
文章目录
前言
目前本人是Java开发工程师,所以里面大部分的学习笔记都是以Java代码为主,Scala后面我再学所以后续再进行补充。
文章目录《Flink入门与实战》 - 徐葳/
一、概述
1 Flink是什么
Apache Flink,内部是用Java及Scala编写的分布式流数据计算引擎,可以支持以批处理或流处理的方式处理数据,在2014年这个项目被Apache孵化器所接受后,Flink迅速成为ASF(ApacheSoftware Foundation)的顶级项目之一,在2019年1月,阿里巴巴集团收购了Flink创始公司(DataArtisans),打造了阿里云商业化的实时计算Flink产品。
它有如下几个特点
- 低延迟
- 高吞吐
- 支持有界数据/无界数据的处理,数据流式计算
- 支持集群,支持HA,可靠性强
什么是有界数据/无界数据?
- 有界数据:数据是有限的,一条SELECT查询下的数据不会是源源不断的
- 无界数据:数据源源不断,不知道为什么时候结束,例如监控下的告警
2 架构分层
名称描述Deploy 部署方式本地/集群/云服务部署。Core 分布式流处理模型计算核心实现,为API层提供基础服务。API 调用接口提供面向
无界数据
的流处理API及
有界数据
的批处理API,其中流处理对应
DataStream API
,批处理对应
DataSet API
。Library 应用层提供应用计算框架,面向流处理支持CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作),面向批处理支持FlinkML(机器学习库)、Gelly(图处理)、Table 操作。
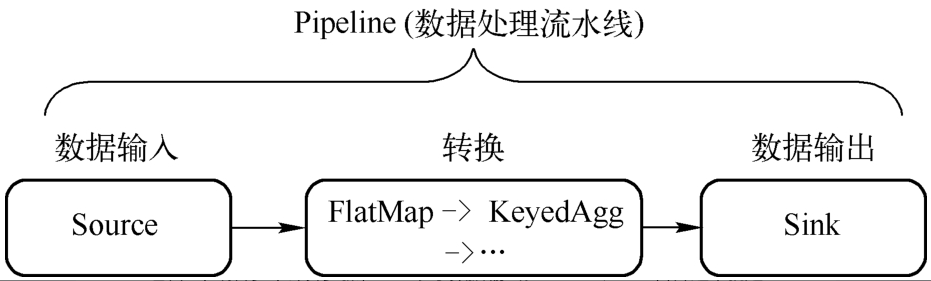
3 数据处理流水线
一个Flink任务 = DataSource + Transformation + DataSink
DataSource :数据源
Transformation :数据处理
DataSink:计算结果输出
而Flink在网络传输中通过缓存块承载数据,可以通过
设置缓存块的超时时间
,变相的决定了数据在网络中的处理方式。
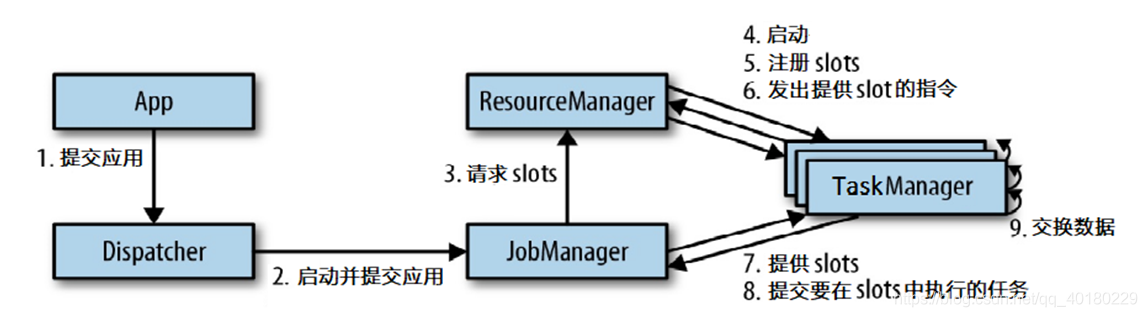
4 运行组件
文章目录Flink-运行时架构中的四大组件-SmallScorpion的CSDN博客
Flink运行时主要有四个大组件
- TaskManager - 任务管理器(1)
- JobManager - 任务管理器(2)
- ResourceManager - 资源管理器
- Dispatcher - 分配器
下面来聊聊关于这四个组件的作用
TaskManager
工作进程,通常在
一个Flink节点
内会有
多个TaskManager
运行,而在
每个TaskManager
中又包含了
多个插槽(slots)
,插槽的数量代表了TaskManager能够执行的任务数量。
进程启动后,TaskManager会向ResourceManager(资源管理器)注册自己的插槽,JobManager通过从ResourceManager请求到的插槽信息,来分配任务执行。

JobManager
控制一个应用程序执行的主进程,一个应用程序只会对应一个JobManager。
一个应用程序包括:
- 作业图 - JobGraph
- 逻辑数据流图 - logical dataflow graph
- 含有打包完的所需资源的Jar包
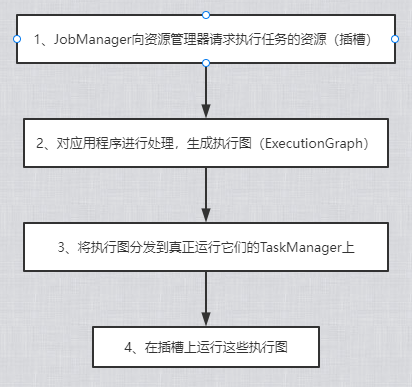
大致的流程是这样
ResourceManager
负责管理TaskManager的slot(插槽),插槽指处理资源单元,当JobManager申请插槽资源时,ResourceManager会把目前已经注册上来的空闲的插槽信息分配给JobManager。
如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
Dispatcher
- 提供Web UI,展示及监控任务执行信息
- 非必须组件,取决于应用提交运行的方式
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager
- 可以跨作业运行,它为应用提交提供了REST接口
5 其他流式计算框架
文章目录Flink介绍、特点及和与其他大数据框架对比_zhangxm_qz的CSDN博客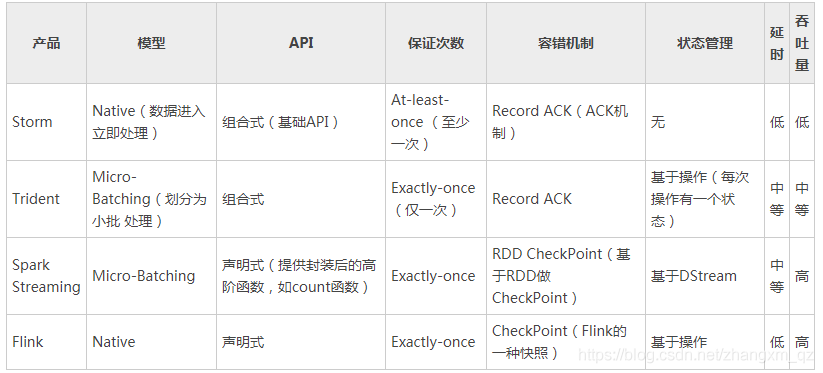
二、入门与使用
1 Flink基本安装
前置描述:xxxxxxxxxxxxx
1.1 Linux
下载链接Index of /dist/flink/flink-1.14.3 (apache.org)
首先去apache官网下载部署的软件包,下载完成之后进行解压
## 解压tar -zxvf flink-1.14.3-bin-scala_2.12.tgz
## 进入bin目录 启动
./start-cluster.sh
## Flink提供的WebUI的端口是8081 此时可以去看看是否启动完成netstat -anp |grep 8081
接着通过页面访问8081端口来个初体验
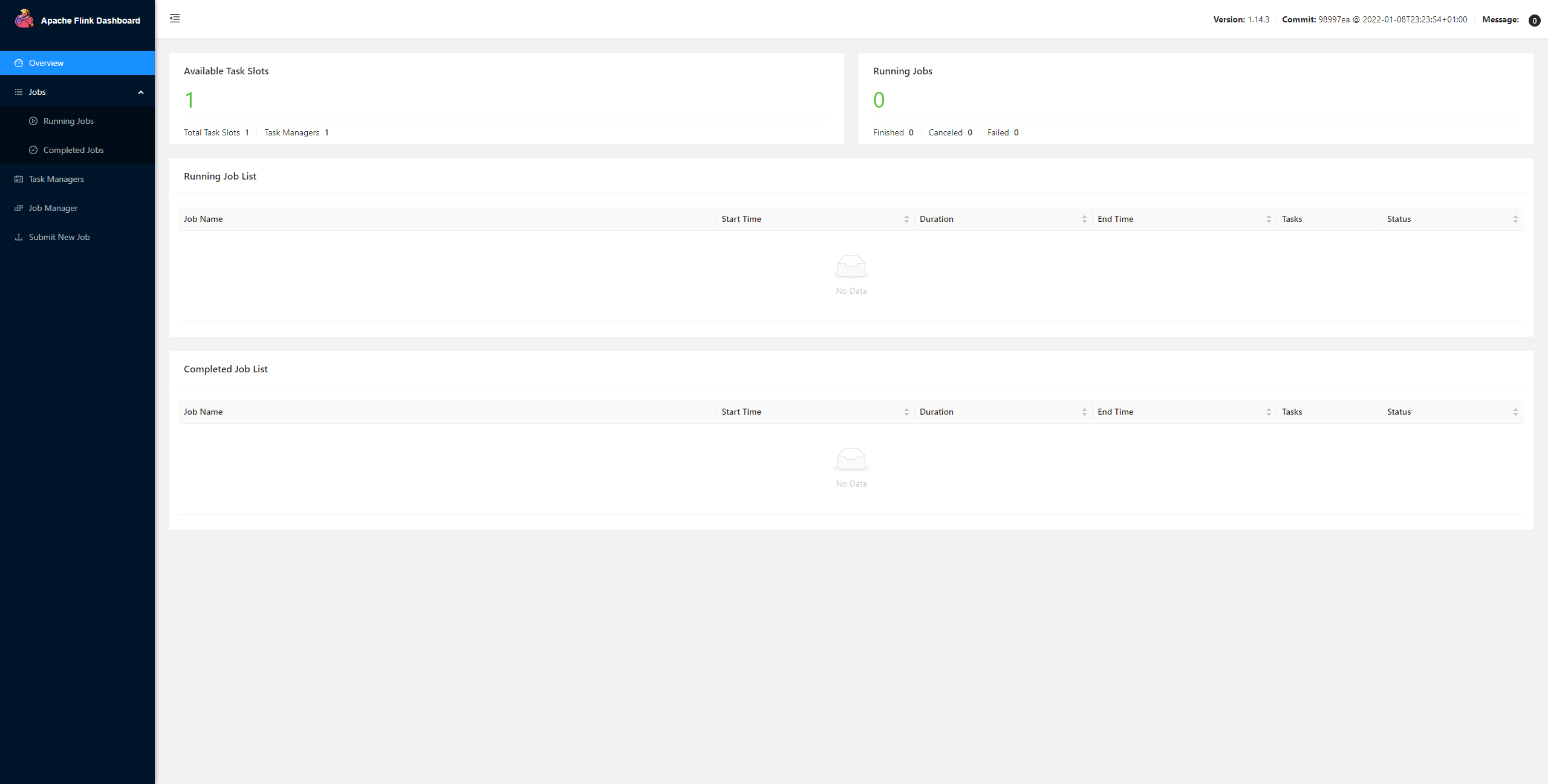
关于Linux下的Flink Shell终端的使用
文章目录flink~使用shell终端_cai_and_luo的博客-CSDN博客
1.2 Java
文章目录Flink入门之Flink程序开发步骤(java语言)_胖虎儿的博客-CSDN博客
导入依赖
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.14.3</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>1.14.3</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.14.3</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-core --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-core</artifactId><version>1.14.3</version></dependency>
入门Demo
import org.apache.flink.api.common.RuntimeExecutionMode;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;publicclassDemoApplication{publicstaticvoidmain(String[] args)throws Exception {/**
* 大致的流程就分为
* 1.环境准备
* 设置运行模式
* 2.加载数据源
* 3.数据转换
* 4.数据输出
* 5.执行程序
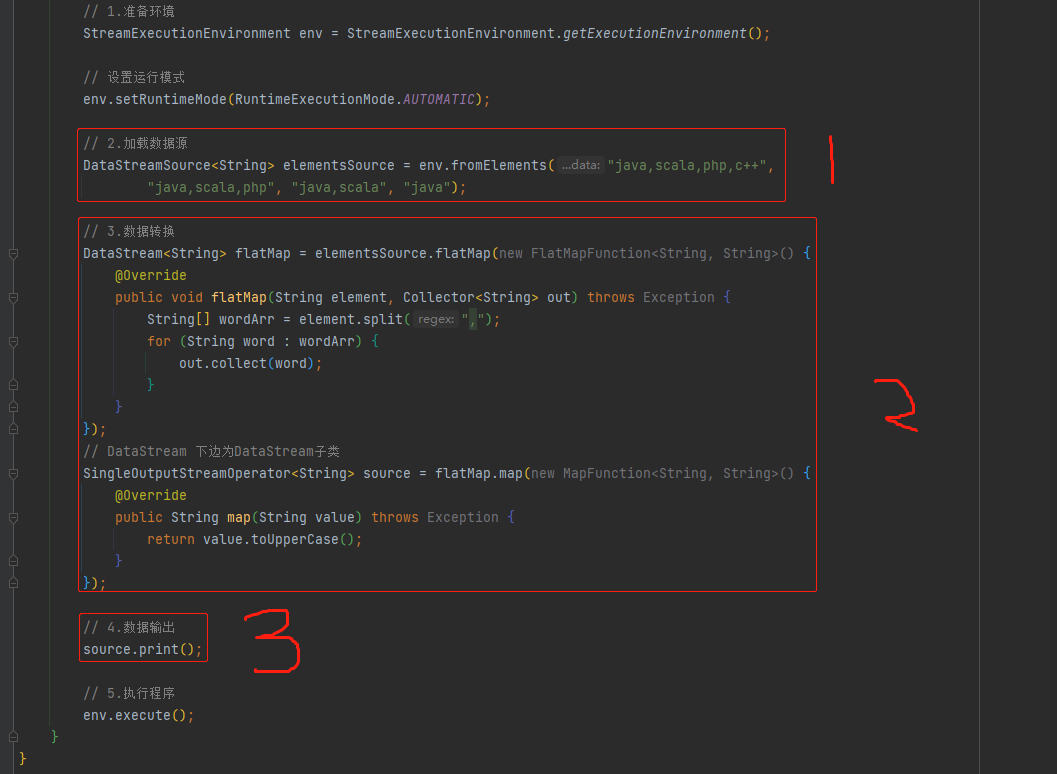
*/// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置运行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 2.加载数据源
DataStreamSource<String> elementsSource = env.fromElements("java,scala,php,c++","java,scala,php","java,scala","java");// 3.数据转换
DataStream<String> flatMap = elementsSource.flatMap(newFlatMapFunction<String, String>(){@OverridepublicvoidflatMap(String element, Collector<String> out)throws Exception {
String[] wordArr = element.split(",");for(String word : wordArr){
out.collect(word);}}});// DataStream 下边为DataStream子类
SingleOutputStreamOperator<String> source = flatMap.map(newMapFunction<String, String>(){@Overridepublic String map(String value)throws Exception {return value.toUpperCase();}});// 4.数据输出
source.print();// 5.执行程序
env.execute();}}
关于在设置运行模式的代码上,有三种选择
/**
* Runtime execution mode of DataStream programs. Among other things, this controls task scheduling,
* network shuffle behavior, and time semantics. Some operations will also change their record
* emission behaviour based on the configured execution mode.
*
* @see <a
* href="https://cwiki.apache.org/confluence/display/FLINK/FLIP-134%3A+Batch+execution+for+the+DataStream+API">
* https://cwiki.apache.org/confluence/display/FLINK/FLIP-134%3A+Batch+execution+for+the+DataStream+API</a>
*/@PublicEvolvingpublicenum RuntimeExecutionMode {/**
* The Pipeline will be executed with Streaming Semantics. All tasks will be deployed before
* execution starts, checkpoints will be enabled, and both processing and event time will be
* fully supported.
*//** 流处理模式 */
STREAMING,/**
* The Pipeline will be executed with Batch Semantics. Tasks will be scheduled gradually based
* on the scheduling region they belong, shuffles between regions will be blocking, watermarks
* are assumed to be "perfect" i.e. no late data, and processing time is assumed to not advance
* during execution.
*//** 批处理模式 */
BATCH,/**
* Flink will set the execution mode to {@link RuntimeExecutionMode#BATCH} if all sources are
* bounded, or {@link RuntimeExecutionMode#STREAMING} if there is at least one source which is
* unbounded.
*//** 自动模式 */
AUTOMATIC
}
1.3 Scala(待补充)
与Java一样都在IDEA编译器上做,此时引入依赖
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>1.14.3</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>1.14.3</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.14.3</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-core --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-core</artifactId><version>1.14.3</version></dependency>
// …
待定 …
// …
1.4 集群模式
文章目录Flink集群部署详细步骤 - 简书 (jianshu.com)Flink集群部署 - 云+社区 - 腾讯云 (tencent.com)
2 常用API
第一次学时,光看上面的Demo例子比较难以理解,所以通过书下面的API内容对照上面的Demo来进行理解,先来了解Flink四种层次的API详情
层级描述信息备注底层 API偏底层,易用性比较差,提供时间/状态的细粒度控制Stateful Stream Processing核心 API对有界/无界数据提供处理方法DataStream(流处理) / DataSet(批处理)Table API/声明式DSLSQL/高级语言
2.1 DataStream 流处理
主要分为三个流程
- DataSource 数据输入:addSource(sourceFunction)为程序添加一个数据源。
- Transformation 数据处理:对一个或多个数据源进行操作。
- Sink 数据输出:通过Transformation 处理后的数据输出到指定的位置。
DataSource
看看他们的API
DataSource API描述readTextFile(文件路径)逐行读取文本文件的数据socketTextStream(地址信息)从socket中读取数据fromCollection(集合数据)从集合内获取数据其他第三方输入数据…或者自定义数据源通过Flink提供的内置连接器去链接其它数据源
如果是自定义数据源,有两种实现方式
- 实现SourceFunction接口(并行度为1 = 无并行度)
- 实现ParallelSourceFunction接口 / 继承RichParallelSourceFunction
什么是并行度?
一个Flink程序由多个任务(Source、Transformation和Sink)组成。一个任务由多个并行实例(线程)来执行,一个任务的并行实例(线程)数目被称为该任务的并行度。
Transformation
接下来是
Transformation
数据处理,Flink针对DataStream提供了大量的已经实现的算子。
DataStream API描述Map输入一个元素,然后返回一个元素,中间可以进行清洗转换等操作FlatMap输入一个元素,可以返回零个、一个或者多个元素Filter过滤函数,对传入的数据进行判断,符合条件的数据会被留下KeyBy根据指定的Key进行分组,Key相同的数据会进入同一个分区,典型用法如下:1、DataStream.keyBy(“someKey”) 指定对象中的someKey段作为分组Key。2、DataStream.keyBy(0) 指定Tuple中的第一个元素作为分组Key。Reduce对数据进行聚合操作,结合当前元素和上一次Reduce返回的值进行聚合操作,然后返回一个新的值Aggregationssum()、min()、max()等Union合并多个流,新的流会包含所有流中的数据,但是Union有一个限制,就是所有合并的流类型必须是一致的Connect和Union类似,但是只能连接两个流,两个流的数据类型可以不同,会对两个流中的数据应用不同的处理方法coMap和coFlatMap在ConnectedStream中需要使用这种函数,类似于Map和flatMapSplit根据规则把一个数据流切分为多个流Select和Split配合使用,选择切分后的流
关于Flink针对DataStream提供的一些数据分区规则
分区规则描述DataStream.shuffle()随机分区DataStream.rebalance()对数据集进行再平衡、重分区和消除数据倾斜DataStream.rescale()重新调节DataStream.broadcast()把元素广播给所有的分区,数据会被重复处理DataStream.partitionCustom(partitioner,0) 或者 DataStream.partitionCustom(partitioner,“smeKey”)自定义分区
Sink
数据处理后的输出
Sink API描述writeAsText()将元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取print() / printToErr()打印每个元素的toString()方法的值到标准输出或者标准错误输出流中自定义输出addSink可以实现把数据输出到第三方存储介质中。系统提供了一批内置的Connector,它们会提供对应的Sink支持
自定义Sink的两种方式
- 实现SinkFunction接口
- 继承RichSinkFunction类
实际上,RichSinkFunction抽象类也是继承了SinkFunction这个接口,所以实际上差别不大
示例一:自定义数据源(SourceFunction)
第一步,继承SourceFunction接口,实现自定义数据源类
import org.apache.flink.streaming.api.functions.source.SourceFunction;import java.util.Random;/**
* 自定义数据源
* @author 李家民
*/publicclassDemoTransactionSourceimplementsSourceFunction<String>{@Overridepublicvoidrun(SourceContext<String> ctx)throws Exception {while(true){// 发射元素
ctx.collect(String.valueOf(newRandom().nextInt(50)));
Thread.sleep(1000);}}@Overridepublicvoidcancel(){}}
第二步,在Flink代码中引入这个数据源
import org.apache.flink.api.common.RuntimeExecutionMode;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.Collector;import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;/**
* @author 李家民
*/@ComponentpublicclassFlinkInitialize{@PostConstructpublicvoidstarter()throws Exception {// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置运行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 为流式作业启用检查点 以毫秒为单位 流式数据流的分布式状态将被定期快照
env.enableCheckpointing(5000);// 2.设置自定义数据源
DataStreamSource<String> stringDataStreamSource = env.addSource(newDemoTransactionSource(),"测试用的数据源");// 3.数据处理
SingleOutputStreamOperator<String> stringSingleOutputStreamOperator = stringDataStreamSource.map(newMapFunction<String, String>(){@Overridepublic String map(String value)throws Exception {return value;}});// 4.数据输出
stringSingleOutputStreamOperator.print();// 5.执行程序
env.execute();}}
此时执行代码,就可以把引入的数据进行打印
SourceFunction定义了run和cancel两个方法和SourceContext内部接口。
- run(SourceContex):实现数据获取逻辑,并可以通过传入的参数ctx进行向下游节点的数据转发。
- cancel():用来取消数据源,一般在run方法中,会存在一个循环来持续产生数据,cancel方法则可以使该循环终止。
- SourceContext:source函数用于发出元素和可能的watermark的接口,返回source生成的元素的类型。
示例二:自定义分区
数据源沿用上述案例的代码,自定义分区是通过实现Partitioner接口去做处理
首先看看自定义分区的实现类
/**
* 自定义分区
* @author 李家民
*/publicclassDemoPartitionerimplementsPartitioner<String>{@Overridepublicintpartition(String key,int numPartitions){
System.out.println("目前分区总数="+ numPartitions +" 当前值="+ key +" 通过最左边的值看分区号");if(newInteger(key)>20){return1;}else{return2;}}}
然后在Flink的代码中体现
import org.apache.flink.api.common.RuntimeExecutionMode;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.java.functions.KeySelector;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;@ComponentpublicclassFlinkInitialize{@PostConstructpublicvoidstarter()throws Exception {// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置运行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 2.设置自定义数据源
DataStreamSource<String> stringDataStreamSource = env.addSource(newDemoTransactionSource(),"测试用的数据源");// 3.数据处理
DataStream<String> dataStream = stringDataStreamSource.map(newMapFunction<String, String>(){@Overridepublic String map(String value)throws Exception {return value;}}).partitionCustom(newDemoPartitioner(),newKeySelector<String, String>(){@Overridepublic String getKey(String value)throws Exception {return value;}});// 4.数据输出
dataStream.print();// 5.执行程序
env.execute();}}
输出后的结果如下
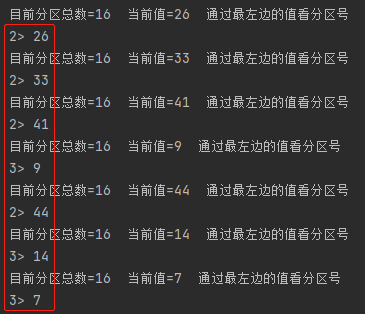
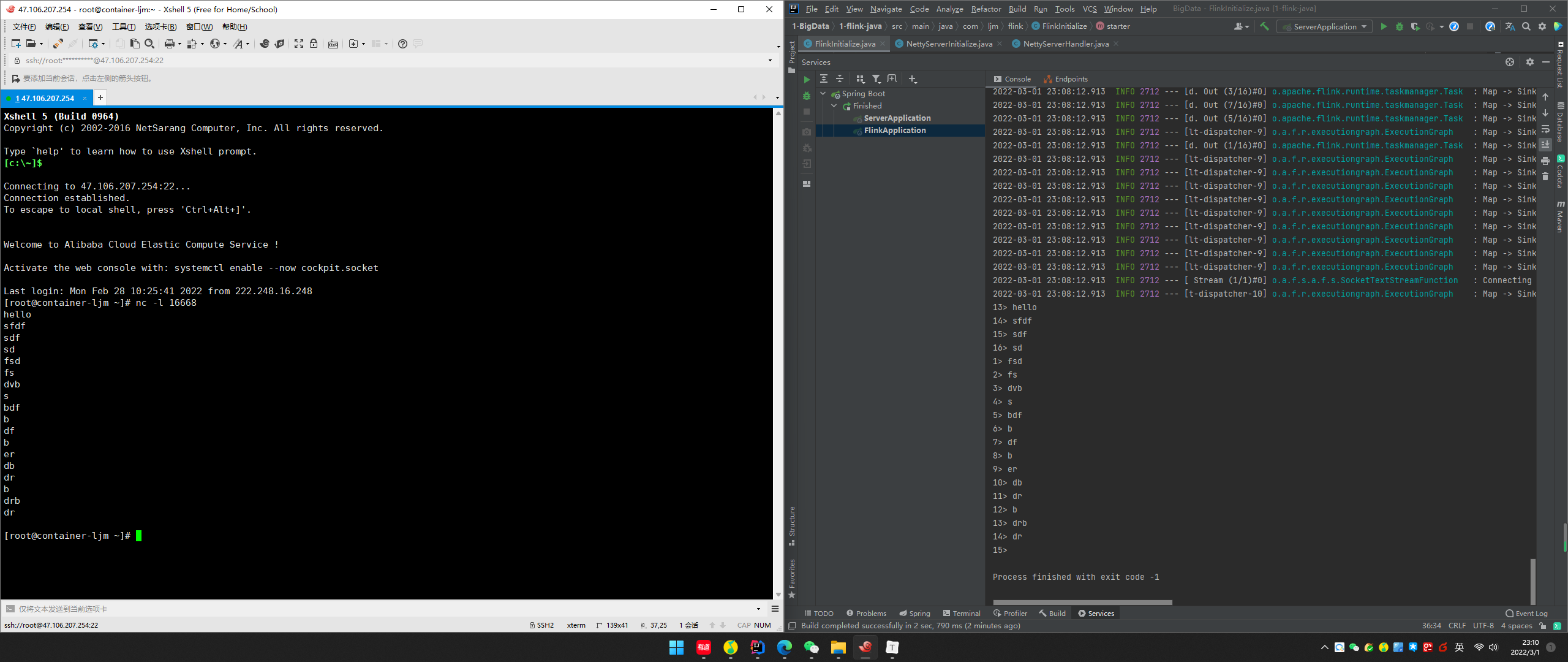
示例三:Socket通信示例
第一步:搭建数据来源,这里使用Linux作为数据来源,在Linux上打命令把端口开启
nc -l 16668
第二步:编写flink代码
import org.apache.flink.api.common.RuntimeExecutionMode;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.java.functions.KeySelector;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;@ComponentpublicclassFlinkInitialize{@PostConstructpublicvoidstarter()throws Exception {// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置运行模式
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 2.设置自定义数据源
String address ="47.106.207.254";int port =16668;
DataStream<String> dataStreamSource = env.socketTextStream(address, port).map(newMapFunction<String, String>(){@Overridepublic String map(String value)throws Exception {return value;}});
dataStreamSource.print();// 5.执行程序
env.execute();}}
效果如下
你学废了吗
示例四:RabbitMQ作为数据源
第一步:搭建RabbitMQ子系统
.....代码省略,不会RabbitMQ的看下面这篇文章
文章目录RabbitMQ - SpringBoot集成版 - 开发+运维__-CSDN博客
第二步:编写flink代码,首先引入RabbitMQ/Flink的依赖
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-rabbitmq --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-rabbitmq_2.12</artifactId><version>1.14.3</version></dependency>
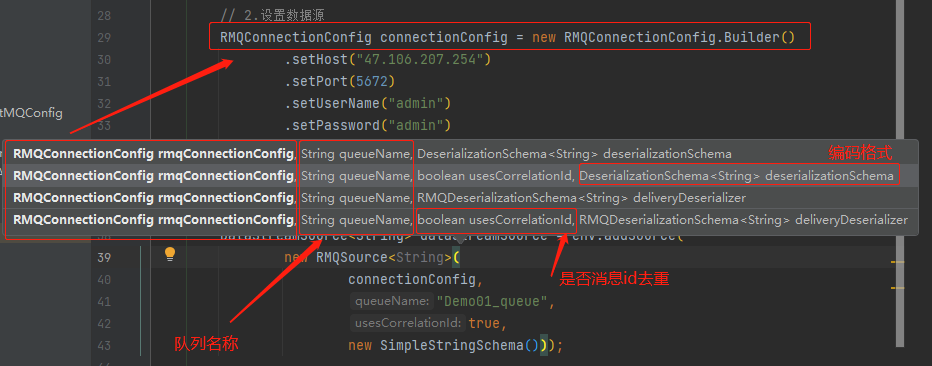
编写java代码
import org.apache.flink.api.common.RuntimeExecutionMode;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.rabbitmq.RMQSource;import org.apache.flink.streaming.connectors.rabbitmq.common.RMQConnectionConfig;import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;@ComponentpublicclassFlinkInitialize{@PostConstructpublicvoidstarter()throws Exception {// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置运行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 2.设置数据源
RMQConnectionConfig connectionConfig =newRMQConnectionConfig.Builder().setHost("47.106.207.254").setPort(5672).setUserName("admin").setPassword("admin").setVirtualHost("/").build();// 3.将RabbitMQ数据源加入
DataStreamSource<String> dataStreamSource = env.addSource(newRMQSource<String>(
connectionConfig,"Demo01_queue",true,newSimpleStringSchema()));// 4.数据转换并输出
dataStreamSource.map(newMapFunction<String, String>(){@Overridepublic String map(String value)throws Exception {return value;}});
dataStreamSource.print();// 5.执行程序
env.execute();}}
在Flink代码中,有两步对于RabbitMQ的加入很关键
示例五:自定义Sink
很简单,把上面的代码稍微改一下就好了
package com.ljm.flink;import org.apache.flink.api.common.RuntimeExecutionMode;import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.rabbitmq.RMQSource;import org.apache.flink.streaming.connectors.rabbitmq.common.RMQConnectionConfig;import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;/**
* @author 李家民
*/@ComponentpublicclassFlinkInitialize{@PostConstructpublicvoidstarter()throws Exception {// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置运行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 2.设置数据源
RMQConnectionConfig connectionConfig =newRMQConnectionConfig.Builder().setHost("47.106.207.254").setPort(5672).setUserName("admin").setPassword("admin").setVirtualHost("/").build();// 3.将RabbitMQ数据源加入
DataStreamSource<String> dataStreamSource = env.addSource(newRMQSource<String>(
connectionConfig,"Demo01_queue",true,newSimpleStringSchema()));// 4.数据转换并输出
dataStreamSource.map(newMapFunction<String, String>(){@Overridepublic String map(String value)throws Exception {return value;}});// 自定义输出
dataStreamSource.addSink(newSinkDemo());// 5.执行程序
env.execute();}}
继承RichSinkFunction抽象类
import org.apache.flink.api.common.eventtime.Watermark;import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;/**
* 自定义Flink输出
* @author 李家民
*/publicclassSinkDemoextendsRichSinkFunction<String>{/**
* 将给定值写入接收器。为每条记录调用此函数
* @param value 获取到的值
* @param context 可用于获取有关输入记录的附加数据的上下文
* @throws Exception
*/@Overridepublicvoidinvoke(String value, Context context)throws Exception {
System.out.println(value +" "+ context.timestamp());}@OverridepublicvoidwriteWatermark(Watermark watermark)throws Exception {super.writeWatermark(watermark);}/**
* 此方法在数据处理结束时调用
* @throws Exception
*/@Overridepublicvoidfinish()throws Exception {
System.out.println("此方法在数据处理结束时调用");}}
接收到数据以后,就可以进行后续的一系列操作了
2.2 DataSet 批处理
组件跟上面的DataStream差不多,都是分为这么三个,
- DataSource
- Transformation
- Sink
一般是用来读取HDFS(分布式文件存储)中的文件数据,不作解释了。
2.3 Table API / SQL(待补充)
Flink针对标准的流处理和批处理提供的两种关系型API:Table API 和 SQL。
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table</artifactId><version>1.14.3</version><type>pom</type><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-common --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>1.14.3</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>1.14.3</version></dependency>
// …
待定 …
// …
2.4 关于序列化
Flink自带针对一些标准类型的序列化器,如果涉及到这些自带的序列化器也无法处理的数据,则需要自定义序列化器。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 使用Avro序列化
env.getConfig().enableForceAvro();// 使用Kryo序列化
env.getConfig().enableForceKryo();// 自定义序列化器
env.getConfig().addDefaultKryoSerializer(xxxxx,xxxxx);
在自定义序列化器参数中,需要填写序列化的类对象类,并且这个类切记需要继承序列化接口Serializer。
三、进阶使用
1 Flink中对于变量的高级用法
前置描述:xxxxxxxxxxxxx
Broadcast
这里的Broadcast指的是广播变量,而不是分区规则。
- DataStream Broadcast(分区规则)
- Flink Broadcast(广播变量)广播变量指再每台机器上保持的一个只读的共享缓存变量,在任务进程需要的时候传递这个共享缓存变量,而不是一个变量副本,可以节省内存,
但是修改广播变量的同时会影响到所有持有这个变量的节点。publicvoidstarter()throws Exception {// 准备环境 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 被广播的数据 DataSource<String> dataSource = env.fromElements("5","6","7","8");// 常规数据 DataSet<String> dataSet = env.fromElements("哈哈哈哈1","哈哈哈哈2","哈哈哈哈3","哈哈哈哈4");// 数据处理// 使用 RichMapFunction, 在open() 方法中拿到广播变量// 由于我是在单个节点上去拿变量的 所以其实放在map方法里面也可以 但是分布式环境下还是得从open方法里获取比较好吧 dataSet.map(newRichMapFunction<String, String>(){@Overridepublic String map(String value)throws Exception {return value;}@Overridepublicvoidopen(Configuration parameters)throws Exception {super.open(parameters); List<String> broadcastVariable =getRuntimeContext().getBroadcastVariable("被广播的共享变量名"); System.out.println("print="+ broadcastVariable);}}).withBroadcastSet(dataSource,"被广播的共享变量名").print();}
Accumulator
累加器,统计Task在运行中的情况,例如在函数中处理了多少条数据,累加器的常用实现有
- IntCounter
- LongCounter
- DoubleCounter
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置并行度
env.setParallelism(1);// 常规数据
DataStream<String> dataSet = env.fromElements("哈哈哈哈1","哈哈哈哈2","哈哈哈哈3","哈哈哈哈4");// 新建累加器
IntCounter counter =newIntCounter();// 数据处理
dataSet.map(newRichMapFunction<String, String>(){@Overridepublic String map(String value)throws Exception {
counter.add(1);return value;}@Overridepublicvoidopen(Configuration parameters)throws Exception {super.open(parameters);// 累加器添加进运行上下文getRuntimeContext().addAccumulator("counter", counter);}}).print();// 执行作业的结果
JobExecutionResult jobExecutionResult = env.execute();// 获取累加器
Integer result = jobExecutionResult.getAccumulatorResult("counter");
System.out.println("累加器之和是="+ result);
你学废了吗
分布式缓存
我的理解就是,一个节点将文件系统注册进集群内,当程序运行后,Flink会自动把这个文件信息复制到其他TaskManager节点的本地文件系统。
- 注册
env.registerCachedFile();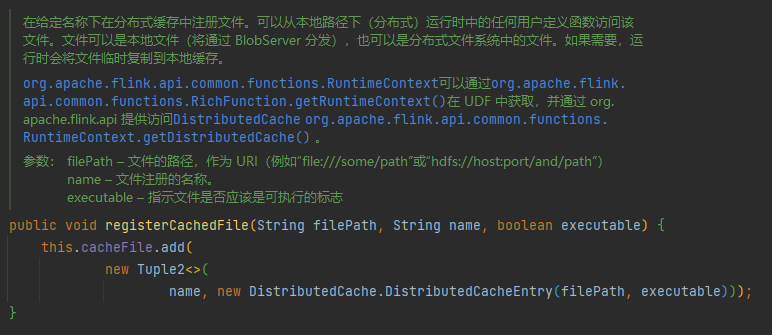
- 访问
File file =getRuntimeContext().getDistributedCache().getFile("文件名");
大概就是这么回事。
总结
- Broadcast只读变量缓存在各节点上,减少内存开销,但是禁止修改该变量。
- Accumulator不同任务中同一变量的累加统计操作,只有任务执行完成后才能得到这个结果。
- Cache分布式缓存系统,结合文件系统实现数据共享。
2 状态管理与恢复(待补充)
文章目录【Flink】Flink 状态管理 - 简书 (jianshu.com)
3 窗口(待补充)
临时补上一个下面会用到的一个时间依赖
<dependency><groupId>joda-time</groupId><artifactId>joda-time</artifactId><version>2.10.5</version></dependency>
Flink的窗口实际上是将无限的流划分为窗口切割成一段一段有限的集合(流是无限的,通常很难对其进行元素计数),它也是从Stream到Batch的一个过程。
而对于窗口的切割的依据,可以由
时间
或
数据量
作为依据驱动,根据需要也可以的进行自定义。
基本窗口可以分为两种
- 时间窗口 - time window:通过时间进行窗口切割。
- 计数窗口 - count window:通过数据量进行窗口切割。
窗口类型
下面具体说说窗口的类型
- Tumbling Window - 滚动窗口,表示窗口内的数据没有重叠。根据时间段进行窗口切割,所以数据故不可能发生重叠。

- Sliding Window - 滑动窗口,表示窗口内的数据有重叠。跟滚动窗口的区别在于,这个滑动是基于窗口的起点偏移量去制定下一个窗口的大小,故数据会发生重叠。
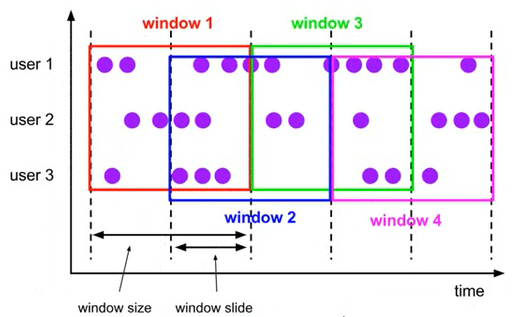
- Session Window - 会话窗口,通过session活动来对元素进行分组,与上述相比,不会有重叠和固定的开始时间和结束时间的情况。
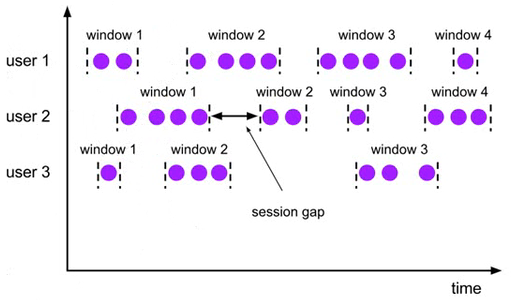
- global Window - 全局窗口,将相同 key 的所有元素聚在一起,但是这种窗口没有起点也没有终点,因此必须自定义触发器。
下面上一个简单的示例代码来对上面打个样
// 时间长度为20秒的滚动窗口
dataStream.keyBy(value ->{return value;}).window(TumblingEventTimeWindows.of(Time.seconds(20)));// 每 10 秒打开 1 分钟的滚动窗口
dataStream.keyBy(value ->{return value;}).window(TumblingProcessingTimeWindows.of(Time.of(1, MINUTES), Time.of(10, SECONDS)));// 每小时 产生15分钟 的偏移量 的滑动窗口
dataStream.keyBy(value ->{return value;}).window(TumblingEventTimeWindows.of(Time.hours(1), Time.minutes(15)));// 全局窗口 将相同 key 的所有元素聚在一起
dataStream.keyBy(value ->{return value;}).window(GlobalWindows.create());// 这个操作将并行度变为1 所有数据放在一个窗口进行操作 不进行分组 所以这个方法的前缀也不需要进行keyBy
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
窗口函数
通常我们的窗口代码中会三个步骤
// Keyed Window
stream
.keyBy(...)<- 按照一个Key进行分组
.window(...)<- 将数据流中的元素分配到相应的窗口中
[.trigger(...)]<- 指定触发器Trigger(可选)
[.evictor(...)]<- 指定清除器Evictor(可选).reduce/aggregate/process()<- 窗口处理函数Window Function
// Non-Keyed Window
stream
.windowAll(...)<- 不分组,将数据流中的所有元素分配到相应的窗口中
[.trigger(...)]<- 指定触发器Trigger(可选)
[.evictor(...)]<- 指定清除器Evictor(可选).reduce/aggregate/process()<- 窗口处理函数Window Function
下面聊聊有关于数据聚合的窗口函数,可以分成两个大类
- 增量聚合函数 - incremental aggregation functions每来一个数据就计算ReduceFuction / AggregationFunction
- 全窗口函数 - full window functions把数据囤积起来,等到最后再一次性遍历计算ProcessWindowFunction / WindowFunction
不学了,以后哪天用到了再补充这里。
参考文章
文章目录旧版本 - Flink 的Window 操作 - 简书 (jianshu.com)
4 时间(待补充)
Stream数据中的时间有三种
- Event Time - 事件产生时间
- Ingestion Time - 事件进入Flink的时间
- Processing Time - 时间被处理时当前的系统时间
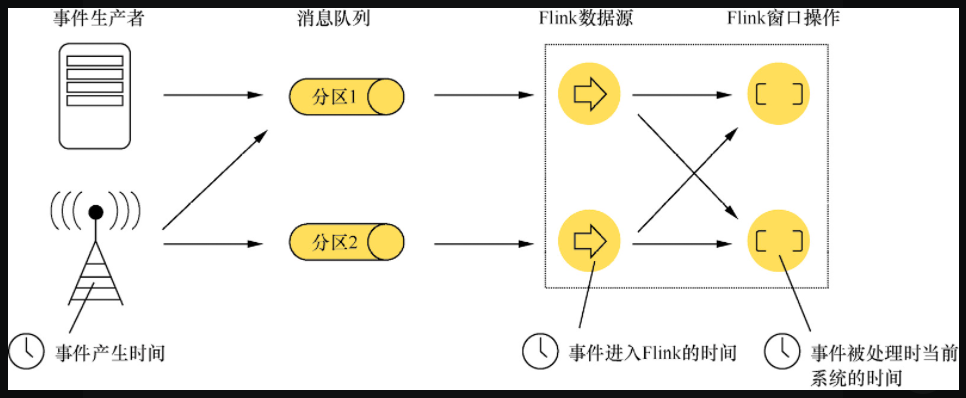
如果是1.2以前的Flink版本
文章目录Flink学习笔记:Time的故事 - 大数据研习社 - 博客园 (cnblogs.com)
新版本的建议使用WatermarkStrategy,通过assignTimestampsAndWatermarks方法进行设置
- 固定乱序长度策略(forBoundedOutOfOrderness)
- 单调递增时间戳策略(forMonotonousTimestamps)
- 不生成水印策略(noWatermarks)
这三种策略都是通过实现WatermarkGenerator接口,下面来看看
publicclassDemoTimeWatermarksimplementsWatermarkGenerator{/**
* 为每个事件调用,允许水印生成器检查并记住事件时间戳,或根据事件本身发出水印
* @param event 接收的事件数据
* @param eventTimestamp 事件时间戳
* @param output 可用output.emitWatermark方法生成一个Watermark
*/@OverridepublicvoidonEvent(Object event,long eventTimestamp, WatermarkOutput output){
System.out.println("event="+ event +" eventTimestamp="+ eventTimestamp +" WatermarkOutput="+ output
);}/**
* 周期性触发,可能会发出新的水印,也可能不会
* 调用此方法和生成水印的时间间隔取决于ExecutionConfig.getAutoWatermarkInterval()
* @param output 可用output.emitWatermark方法生成一个Watermark
*/@OverridepublicvoidonPeriodicEmit(WatermarkOutput output){
System.out.println("被定期执行的方法onPeriodicEmit");}}
固定乱序长度策略
111
publicvoidstarter()throws Exception {// 1.创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 水印生成的间隔时间 5毫秒// 将间隔设置为0将禁用周期性水印发射
env.getConfig().setAutoWatermarkInterval(5L);// 并行度
env.setParallelism(5);// 2.数据来源
DataStreamSource<String> datasource = env.fromElements("1","2","3","345345","$5745457");// 3.数据处理 - 时间策略指定
SingleOutputStreamOperator<String> streamOperator = datasource.assignTimestampsAndWatermarks(// 设定事件时间戳无序的界限 这里是5毫秒
WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofMillis(5)).withTimestampAssigner(// 为元素分配时间戳 从事件数据中抽取newSerializableTimestampAssigner<String>(){@OverridepubliclongextractTimestamp(String event,long recordTimestamp){
System.out.println("event = "+ event);
System.out.println("recordTimestamp = "+ recordTimestamp);return recordTimestamp;}}));// 4.sink输出
streamOperator.print();// 5.任务执行
env.execute();}
111
单调递增时间戳策略
111
不生成水印策略
111
关于水印延迟/窗口允许延迟
文章目录区分理解Flink水印延迟与窗口允许延迟的概念-51CTO.COM
5 并行度
什么是并行度?
一个任务(Source、Transformation、Sink)的并行实例(线程)数目被称为该任务的并行度。
首先从书中了解到,每个TaskManager为集群提供Solt(插槽),Solt的数量通常与每个TaskManager节点的可用CPU内核数成比例,一般情况下Slot的数量就是每个节点的CPU的核数。
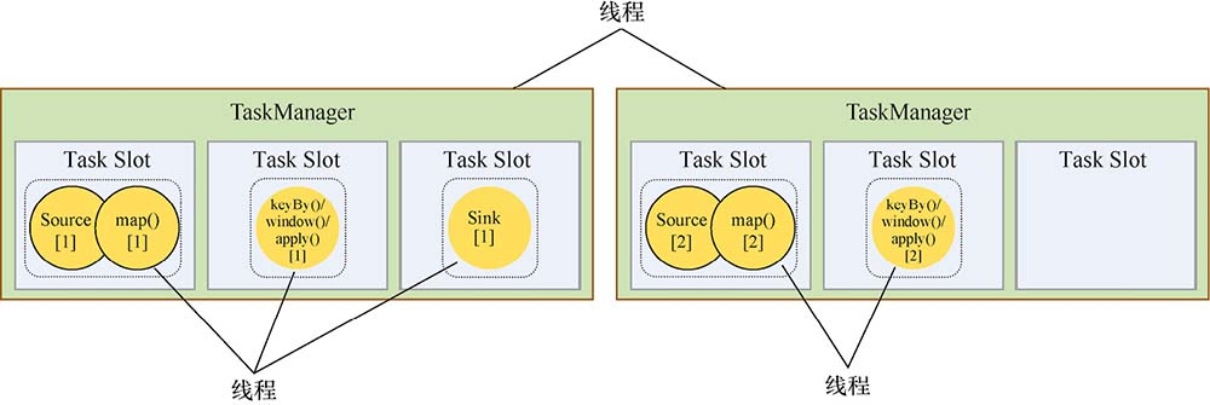
插槽内代表着应用程序所运行的执行图

一个任务的并行度设置可以从4个层面指定
- Operator Level - 算子层面
DataStream<String> dataSet = env.fromElements("哈哈哈哈1","哈哈哈哈2","哈哈哈哈3","哈哈哈哈4");// setParallelism(4) 算子层面dataSet.map(newRichMapFunction<String, String>(){@Overridepublic String map(String value)throws Exception {return value;}}).setParallelism(4).print(); - Execution Environment Level - 执行环境层面
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 执行环境层面env.setParallelism(3); - Client Level - 客户端层面
## 客户端提交job时设定,通过-p参数指定并行度./bin/flink run -p 4 XXXXX.jar - System Level - 系统层面通过修改配置文件conf/flink-conf.yaml中的parallelism.default属性
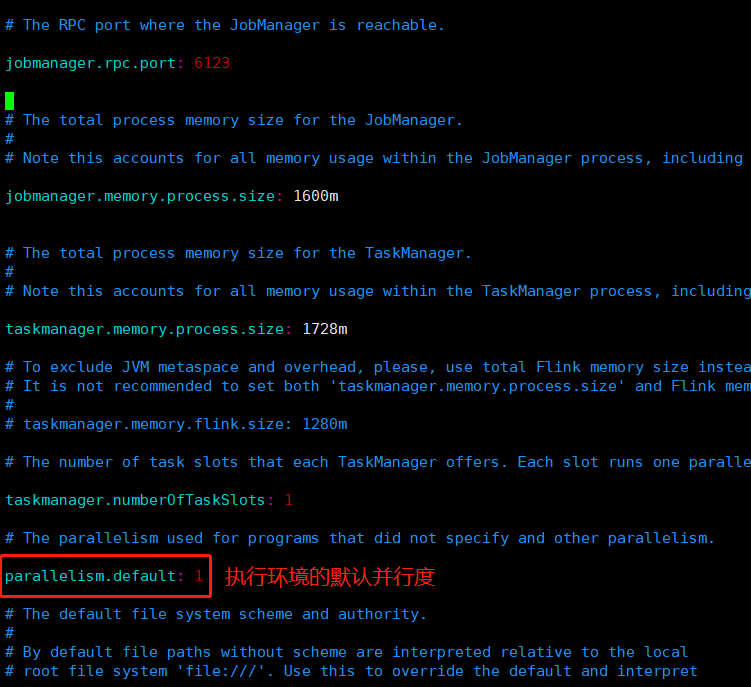
并行度也并非越大越好,上述也提到,需要考虑到CPU内核数。
四、原理解析(待补充)
1
1
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容。
版权归原作者 「已注销」 所有, 如有侵权,请联系我们删除。