
一、hadoop有三种运行模式
1、本地模式
数据存储在linux本地,不用
2、伪分布式集群
数据存储在HDFS,测试用
3、完全分布式集群
数据存储在HDFS,同时多台服务器工作。企业大量使用
二、单机运行
单机运行就是直接执行hadoop命令
1、例子-统计单词数量
cd /appserver/hadoop/hadoop-3.3.4
mkdir wcinput
mkdir outinput
在wcinput下建立一个word.txt,输入一些单词
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount wcinput/ wcoutput/
三、ssh免密登录
ssh-keygen生成本机的公私钥对。ssh-copy-id将本机公钥安装到远程主机上,实现免密登录远程主机
四、单机伪集群安装
见上一篇
五、集群部署规划
1、NameNode和SecondaryNameNode不要安装在同一台服务器。
2、ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
hadoop101hadoop102hadoop103HDFS
NameNode
DataNode
DataNode
SecondaryNameNode
DataNode
YARN
NodeManager
ResourceManager
NodeManager
NodeManager
3、配置文件配置
Hadoop配置文件分为两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值
(1)默认配置文件
默认的四大配置文件存放位置core-default.xmlhadoop-common-3.x.x.jar/core-default.xmlhdfs-default.xmlhadoop-hdfs-3.x.x.jar/hdfs-default.xmlyarn-default.xmlhadoop-yarn-common-3.x.x.jar/yarn-default.xmlmapred-default.xmlhadoop-mapreduce-client-core-3.x.x.jar/mapred-default.xml
(2)自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置
(3)workers配置文件
配置集群,把所有节点添加进去
六、NameNode初始化
1、如果是第一次启动集群,需要进行初始化操作,在hadoop101节点上格式化NameNode。(类似于电脑新加了一个硬盘,需要给硬盘进行分盘符等初始化操作)。
2、如果多次格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止NameNode和DataNode的进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
七、查看HDFS上存储的数据
http://192.168.1.1:9870/,访问Browse the file system
八、查看Yarn上运行的Job
九、测试
1、在hdfs创建一个目录
cd /appserver/hadoop/hadoop-3.3.4/bin
./hadoop fs -mkdir /wcinput
2、上传一个文件
./hadoop fs -put /tmp/aa.txt /wcinput
3、点下载文件报错
Couldn't preview the file. NetworkError: Failed to execute 'send' on 'XMLHttpRequest': Failed to load 'http://localhost:9864/webhdfs/v1/wcinput/aa.txt?op=OPEN&namenoderpcaddress=hadoop001:8020&offset=0&_=1675238533732'.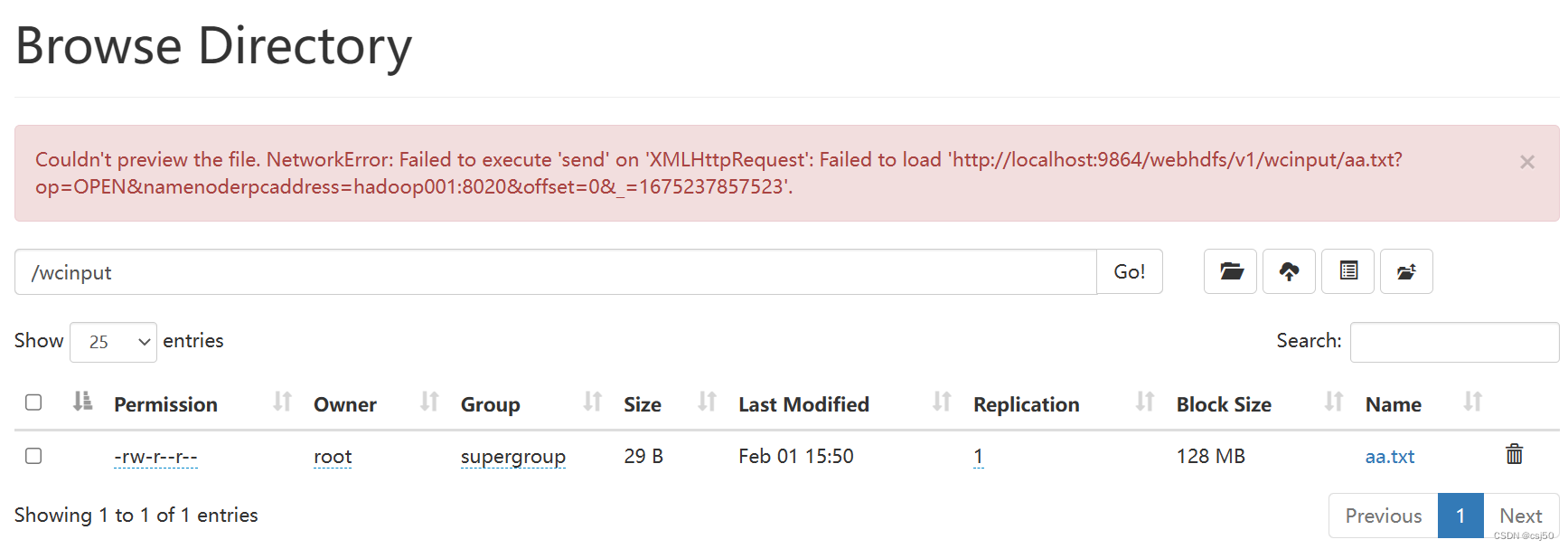
解决办法:检查/etc/hosts下主机名配置,关闭hdfs、yarn,重启服务器,就好了。。。
这里的Availability本来是localhost,重启后变成hadoop001。(PS:访问的电脑本机也要配置好hosts,加上节点和IP)
4、文件存储位置
在/appserver/hadoop/datanode/data/current/BP-1427885282-127.0.0.1-1675234871384/current/finalized/subdir0/subdir0目录下
-rw-r--r--. 1 root root 29 2月 1 15:50 blk_1073741825
-rw-r--r--. 1 root root 11 2月 1 15:50 blk_1073741825_1001.meta
[root@hadoop001 subdir0]# cat blk_1073741825
aa
bb ce
bobo
tom
aa
bobo
aa
5、执行wordcount程序
看看yarn是怎么工作的
cd /appserver/hadoop/hadoop-3.3.4
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /wcinput /wcoutput
报错了:
2023-02-01 17:25:44,177 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop001/192.168.0.3:8032
2023-02-01 17:25:44,435 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1675239930166_0002
2023-02-01 17:25:45,103 INFO input.FileInputFormat: Total input files to process : 1
2023-02-01 17:25:46,136 INFO mapreduce.JobSubmitter: number of splits:1
2023-02-01 17:25:46,692 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1675239930166_0002
2023-02-01 17:25:46,692 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-02-01 17:25:46,803 INFO conf.Configuration: resource-types.xml not found
2023-02-01 17:25:46,803 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-02-01 17:25:47,171 INFO impl.YarnClientImpl: Submitted application application_1675239930166_0002
2023-02-01 17:25:47,191 INFO mapreduce.Job: The url to track the job: http://hadoop001:8088/proxy/application_1675239930166_0002/
2023-02-01 17:25:47,192 INFO mapreduce.Job: Running job: job_1675239930166_0002
2023-02-01 17:25:50,231 INFO mapreduce.Job: Job job_1675239930166_0002 running in uber mode : false
2023-02-01 17:25:50,232 INFO mapreduce.Job: map 0% reduce 0%
2023-02-01 17:25:50,241 INFO mapreduce.Job: Job job_1675239930166_0002 failed with state FAILED due to: Application application_1675239930166_0002 failed 2 times due to AM Container for appattempt_1675239930166_0002_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2023-02-01 17:25:49.755]Exception from container-launch.
Container id: container_1675239930166_0002_02_000001
Exit code: 1
[2023-02-01 17:25:49.757]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
[2023-02-01 17:25:49.760]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
For more detailed output, check the application tracking page: http://hadoop001:8088/cluster/app/application_1675239930166_0002 Then click on links to logs of each attempt.
. Failing the application.
2023-02-01 17:25:50,252 INFO mapreduce.Job: Counters: 0
解决办法:
bin/hadoop classpath
/appserver/hadoop/hadoop-3.3.4/etc/hadoop:/appserver/hadoop/hadoop-3.3.4/share/hadoop/common/lib/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/common/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/hdfs:/appserver/hadoop/hadoop-3.3.4/share/hadoop/hdfs/lib/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/hdfs/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/mapreduce/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/yarn:/appserver/hadoop/hadoop-3.3.4/share/hadoop/yarn/lib/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/yarn/*
将路径加入yarn-site.xml:
<property>
<name>yarn.application.classpath</name>
<value>/appserver/hadoop/hadoop-3.3.4/etc/hadoop:/appserver/hadoop/hadoop-3.3.4/share/hadoop/common/lib/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/common/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/hdfs:/appserver/hadoop/hadoop-3.3.4/share/hadoop/hdfs/lib/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/hdfs/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/mapreduce/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/yarn:/appserver/hadoop/hadoop-3.3.4/share/hadoop/yarn/lib/*:/appserver/hadoop/hadoop-3.3.4/share/hadoop/yarn/*</value>
</property>
重启yarn:
yarn --daemon stop resourcemanager
yarn --daemon stop nodemanager
yarn --daemon start resourcemanager
yarn --daemon start nodemanager
执行成功:
2023-02-01 17:40:08,122 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at hadoop001/192.168.0.3:8032
2023-02-01 17:40:08,390 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1675244388030_0001
2023-02-01 17:40:09,045 INFO input.FileInputFormat: Total input files to process : 1
2023-02-01 17:40:09,275 INFO mapreduce.JobSubmitter: number of splits:1
2023-02-01 17:40:09,833 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1675244388030_0001
2023-02-01 17:40:09,834 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-02-01 17:40:09,943 INFO conf.Configuration: resource-types.xml not found
2023-02-01 17:40:09,944 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-02-01 17:40:10,106 INFO impl.YarnClientImpl: Submitted application application_1675244388030_0001
2023-02-01 17:40:10,162 INFO mapreduce.Job: The url to track the job: http://hadoop001:8088/proxy/application_1675244388030_0001/
2023-02-01 17:40:10,162 INFO mapreduce.Job: Running job: job_1675244388030_0001
2023-02-01 17:40:16,271 INFO mapreduce.Job: Job job_1675244388030_0001 running in uber mode : false
2023-02-01 17:40:16,273 INFO mapreduce.Job: map 0% reduce 0%
2023-02-01 17:40:19,311 INFO mapreduce.Job: map 100% reduce 0%
2023-02-01 17:40:23,337 INFO mapreduce.Job: map 100% reduce 100%
2023-02-01 17:40:25,359 INFO mapreduce.Job: Job job_1675244388030_0001 completed successfully
2023-02-01 17:40:25,416 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=54
FILE: Number of bytes written=552301
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=130
HDFS: Number of bytes written=28
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=1397
Total time spent by all reduces in occupied slots (ms)=1565
Total time spent by all map tasks (ms)=1397
Total time spent by all reduce tasks (ms)=1565
Total vcore-milliseconds taken by all map tasks=1397
Total vcore-milliseconds taken by all reduce tasks=1565
Total megabyte-milliseconds taken by all map tasks=1430528
Total megabyte-milliseconds taken by all reduce tasks=1602560
Map-Reduce Framework
Map input records=7
Map output records=8
Map output bytes=61
Map output materialized bytes=54
Input split bytes=101
Combine input records=8
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=54
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=62
CPU time spent (ms)=540
Physical memory (bytes) snapshot=567222272
Virtual memory (bytes) snapshot=5580062720
Total committed heap usage (bytes)=479199232
Peak Map Physical memory (bytes)=329158656
Peak Map Virtual memory (bytes)=2786742272
Peak Reduce Physical memory (bytes)=238063616
Peak Reduce Virtual memory (bytes)=2793320448
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=29
File Output Format Counters
Bytes Written=28
6、查看结果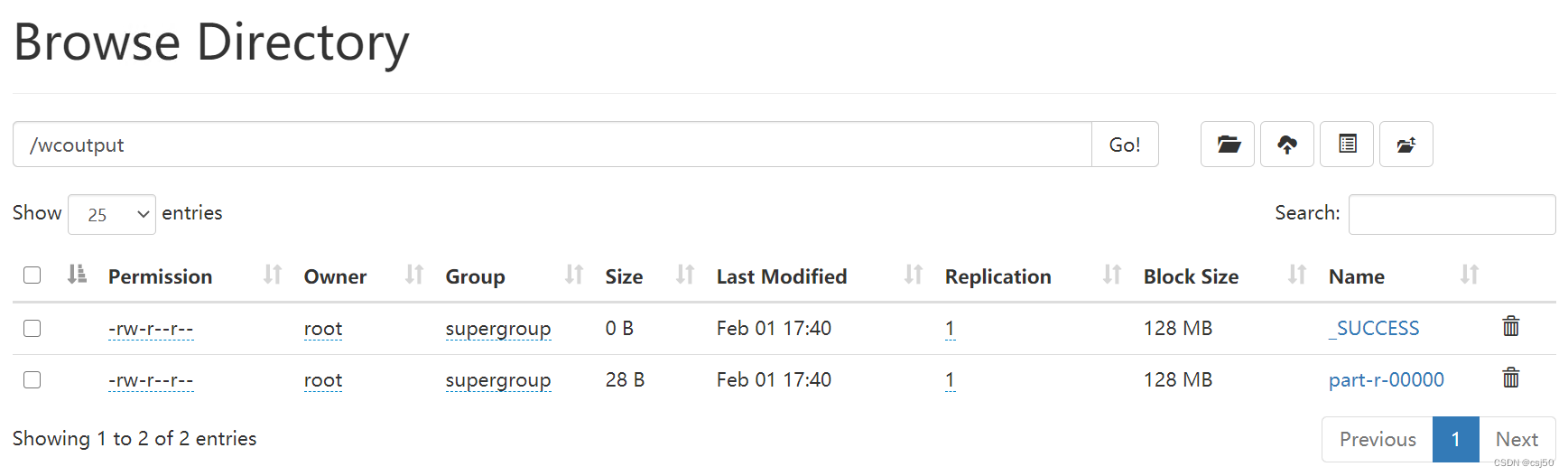
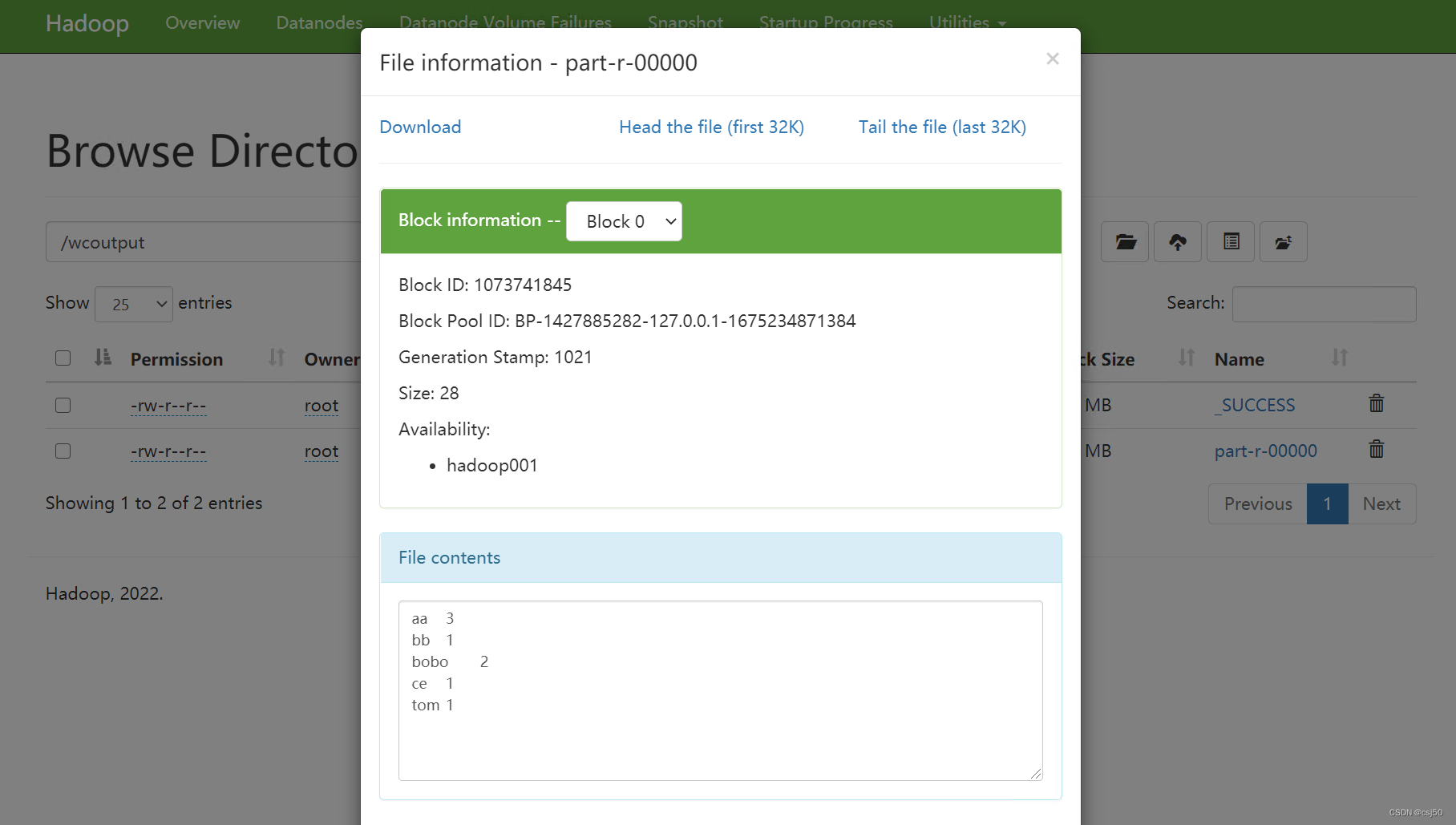
十、历史服务器和日志归集
1、历史服务器可以查看程序的历史运行情况。
2、日志归集
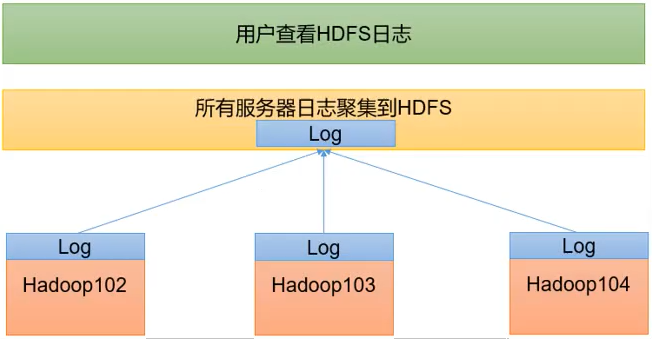
日志聚集:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
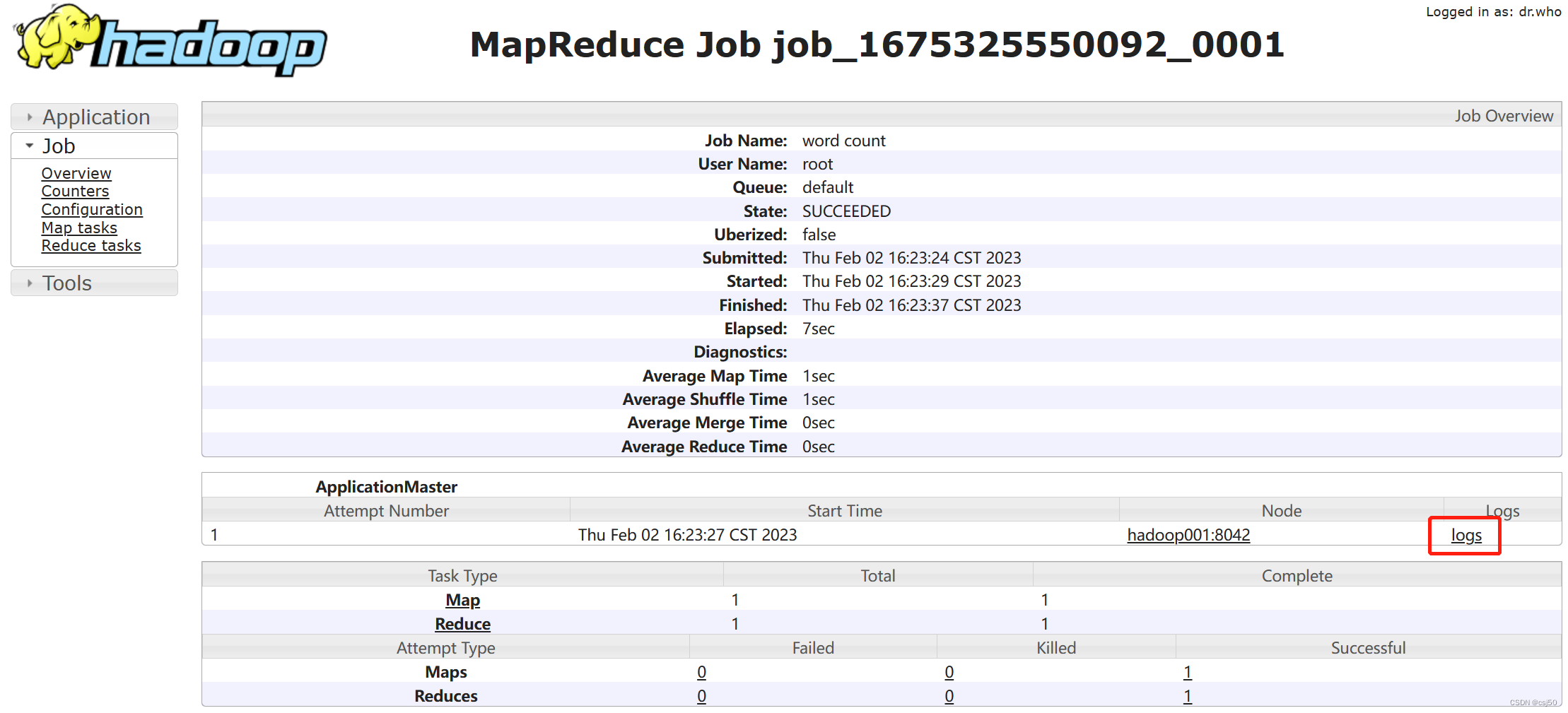
我们配置的历史服务器虽然可以查看到历史 job 的运行信息,但是如果点击后面的logs链接查看其详细日志,却无法查看,提示 Aggregation is not enabled.(日志聚集功能未开启)。
我们开启了日志聚集功能后,可以很方便的查看程序运行详情,方便开发调试。
开启日志聚集功能,需要重新启动 NodeMananger、ResourceMananger、HistoryServer。
3、配置、重启好服务后,删除wcoutput目录,重新执行任务
hadoop fs -rm -f -r /wcoutput
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /wcinput /wcoutput
版权归原作者 csj50 所有, 如有侵权,请联系我们删除。