

文章目录
HDFS权限和 Java的api使用
前言
博主语录:一文精讲一个知识点,多了你记不住,一句废话都没有
经典语录:别在生活里找你想要的,要去感受生活里发生的东西
一、HDFS的权限
1、启蒙案例
Permission Owner Group Size Replication Block Size Name
drwxr-xr-x root supergroup 0 B 0 0 B user
-rw-r--r-- root supergroup 8.61 KB 2 128 MB install.log
2、基本特征
HDFS是一个文件系统
类似unix、linux有用户概念
HDFS有相关命令和接口去创建用户
有超级用户的概念
linux系统中超级用户:root hdfs系统中超级用户: 是namenode进程的启动用户有权限概念
hdfs的权限是自己控制的来自于hdfs的超级用户
3、实操
注意:一般在企业中不会用root做什么事情
**面向操作系统 **
root是管理员 其他用户都叫【普通用户】
**面向操作系统的软件 **
谁启动,管理这个进程,那么这个用户叫做这个软件的管理员
实操案例
切换我们用root搭建的HDFS
用god这个用户来启动
重复操作node01~node04:
sh stop-dfs.sh
3.1、添加用户:root
useradd god
passwd god
3.2、将资源与用户绑定
chown -R god src
chown -R god /opt/bigdata/hadoop-2.6.5
chown -R god /var/bigdata/hadoop
**3.3、切换到god去启动 **
sh start-dfs.sh
为了拿到.ssh
ssh localhost
给god做免密
注意:我们是HA模式:免密的2中场景都要做的
# node01~node02:
cd /home/god/.ssh
ssh-keygen -t dsa -P '' -f ./id_dsa
# node01:
ssh-copy-id -i id_dsa node01
ssh-copy-id -i id_dsa node02
ssh-copy-id -i id_dsa node03
ssh-copy-id -i id_dsa node04
# node02
cd /home/god/.ssh
ssh-copy-id -i id_dsa node01
ssh-copy-id -i id_dsa node02
修改hdfs-site.xml
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/god/.ssh/id_dsa</value>
</property>
分发给node02~04
3.4、使用god用户重启HDFS
sh start-dfs.sh
4、用户权限验证实操
在node01执行操作
su god
hdfs dfs -mkdir /temp
hdfs dfs -chown god:ooxx /temp
hdfs dfs -chmod 770 /temp
在node04执行操作
useradd good
groupadd ooxx
usermod -a -G ooxx good
id good
su good
hdfs dfs -mkdir /temp/abc # 失败
hdfs groups
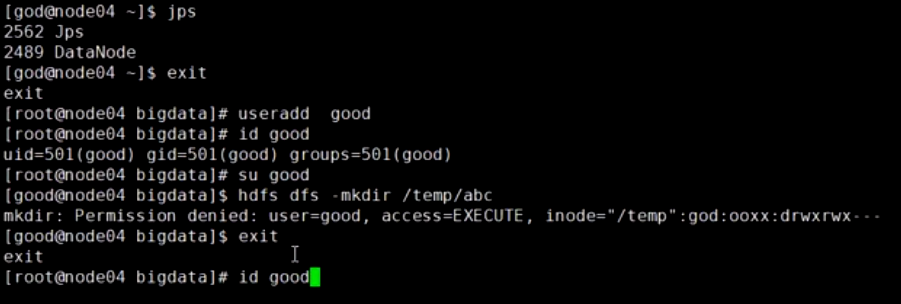
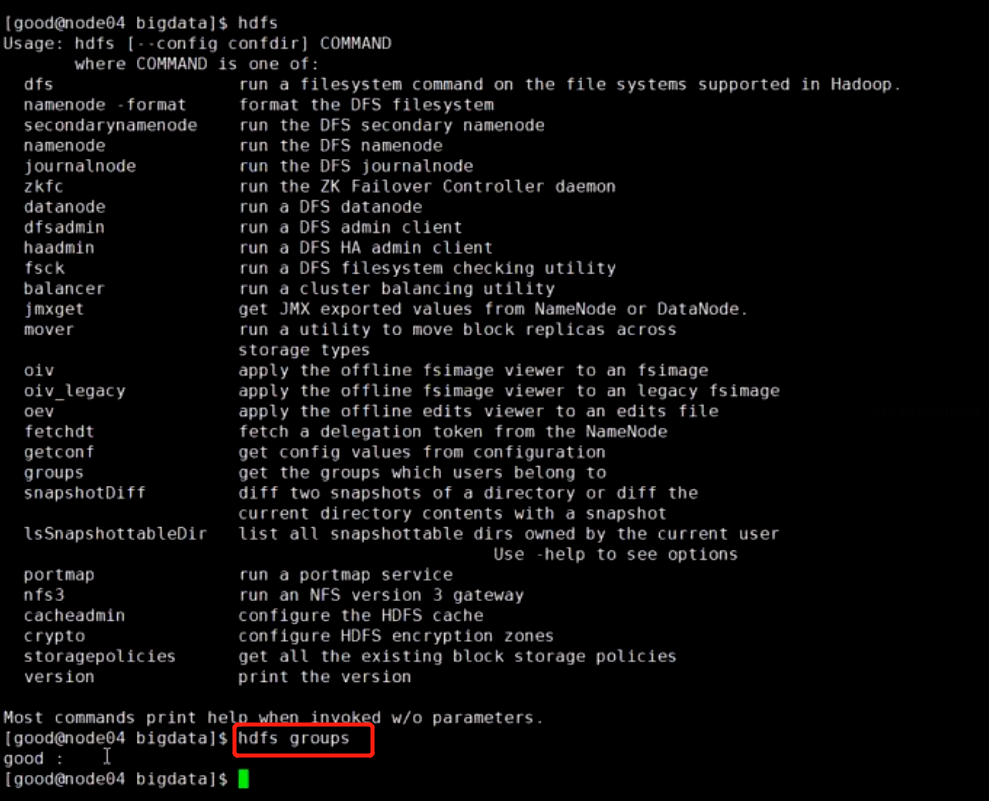
用户good操作失败因为hdfs已经启动了,不知道你操作系统又偷偷摸摸创建了用户和组
成功操作命令
useradd good
groupadd ooxx
usermod -a -G ooxx good
su god
hdfs dfsadmin -refreshUserToGroupsMappings
**注意需要在namenode的节点执行,其他节点是无效的 **
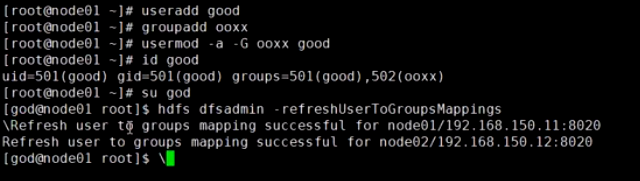
执行上面命令就可以刷新用户权限

结论:默认hdfs依赖操作系统上的用户和组
二、hdfs中Java的api使用
windows idea eclips 叫什么?
集成开发环境
语义:
开发hdfs的client
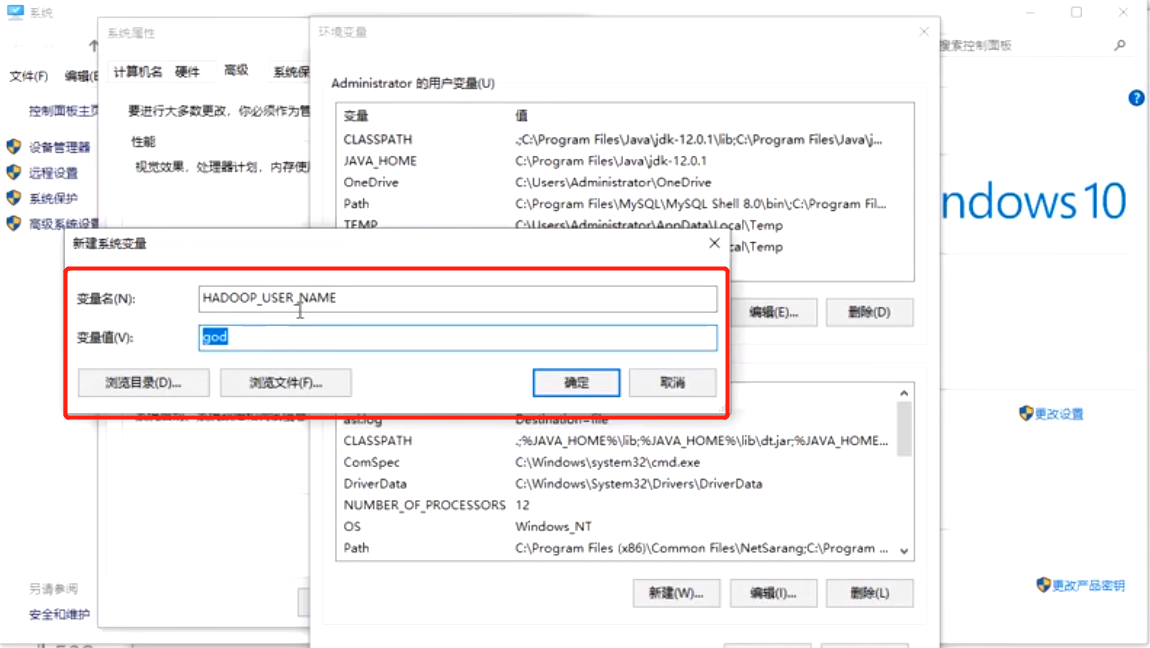
权限:
1)参考系统登录用户名;
2)参考环境变量;
3)代码中给出;
HADOOP_USER_NAME god
这一步操作优先再启动idea
JDK版本:
集群和开发环境jdk版本一致
maven:
构建工具
文件操作代码
package com.lanson.bigdata.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.net.URI;
public class TestHDFS {
public Configuration conf = null;
public FileSystem fs = null;
//C/S
@Before
public void conn() throws Exception {
conf = new Configuration(true);//true
// fs = FileSystem.get(conf);
// <property>
// <name>fs.defaultFS</name>
// <value>hdfs://mycluster</value>
// </property>
//去环境变量 HADOOP_USER_NAME god
fs = FileSystem.get(URI.create("hdfs://mycluster/"),conf,"god");
}
@Test
public void mkdir() throws Exception {
Path dir = new Path("/lanson01");
if(fs.exists(dir)){
fs.delete(dir,true);
}
fs.mkdirs(dir);
}
@Test
public void upload() throws Exception {
BufferedInputStream input = new BufferedInputStream(new FileInputStream(new File("./data/hello.txt")));
Path outfile = new Path("/lanson/out.txt");
FSDataOutputStream output = fs.create(outfile);
IOUtils.copyBytes(input,output,conf,true);
}
@Test
public void blocks() throws Exception {
Path file = new Path("/user/god/data.txt");
FileStatus fss = fs.getFileStatus(file);
BlockLocation[] blks = fs.getFileBlockLocations(fss, 0, fss.getLen());
for (BlockLocation b : blks) {
System.out.println(b);
}
// 0, 1048576, node04,node02 A
// 1048576, 540319, node04,node03 B
//计算向数据移动~!
//其实用户和程序读取的是文件这个级别~!并不知道有块的概念~!
FSDataInputStream in = fs.open(file); //面向文件打开的输入流 无论怎么读都是从文件开始读起~!
// blk01: he
// blk02: llo lanson 66231
in.seek(1048576);
//计算向数据移动后,期望的是分治,只读取自己关心(通过seek实现),同时,具备距离的概念(优先和本地的DN获取数据--框架的默认机制)
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
}
@After
public void close() throws Exception {
fs.close();
}
}
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
版权归原作者 Lansonli 所有, 如有侵权,请联系我们删除。