
今天早上,我通过python的基础抓爬以及语音输出模块实现了自动古诗文查询的功能。接下来我将分享我的代码。
首先,我们先来梳理一下思路:
在这里我们找到的古诗文大全网站是:古诗文网-古诗文经典传承
我们可以打开这个网站来查看网址,这一找网址查询规律是有方法的。我们可以在输入框中搜索一些古诗,然后反复实验对结论进行严谨的检测,接下来,我会用我们语文老师今天新教的课文来尝试:

这个就是网站的大体结构,网页上的杂项会相对来说比较多,在抓爬的时候要注意不要把这些无关紧要的内容抓取下来。
当我们在输入“虽有佳肴”这篇古文时,我们会看到这样一个界面:
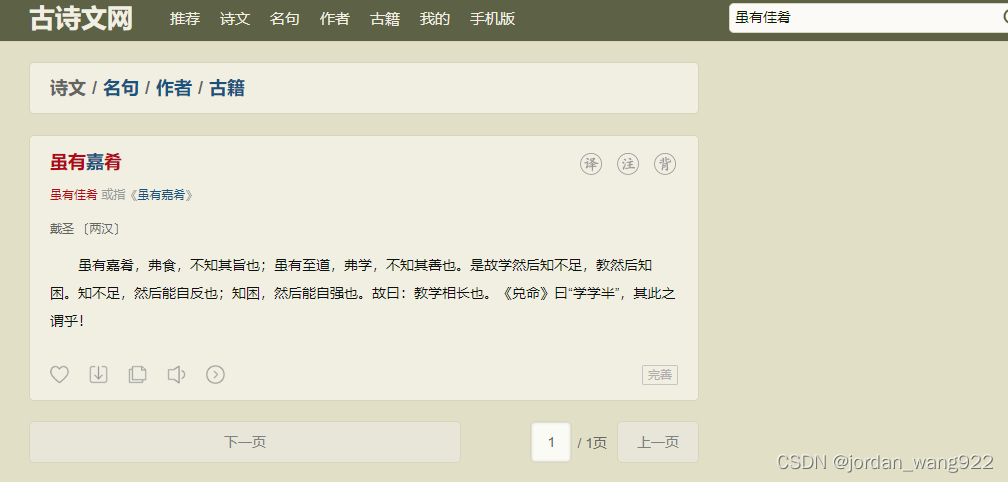
这时候我们查看他的网址:

可以发现,网址搜索的值就是我们所输入的“虽有佳肴”的内容。与一般网址不同的是,他在最后的地方还加人了我们输入值的第一个字。
有了猜想,我们不妨进行一下实验,在前面的搜索值古文“北冥有鱼”,在后面填写“北冥有鱼”的第一个字“北”
测试结果如下:
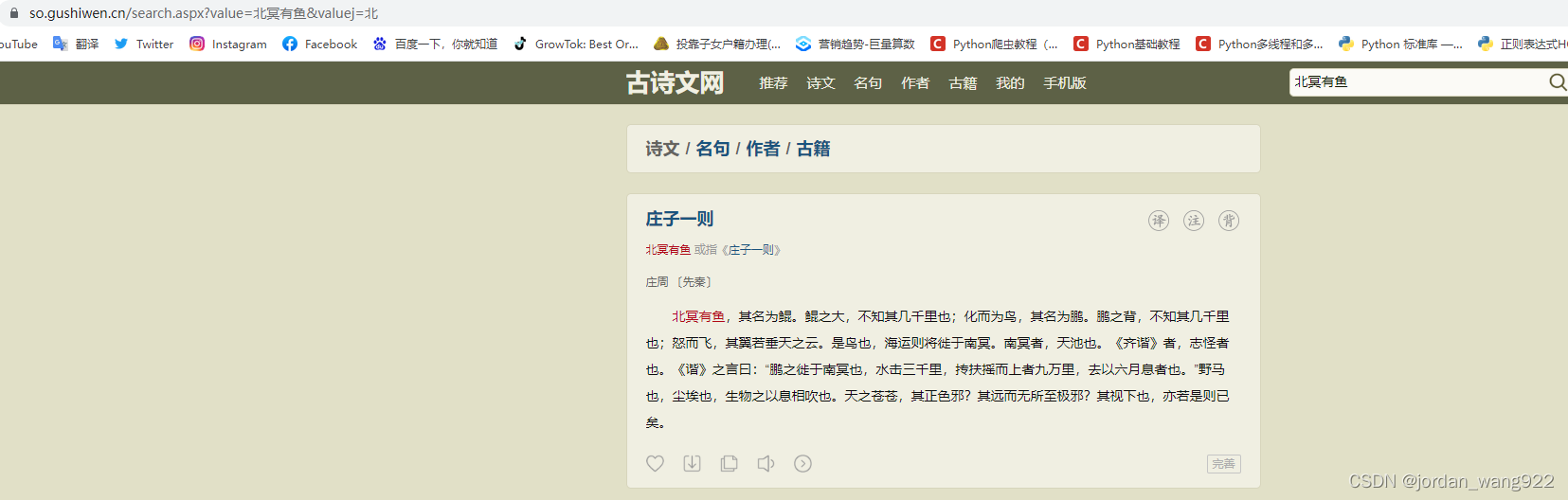
这也就说明我的推测是正确的(对了,有没有大佬可以解释一些这个网站为什么要在后面再讲搜索内容的第一个字再写一边?)
然后我们就可以用我们上一期博客所教的万能抓爬代码对其进行抓爬,代码如下:
from bs4 import BeautifulSoup
import requests
req = requests.get(url="https://so.gushiwen.cn/search.aspx?value=" + poem + "&valuej=" + poem[0])
req.encoding = "utf-8"
html=req.text
soup = BeautifulSoup(req.text,features="html.parser")
poem = soup.find("p",class_="source")
dd = poem.text.strip()
print(dd)
Jarvis_voice(x = dd)
soup = BeautifulSoup(req.text,features="html.parser")
poems = soup.find_all("div",class_="contson")
for poem in poems:
dd = poem.text.strip()
print(dd)
Jarvis_voice(x = dd)
在这里,我们进行了两次抓爬,第一次将文章的标题抓取下来了,第二次将内容抓取下来。
然后可以再加入一个语音模块让他把抓取内容读出来:
engine = pyttsx3.init()
rate = engine.getProperty('rate') # getting details of current speaking rate
engine.setProperty('rate', 210) # setting up new voice rate
voices = engine.getProperty('voices') # getting details of current voice
engine.setProperty('voice', voices[0].id) # changing index, changes voices. 1 for femal
engine.say("%s" % x)
engine.runAndWait()
最终代码如下:
import pyttsx3
from bs4 import BeautifulSoup
import requests
for x in range(20):
poem = input("您需要查询的诗名或诗句:")
def Jarvis_voice(x):
engine = pyttsx3.init()
rate = engine.getProperty('rate') # getting details of current speaking rate
engine.setProperty('rate', 210) # setting up new voice rate
voices = engine.getProperty('voices') # getting details of current voice
engine.setProperty('voice', voices[0].id) # changing index, changes voices. 1 for femal
engine.say("%s" % x)
engine.runAndWait()
#poem = input("请输入您需要查询的古诗词名或其中的某句话:")
#print(x[0])
req = requests.get(url="https://so.gushiwen.cn/search.aspx?value=" + poem + "&valuej=" + poem[0])
req.encoding = "utf-8"
html=req.text
soup = BeautifulSoup(req.text,features="html.parser")
poem = soup.find("p",class_="source")
dd = poem.text.strip()
print(dd)
Jarvis_voice(x = dd)
soup = BeautifulSoup(req.text,features="html.parser")
poems = soup.find_all("div",class_="contson")
for poem in poems:
dd = poem.text.strip()
print(dd)
Jarvis_voice(x = dd)
最后调出运行窗口,找到py文件位置,输入pyinstaller -F xxx.py 就可以打包为exe文件。
运行效果如下:

喜欢的话就点个赞吧!
本文转载自: https://blog.csdn.net/jordan_wang922/article/details/124946574
版权归原作者 jordan_wang922 所有, 如有侵权,请联系我们删除。
版权归原作者 jordan_wang922 所有, 如有侵权,请联系我们删除。