
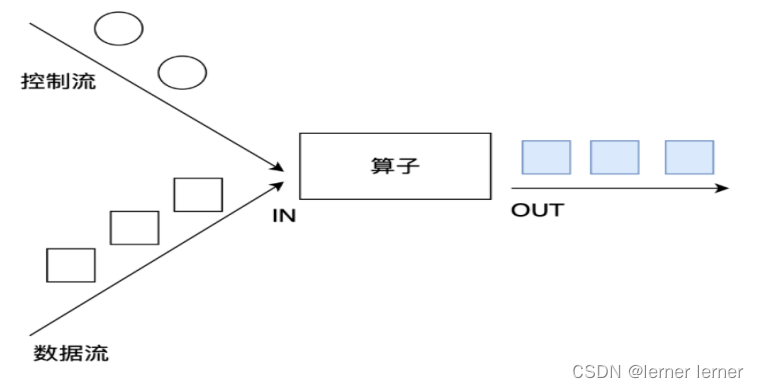
以下所有内容是对黑马程序员的FLINK PPT的整理
一、
Flink组件栈
- Runtime核心层:Runtime层提供了支持Flink计算的全部核心实现,为上层API层提供基础服务,该层主要负责对上层不同接口提供基础服务,也是Flink分布式计算框架的核心实现层,支持分布式Stream作业的执行、JobGraph到ExecutionGraph的映射转换、任务调度等。将DataSteam和DataSet转成统一的可执行的Task Operator,达到在流式引擎下同时处理批量计算和流式计算的目的。
- API&Libraries层:Flink 首先支持了 Scala 和 Java 的 API,Python 也正在测试中。DataStream、DataSet、Table、SQL API,作为分布式数据处理框架,Flink同时提供了支撑计算和批计算的接口,两者都提供给用户丰富的数据处理高级API,例如Map、FlatMap操作等,也提供比较低级的Process Function API,用户可以直接操作状态和时间等底层数据。
- 扩展库:Flink 还包括用于复杂事件处理的CEP,机器学习库FlinkML,图处理库Gelly等。Table 是一种接口化的 SQL 支持,也就是 API 支持(DSL),而不是文本化的SQL 解析和执行。
Flink基石
- Checkpoint 基于Chandy-Lamport算法,实现可分布式一致性快照,提供了一致性的语义。
- State 丰富的State API,ValueState,ListState,MapState,BroadcastState。
- Time 实现了Watermark机制。乱序数据处理,迟到数据容忍。
- Window 开箱即用的滚动、滑动、会话窗口,以及灵活的自定义窗口
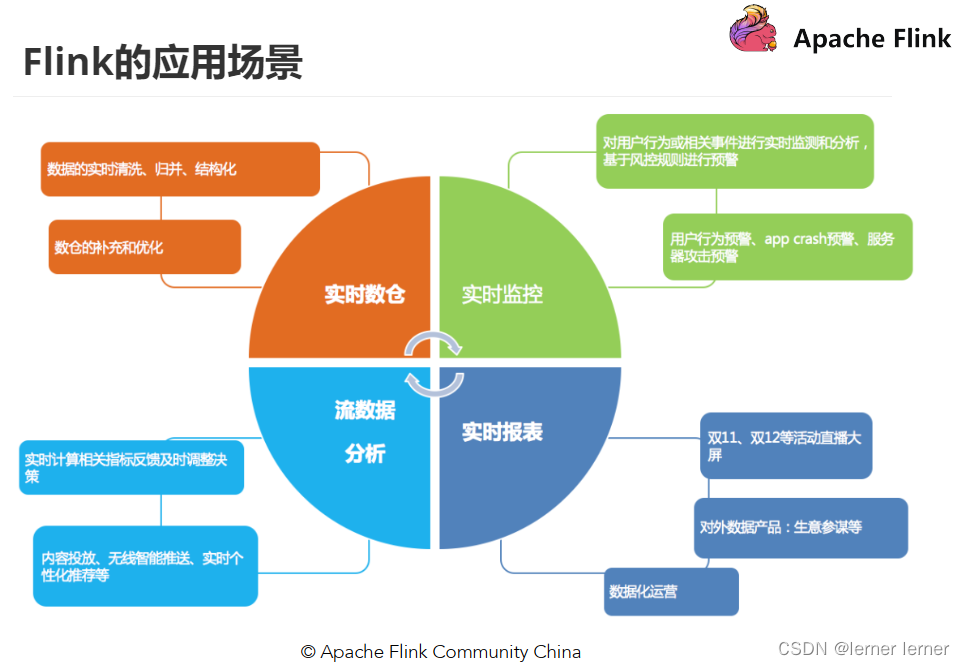
Flink应用场景
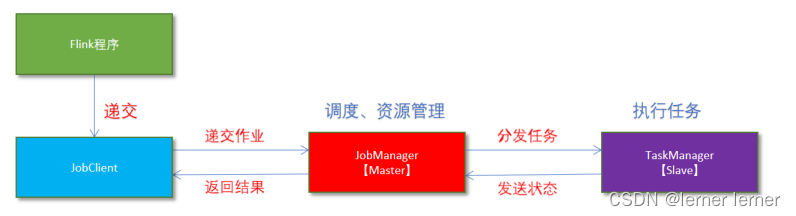
Flink local模式(很少使用)原理:
- Flink程序由JobClient进行提交。
- JobClient将作业提交给JobManager。
- JobManager负责协调资源分配和作业执行。资源分配完成后,任务将提交给相应的TaskManager。
- TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改,如开始执行,正在进行或已完成。
- 作业执行完成后,结果将发送回客户端(JobClient)。
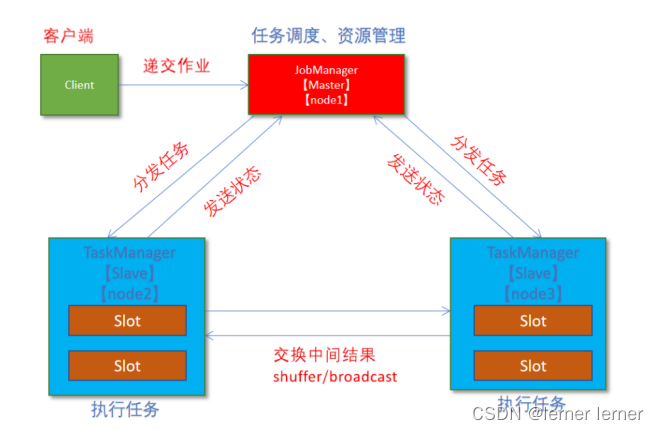
Standalone独立集群模式原理:
- client客户端提交任务给JobManager
- JobManager负责申请任务运行所需要的资源并管理任务和资源,
- JobManager分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
standalone-HA高可用(测试环境)集群模式
通过zookeeper实现主从节点切换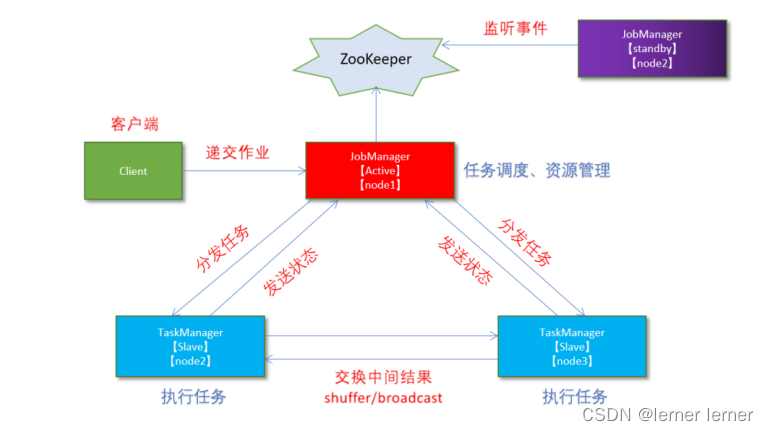

Flink On Yarn模式(生产环境)原理
-1.Yarn的资源可以按需使用,提高集群的资源利用率
-2.Yarn的任务有优先级,根据优先级运行作业
-3.基于Yarn调度系统,能够自动化地处理各个角色的 Failover(容错)
○ JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控
○ 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器
○ 如果TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager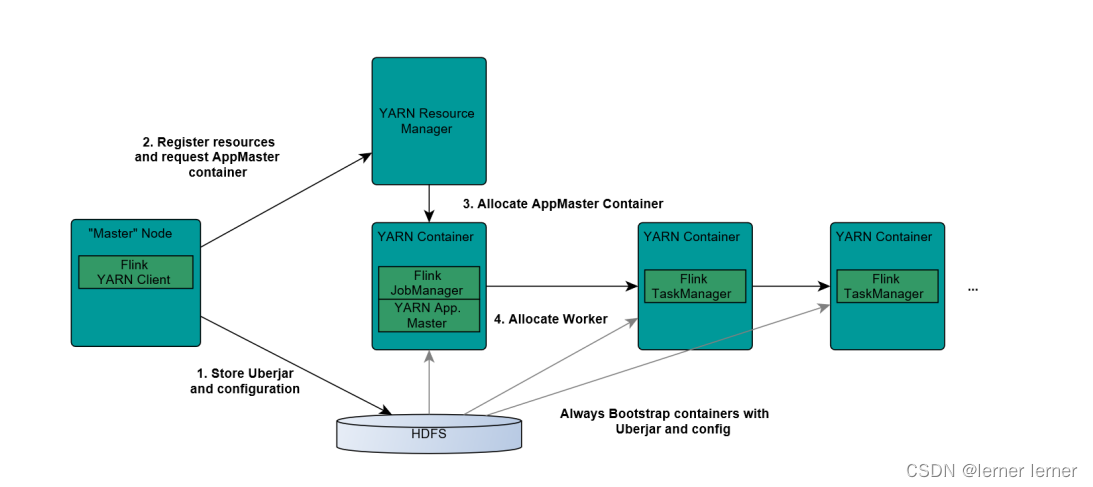
1.Client上传jar包和配置文件到HDFS集群上
2.Client向Yarn ResourceManager提交任务并申请资源
3.ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager
JobManager和ApplicationMaster运行在同一个container上。
一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器)。
它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。
这个配置文件也被上传到HDFS上。
此外,AppMaster容器也提供了Flink的web服务接口。
YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink
4.ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
5.TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务
Dataflow,Operator,Partition,Subtask,Parallelism
1.Dataflow:Flink程序在执行的时候会被映射成一个数据流模型
2.Operator:数据流模型中的每一个操作被称作Operator,Operator分为:Source/Transform/Sink
3.Partition:数据流模型是分布式的和并行的,执行中会形成1~n个分区
4.Subtask:多个分区任务可以并行,每一个都是独立运行在一个线程中的,也就是一个Subtask子任务
5.Parallelism:并行度,就是可以同时真正执行的子任务数/分区数
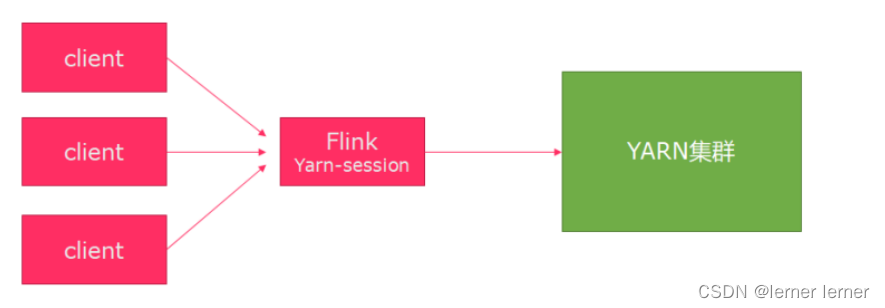
- Session模式 特点:需要事先申请资源,启动JobManager和TaskManger 优点:不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提高执行效率 缺点:作业执行完成以后,资源不会被释放,因此一直会占用系统资源 应用场景:适合作业递交比较频繁的场景,小作业比较多的场景
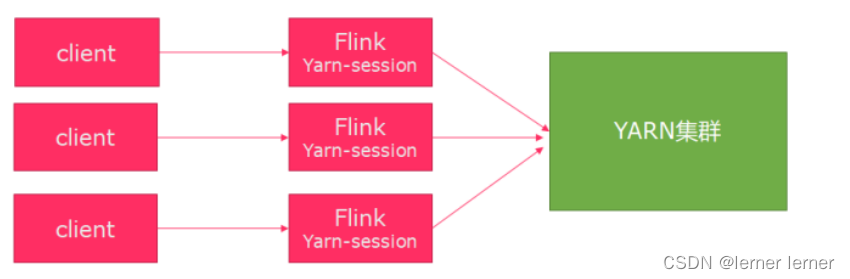
- Per-Job模式 特点:每次递交作业都需要申请一次资源 优点:作业运行完成,资源会立刻被释放,不会一直占用系统资源 缺点:每次递交作业都需要申请资源,会影响执行效率,因为申请资源需要消耗时间 应用场景:适合作业比较少的场景、大作业的场景
 进入node1:8088/cluster后,点击一个任务,进去可以看到jobmanger和taskmanager
进入node1:8088/cluster后,点击一个任务,进去可以看到jobmanger和taskmanager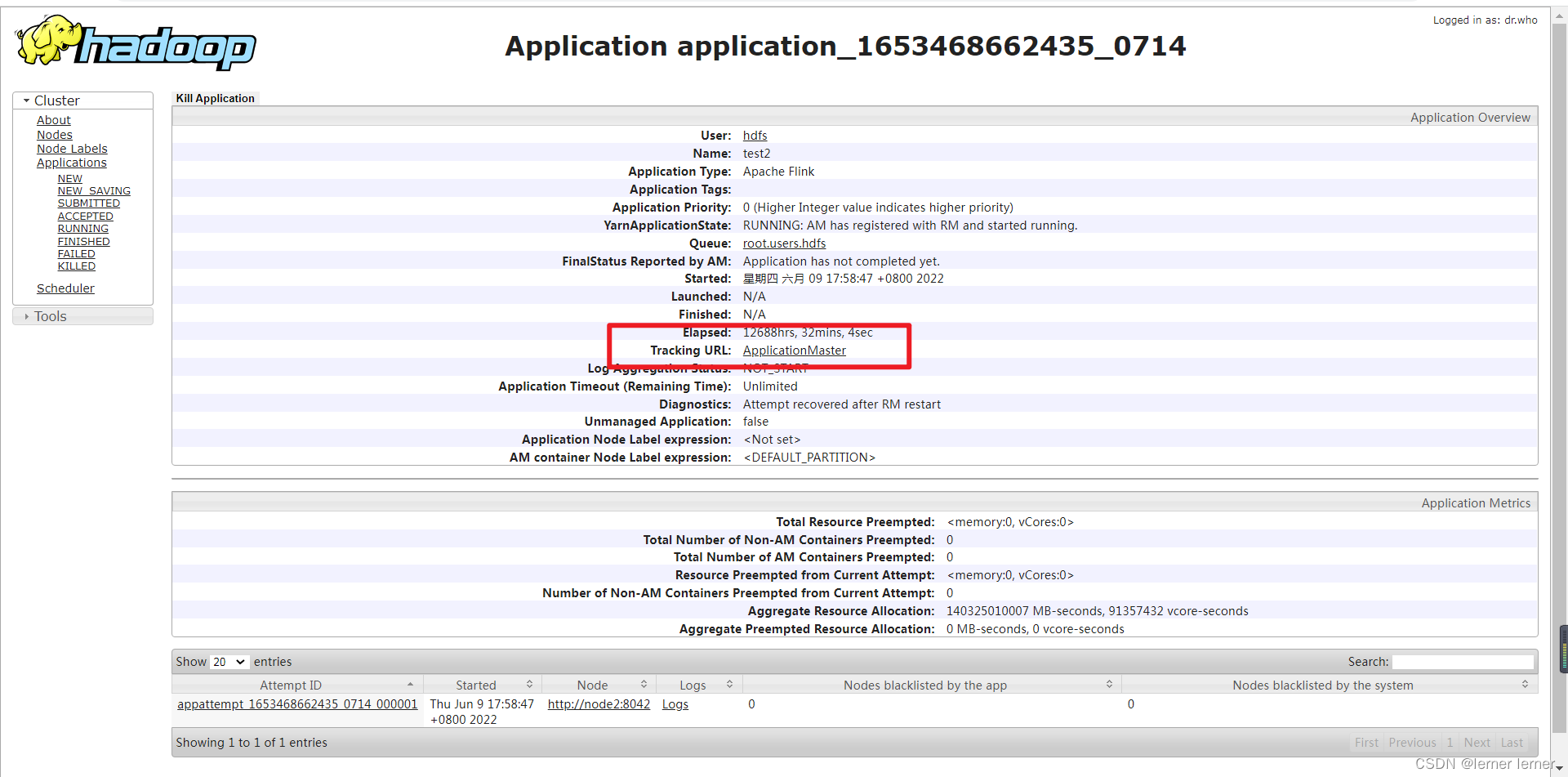
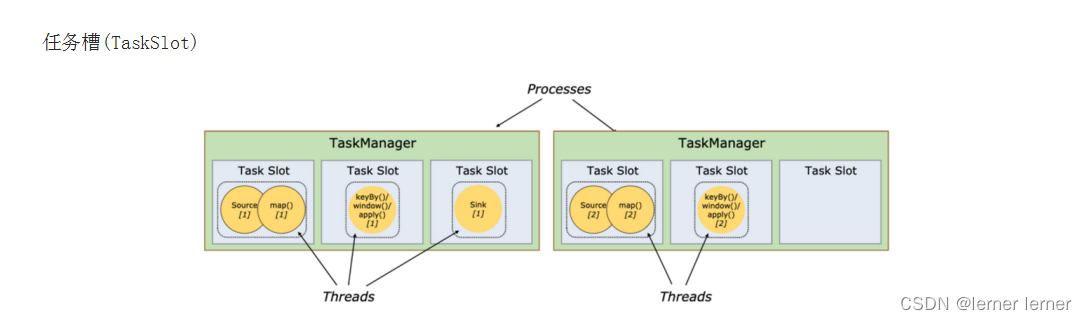
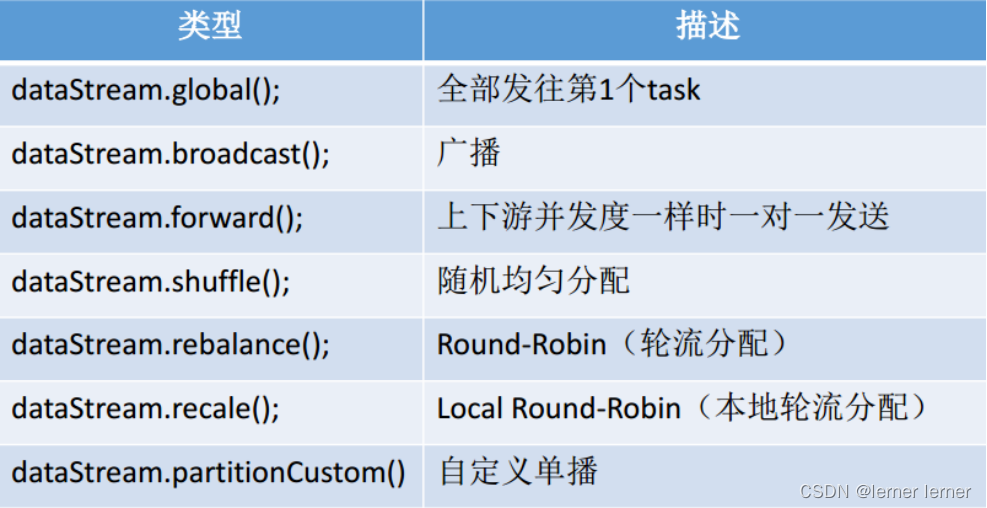
Operator传递模式
数据在两个operator(算子)之间传递的时候有两种模式:
1.One to One模式:
两个operator用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的Source1到Map1,它就保留的Source的分区特性,以及分区元素处理的有序性。–类似于Spark中的窄依赖
2.Redistributing 模式:
这种模式会改变数据的分区数;每个一个operator subtask会根据选择transformation把数据发送到不同的目标subtasks,比如keyBy()会通过hashcode重新分区,broadcast()和rebalance()方法会随机重新分区。–类似于Spark中的宽依赖
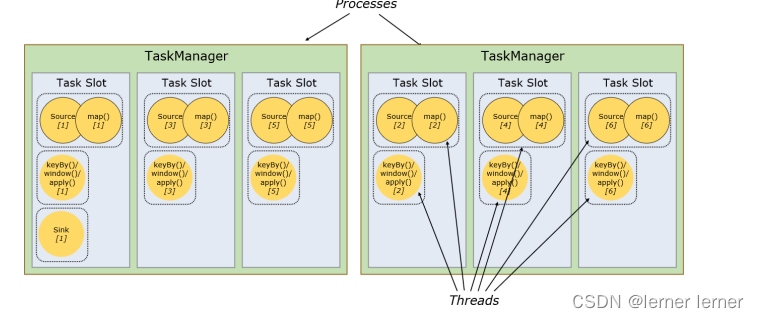
TaskSlot And Slot Sharing
每个TaskManager是一个JVM的进程, 为了控制一个TaskManager(worker)能接收多少个task,Flink通过Task Slot来进行控制。TaskSlot数量是用来限制一个TaskManager工作进程中可以同时运行多少个工作线程,TaskSlot 是一个 TaskManager 中的最小资源分配单位,一个 TaskManager 中有多少个 TaskSlot 就意味着能支持多少并发的Task处理。
Flink将进程的内存进行了划分到多个slot中,内存被划分到不同的slot之后可以获得如下好处:
- TaskManager最多能同时并发执行的子任务数是可以通过TaskSolt数量来控制的
- TaskSolt有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响。
槽共享(Slot Sharing)
Flink允许子任务共享插槽,即使它们是不同任务(阶段)的子任务(subTask),只要它们来自同一个作业。
比如图左下角中的map和keyBy和sink 在一个 TaskSlot 里执行以达到资源共享的目的。
允许插槽共享有两个主要好处:
- 资源分配更加公平,如果有比较空闲的slot可以将更多的任务分配给它。
- 有了任务槽共享,可以提高资源的利用率。
注意:
slot是静态的概念,是指taskmanager具有的并发执行能力
parallelism是动态的概念,是指程序运行时实际使用的并发能力
Flink执行图(ExecutionGraph)
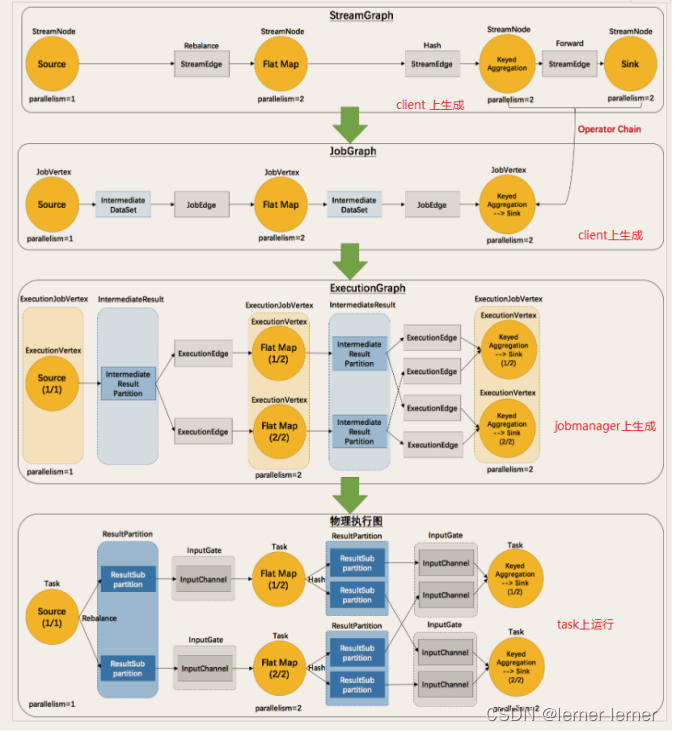
StreamGraph:最初的程序执行逻辑流程,也就是算子之间的前后顺序–在Client上生成
JobGraph:将OneToOne的Operator合并为OperatorChain–在Client上生成
ExecutionGraph:将JobGraph根据代码中设置的并行度和请求的资源进行并行化规划 --在JobManager上生成
物理执行图:将ExecutionGraph的并行计划,落实到具体的TaskManager上,将具体的SubTask落实到具体的TaskSlot内进行运行。
二、流批一体API
流处理相关概念
编程模型
Flink 应用程序结构主要包含三部分,Source/Transformation/Sink,如下图所示: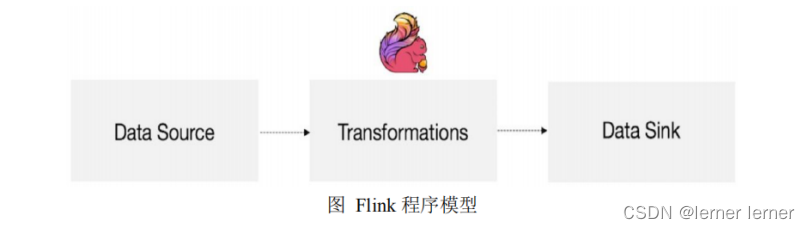
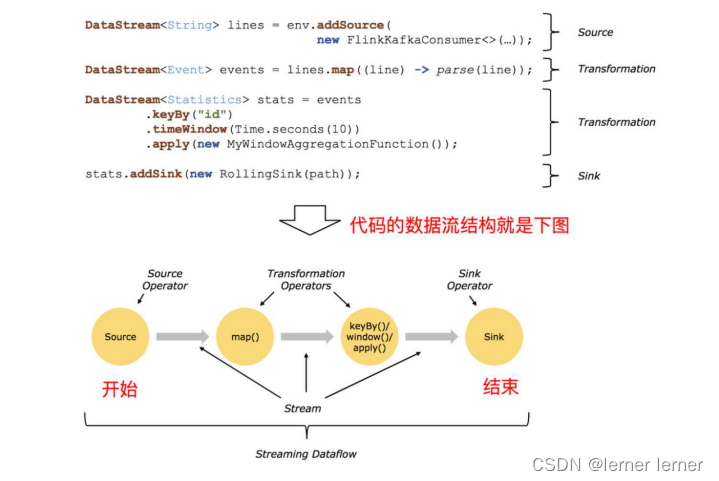
Source
基于集合的Source
// 1.envStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 2.source// * 1.env.fromElements(可变参数);DataStream<String> ds1 = env.fromElements("hadoop","spark","flink");// * 2.env.fromColletion(各种集合);DataStream<String> ds2 = env.fromCollection(Arrays.asList("hadoop","spark","flink"));// * 3.env.generateSequence(开始,结束);DataStream<Long> ds3 = env.generateSequence(1,10);//* 4.env.fromSequence(开始,结束);DataStream<Long> ds4 = env.fromSequence(1,10);
基于文件的Source
DataStream<String> ds1 = env.readTextFile("data/input/words.txt");//本地文件DataStream<String> ds2 = env.readTextFile("data/input/dir");DataStream<String> ds3 = env.readTextFile("hdfs://node1:8020//wordcount/input/words.txt");//DFS文件DataStream<String> ds4 = env.readTextFile("data/input/wordcount.txt.gz");//压缩文件
基于Socket的Source
DataStream<String> linesDS = env.socketTextStream("node1",9999);
MySQL
publicstaticclassMySQLSourceextendsRichParallelSourceFunction<Student>{@Overridepublicvoidopen(Configuration parameters)throwsException{//加载驱动,开启连接//Class.forName("com.mysql.jdbc.Driver");
conn =DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata","root","root");String sql ="select id,name,age from t_student";
ps = conn.prepareStatement(sql);}@Overridepublicvoidrun(SourceContext<Student> ctx)throwsException{while(flag){...}}
Transformation
- API
- map:将函数作用在集合中的每一个元素上,并返回作用后的结果
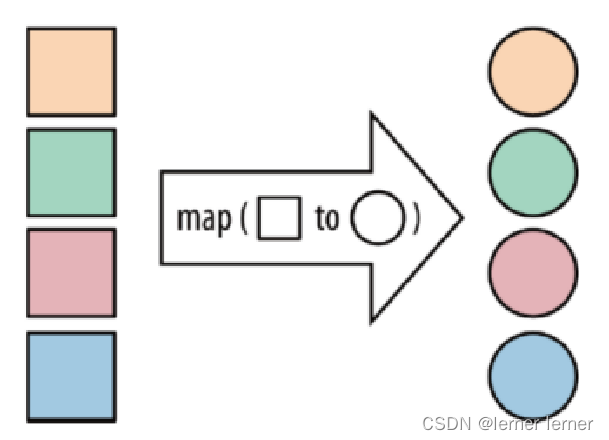
- flatMap:将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果
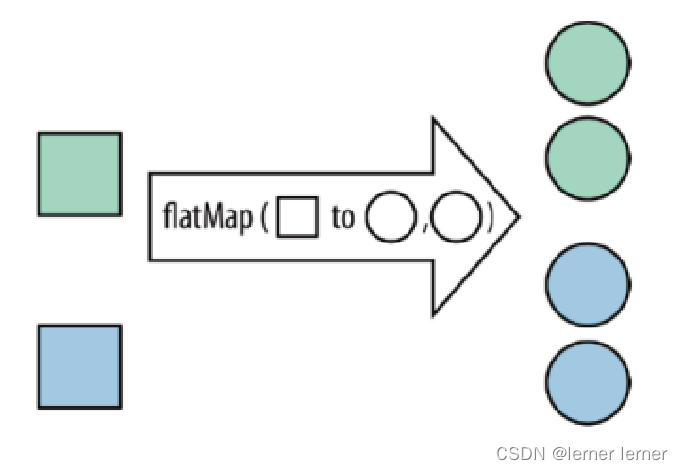
- keyBy:按照指定的key来对流中的数据进行分组,前面入门案例中已经演示过 注意: 流处理中没有groupBy,而是keyBy
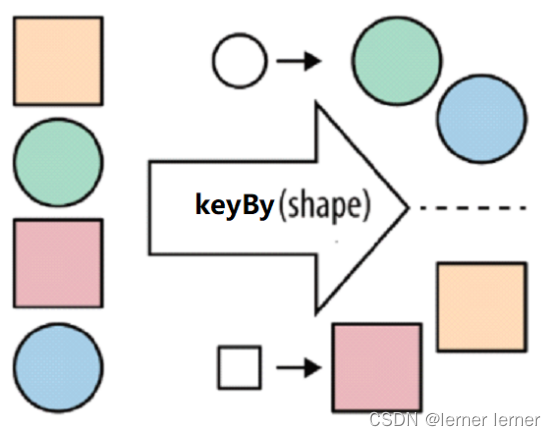
- filter:按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素
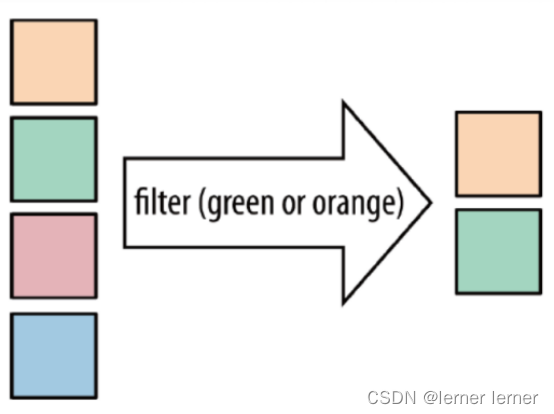
- sum:按照指定的字段对集合中的元素进行求和
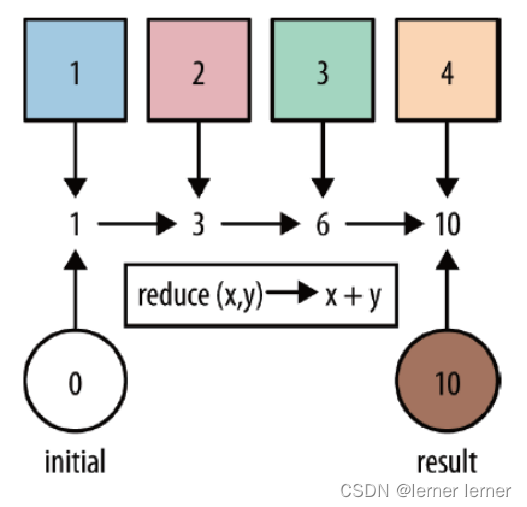
- reduce:对集合中的元素进行聚合
- union: union算子可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。数据将按照先进先出(First In First Out)的模式合并。
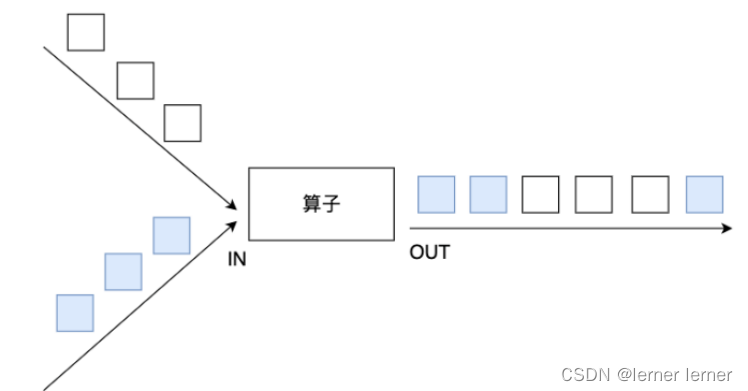
- connect: connect提供了和union类似的功能,用来连接两个数据流,它与union的区别在于:connect只能连接两个数据流,union可以连接多个数据流。****connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。 两个DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态
- split、select和Side Outputs Split就是将一个流分成多个流(注意:split函数已过期并移除****Select就是获取分流后对应的数据Side Outputs:可以使用process方法对流中数据进行处理,并针对不同的处理结果将数据收集到不同的OutputTag中
- rebalance重平衡分区 类似于Spark中的repartition,但是功能更强大,可以直接解决数据倾斜 Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会出现数据倾斜,其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成; 所以在实际的工作中,出现这种情况比较好的解决方案就是rebalance(内部使用round robin方法将数据均匀打散)
- 其他分区
 说明: recale分区。基于上下游Operator的并行度,将记录以循环的方式输出到下游Operator的每个实例。 举例: 上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。若上游并行度是4,下游并行度是2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上
说明: recale分区。基于上下游Operator的并行度,将记录以循环的方式输出到下游Operator的每个实例。 举例: 上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。若上游并行度是4,下游并行度是2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上
sink
- 基于控制台和文件的Sink 1.ds.print 直接输出到控制台 2.ds.printToErr() 直接输出到控制台,用红色 3.ds.writeAsText(“本地/HDFS的path”,WriteMode.OVERWRITE).setParallelism(1) 注意: 在输出到path的时候,可以在前面设置并行度,如果 并行度>1,则path为目录 并行度=1,则path为文件名
- MySQL 需求:将Flink集合中的数据通过自定义Sink保存到MySQL
publicstaticclassMySQLSinkextendsRichSinkFunction<Student>{@Overridepublicvoidopen(Configuration parameters)throwsException{//Class.forName("com.mysql.jdbc.Driver");
conn =DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata","root","root");String sql ="INSERT INTO `t_student` (`id`, `name`, `age`) VALUES (null, ?, ?)";
ps = conn.prepareStatement(sql);}@Overridepublicvoidinvoke(Student value,Context context)throwsException{
ps.setString(1,value.getName());
ps.setInt(2,value.getAge());
ps.executeUpdate();}
Connectors
kafka
Flink高级API
Time
除此之外,Flink还实现了Watermark的机制,能够支持基于事件的时间的处理,能够容忍迟到/乱序的数据。
Window
另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
Flink-Window操作
在流处理应用中,数据是连续不断的,有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。
在这种情况下,我们必须定义一个窗口(window),用来收集最近1分钟内的数据,并对这个窗口内的数据进行计算。
按照上面窗口的分类方式进行组合,可以得出如下的窗口:
1.基于时间的滚动窗口tumbling-time-window–用的较多
2.基于时间的滑动窗口sliding-time-window–用的较多 滑动窗口size>slide 每隔5s统计最近10s的数据
3.基于数量的滚动窗口tumbling-count-window–用的较少
4.基于数量的滑动窗口sliding-count-window–用的较少
注意:Flink还支持一个特殊的窗口:Session会话窗口,需要设置一个会话超时时间,如30s,则表示30s内没有数据到来,则触发上个窗口的计算
使用keyby的流,应该使用window方法
未使用keyby的流,应该调用windowAll方法
WindowAssigner
window/windowAll 方法接收的输入是一个 WindowAssigner, WindowAssigner 负责将每条输入的数据分发到正确的 window 中,
Flink提供了很多各种场景用的WindowAssigner:
Flink-Time与Watermark
实际开发中我们希望基于事件时间(EventTime)来处理数据,但因为数据可能因为网络延迟等原因,出现了乱序或延迟到达,那么可能处理的结果不是我们想要的甚至出现数据丢失的情况,所以需要一种机制来解决一定程度上的数据乱序或延迟到达的问题!也就是我们接下来要学习的
Watermaker水印机制/水位线机制。
Watermaker就是给数据再额外的加的一个时间列,Watermaker是个时间戳
- 如何计算Watermaker?Watermaker = 数据的事件时间 - 最大允许的延迟时间或乱序时间 注意:后面通过源码会发现,准确来说: Watermaker = 当前窗口的最大的事件时间 - 最大允许的延迟时间或乱序时间 这样可以保证Watermaker水位线会一直上升(变大),不会下降
- Watermark有什么用?之前的窗口都是按照系统时间来触发计算的,如: [10:00:00 ~ 10:00:10) 的窗口, 一但系统时间到了10:00:10就会触发计算,那么可能会导致延迟到达的数据丢失! 那么现在有了Watermaker,窗口就可以按照Watermaker来触发计算! 也就是说Watermaker是用来触发窗口计算的!
- Watermaker如何触发窗口计算的?窗口计算的触发条件为: 1.窗口中有数据 2.Watermaker >= 窗口的结束时间 Watermaker = 当前窗口的最大的事件时间 - 最大允许的延迟时间或乱序时间 也就是说只要不断有数据来,就可以保证Watermaker水位线是会一直上升/变大的,不会下降/减小的 所以最终一定是会触发窗口计算的 注意: 上面的触发公式进行如下变形: Watermaker >= 窗口的结束时间 Watermaker = 当前窗口的最大的事件时间 - 最大允许的延迟时间或乱序时间 当前窗口的最大的事件时间 - 最大允许的延迟时间或乱序时间 >= 窗口的结束时间 当前窗口的最大的事件时间 >= 窗口的结束时间 + 最大允许的延迟时间或乱序时间
Flink-状态管理
无状态计算和有状态计算
无状态计算
不需要考虑历史数据
相同的输入得到相同的输出就是无状态计算, 如map/flatMap/filter…

有状态计算
需要考虑历史数据
相同的输入得到不同的输出/不一定得到相同的输出,就是有状态计算,如:sum/reduce

状态的分类
Managed State & Raw State
Keyed State & Operator State
Managed State 分为两种,Keyed State 和 Operator State (Raw State都是Operator State)
Keyed State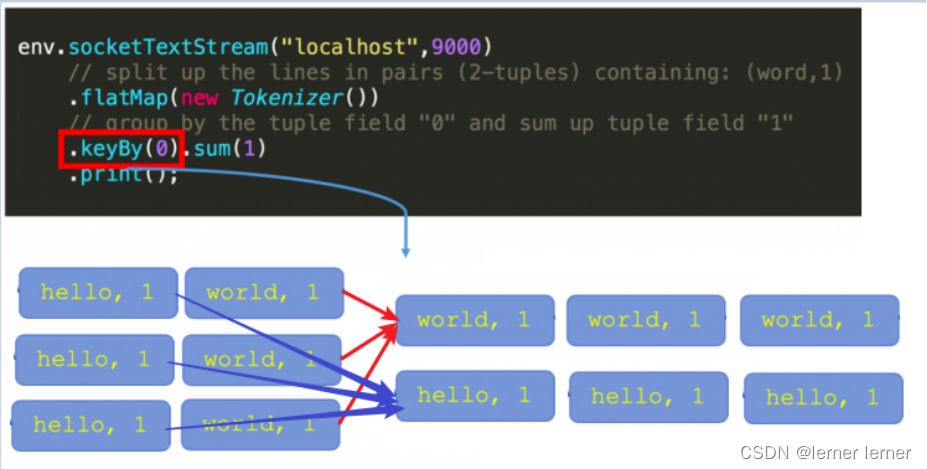
在Flink Stream模型中,Datastream 经过 keyBy 的操作可以变为 KeyedStream。
Keyed State是基于KeyedStream上的状态。这个状态是跟特定的key绑定的,对KeyedStream流上的每一个key,都对应一个state,如stream.keyBy(…);
KeyBy之后的State,可以理解为分区过的State,每个并行keyed Operator的每个实例的每个key都有一个Keyed State,即<parallel-operator-instance,key>就是一个唯一的状态,由于每个key属于一个keyed Operator的并行实例,因此我们将其简单的理解为<operator,key>
Operator State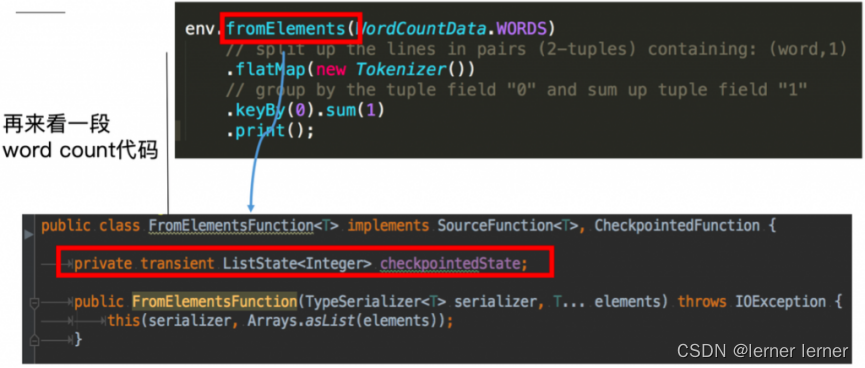
这里的fromElements会调用FromElementsFunction的类,其中就使用了类型为 list state 的 operator state
Operator State又称为 non-keyed state,与Key无关的State,每一个 operator state 都仅与一个 operat的实例绑定。
Operator State 可以用于所有算子,但一般常用于 Source。
存储State的数据结构/API介绍
前面说过有状态计算其实就是需要考虑历史数据
而历史数据需要搞个地方存储起来
Flink为了方便不同分类的State的存储和管理,提供了如下的API/数据结构来存储State
Keyed State 通过 RuntimeContext 访问,这需要 Operator 是一个RichFunction。
保存Keyed state的数据结构:
ValueState<T>:即类型为T的单值状态。这个状态与对应的key绑定,是最简单的状态了。它可以通过update方法更新状态值,通过value()方法获取状态值,如求按用户id统计用户交易总额
ListState<T>:即key上的状态值为一个列表。可以通过add方法往列表中附加值;也可以通过get()方法返回一个Iterable来遍历状态值,如统计按用户id统计用户经常登录的Ip
ReducingState<T> :这种状态通过用户传入的reduceFunction,每次调用add方法添加值的时候,会调用reduceFunction,最后合并到一个单一的状态值
MapState<UK, UV>:即状态值为一个map。用户通过put或putAll方法添加元素
需要注意的是,以上所述的State对象,仅仅用于与状态进行交互(更新、删除、清空等),而真正的状态值,有可能是存在内存、磁盘、或者其他分布式存储系统中。相当于我们只是持有了这个状态的句柄。
Operator State 需要自己实现 CheckpointedFunction 或 ListCheckpointed 接口。
保存Operator state的数据结构:
ListState
BroadcastState<K,V>
举例来说,Flink中的FlinkKafkaConsumer,就使用了operator state。它会在每个connector实例中,保存该实例中消费topic的所有(partition, offset)映射
State代码示例
- keyed state
下图就 word count 的 sum 所使用的StreamGroupedReduce类为例讲解了如何在代码中使用 keyed state: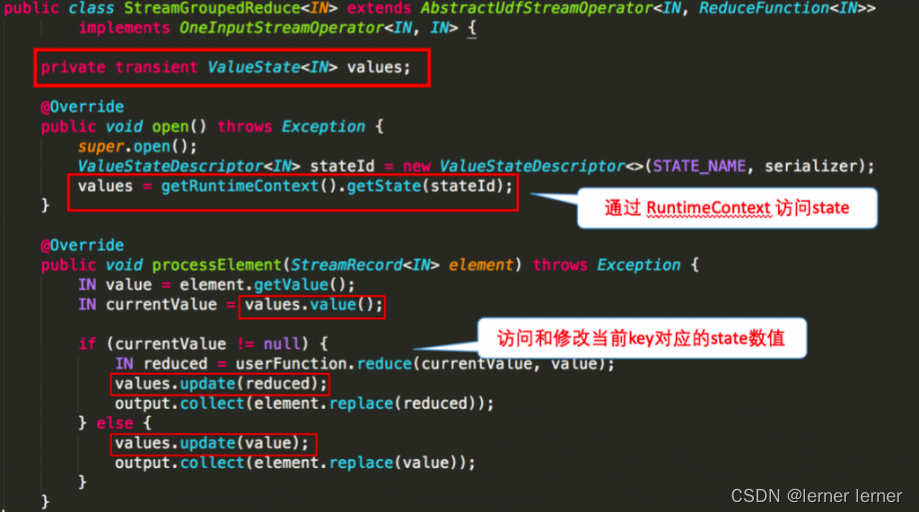
需求:
使用KeyState中的ValueState获取数据中的最大值(实际中直接使用maxBy即可)
编码步骤
//-1.定义一个状态用来存放最大值
private transient ValueState maxValueState;
//-2.创建一个状态描述符对象
ValueStateDescriptor descriptor = new ValueStateDescriptor(“maxValueState”, Long.class);
//-3.根据状态描述符获取State
maxValueState = getRuntimeContext().getState(maxValueStateDescriptor);
//-4.使用State
Long historyValue = maxValueState.value();
//判断当前值和历史值谁大
if (historyValue == null || currentValue > historyValue)
//-5.更新状态
maxValueState.update(currentValue);
- Operator State 下图对 word count 示例中的FromElementsFunction类进行详解并分享如何在代码中使用 operator state:
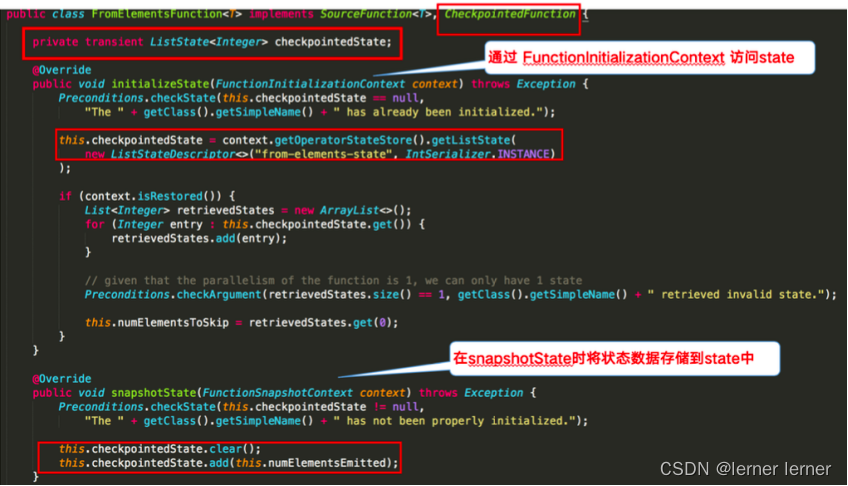 需求: 使用ListState存储offset模拟Kafka的offset维护 编码步骤 //-1.声明一个OperatorState来记录offset private ListState offsetState = null; private Long offset = 0L; //-2.创建状态描述器 ListStateDescriptor descriptor = new ListStateDescriptor(“offsetState”, Long.class); //-3.根据状态描述器获取State offsetState = context.getOperatorStateStore().getListState(descriptor);
需求: 使用ListState存储offset模拟Kafka的offset维护 编码步骤 //-1.声明一个OperatorState来记录offset private ListState offsetState = null; private Long offset = 0L; //-2.创建状态描述器 ListStateDescriptor descriptor = new ListStateDescriptor(“offsetState”, Long.class); //-3.根据状态描述器获取State offsetState = context.getOperatorStateStore().getListState(descriptor);
Flink-容错机制
State Vs Checkpoint
State:
维护/存储的是某一个Operator的运行的状态/历史值,是维护在内存中!
一般指一个具体的Operator的状态( operator的状态表示一些算子在运行的过程中会产生的一些历史结果, 如前面的maxBy底层**会维护当前的最大值,也就是会维护一个keyedOperator,**这个State里面存放就是maxBy这个Operator中的最大值)
State数据默认保存在Java的堆内存中/TaskManage节点的内存中
State可以被记录,在失败的情况下数据还可以恢复
Checkpoint:
某一时刻,Flink中所有的Operator的当前State的全局快照,一般存在磁盘上
表示了一个Flink Job在一个特定时刻的一份全局状态快照,即包含了所有Operator的状态
可以理解为Checkpoint是把State数据定时持久化存储了
比如KafkaConsumer算子中维护的Offset状态,当任务重新恢复的时候可以从Checkpoint中获取
注意:
Flink中的Checkpoint底层使用了Chandy-Lamport algorithm分布式快照算法可以保证数据的在分布式环境下的一致性!
https://zhuanlan.zhihu.com/p/53482103
Chandy-Lamport algorithm算法的作者也是ZK中Paxos 一致性算法的作者
https://www.cnblogs.com/shenguanpu/p/4048660.html
Flink中使用Chandy-Lamport algorithm分布式快照算法取得了成功,后续Spark的StructuredStreaming也借鉴了该算法
Checkpoint执行流程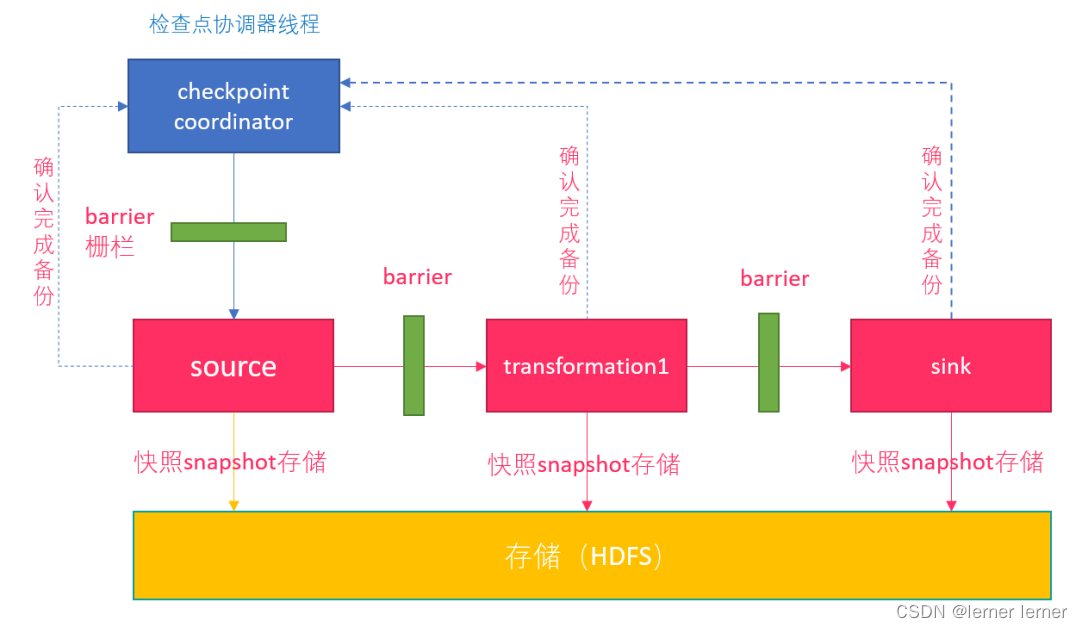
0.Flink的JobManager创建CheckpointCoordinator
1.Coordinator向所有的SourceOperator发送Barrier栅栏(理解为执行Checkpoint的信号)
2.SourceOperator接收到Barrier之后,暂停当前的操作(暂停的时间很短,因为后续的写快照是异步的),并制作State快照, 然后将自己的快照保存到指定的介质中(如HDFS), 一切 ok之后向Coordinator汇报并将Barrier发送给下游的其他Operator
3.其他的如TransformationOperator接收到Barrier,重复第2步,最后将Barrier发送给Sink
4.Sink接收到Barrier之后重复第2步
5.Coordinator接收到所有的Operator的执行ok的汇报结果,认为本次快照执行成功
注意:
1.在往介质(如HDFS)中写入快照数据的时候是异步的(为了提高效率)
2.分布式快照执行时的数据一致性由Chandy-Lamport algorithm分布式快照算法保证!
State状态后端/State存储介质
注意:
前面学习了Checkpoint其实就是Flink中某一时刻,所有的Operator的全局快照,
那么快照应该要有一个地方进行存储,而这个存储的地方叫做状态后端
Flink中的State状态后端有很多种:
MemStateBackend[了解] —— 不推荐生产场景使用
FsStateBackend
另一种就是在文件系统上的 FsStateBackend 构建方法是需要传一个文件路径和是否异步快照。
State 依然在 TaskManager 内存中,但不会像 MemoryStateBackend 是 5 M 的设置上限
Checkpoint 存储在外部文件系统(本地或 HDFS), 打破了总大小 Jobmanager 内存的限制。
推荐使用的场景为:常规使用状态的作业、例如分钟级窗口聚合或 join、需要开启HA的作业。
如果使用HDFS,则初始化FsStateBackend时,需要传入以 “hdfs://”开头的路径(即: new FsStateBackend(“hdfs:///hacluster/checkpoint”)),
如果使用本地文件,则需要传入以“file://”开头的路径(即:new FsStateBackend(“file:///Data”))。
在分布式情况下,不推荐使用本地文件。因为如果某个算子在节点A上失败,在节点B上恢复,使用本地文件时,在B上无法读取节点 A上的数据,导致状态恢复失败
RocksDBStateBackend
还有一种存储为 RocksDBStateBackend ,
RocksDB 是一个 key/value 的内存存储系统,和其他的 key/value 一样,先将状态放到内存中,如果内存快满时,则写入到磁盘中,
但需要注意 RocksDB 不支持同步的 Checkpoint,构造方法中没有同步快照这个选项。
不过 RocksDB 支持增量的 Checkpoint,意味着并不需要把所有 sst 文件上传到 Checkpoint 目录,仅需要上传新生成的 sst 文件即可。它的 Checkpoint 存储在外部文件系统(本地或HDFS),
其容量限制只要单个 TaskManager 上 State 总量不超过它的内存+磁盘,单 Key最大 2G,总大小不超过配置的文件系统容量即可。
推荐使用的场景为:超大状态的作业,例如天级窗口聚合、需要开启 HA 的作业、最好是对状态读写性能要求不高的作业
重启策略分类
默认重启策略
无重启策略
固定延迟重启策略–开发中使用
失败率重启策略–开发偶尔使用
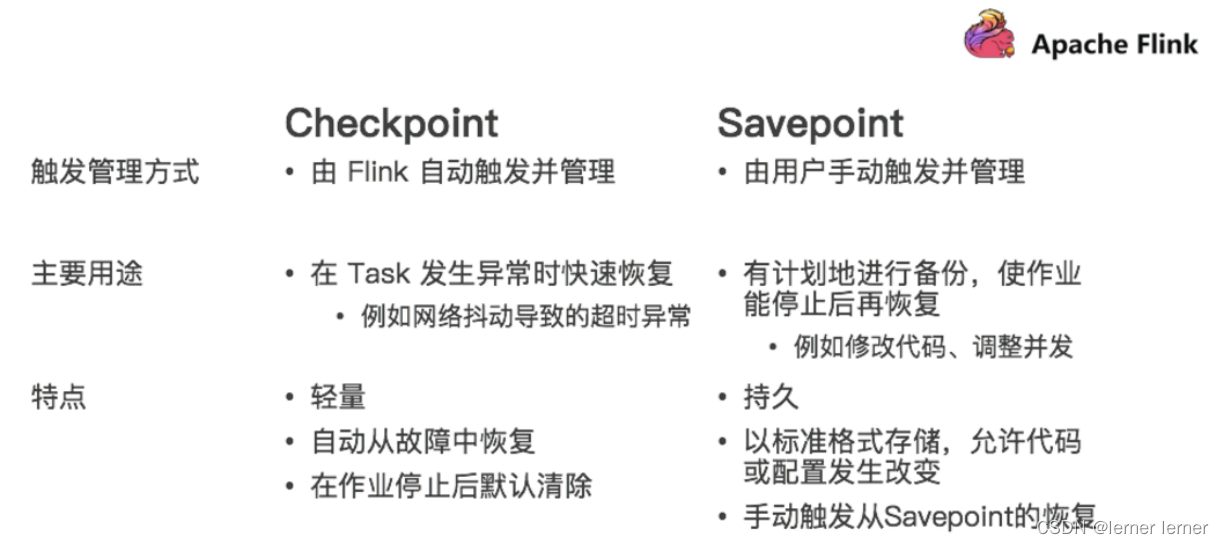
Savepoint:保存点,类似于以前玩游戏的时候,遇到难关了/遇到boss了,赶紧手动存个档,然后接着玩,如果失败了,赶紧从上次的存档中恢复,然后接着玩
在实际开发中,可能会遇到这样的情况:如要对集群进行停机维护/扩容…
那么这时候需要执行一次**Savepoint也就是执行一次手动的Checkpoint/也就是手动的发一个barrier栅栏,**那么这样的话,程序的所有状态都会被执行快照并保存,
当维护/扩容完毕之后,可以从上一次Savepoint的目录中进行恢复!
Savepoint VS Checkpoint
四、Flink-Table与SQL
Flink的Table模块包括 Table API 和 SQL:
Table API 是一种类SQL的API,通过Table API,用户可以像操作表一样操作数据,非常直观和方便
SQL作为一种声明式语言,有着标准的语法和规范,用户可以不用关心底层实现即可进行数据的处理,非常易于上手
Flink Table API 和 SQL 的实现上有80%左右的代码是公用的。作为一个流批统一的计算引擎,Flink 的 Runtime 层是统一的。
Dynamic Tables & Continuous Queries
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/streaming/dynamic_tables.html
在Flink中,它把针对无界流的表称之为Dynamic Table(动态表)。它是Flink Table API和SQL的核心概念。
顾名思义,它表示了Table是不断变化的。
我们可以这样来理解,当我们用Flink的API,建立一个表,其实把它理解为建立一个逻辑结构,这个逻辑结构需要映射到数据上去。Flink source源源不断的流入数据,就好比每次都往表上新增一条数据。表中有了数据,我们就可以使用SQL去查询了。要注意一下,流处理中的数据是只有新增的,所以看起来数据会源源不断地添加到表中。
动态表也是一种表,既然是表,就应该能够被查询。我们来回想一下原先我们查询表的场景。
打开编译工具,编写一条SQL语句
将SQL语句放入到mysql的终端执行
查看结果
再编写一条SQL语句
再放入到终端执行
再查看结果
……如此反复
而针对动态表,Flink的source端肯定是源源不断地会有数据流入,然后我们基于这个数据流建立了一张表,再编写SQL语句查询数据,进行处理。这个SQL语句一定是不断地执行的。而不是只执行一次。注意:针对流处理的SQL绝对不会像批式处理一样,执行一次拿到结果就完了。而是会不停地执行,不断地查询获取结果处理。所以,官方给这种查询方式取了一个名字,叫Continuous Query,中文翻译过来叫连续查询。而且每一次查询出来的数据也是不断变化的.
这是非常简单的示意图。该示意图描述了:我们通过建立动态表和连续查询来实现在无界流中的SQL操作。大家也可以看到,在Continuous上面有一个State,表示查询出来的结果会存储在State中,再下来Flink最终还是使用流来进行处理。
所以,可以理解为Flink的Table API和SQL,是一个逻辑模型,通过该逻辑模型可以让我们的数据处理变得更加简单
对表的编码操作
我们前面说到过,表是一种逻辑结构。而Flink中的核心还是Stream。所以,Table最终还是会以Stream方式来继续处理。如果是以Stream方式处理,最终Stream中的数据有可能会写入到其他的外部系统中,例如:将Stream中的数据写入到MySQL中。
我们前面也看到了,表是有可能会UPDATE和DELETE的。那么如果是输出到MySQL中,就要执行UPDATE和DELETE语句了。而DataStream我们在学习Flink的时候就学习过了,DataStream是不能更新、删除事件的。
如果对表的操作是INSERT,这很好办,直接转换输出就好,因为DataStream数据也是不断递增的。但如果一个TABLE中的数据被UPDATE了、或者被DELETE了,如果用流来表达呢?因为流不可变的特征,我们肯定要对这种能够进行UPDATE/DELETE的TABLE做特殊操作。
我们可以针对每一种操作,INSERT/UPDATE/DELETE都用一个或多个经过编码的事件来表示。
例如:针对UPDATE,我们用两个操作来表达,[DELETE] 数据+ [INSERT]数据。也就是先把之前的数据删除,然后再插入一条新的数据。针对DELETE,我们也可以对流中的数据进行编码,[DELETE]数据。
总体来说,我们通过对流数据进行编码,也可以告诉DataStream的下游,[DELETE]表示发出MySQL的DELETE操作,将数据删除。用 [INSERT]表示插入新的数据
将表转换为三种不同编码方式的流
Flink中的Table API或者SQL支持三种不同的编码方式。分别是:
Append-only流
Retract流
Upsert流
分别来解释下这三种流。
- Append-only流 跟INSERT操作对应。这种编码类型的流针对的是只会不断新增的Dynamic Table。这种方式好处理,不需要进行特殊处理,源源不断地往流中发送事件即可。
- Retract流 这种流就和Append-only不太一样。上面的只能处理INSERT,如果表会发生DELETE或者UPDATE,Append-only编码方式的流就不合适了。Retract流有几种类型的事件类型:ADD MESSAGE:这种消息对应的就是INSERT操作。RETRACT MESSAGE:直译过来叫取消消息。这种消息对应的就是DELETE操作。
- Upsert流 前面我们看到的RETRACT编码方式的流,实现UPDATE是使用DELETE + INSERT模式的。大家想一下:在MySQL中我们更新数据的时候,肯定不会先DELETE掉一条数据,然后再插入一条数据,肯定是直接发出UPDATE语句执行更新。而Upsert编码方式的流,是能够支持Update的,这种效率更高。它同样有两种类型的消息:UPSERT MESSAGE:这种消息可以表示要对外部系统进行Update或者INSERT操作DELETE MESSAGE:这种消息表示DELETE操作。Upsert流是要求必须指定Primary Key的,因为Upsert操作是要有Key的。 Upsert流针对UPDATE操作用一个UPSERT MESSAGE就可以描述,所以效率会更高。
版权归原作者 lerner lerner 所有, 如有侵权,请联系我们删除。