
1、有哪些分布式数据库
一、PG-XC 风格:
由传统分库分表演进而来,再加上额外的调度节点实现分片路由、全局时钟实现分布式事务,基本构成了一个分布式数据库。
• 中兴的 GoldenDB
• 华为的 GaussDB
• 腾讯的 TDSQL
二、NewSQL 风格:
数据库中的每个组件都采用分布式设计,底层存储多采用键值(KV)系统,同时引入多数派选举算法实现多副本同步,存储、计算、调度完全分离。
• 国外的 CockroachDB、YugabyteDB
• PingCAP 的 TiDB
• 蚂蚁的 OceanBase
三、云原生数据库:
• AWS 的 Aurora
• 微软的 Cosmos DB
• 阿里的 PolarDB
参考:什么是分布式数据库?我不信,看完这篇你还不懂!! - 知乎
2、OLAP、OLTP、HTAP
数据处理大致可以分成两大类:
联机事务处理 OLTP(On-Line Transaction Processing)
OLTP 的场景如电商场景中加购物车、下单、支付等需要在原地进行大量insert、update、delete操作
联机分析处理 OLAP(On-Line Analytical Processing)
OLAP 场景通常是将数据批量导入后,进行任意维度的灵活探索、BI工具洞察、报表制作等
混合事务和分析处理 HTAP(Hybrid Transaction and Analytical Process)
同时支持在线事务处理与在线分析处理的融合型数据库。
3、TIDB、clickhouse、hive
一、TIDB
官网:https://docs.pingcap.com/zh/ (以下内容摘自官网介绍)
参考:15分钟了解TiDB_D_Guco的博客-CSDN博客_tidb
TiDB 是 PingCAP 公司研发的分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 的融合型分布式数据库产品,目标是为用户提供一站式 OLTP、OLAP、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
1. TiDb 核心特性:
- 支持水平扩容或者缩容
TiDB 存储计算分离的架构设计,可按需对计算、存储分别进行扩容或者缩容。
- 金融级高可用
数据采用多副本存储,数据副本通过 Multi-Raft 协议同步事务日志,多数派写入成功事务才能提交,确保数据强一致性且少数副本发生故障时不影响数据的可用性。
- 实时 HTAP
提供行存储引擎 TiKV、列存储引擎 TiFlash 两款存储引擎,TiFlash 通过 Multi-Raft Learner 协议实时从 TiKV 复制数据,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。
- 云原生的分布式数据库
专为云而设计的分布式数据库,通过 TiDB Operator 可在公有云、私有云、混合云中实现部署工具化、自动化。
- 兼容 MySQL 5.7 协议和 MySQL 生态
2. TiDb 整体架构:

TiDB Server:SQL 层,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)
PD Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。
Storage Server:数据存储。
TiKV Server:负责存储数据,从外部看 TiKV 是一个 Key-Value 存储引擎。存储数据的基本单位是 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。
TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
简化为 PD -> TiDB -> TiKV 的架构:

3.TiDB 存储:
① 存储数据结构: Key-Value Pairs(键值对):TiKV 选择的是 Key-Value 模型,并且提供有序遍历方法。
② 数据落盘方式: 本地存储 (RocksDB):TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责(RocksDB 是由 Facebook 开源的一个非常优秀的单机 KV 存储引擎)。
③ 数据同步协议:Raft 协议:TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到复制组的每一个节点中。
④ 分布式存储解决方案:Region:以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上 Region 的数量差不多;以 Region 为单位做 Raft 的复制和成员管理。

二、clickhouse
参考:ClickHouse深度揭秘 - 知乎
ClickHouse 是一整套完善的解决方案,它自包含了 存储 和 计算能力,完全自主实现了高可用,而且支持完整的 SQL 语法。相比于 hadoop 体系,以数据库的方式来做大数据处理更加简单易用,学习成本低且灵活度高。
ClickHouse 的技术优势:
- 极致的查询性能;
- 低成本的海量存储: 列存、压缩,大幅提升单机数据存储和计算能力,大幅降低使用成本;
- 简单灵活且强大:完善 SQL 支持;提供 json、map、array 等数据类型;支持近似计算、概率数据结构等。
clickhouse 优势体现在 OLAP 场景
OLAP 场景的特点:
1、读多于写:数据分析通常是数据一次性写入后,分析师尝试从各个角度对数据做挖掘、分析,直到发现其中的商业价值、业务变化趋势等信息。
2、大宽表,读大量行但仅需少量列:数据分析时,选择其中的少数几列作为维度列、其他少数几列作为指标列,然后对全表或某一较大范围内的数据做聚合计算。这个过程会扫描大量的行数据,但是只用到了其中的少数列。
3、数据批量写入,且数据不更新或少更新:OLAP类业务数据量非常大,通常更加关注写入吞吐(Throughput),要求海量数据能够尽快导入完成。
4、无需事务,数据一致性要求低:OLAP类业务对于事务需求较少,通常是导入历史日志数据。
针对 OLAP 场景,clickhouse 的优势特点:
1、数据有序存储:ClickHouse 支持在建表时,指定将数据按照某些列进行 sort by。排序后相同 sort key 的数据在磁盘上连续存储,有序摆放。查询时命中的数据都紧密存储在一个或若干个连续的Block 中,大幅减少 IO,提高查询性能。
2、主键索引:ClickHouse 支持主键索引,它将数据按照 index granularity(默认8192行)进行划分,每个 index granularity 的开头第一行被称为 mark 行。主键索引存储该 mark 行对应的值。对于where 条件中含有主键索引的查询,通过对主键索引进行二分查找,减少查询时间。
3、有限支持delete、update:ClickHouse 没有直接支持delete、update操作。
4、列式存储:一条数据以列的形式存储,同一行为多条数据的同一个字段数据。同一字段的数据顺序存储到在一个或邻近的 block 中,对于大宽表的情况能减少 IO。
5、高吞吐写入能力:ClickHouse 在数据导入时全部是顺序写。
6、数据 Sharding:ClickHouse 支持单机模式,也支持分布式集群模式。
7、数据 Partitioning:ClickHouse 可以指定按照任意合法表达式进行数据分区操作。
三、hive
官网:Apache Hive
参考1:https://blog.csdn.net/l1212xiao/article/details/80432759
参考2:Hive是什么?_Apache Hive数据仓库介绍-AWS云服务
参考3:Hive架构及原理 - 知乎
1.什么是 Hive?
Apache Hive 是建立在 Apache Hadoop 基础之上,可实现大规模分析的分布式容错数据仓库系统。Hive 可以将结构化的数据文件映射为一张数据库表,让用户可以利用 SQL 读取、写入和管理 PB 级数据。
2.Hive 架构和如何运作?
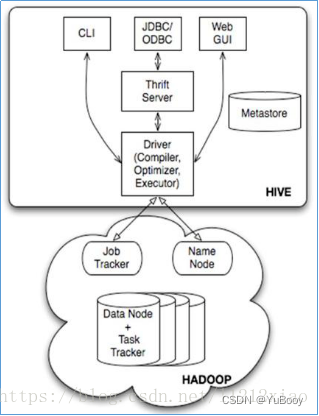
Jobtracker 是 hadoop1.x 中的组件,它的功能相当于: Resourcemanager + AppMaster
TaskTracker 相当于: Nodemanager + yarnchild
· Hive 旨在让非程序员熟悉 SQL,并使用名为 HiveQL 的类似于 SQL 的界面对 PB 级数据进行操作。
**· **传统关系数据库被用于对中小型数据集进行交互式查询,它在处理大型数据集时的表现并不理想。但 Hive 使用批处理,因此它可以快速操作非常大型的分布式数据库。
**· **Hive 会将 HiveQL 查询转换成在 Apache Hadoop 的分布式作业计划框架,即 Yet Another Resource Negotiator (YARN) 上运行的 MapReduce 或 Tez 作业。它会查询存储在分布式存储解决方案,如 Hadoop 分布式文件系统 (HDFS) 或 Amazon S3 当中的数据。
**· **Hive 将表元数据存储在数据库中,元数据包括(表名、表所属的数据库名、 表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等)。

版权归原作者 YuBooy 所有, 如有侵权,请联系我们删除。