
文章目录
万花筒
大众眼中的hive
hive是基于Hadoop的一个数据仓库工具,我们经常用来对数据仓库进行数据统计分析。其中包括我们大家都知道的通过类似SQL语句实现快速MapReduce统计,将数据进行提取、转化、加载。
这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。它使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。
我眼中的hive
- Hive:由Facebook开发用于解决海量结构化日志的数据统计。
- Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL 查询功能。
- Hive是构建在Hadoop之上的数据仓库平台。
- Hive是一个SQL解析引擎,它将SQL语句转译成MapReduce作业并在Hadoop上执行。
- Hive表是HDFS的一个文件目录,一个表名对应一个目录名,如果有分区表的话,则分区值对应子目录名。它的本质是:将HQL转化成MapReduce 程序
Hive的生母
- Hive是Facebook开发的,构建于Hadoop集群之上的数据仓库应用。2008年Facebook将Hive项目贡献给Apache,成为ASF开源顶级项目。
- 目前最新版本hive-4.0.0
Hive体系结构
Hive在Hadoop 心中的位置
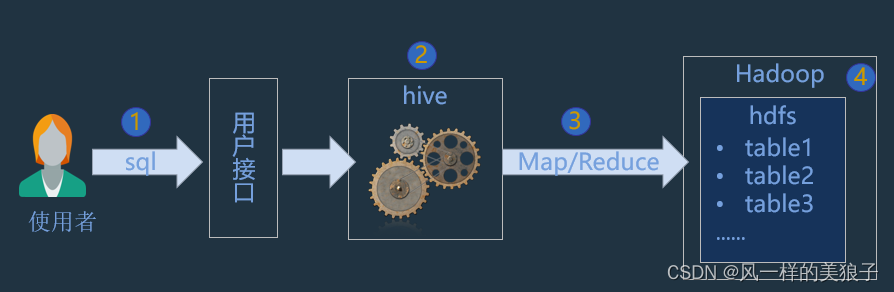
我们来看一下Hive在Hadoop 心中的位置。
Hive的设计特征
做为Hadoop 的数据仓库处理工具,它所有的数据都存储在Hadoop 兼容的文件系统中。Hive在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下。
1、支持索引,加快数据查询。
2、不同的存储类型,例如,纯文本文件、HBase 中的文件。
3、将元数据保存在关系数据库中,减少了在查询中执行语义检查时间。
4、可以直接使用存储在Hadoop 文件系统中的数据。
内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。
5、类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。
6、编码跟Hadoop同样使用UTF-8字符集。
Hive的体系结构
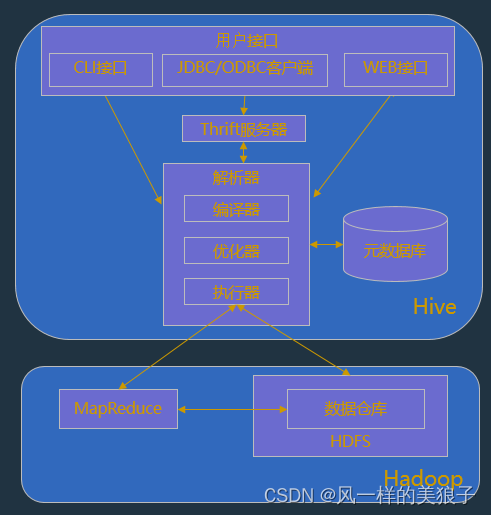
一、解析器
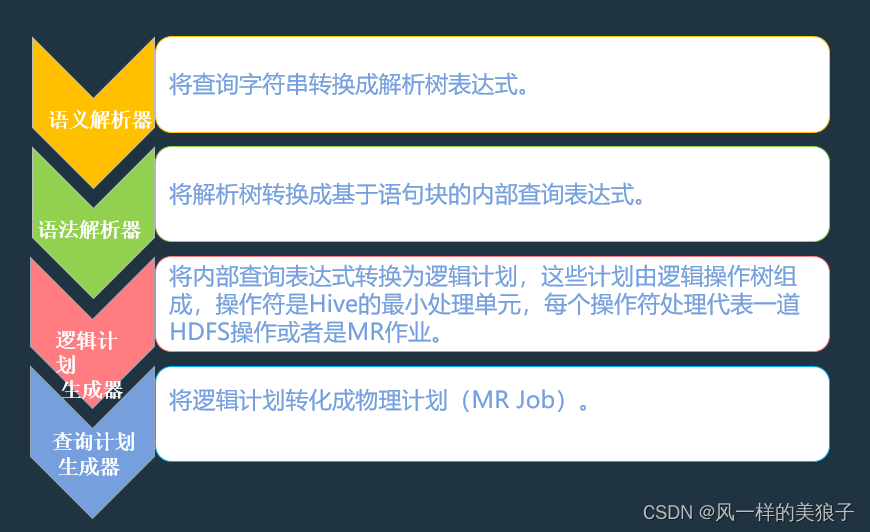
- 编译器:主要完成 HQL 语句从词法分析、语法分析、编译、优化以及执行计划的生成。
- 优化器是一个演化组件,当前它的规则是:列修剪,谓词下压。
- 执行器会顺序执行所有的Job。如果Task链不存在依赖关系,可以采用并发执行的方式执行Job。
二、元数据库
- Hive的数据由两部分组成:数据文件和元数据。元数据用于存放Hive库的基础信息,它存储在关系数据库中,如 mysql、derby。元数据包括:数据库信息、表的名字,表的列和分区及其属性,表的属性,表的数据所在目录等。
三、Hadoop
- Hive 的数据文件存储在 HDFS 中,大部分的查询由 MapReduce 完成。(对于包含 * 的查询,比如 select * from tablename 不会生成 MapRedcue 作业)
Hive的运行机制

Hive的核心-编译器
Hive的优缺点

本文转载自: https://blog.csdn.net/fyydlz/article/details/128226998
版权归原作者 风一样的美狼子 所有, 如有侵权,请联系我们删除。
版权归原作者 风一样的美狼子 所有, 如有侵权,请联系我们删除。