
导语
腾讯云消息队列 Kafka 内核负责人鲁仕林为大家带来了《Kafka 分级存储在腾讯云的实践与演进》的精彩分享,从 Kafka 架构遇到的问题与挑战、Kafka 弹性架构方案类比、Kafka 分级存储架构及原理以及腾讯云的落地与实践四个方面详细分享了 Kafka 分级存储在腾讯云的实践与演进。
Kafka 架构遇到的问题与挑战
Kafka 架构
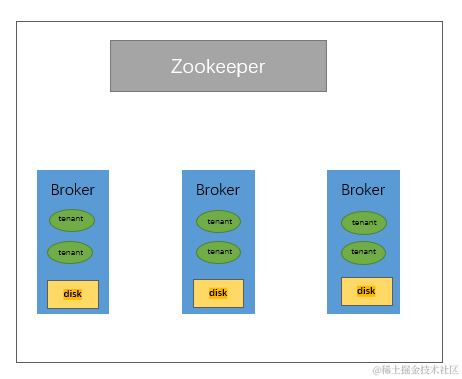
上图是 Kafka 目前本身的架构。腾讯云在线上环境部署 Kafka 集群的时候,都是基于 Zookeeper 或者 Kraft 作为元数据存储,然后使用物理机或者 VM 作为计算资源,本地磁盘作为存储介质来构建集群。
但这种部署模式有以下几个问题:
本地状态比较重,因为数据都是存在本地的,任何的运维操作都需要进行数据搬迁,运维复杂度较高。
这种部署模式,资源是 Broker 维度,所以在进行线上运维的时候,扩缩容都是以 Broker 节点维度进行,但是节点维度的资源分为 CPU、带宽、磁盘等,直接以 Broker 节点维度处理会造成资源浪费。
在线上服务过程中,会有故障恢复或者大量历史数据处理等场景,处理历史数据会有历史数据回溯的问题,造成 pagecache 的污染,会影响集群整体读写 SLA。
接下来带着这三个问题,来看一下具体是哪些场景。
运维难度大
上面有提到过 Kafka 集群在某些运维操作的时候需要进行数据迁移,这就导致了运维难度比较大,那哪些场景会涉及到数据搬迁呢?
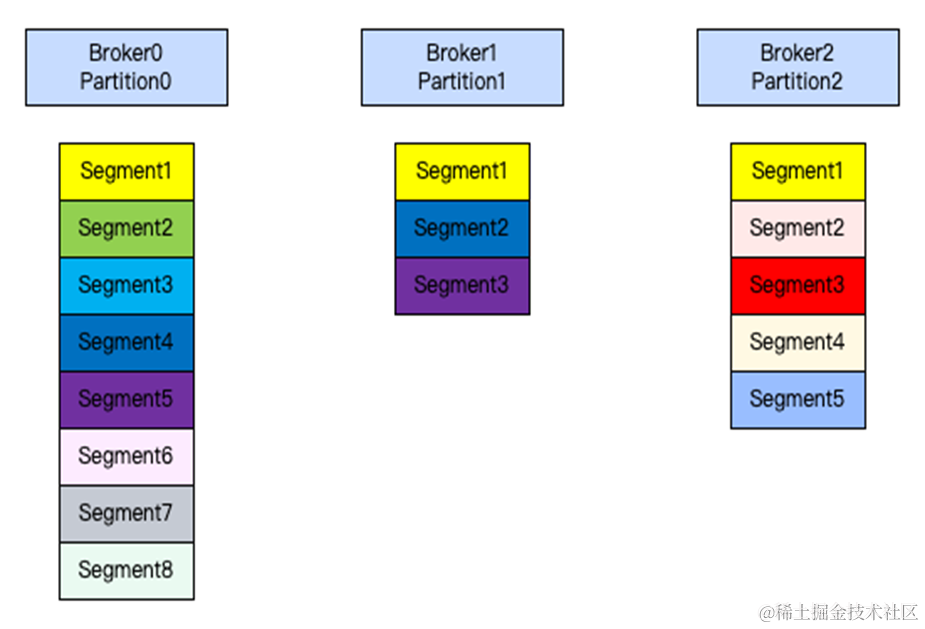
有三种情况:
1、节点间数据分布不均
我们都知道稳态情况下 Kafka 中的 Patition 分区是均匀分布于各个 Broker 节点,但是分区是归属于 Topic 的,而 Topic 又有各种不同的业务场景,不同的业务场景之间的流量是不一样的,所以 Broker 节点分区均匀的情况下,数据不一定分布均匀。
2、节点系统指标瓶颈(带宽、磁盘、CPU 等)
单节点部分物理资源出现系统瓶颈,必须对节点进行升配或者扩容。
3、节点内数据多,迁移较慢且影响读写。
如果日常流量比较大,集群内数据过多的时候,也确实会需要进行数据搬迁。
所以以上三个问题都会导致数据搬迁,数据搬迁在数据量大的时候会涉及到天级别的运维跨度,这其实在线上是难以接受的。
资源浪费
分析系统瓶颈,考虑的资源基本就是 CPU、磁盘、带宽还有内存。
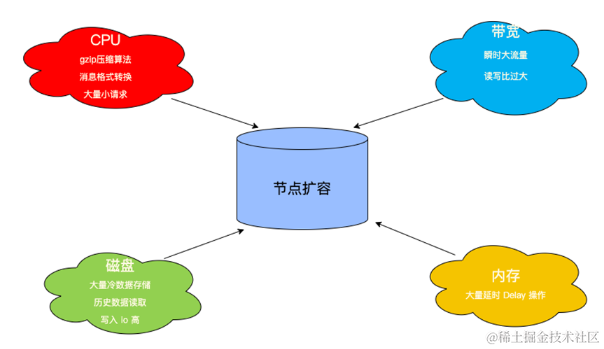
CPU
- 压缩算法(Gzip、Snappy、Zstd等)
- 消息格式转换(V0、V1、V2)
Kafka 如果使用消息压缩,那么就需要在服务端解压缩进行校验,就会消耗大量的 CPU(Gzip 压缩损耗尤其大)。另外在云上客户端的环境是较为复杂的,客户端的版本,使用场景,使用姿势都是未知的。
另外,客户在购买腾讯云 CKafka 集群时可能并不关注集群的版本信息,可能购买的集群版本跟他使用的 SDK 的版本并不是一致的,还会涉及到消息的协议转换,也会损耗大量的 CPU。
磁盘
- 存储空间,大量冷数据存储
- 历史数据 Tail-Read 读取,磁盘 IO 瓶颈
- HDD 磁盘导致大吞吐下磁盘 IO 瓶颈
带宽
- 瞬时流量突刺
- 集群扇出度/读写比大
内存
● Broker 限流后产生大量的 Delay 操作
综上所述,Kafka 在不同使用场景模式下造成的资源瓶颈都是不同的。线上可能就是遇到一个或者几个场景,那么就会带来节点级别的资源损耗。
以上问题大家也都比较了解,这些问题都是因为 Kafka 本地状态比较重,存储在本地,存储和计算资源没有解耦造成的,要解决这些问题就需要引入比较成熟的弹性架构来帮助它实现架构上面的弹性,资源的解耦。
Kafka 弹性架构方案对比
存储计算分离架构
存储计算分离架构是最开始考虑的,也是目前 Pulsar 采用的架构,Pulsar 底层的存储是 Bookkeeper,图中的架构是 HDFS 作为存储底座,该架构就是一套云原生的存储计算分离架构。
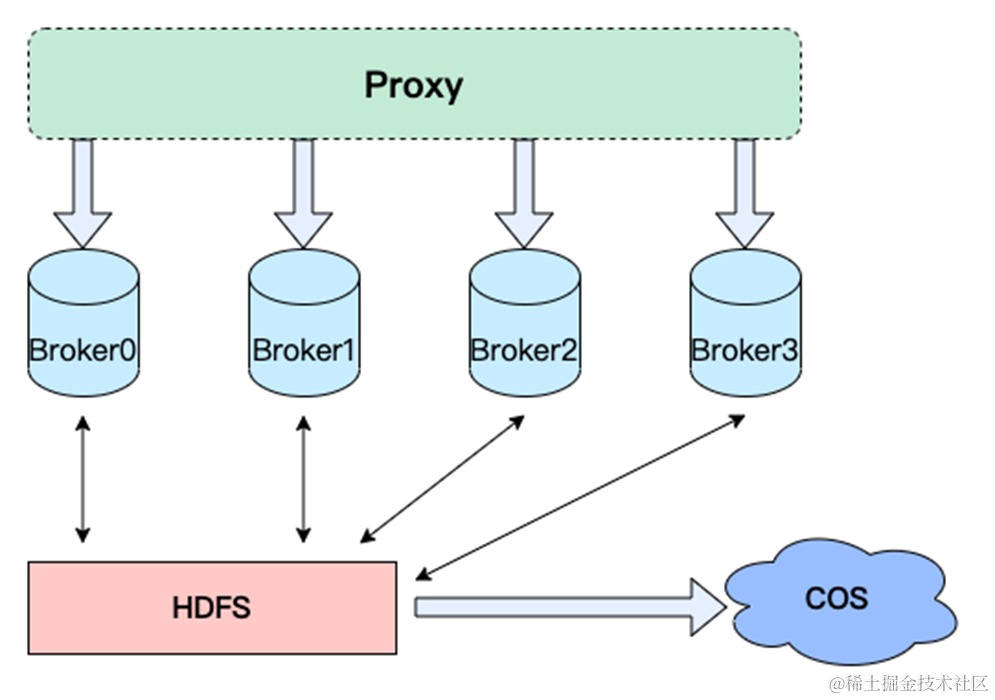
- Proxy 负责统一接入,负责服务发现、限流包括格式转换,一些通用需求的功能上传上浮化。
- Broker 作为 Partition 的 Holder 用来适配多套存储介质,比如 HDFS、Bookkeeper ,起到 Partition 之间的负载均衡的作用。
- 存储层可以用到多模的存储,比如 HDFS、腾讯云 COS、亚马逊 S3 等。
这个架构优势比较明显,可以看到计算资源跟存储资源是完全解耦的,扩容的时候有以下优势:
- 节点扩容无需进行数据迁移
- 存储节点与计算节点分离,可以按需扩容
虽然从理论上看是有优势的,但从实际落地来看,有两个比较明显的问题。
HDFS 或者 Bookkeeper 都会遇到一个问题,就是切文件的时候。老文件需要进行 Recover Lease,新文件需要进行元数据的存储(强依赖 Zookeeper/Etcd 等),所以在切换文件的时候会有毛刺抖动。
可以看到存储系统加 HDFS 在这个架构里面其实是一个强依赖关系,如果它断了,那么生产消费都是运行不上去的,只能等系统恢复。
这两个问题在线上是比较严重的问题,而且很难找到非常靠谱的存储系统去承载它,强依赖的关系在系统设计过程中也是不可取的,最好是对外部系统弱依赖。
弹性的本地存储架构
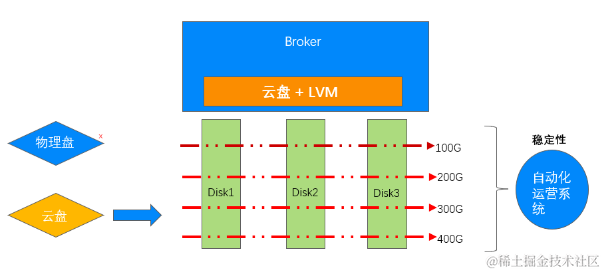
第二个架构是目前 CKafka 比较广泛的一套架构,核心逻辑就是云盘 + 云主机,然后依赖自动化运营系统结合云盘的 LVM 以及云主机的热迁移实现快速扩容。
自动化运营系统就是用来监控资源的使用量,比如说使用的是100G的磁盘,已经用到90G了,那么就可以用自动化运营系统监测到 90%的磁盘,需要进行磁盘扩容,那么我们就可以自动化的申请云盘,做 LVM 增加存储空间以及吞吐能力。
自动化运营系统同时会监控计算资源节点的运行情况,监控发现计算资源如 CPU、内存有瓶颈,则会使用腾讯云 CVM 或者容器的热迁移进行计算资源的垂直升配。
这是目前腾讯云线上正在使用的一套产品架构,但是这个产品架构之前也说到了是有缺陷的。它只能垂直扩容,但是分布式系统都是分布式的,只以垂直扩容肯定是不够的,肯定要在横向具备扩容的功能,所以说这种系统在横向扩容领域还是和原生 Kafka 系统有类似问题。
弹性的远程存储架构
所以针对以上两个弹性架构带来的问题,作者又思考了一些新的可能,看能否本地存储和远程存储结合起来,Kafka 的分级存储,本地会有少量的云盘热数据,远程存储有大量的冷数据。
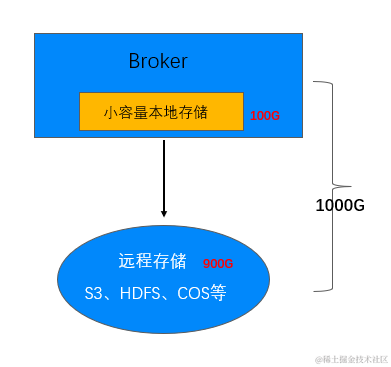
本地弹性存储
- 本地存储服务写流量/Tail-Read 读,提供与原生 Kafka 一致的延时、可用性和一致性。
- 远程存储故障或者性能衰退,本地存储支持弹性扩容提供读写服务。
远程弹性存储
- 远程存储服务 Catch- Up 读,冷热数据分离。
- 按需使用,按量计费。
- 支持多模存储,多介质存储。
优势
1、 第一个优势在于写入延迟和本地写入延时是一致的,在远程存储出现故障或者毛刺的时候,可以退化为本地存储,再结合自动化运营系统对本地存储形态进行动态扩容。
2、 第二个优势在于远程的存储相对廉价,可以从一定程度上实现降本。
结合成本以及服务稳定性以及可落地性这几方面,我们选择本地存储+远程存储构建 Kafka 的弹性架构。
Kafka 分级存储架构
接下来我们来聊一下分级存储当前的加固是怎么实现的?包括它的语义是什么?它能提供怎么样的数据的生命周期管理?
分级存储读写流程
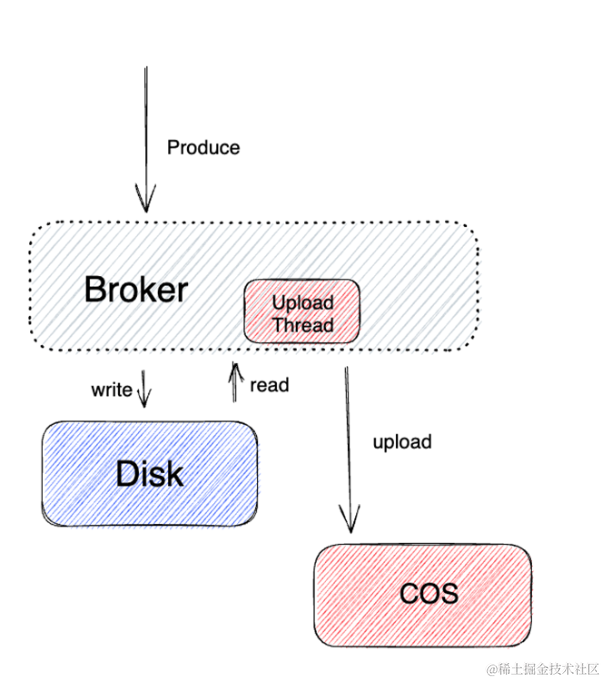
分层生产流程
生产的主体流程和原生 Kafka 类似,写入到云盘的数据会异步同步到远端存储 COS。
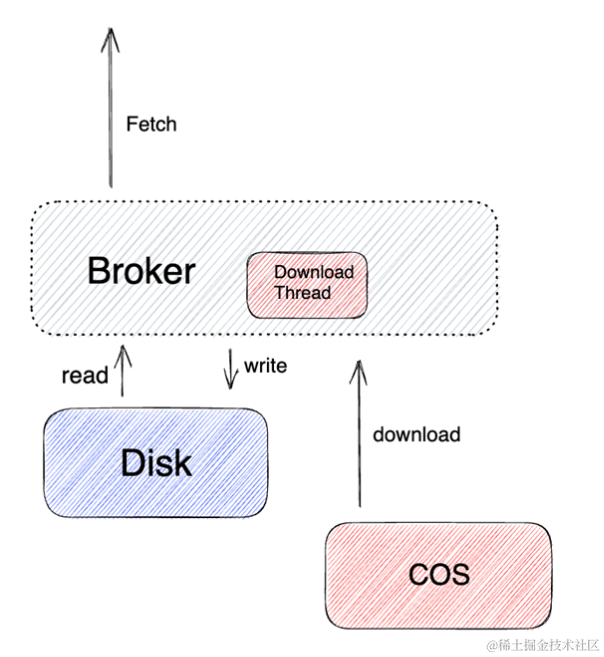
分层消费流程
消费的流程也是类似的,会根据用户 Consumer 的 Offset来做一个比较,如果是在本地存储,那么就本地存储优先返回。如果本地存储没有,那就从远端存储里面去实时读取,或者说根据不同的读取策略有不同的读取下载策略,进行消息读取的消费。
数据生命周期
引入了分层存储之后,数据就不只存储在本地了,就涉及到远端跟本地的数据生命周期的管理。
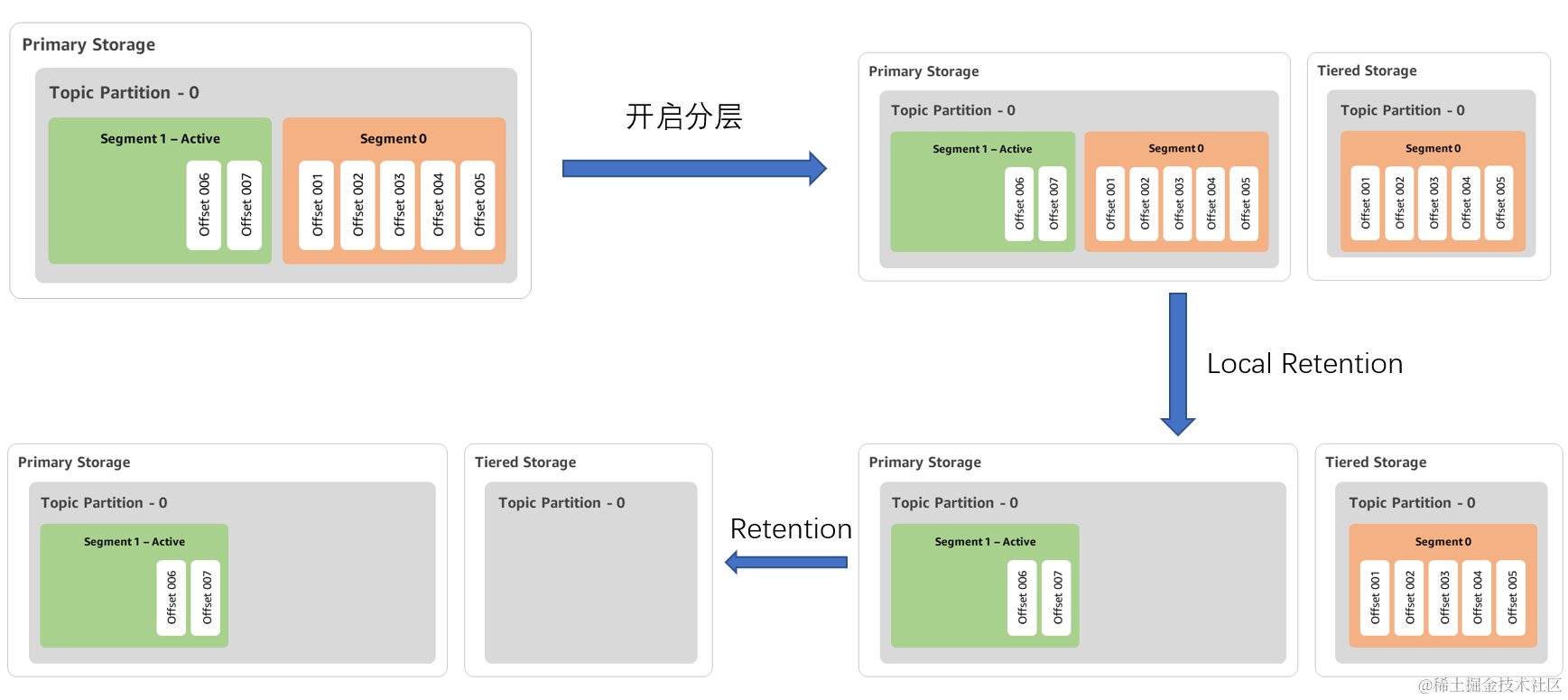
上面这四个图就是一个完整的开启分层存储之后数据的流转。
Kafka Broker 存储数据的最小文件单元为 Segment,Segment 可以划分为 Active/Inactive 两种类型,Active Segment 是指当前正在写入的 Segment,Inactive Segment 则反之。
开启分层之后,只会上传 Inactive Segment,对应图中开启分层后先上传 Segment 0。
Local Rentention 参数,Inactive Segment 上传到远程存储之后,本地其实可以删除了,这里设计了一个参数 Local Rentention,控制本地已上传文件的保存时间。
Rentention 参数,该参数在原生 Kafka 中就有体现,该参数的语义为 Topic 数据的保存时间,对应图中到 Rentention 时间之后远端数据进行数据删除。
这 1-4 步骤的状态流转即构成了 Kafka 本地以及远端数据的生命周期管理。
Offset 约束
Kafka 中每条 Message 都对应 Offset 位点,消息数据涉及从本地上传到远端,所以对于上传的 Offset 是有一定约束的。
图一:

图二:
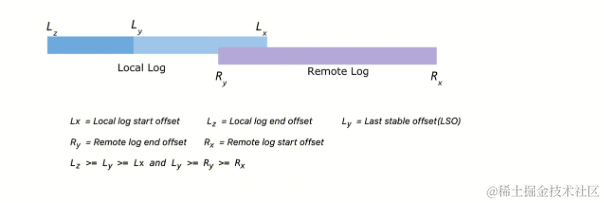
图二中从左到右分别为 Lz,Ly,Ry,Lx,Rx。
- Lz(Local log end offset),本地数据中最新数据的 Offset 位点。
- Ly(Last stable offset),本地数据中,符合消费可见的数据,Kafka 中有 消费可见/事务可见 两种消息隔离级别。
- Ry(Remote log end offset),远端数据中最新数据的 Offset 位点。
- Lx(Local log start offset),本地数据中最老数据的 Offset 位点。
- Rx(Remote log start offset),远端数据中最老数据的Offset 位点。
Offset 约束为 Lz >= Ly >= Lx 和 Ly >= Ry >= Rx 两条规则。
Segment 状态机
上文有提到过,数据从本地上传到远程是按照 Segment 维度进行上传的,那么每个 Segment 在上传过程中就会有各种状态,通过 Segment 状态机可以实现 Segment 状态流转以及状态管理。
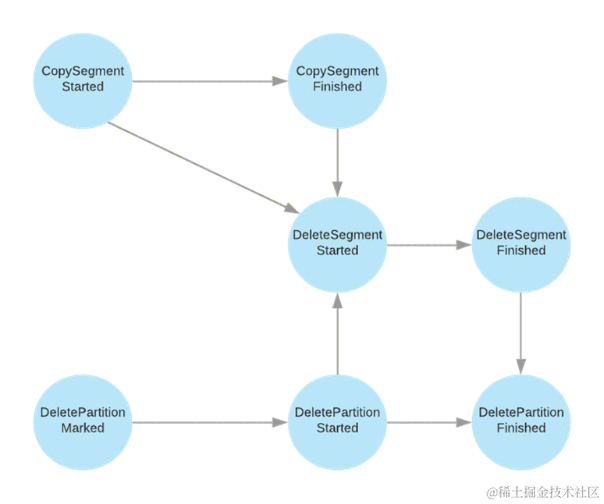
Segment 状态流转主要体现在三个维度,CopySegment,DeleteSegment,DeletePartition。
- CopySegment○ CopySegmentStarted -> CopySegmentFinished
- DeleteSegment○ DeleteSegmentStarted -> DeleteSegmentFinished
- DeletePartition○ DeletePartitionMarked -> DeletePartitionStarted -> DeletePartitionFinished
同时状态流转中,从一个状态转换到另一个状态是有限制的,比如:不能只能从 CopySegmentStarted -> DeleteSegmentStarted,从 CopySegmentStarted到DeleteSegmentStarted 必须保证:CopySegmentStarted -> CopySegmentFinished -> DeleteSegmentStarted。
分级存储架构
上文介绍了 Kafka 分级存储的读写流程、数据生命周期、Segment 状态流转,那么这些逻辑在 Kafka 原生系统中是在哪里实现的呢?
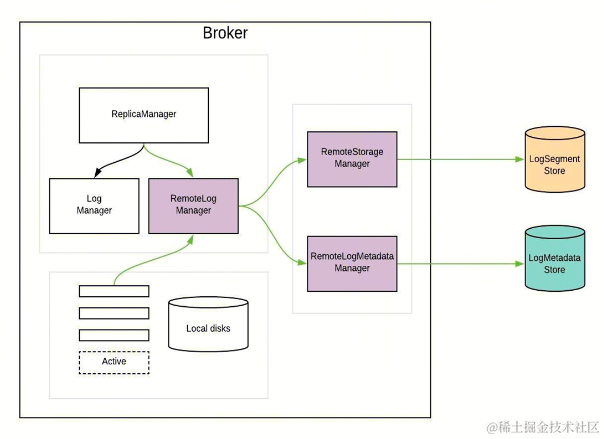
下图中介绍了整个 Kafka 存储的类以及架构图:
- Kafka ReplicaManager,负责管理本地存储 LogManager 以及远程存储 RemoteLogManager。
- 本地存储 LogManager,负责本地数据的生命周期管理。
- 远程存储 RemoteLogManager,负责远程存储的生命周期管理以及 Segment 元数据管理。○ RemoteStorageManager 负责远程存储的生命周期管理。○ RemoteLogMetadataManager 负责 Segment 元数据管理。
- 元数据存储○ ETCD/ZooKeeper 作为元数据存储服务,负责元数据的存储以及 Recovery。
腾讯云的落地与实践
Segment 元数据管理
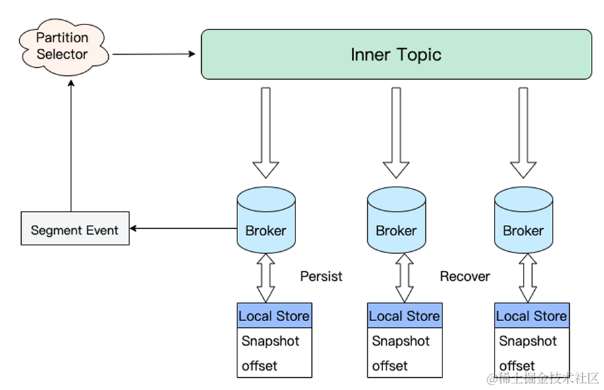
如下图:
- 依赖内部 Inner-Topic 作为 WAL 进行元数据信息同步。
- Broker 消费 WAL 进行内存状态机状态构建。
- Broker 定期持久化内存快照 Snapshot 以及快照对应的 Offset 到 Broker 本地。
- Broker 依赖 Snapshot 和增量 WAL 进行状态机 Recovery。
消费性能
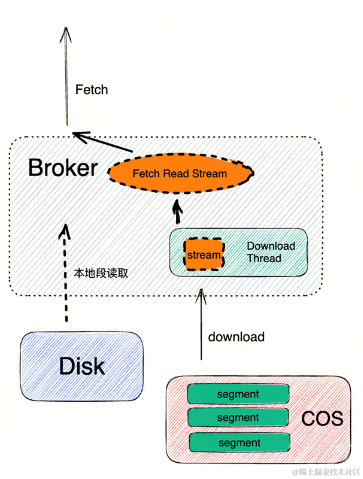
上文读写流程中介绍了,写流程其实和原生 Kafka 是类似的,所以写性能基本和原生 Kafka 持平,大家可能都比较担心读取性能,比如读取历史数据的吞吐、SLA、数据可靠性等。在线上实践过程中,我们使用 COS 作为远程存储,在初步实践过程中发现直接使用 COS Stream 流式读取会有性能瓶颈问题。使用以下几个方案去提升读取性能。
预加载的方式,规划内存池进行消息的预读和预加载。
有空闲资源时对热点数据提前下载。
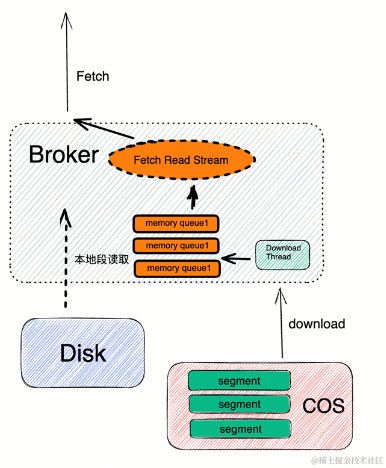
隔离性
因为引入了第三方存储,大家也知道线上的稳定性是第一重要的,稳定性就是生命性,所以说它的隔离性也是非常重要的。
硬盘
- 独立的 IO 盘,减少磁盘 IO 影响
CPU
- 核心线程进行绑核
- 线程隔离
带宽
- 上传/下载限流
- 上传/下载任务并行度控制
内存
- 使用堆外内存
- ByteBuffer 复用
回滚
- 暂停分层上传能力
- 按需暂停分层数据下载能力
- 运营系统自动扩容云盘
- 支持 Topic/集群维度回滚
未来展望
整体落地的架构以上都有介绍的比较清楚,最终我们还是讲一下未来怎么发展。
大家都知道数据存到第三方存储之后,你对这部分数据的可操控性就强了很多,因为数据存在HDFS,那么你对文件就有操纵的能力。
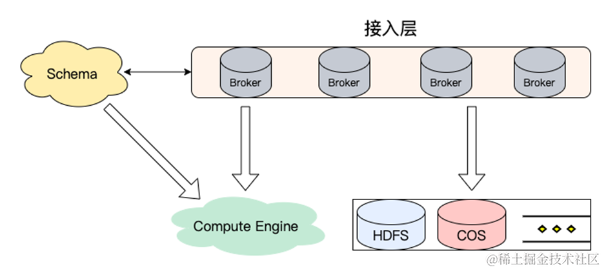
Schema
- 消息格式存储(Protobuf、Json)
目前大数据、数据符这种概念在业界传播很广,在各大厂或者各个公司都有不同的场景,Broker 把这部分数据转存到 HDFS 或者COS的时候,我们也可以转存一份 Schema或者Protobuf、Json等。Broker只是做计算层,不光可以上传数据,也可以把 Schema 这个功能运用起来,然后把那个数据格式进行转化。
接入层
- 流量接入,无状态可横向扩展
Compute Engine
- 格式转换计算层,如:行列格式转换(Parquet)
- Parquet 直接对接 Hudi/Delta Lake
- 云 Api 获取文件
存储层
- 多模存储,数据分级
- 软硬件结合,探索新的存储系统
版权归原作者 腾讯云中间件 所有, 如有侵权,请联系我们删除。