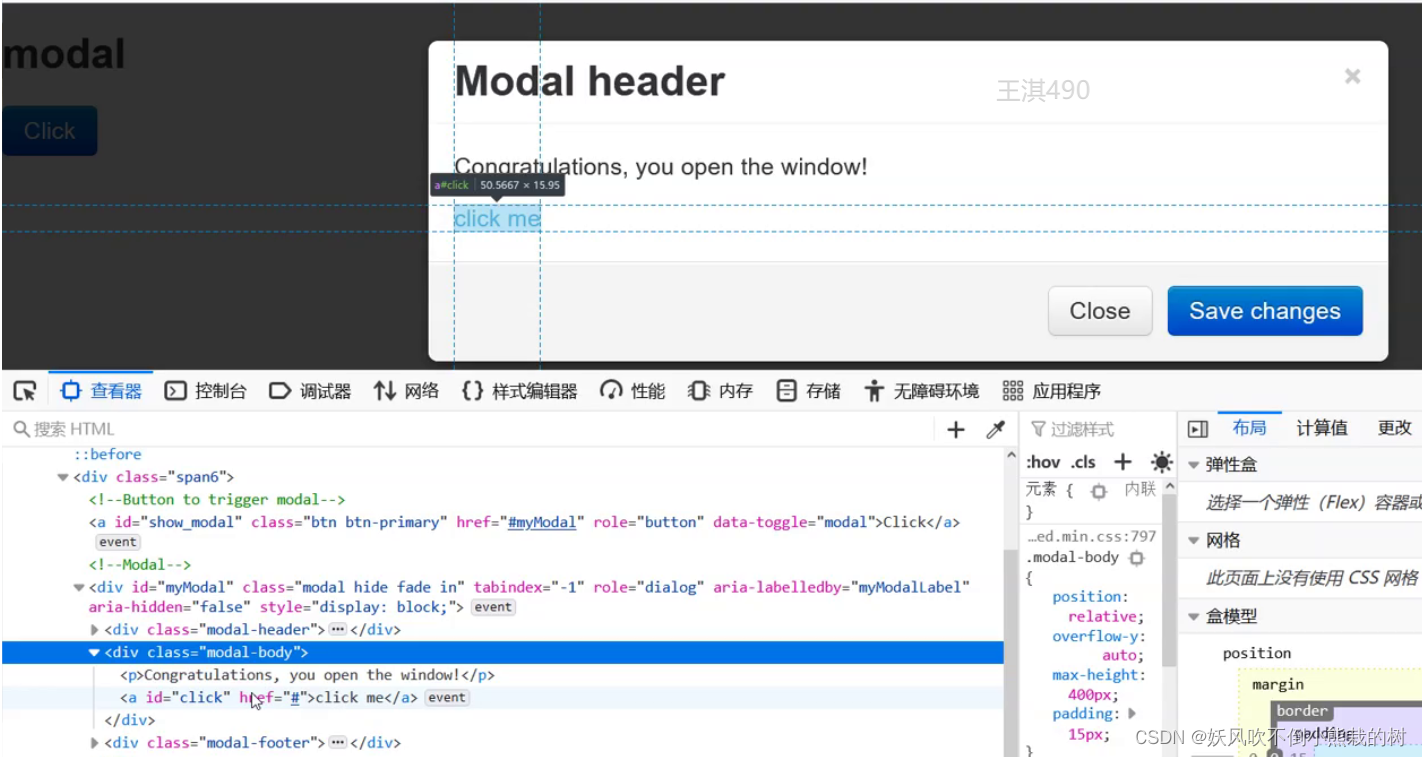
6.div对话框的处理
适用与页面复杂,元素非常多,没有id,并且name,或者tag_name重复
1.首先定位元素所在的div模块
2.在定位到的div模块的基础上去精确寻找需要定位的元素

7.上传文件
定位按钮
就是把一个文件上传上去
send_keys(需要上传文件的绝对路径+文件名字)

8.为什么很多页面防自动化操作
基于安全性的考虑,所以每次的id都不一样。

8.selenium3 (之前提到的时selenium2)
unittest框架:是一个功能单元测试,UI功能单元测试,与java单元测试框架不同,一个时是黑盒一个是白盒。
(1)测试固件(框架里面固定的方法):
**setup方法**:测试环境和数据的准备工作(环境的初始化) ** tearDown**:做测试用例执行完成后的清理工作(环境的清理工作)(2)测试用例 一个用例是一个方法,def名字以test_开头
运行脚本的时候默认会自动会运行test_开头的方法
普通方法被test_开头的方法调用的时候才会运行
(3)测试套件
把不同文件里面不同类里面的不同测试方法组织起来放在一起运行,把测试用例组织到一起进行一个整体的测试
必须以继承方式来使用。先定义一个类。
测试套件:
(1)unittest.TestSuite
addTest(脚本名称.类名称.方法名) 一个方法添加
makeSuit() unittest.makeSuit(脚本名称.类名称)可以把一个类中所有的测试方法添加到测试套件中
(2)TestLoader()
unittest.TestLoader().loadTestsFromCase 把一个类中所有的测试方法创建成一个测试套件返回。
(3)把一个文件夹下以某种形式命名的脚本文件中所有的测试用例放在测试套件中。
discover()
把一个文件夹下所有测试脚本的测试用例都执行一遍
discover
定位账号输入账号,登入密码输入密码
2 最详细,1,也详细



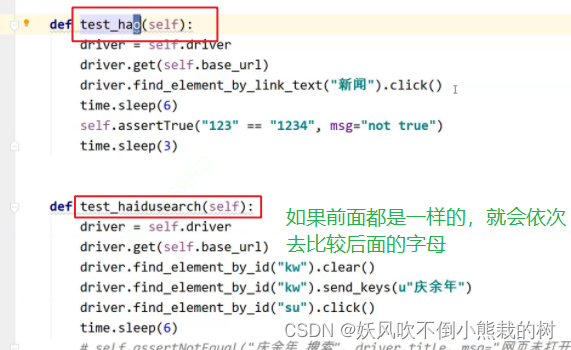
9. 测试用例的执行顺序
先0-9 A-Z a-z
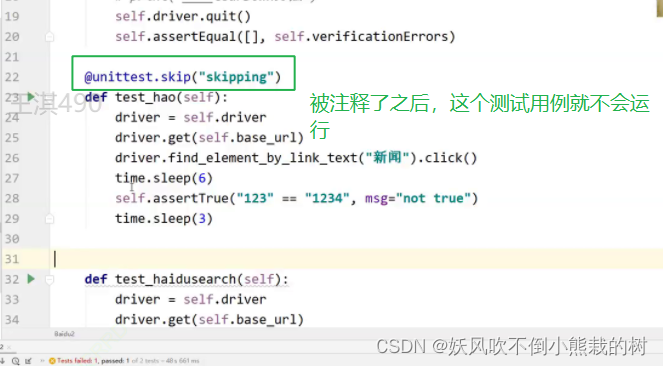
10.忽略测试用例的执行
对于不想运行的测试用例打标签:@unittest.skip("skipping")
11.unittest断言
复习:测试用例的要素都有哪一些?
测试步骤,测试数据,测试环境,预期结果
测试的最终结果就是判断实际结果和预期结果是否相符。
预期的结果其实就是:符合需求标准的
断言:判断实际结果和预期结果相符合(相当于眼睛和大脑)
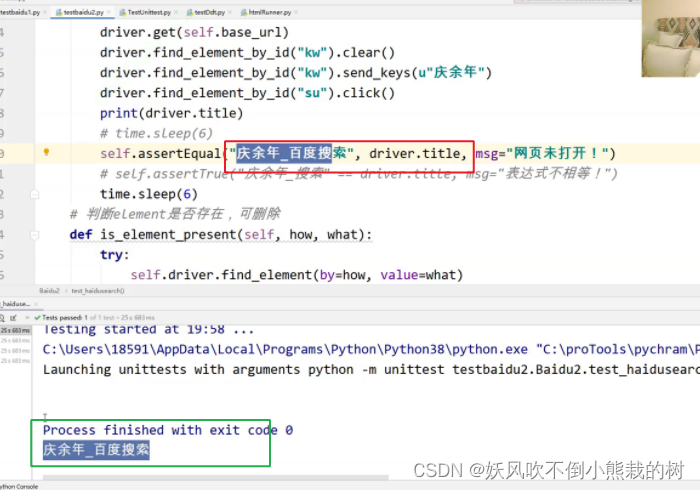
driver.title打印的就是驱动的title
必须让浏览器把第二个页面加载出来才是庆余年,加载不出来title就是百度一下,,,和网速有关,加个sleep(6)即可
冒烟测试:就是把一个项目主要的流程和核心的功能测试一遍。
要让自动化脚本变得稳定。
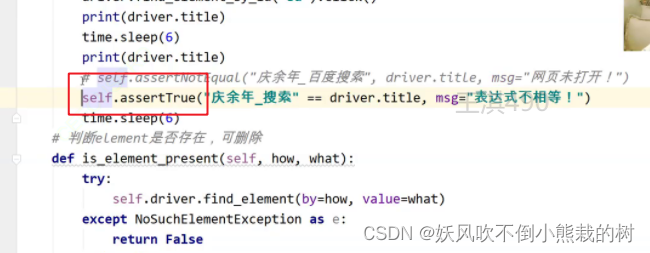
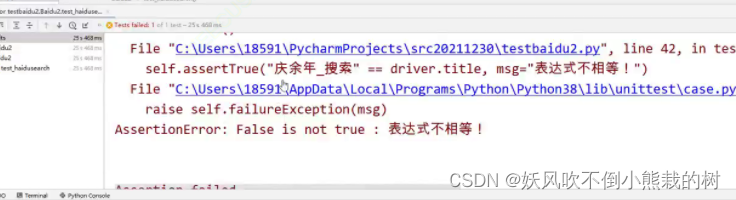
改为assertNotEqual之后,实际相等,我预判不相等,结果就会报错
运行失败,因为人家的title是庆余年百度搜索




12.HTML报告
import HTMLTestRunner import os import sys import time import unittest def createsuite(): discovers = unittest.defaultTestLoader.discover("../src20211230", pattern="testbaidu*.py", top_level_dir=None) print(discovers) return discovers if __name__=="__main__": # 文件夹要创建在哪里 curpath = sys.path[0] print(sys.path) print(sys.path[0]) # 1,创建文件夹,创建的这个文件夹干什么 if not os.path.exists(curpath+'/resultreport'): os.makedirs(curpath+'/resultreport') # 2,文件夹的命名,不能让名称重复,如果重复,这次的报告会覆盖上一次的报告 # 时间 时分秒 ——》名称绝对不会重复,加上时间命名即可 now = time.strftime("%Y-%m-%d-%H %M %S", time.localtime(time.time())) print(now) print(time.time()) print(time.localtime(time.time())) # 文件名 filename = curpath + '/resultreport/'+ now + 'resultreport.html' with open(filename, 'wb') as fp: runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u"测试报告", description=u"用例执行情况", verbosity=2) suite = createsuite() runner.run(suite)

13.异常捕捉和错误截图(目的:保留测试结果现场)
./image
"." 代表当前文件所在的路径下
把异常捕获了,也就是截图了,所以不会报异常
14.数据驱动的方法

版权归原作者 妖风吹不倒小熊栽的树 所有, 如有侵权,请联系我们删除。