
关联比赛: CVPR2021 安全AI挑战者计划第六期:防御模型的白盒对抗攻击
CVPR2021 安全AI挑战者计划第六期赛道一第二名方案分享 (UM-SIAT队)
1.赛题简介
1.比赛通过15个防御模型测试攻击算法,其中包括13个在CIFAR-10上训练的模型和2个在ImageNet上训练的模型。
2.白盒攻击,提交的攻击算法可以获取到白盒模型的信息,但是仅仅可以获得模型的logits输出,然后在此输出的基础上设计攻击目标函数或者梯度更新方式。基于模型特征上的白盒攻击算法不被允许。
3.评测使用的是L∞范数扰动。对于CIFAR-10上的模型,对抗扰动规模是8/255,对于ImageNet上的模型,扰动规模是4/255。
4.限制提交攻击的运行时间。每个数据的平均梯度计算次数应少于100次,平均模型预测次数应少于200次。在Tesla V100 GPU上,所有模型的总运行时间应少于3小时。
5.初赛的模型是可见的,复赛和最终阶段的模型是隐藏的。
6.初赛和复赛是在CIFAR-10测试集的前1000个数据和ImageNet ILSVRC 2012验证集中随机挑选的1000个数据进行测试。最终阶段利用CIFAR-10测试集中所有的10000个数据和ImageNet中的1000个数据进行最终评测。
7.比赛中使用的深度学习框架为Tensorflow。
2.赛题分析
1.众所周知,目前很多对抗防御方法被提出以减轻对抗样本的威胁。但是,其中一些一开始认为很有效防御可以被后来更强大或更具针对性的攻击攻破,这使得很难判断和评估当前防御和未来防御的有效性,如果不能对防御模型进行全面而正确的鲁棒性评估,那么此领域的进展将受到限制。这已经充分说明了尽快解决该问题变得多么急切和重要,所以这次比赛举办的恰逢其时。
2.本次比赛限制仅仅可以获得模型的logits输出,然后在此输出的基础上设计攻击目标函数或者梯度更新方式。基于模型特征上的白盒攻击算法不被允许。这一限制对我们提出的策略影响很大,因为我们正好提出了一个利用模型特征提升白盒攻击威力的框架,这一工作已经被评为cvpr2021的oral。

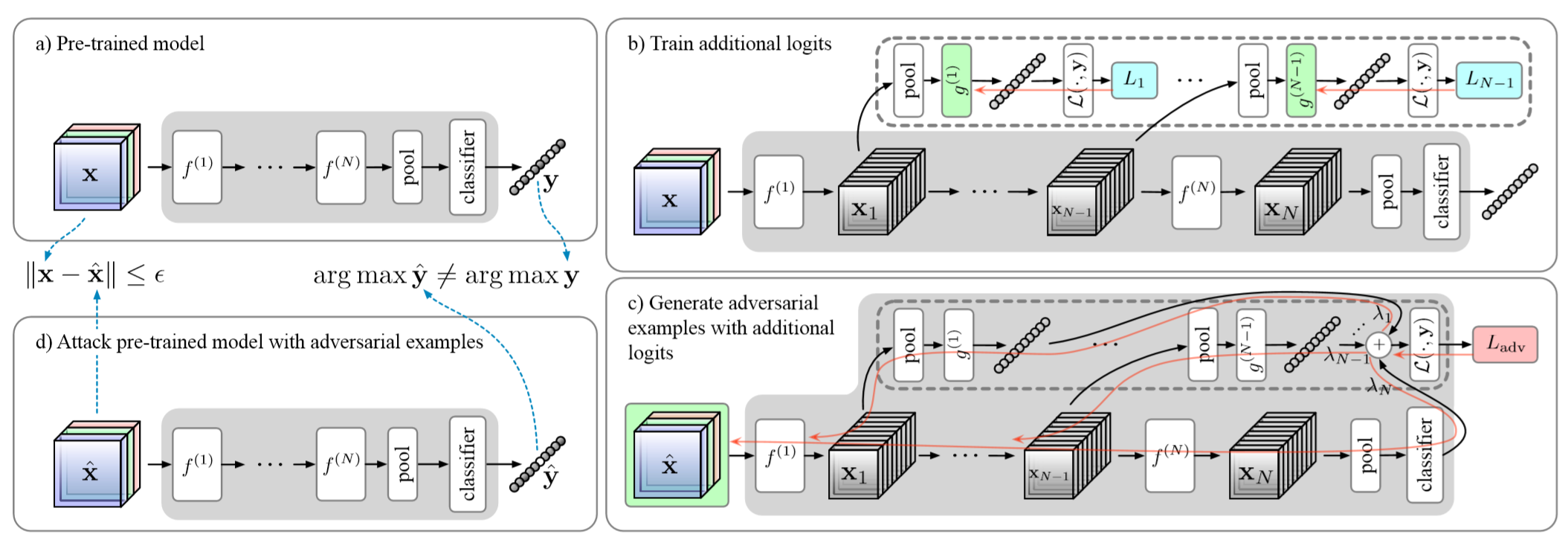
论文具体细节请参考:https://arxiv.org/abs/2104.09284
3.每个数据的平均梯度计算次数应少于100次,目前的所有攻击策略都是,迭代的次数越多效果越好,正好这次规定不是每一个数据的梯度计算次数,所以可以将很快就攻击成功的数据停止进一步的攻击,将剩余的梯度计算次数分配给那些需要迭代次数比较多的样本。
4.在Tesla V100 GPU上,所有模型的总运行时间应少于3小时,在所有模型中,最耗费时间的就是ImageNet模型,所以如果时间超出范围,就可以主动降低在ImageNet模型上的平均梯度计算次数,以降低总体的运行时间。
5.初赛的模型是可见的,这为参赛选手提供了足够的机会进行攻击策略的优化,复赛和最终阶段的模型是隐藏的,这对攻击策略的泛化能力提出了很大的考验。
6.初赛和复赛均是在CIFAR-10测试集的前1000个数据和ImageNet ILSVRC 2012验证集中随机挑选的1000个数据进行测试。而最终阶段利用CIFAR-10测试集中所有的10000个数据和ImageNet中的1000个数据进行最终评测。由于初赛和复赛参与评测的数据较少,使得评测结果与最终评测时所有数据参与评测的结果有所差异。
7.比赛中使用的深度学习框架为Tensorflow,目前学术圈不是以Pytorch为主吗?而且Tensorflow各个版本之间存在兼容的问题,如果官方比赛时的环境重新安装了或者发生了变动,使得某些函数无法实现原有的功能,比赛的结果就会收到很大的扰动,感觉把比赛的框架换成Pytorch会吸引更多的人参与这个比赛。
3.解决方案思路
1.本次比赛的梯度计算次数,所以攻击策略的收敛速度是很关键的。虽然不能使用模型特征信息使得我们很受伤,但是我们在论文里提出了新的损失函数,收敛速度远超Autoattack中的dlr_loss。
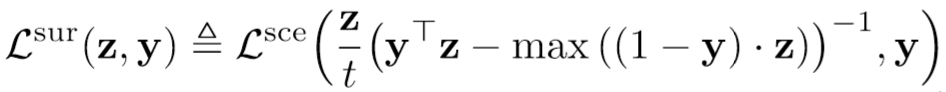
2.我们将模型分为两类,一类是不管是使用什么类型的攻击方法进行攻击,模型(以trades模型为例)的鲁棒性均不会大幅度改变,另一类模型则是在不同类型的攻击方法进行攻击的情况下,模型(以feature scatter模型为例)的鲁棒性会发生很大的变动,模型的鲁棒性直接减半甚至几乎为0。针对这两类模型的攻击策略应该有所区分。
3.步长的调整策略很关键,定长的步长并不是一个很好的选择,我们在论文中已经验证了linear_decay策略的有效性。
4.集成的攻击效果会更好,如何在平均梯度计算次数应少于100次的前提下进行集成是一个不小的考验。
5.保证攻击策略的泛化能力需要确保攻击策略对超参数不敏感,同时确保攻击策略在不同类型的模型上均有好的效果。
4.方案细节
1.首先是,在每次攻击之前,我们都会判定,参与攻击的样本是否已经成功使得模型预测出错,如果犯错则说明,该攻击已经成功,对于该输入样本的攻击则会停止。将剩余的梯度计算次数让给还未攻击成功的样本。
2.除了我们自己提出的新的损失函数,我们在攻击过程中也引入了dlr_loss,一是为了增加一些攻击扰动的多样性,最重要的则是我们要用dlr_loss攻击的结果,自适应的将模型区分为两类,之后针对不同的分类结果调用不同的后续攻击策略。这么做的主要原因就是我们自己的损失函数收敛速度快,在untarget版本的攻击下仅需要10轮迭代便可使得模型的鲁棒性下降过程趋于稳定,对于鲁棒性变动不大的模型,使用dlr_loss的top3 target版本,每个target赋予10次迭代,进行攻击不会带来很大的收益,对于鲁棒性变化很大的模型,使用dlr_loss的top3 target版本进行攻击则会使得模型的鲁棒性大幅的下降,利用这个特点,我们设计了自适应的区分不同类型的模型的策略。这个策略能不能被触发就完全取决于复赛中有没有鲁棒性变动很大的模型了。
3.针对区分出来的鲁棒性变动不大的模型,我们会将剩余的所有梯度计算次数给我们提出的新的损失函数的untarget版本进行攻击。针对区分出来的鲁棒性变化很大的模型,我们将剩余的梯度计算次数均分到我们提出的新的损失函数的top10 multitarget进行攻击。
4.由于我们使用了集成,会对同一个数据进行不同的target进行攻击,为了充分使用之前攻击的扰动,我们设计了,下一个target的攻击会在保留之前扰动的基础上进行,采用了这个策略之后,我们就完全没有使用随机噪声和动量。
5.步长的调整,我们使用了linear, cos, cosine三个版本的衰减策略,然后在三种策略中进行搜索,匹配出效果最稳定的版本,最终我们使用的为按照cos规律衰减的版本。
6.我们为了确保攻击策略对超参数不敏感,在搜索不同的组合的时候,特意选择了最终结果在不同的超参数下面比较稳定的版本。
5.致谢
感谢阿里举办的本次比赛,祝愿比赛越办越好,影响力越来越高。
查看更多内容,欢迎访问天池技术圈官方地址:CVPR2021 安全AI挑战者计划第六期赛道一第二名方案分享 (UM-SIAT队)_天池技术圈-阿里云天池
版权归原作者 阿里云天池 所有, 如有侵权,请联系我们删除。