
本人是爬虫初学者,想通过爬取电视剧信息来巩固自己所学的一些知识,但是在一些网站中并没有找到类似于page的参数,或者就是参数加密,自己的能力没法解开,导入无法使用下一页的功能。所以我就想到了selenium,找到"下一页所在的标签",直接点击就好了。慢是慢了点,不过好在能使用下一页的功能了。
发送url请求
网站地址(参数url的值)
# 发送请求
url =""
bro = webdriver.Edge()
bro.get(url=url)
bro.maximize_window() #窗口最大化
我使用的是Edge浏览器驱动
我没有用无头浏览,bro.maximize_window()的作用就是使浏览器窗口最大化。
创建接收文件夹并写好excel的表头
headers=["电影名称","导演","编剧","主演","类型","首播时间"]
if not os.path.exists(r"D:\爬虫数据接收"):
os.mkdir(r"D:\爬虫数据接收")
fp = open(r"D:/爬虫数据接收/某瓣电视剧信息爬取.csv","a",encoding="utf-8-sig",newline="")
# 创建writer对象
writer = csv.writer(fp)
# 写表头
writer.writerow(headers)
utf-8-sig 的作用就是防止写入excel文件的时候中文乱码
newline="" 的作用就是防止写入的时候自动换行,导致数据一行隔一行
循环点击电视剧详情页并做xpath解析
while 1:
# 获取点击链接
hreflist = bro.find_elements(By.XPATH, '//div[@class="doulist-item"]//div[@class="title"]/a')
for i in hreflist:
i.click()
# 切换到新打开的界面
bro.switch_to.window(bro.window_handles[-1])
time.sleep(2)
# 电影名字
title_ele = bro.find_element(By.XPATH,'//div[@id="content"]/h1/span[1]')
title = title_ele.text
# 导演
director_ele = bro.find_element(By.XPATH, '//div[@id="content"]//div[@id="info"]/span[1]/span[@class="attrs"]/a')
director = director_ele.text
# 编剧
scriptwriter_ele = bro.find_element(By.XPATH,'//div[@id="content"]//div[@id="info"]/span[2]/span[@class="attrs"]')
scriptwriter = scriptwriter_ele.text
# 主演
actor_ele =bro.find_element(By.XPATH,'//div[@id="content"]//div[@id="info"]/span[3]/span[@class="attrs"]')
actor = actor_ele.text
# 类型
type_ele =bro.find_elements(By.XPATH,'//div[@id="content"]//div[@id="info"]/span[@property="v:genre"]')
TV_type = ""
for i in type_ele:
TV_type = i.text+"/"+TV_type
#首播
debut_ele = bro.find_element(By.XPATH,'//div[@id="content"]//div[@id="info"]/span[@property="v:initialReleaseDate"]')
debut = debut_ele.text
# 把数据存放到列表中
data = [title,director,scriptwriter,actor,TV_type,debut]
# 写内容
fp = open(r"D:\爬虫数据接收/电视剧信息爬取.csv", "a", encoding="utf-8-sig",newline="")
writer.writerow(data)
print("{}爬取完成".format(title))
fp.close()
time.sleep(2)
# 关闭当前窗口
bro.close()
# 切换到原来的页面
bro.switch_to.window(bro.window_handles[-1])
time.sleep(1)
#切换下一页
print("下一页....")
next = bro.find_element(By.XPATH,'//span[@class="next"]/a')
next.click()
这里可以说明前面为什么要提前写好表头,因为这里写入excel的命令都是在循环中的,如果把写入表头的命令放在这里,就会导致写入很多表头。但是我们的表头只需要一个。(我是纯小白,没有找到好办法只能用笨方法,欢迎大佬指正)
当一个页面循环点击结束之后,找到"下一页"对象,并且点击
#切换下一页
print("下一页....")
next = bro.find_element(By.XPATH,'//span[@class="next"]/a')
next.click()
爬取完成
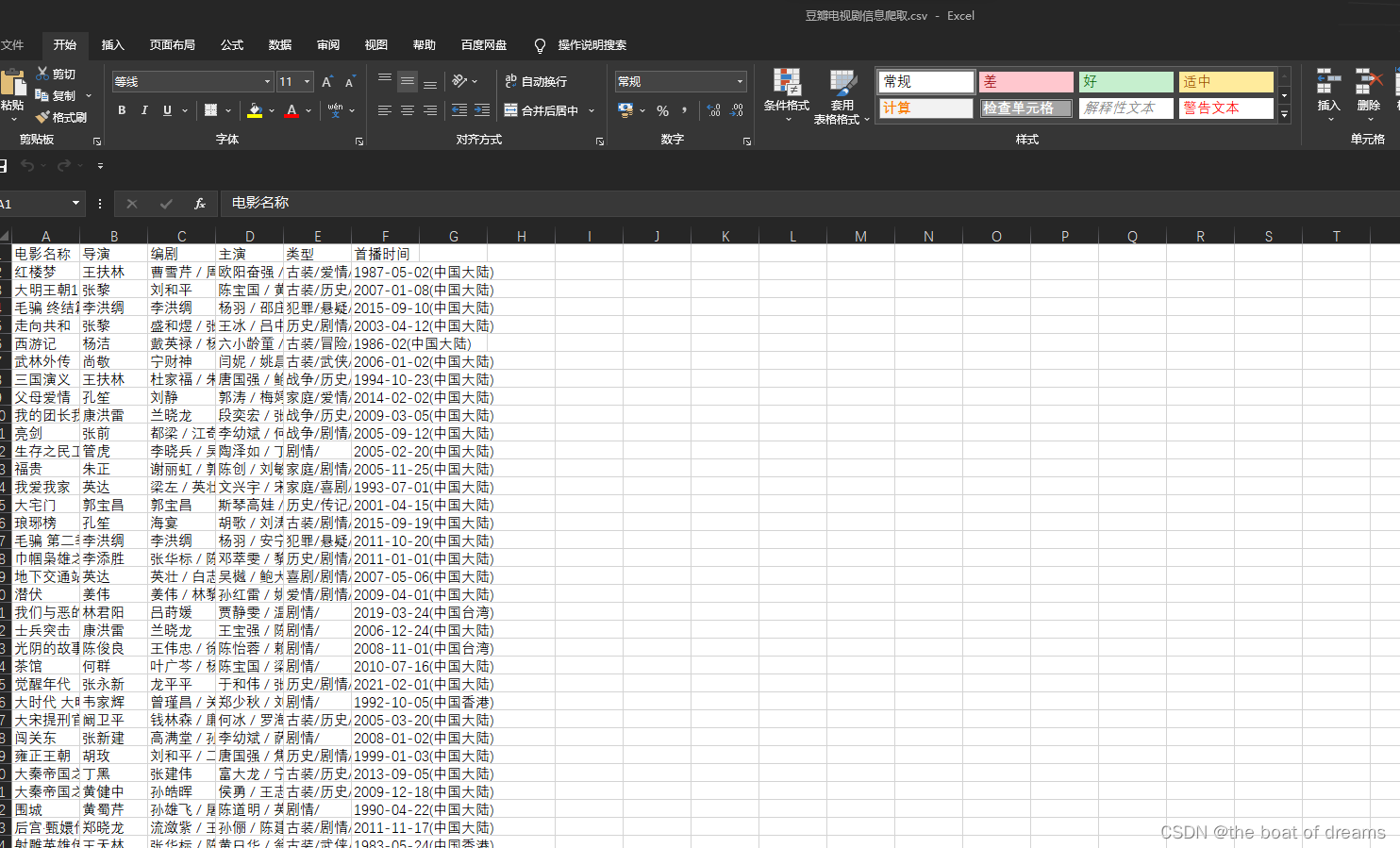
(本人能力有限,欢迎大佬们修改指正)
附上源码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import csv
import os
# 发送请求
url =""
bro = webdriver.Edge()
bro.get(url=url)
bro.maximize_window() #窗口最大化
headers=["电影名称","导演","编剧","主演","类型","首播时间"]
if not os.path.exists(r"D:\爬虫数据接收"):
os.mkdir(r"D:\爬虫数据接收")
fp = open(r"D:/爬虫数据接收/某瓣电视剧信息爬取.csv","a",encoding="utf-8-sig",newline="")
# 创建writer对象
writer = csv.writer(fp)
# 写表头
writer.writerow(headers)
while 1:
# 获取点击链接
hreflist = bro.find_elements(By.XPATH, '//div[@class="doulist-item"]//div[@class="title"]/a')
for i in hreflist:
i.click()
# 切换到新打开的界面
bro.switch_to.window(bro.window_handles[-1])
time.sleep(2)
# 电影名字
title_ele = bro.find_element(By.XPATH,'//div[@id="content"]/h1/span[1]')
title = title_ele.text
# 导演
director_ele = bro.find_element(By.XPATH, '//div[@id="content"]//div[@id="info"]/span[1]/span[@class="attrs"]/a')
director = director_ele.text
# 编剧
scriptwriter_ele = bro.find_element(By.XPATH,'//div[@id="content"]//div[@id="info"]/span[2]/span[@class="attrs"]')
scriptwriter = scriptwriter_ele.text
# 主演
actor_ele =bro.find_element(By.XPATH,'//div[@id="content"]//div[@id="info"]/span[3]/span[@class="attrs"]')
actor = actor_ele.text
# 类型
type_ele =bro.find_elements(By.XPATH,'//div[@id="content"]//div[@id="info"]/span[@property="v:genre"]')
TV_type = ""
for i in type_ele:
TV_type = i.text+"/"+TV_type
#首播
debut_ele = bro.find_element(By.XPATH,'//div[@id="content"]//div[@id="info"]/span[@property="v:initialReleaseDate"]')
debut = debut_ele.text
# 把数据存放到列表中
data = [title,director,scriptwriter,actor,TV_type,debut]
# 写内容
fp = open(r"D:\爬虫数据接收/某瓣电视剧信息爬取.csv", "a", encoding="utf-8-sig",newline="")
writer.writerow(data)
print("{}爬取完成".format(title))
fp.close()
time.sleep(2)
# 关闭当前窗口
bro.close()
# 切换到原来的页面
bro.switch_to.window(bro.window_handles[-1])
time.sleep(1)
#切换下一页
print("下一页....")
next = bro.find_element(By.XPATH,'//span[@class="next"]/a')
next.click()
本文转载自: https://blog.csdn.net/weixin_52293703/article/details/128117862
版权归原作者 the boat of dreams 所有, 如有侵权,请联系我们删除。
版权归原作者 the boat of dreams 所有, 如有侵权,请联系我们删除。