
一、flume概述
1.1 flume定义
大数据需要解决的三个问题:采集、存储、计算。
Apache flume是一个分布式、可靠的、高可用的海量日志数据采集、聚合和传输系统,将海量的日志数据从不同的数据源移动到一个中央的存储系统中。用一句话总结:Flume不生产数据,它只是数据的搬运工。
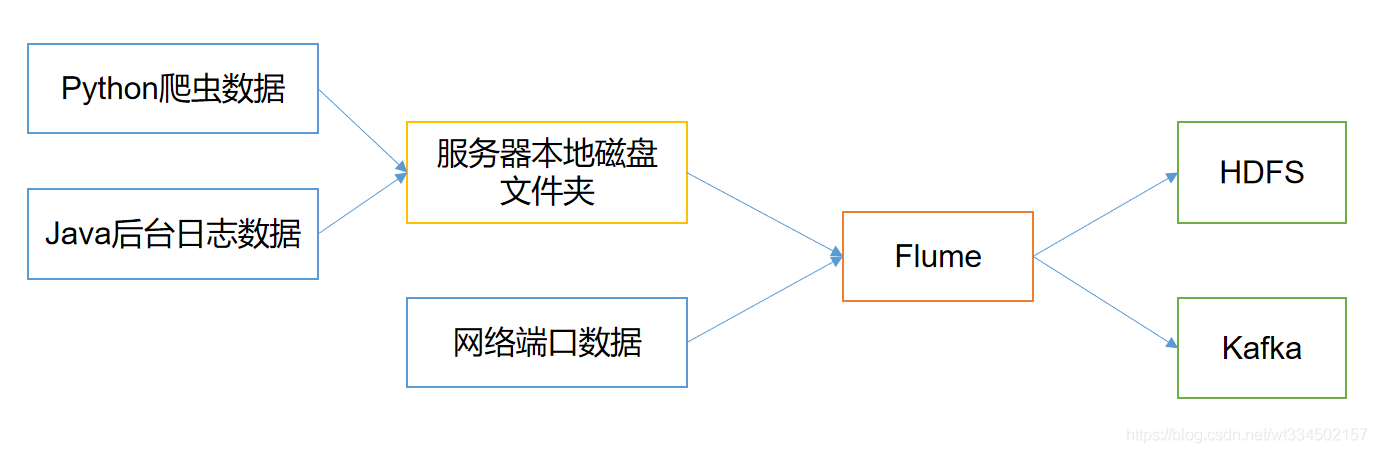
flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
1.2 flume基础框架
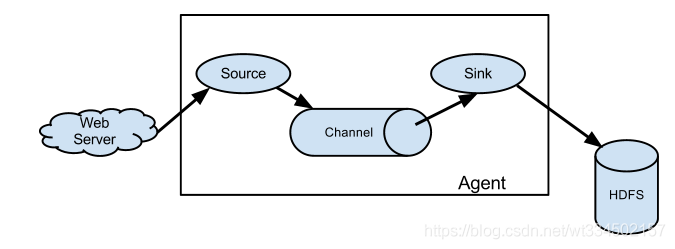
1.2.1 Agent
agent是一个JVM进程,它以事件的形式将数据从源头送至目的地。
agent主要有三个组成部分:Source、Channel、Sink。
Source:采集组件。
用户跟数据源对接,以获取数据;它有各种各样的内置实现。包括
avro、thrift、
exec、jms、
spooling directory、
netcat、
taildir等。Sink:下沉组件。
不断轮询channel中的事件并批量地移除它们。将这些时间批量写入到存储或索引系统、或者被发送到另一个flume agent中。组件包括
hdfs、
logger、avro、thrift、ipc、
file、
HBase、solr、自定义。Channel : 传输通道组件。
用于从source将数据传递到sink,起到缓冲的作用,是source和sink之间的缓冲区。如源头采集的数据和输出数据速率不对等,若没有channel,source采集的速率快于sink输出的数据时,会导致系统的崩溃。
channel是
线程安全的,可以同时处理几个source的写入操作和几个sink的读取操作。flume自带两种channel:
memory channel和
file channel。
memory channel是内存中的队列,在
不需要关心数据丢失的情景下使用;
file channel将所有的事件写道磁盘,因此在程序关闭或者宕机的情况下
不会丢失数据。
1.2.2 Event
传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。
Header(k=v)
Body(byte array)
二、Flume安装
2.1 解压文件
1. 解压文件到/opt/soft中
[root@hadoop02 install]# tar -zxf ./apache-flume-1.9.0-bin.tar.gz -C ../soft/
2. 在/opt/soft目录下将apache-flume-1.9.0-bin 改名为flume190
[root@hadoop02 soft]# mv apache-flume-1.9.0-bin/ flume190
2.2 修改配置文件
1. /opt/soft/flume190/conf目录中将临时配置文件flume-env.sh.template拷贝为配置文件flume-env.sh
[root@hadoop02 conf]# cp flume-env.sh.template flume-env.sh
2. 配置flume-env.sh文件 (修改22行和25行)
[root@hadoop02 conf]# vim flume-env.sh
22 export JAVA_HOME=/opt/soft/jdk180
25 export JAVA_OPTS="-Xms1000m -Xmx2000m -Dcom.sun.management.jmxremote"
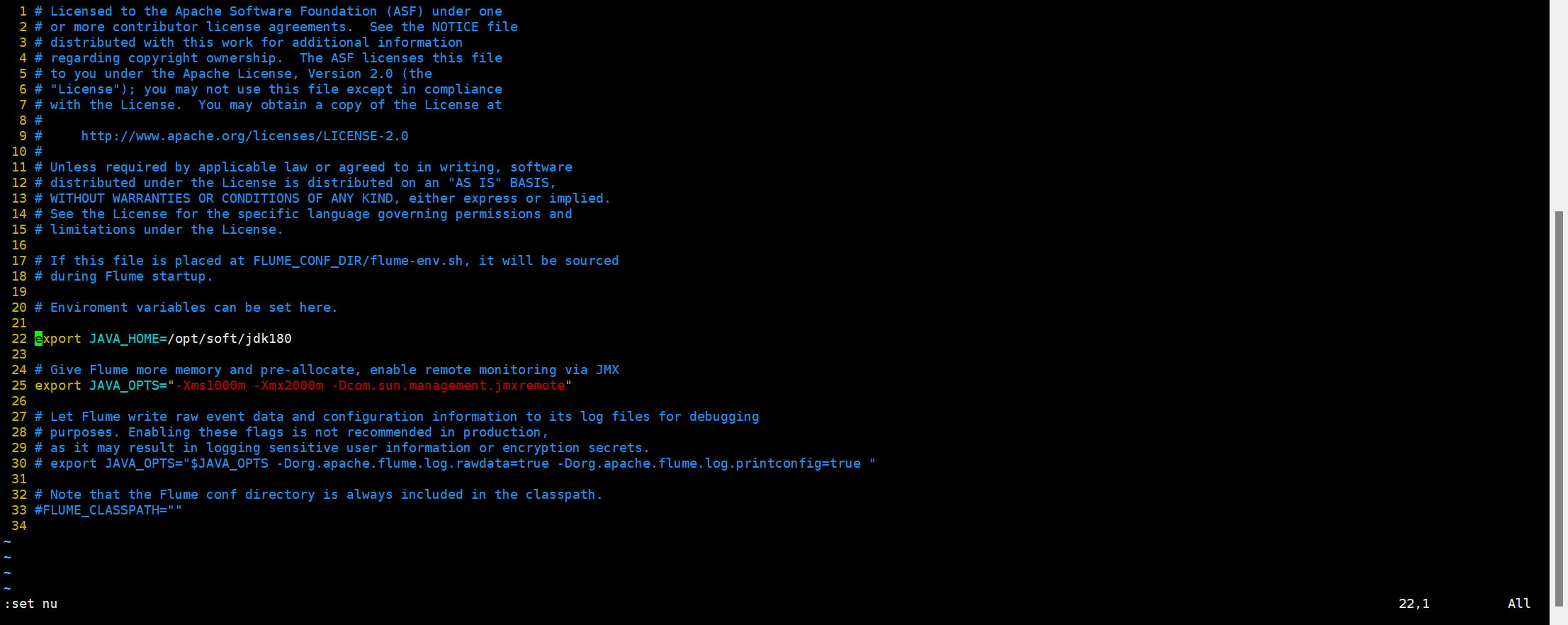
-Xms:初始Heap大小,使用的最小内存,cpu性能高时此值应设的大一些。
-Xmx:java heap最大值,使用的最大内存。
2.3 安装nc(netcat) /telnet协议
[root@hadoop02 conf]# yum install -y nc
先查看telnet
[root@hadoop02 ~]# yum list telnet*
安装telnet
[root@hadoop02 ~]# yum install telnet-server
[root@hadoop02 ~]# yum install telnet.*
telnet是teletype network的缩写,现在已成为一个专有名词,表示远程登录协议和方式,分为Telnet客户端和Telnet服务器程序. Telnet可以让用户在本地Telnet客户端上远端登录到远程Telnet服务器上。
监听端口
先开服务端
[root@hadoop02 ~]# nc -lc 9999
再开客户端
[root@hadoop02 ~]# nc localhost(或输入ip地址) 9999
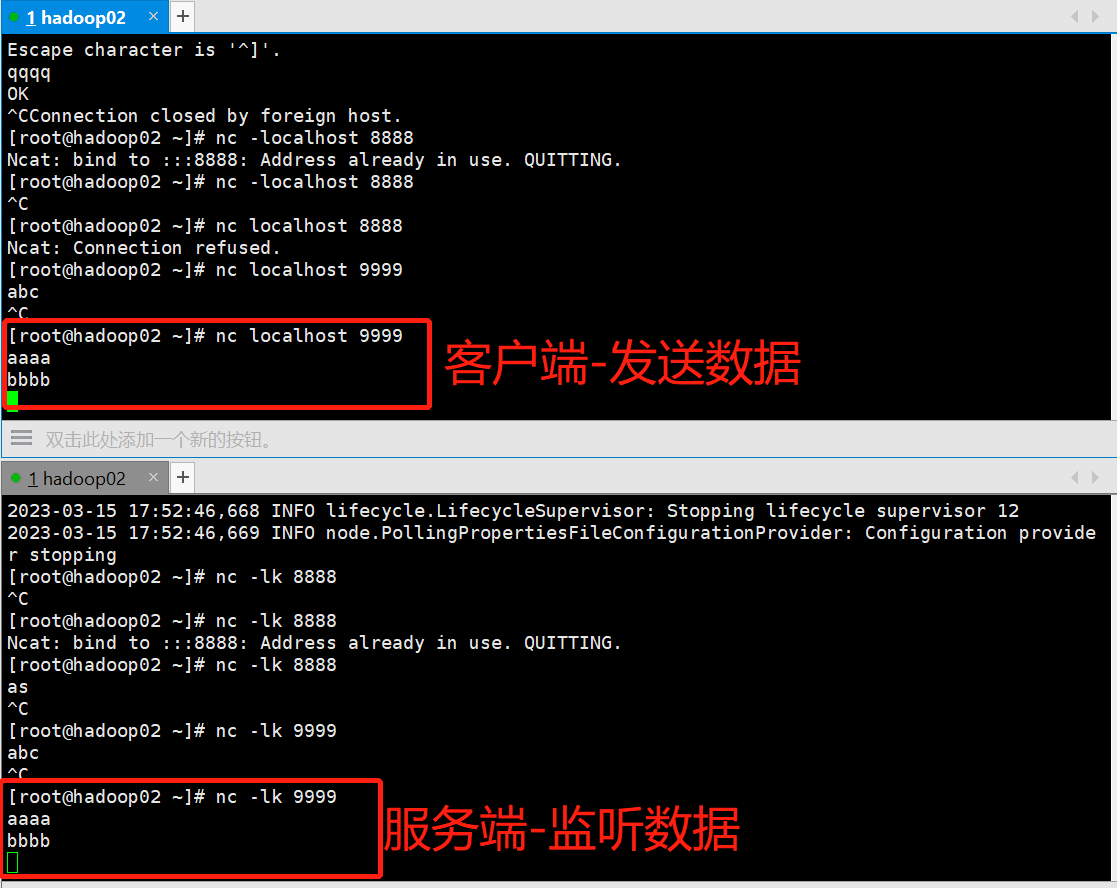
2.4 应用
2.4.1 监控端口并输出到控制台
1> 通过netcat工具向本机的8888端口发送数据。
2> flume监控本机的8888端口。通过flume的source端读取数据。
3> flume将获取的数据通过sink端写出到控制台。
新建netcat-logger.conf文件
[root@hadoop02 conf]# vim ./netcat-logger.conf
# 给agent命名为a1
a1.sources=r1
a1.sinks=k1
a1.channels=c1
# source的描述信息/配置
a1.sources.r1.type=netcat
a1.sources.r1.bind=192.168.152.192
a1.sources.r1.port=8888
# channel的描述信息/配置
a1.channels.c1.type=memory
-- 事务容量,单次发送最大的事件量。要小于总容量
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=logger
# 将source端和sink端进行绑定
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
启动监听:
监听端口:
以下命令需要进入到flume/bin目录下运行
[root@hadoop02 ~]# /opt/soft/flume190/bin/flume-ng agent --name a1 --conf /opt/soft/flume190/conf/ --conf-file /opt/soft/flume190/conf/netcat-logger.conf -Dflume.root.logger=INFO,console
访问端口:
[root@hadoop02 conf]# netcat 192.168.153.139 8888
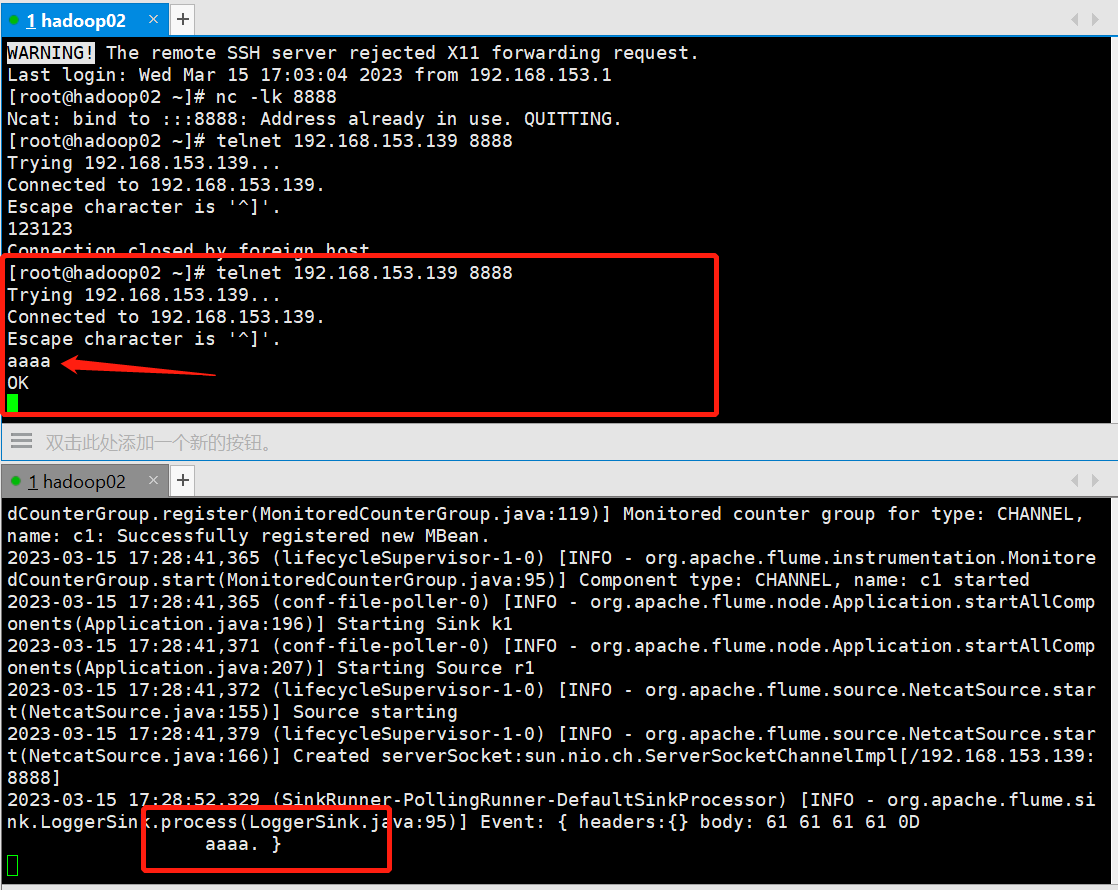
运行命令说明:
flume-ng agent:
启动命令。
--name(-n):
agent的名字,这里为a1。
--conf(-c):
flume的配置文件存储在conf/目录。
--conf-file(-f):
flume本次启动的配置文件是conf/netcat-logger.conf文件。
-Dflume.root.logger=INFO,console:
普通运行模式,将运行日志输出到控制台。
-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error。
2.4.3 监控单个追加文件
新建flume-file-hdfs.conf文件
--文件保存在/opt/conf中
a1.sources=r1
a1.sinks=k1
a1.channels=c1
--监听hadoop datanode的log文件
a1.sources.r1.type=exec
a1.sources.r1.command=tail -F /opt/data/datas.csv
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://hadoop02:9000/flume/upload/%Y%m%d/%H
a1.sources.r1.channels=c1
a1.sinks.k1.channels=c1
启动hadoop
[root@hadoop02 ~]# start-all.sh
启动监听
[root@hadoop02 flume190]# ./bin/flume-ng agent -n a1 -c conf/ -f /opt/conf/flume-file-hdfs.conf
三、flume事务
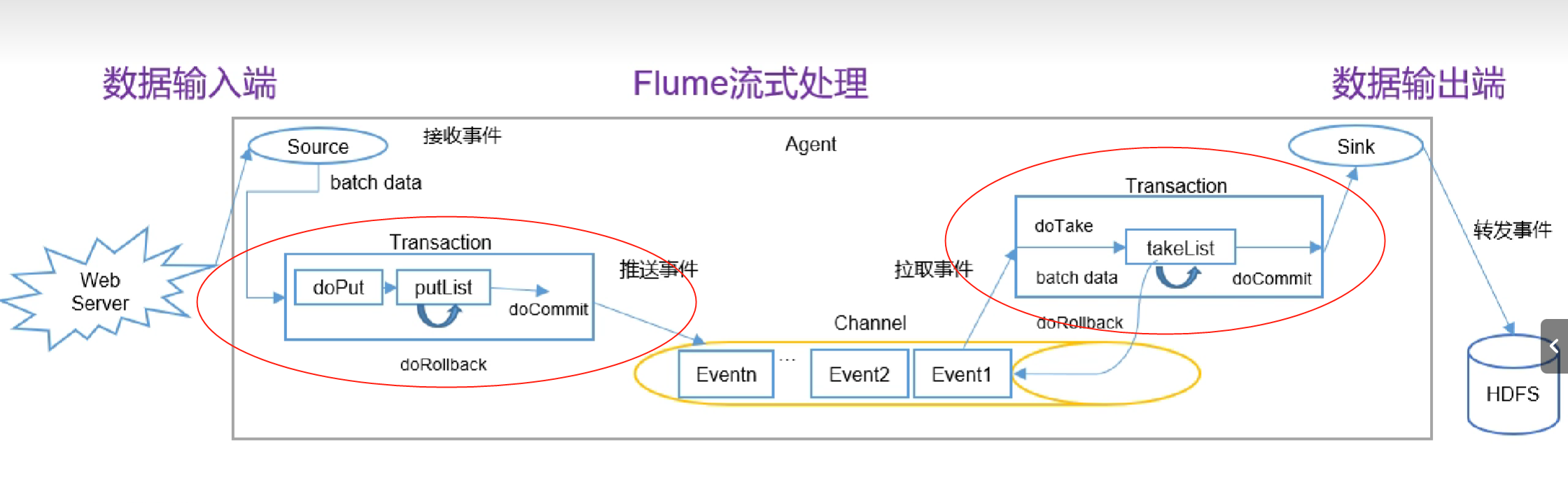
Source 采集数据并包装成Event,并将Event缓存再Channel中,Sink不断地从Channel 获取Event,并解决成数据,最终将数据写入存储或索引系统。
Put事务流程:
doPut:将批数据先写入临时缓冲区。doCommit:检查channel内存队列是否足够合并。
doRollback:channel内存队列空间不足,回滚事务。
Take事务:
doTake:将数据取到临时缓冲区takeList,并将数据发送到HDFSdoCommit:如果数据全部发送成功,则清楚临时缓冲区takeList。
doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takeList中的数据归还给channel内存队列。
版权归原作者 five小点心 所有, 如有侵权,请联系我们删除。