
一、端到端精准一次
先来讲讲状态一致性
状态一致性概念:
一致性其实就是结果的正确性。对于分布式系统而言,强调的是不同节点中相同数据的副本应该总是“一致的”。
而对于 Flink 来说,多个节点并行处理不同的任务,我们要保证计算结果是正确的,就必须不漏掉任何一个数据,而且也不会重复处理同一个数据。流式计算本身就是一个一个来的,所以正常处理的过程中结果肯定是正确的;但在发生故障、需要恢复状态进行回滚时就需要更多的保障机制了。
状态一致性分类:
- 最多一次(AT-MOST-ONCE)当任务发生故障时,最简单的做法就是直接重启,别的什么都不干;既不恢复丢失的状态,也不重放丢失的数据。每个数据在正常情况下会被处理一次,遇到故障时就会丢掉,所以就是“最多处理一次”。我们发现,如果数据可以直接被丢掉,那其实就是没有任何操作来保证结果的准确性;所以这种类型的保证也叫“没有保证”。尽管看起来比较糟糕,不过如果我们的主要诉求是“快”,而对近似正确的结果也能接受,那这也不失为一种很好的解决方案。
- 至少一次(AT-LEAST-ONCE)
在实际应用中,我们一般会希望至少不要丢掉数据。这种一致性级别就叫作“至少一次”(at-least-once),就是说是所有数据都不会丢,肯定被处理了,不过不能保证只处理一次,有些数据会被重复处理。 在有些场景下,重复处理数据是不影响结果的正确性的,这种操作具有“幂等性”。了保证达到 at-least-once 的状态一致性,我们需要在发生故障时能够重放数据。最常见的做法是,可以用持久化的事件日志系统,把所有的事件写入到持久化存储中。这时只要记录一个偏移量,当任务发生故障重启后,重置偏移量就可以重放检查点之后的数据了。Kafka 就是这种架构的一个典型实现。
- 精确一次(EXACTLY-ONCE)
最严格的一致性保证,就是所谓的“精确一次”(exactly-once,有时也译作“恰好一次”)。
这也是最难实现的状态一致性语义。exactly-once 意味着所有数据不仅不会丢失,而且只被处理一次,不会重复处理。也就是说对于每一个数据,最终体现在状态和输出结果上,只能有一次统计。 exactly-once 可以真正意义上保证结果的绝对正确,在发生故障恢复后,就好像从未发生过故障一样。 很明显,要做的 exactly-once,首先必须能达到 at-least-once 的要求,就是数据不丢。所以同样需要有数据重放机制来保证这一点。另外,还需要有专门的设计保证每个数据只被处理一次。
Flink 中使用的是一种轻量级快照机制——检查点(checkpoint)来保证 exactly-once 语义。
端到端一致性概念:
- 什么叫端到端的一致性?跟状态一致性有什么区别?在Flink流处理应用中,总共有四大模块,执行环境,数据源、流处理器和外部存储系统四个部分。
如果做到状态一致性中的至少一次(AT-LEAST-ONCE)程度,主要看数据源能够重放数据。做到状态一致性中的精确一次(EXACTLY-ONCE)程度,流处理器、数据源、外部存储都要有保证机制。保证了这三大模块的一致性,就叫作“端到端(end-to-end)的状态一致性”。
- 具体的方案是什么?- 在流处理器中使用检查点保证精准一致性- 在数据源端使用数据偏移量进行“数据重放”保证精准一致性- 在输出端,做幂等写入、或者事务写入,防止消息的重复消费
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qkGsdyla-1681811696794)(image-20230413144218875.png)]](https://img-blog.csdnimg.cn/f032107216914e89ad57694b7cd9f663.png)
(1)数据源端如何保证
选择可以进行“数据重放”的数据源。
先来举例,典型的不能进行“数据重放”的数据源
例如socket 文本流, socket 服务器是不负责存储数据的,发送一条数据之后,我们只能消费一次,是“一锤子买卖”。对于这样的数据源,故障后我们即使通过检查点恢复之前的状态,可保存检查点之后到发生故障期间的数据已经不能重发了,这就会导致数据丢失。所以就只能保证 at-most-once 的一致性语义,相当于没有保证。
有没有能够进行“数据重放”的数据源呢?
一个最经典的应用就是 Kafka。在 Flink 的 Source 任务中将数据读取的偏移量保存为状态,这样就可以在故障恢复时从检查点中读取出来,对Kafka中的数据源重置偏移量,重新获取数据。
(2)输出端如何保证
- 幂等写入
所谓“幂等”操作,就是说一个操作可以重复执行很多次,但只导致一次结果更改。
缺点:
对于幂等写入,遇到故障进行恢复时,有可能会出现短暂的不一致。因为保存点完成之后到发生故障之间的数据,其实已经写入了一遍,回滚的时候并不能消除它们。如果有一个外部应用读取写入的数据,可能会看到奇怪的现象:短时间内,结果会突然“跳回”到之前的某个值,然后“重播”一段之前的数据。不过当数据的重放逐渐超过发生故障的点的时候,最终的结果还是一致的。
- 事务写入
用一个事务来进行数据向外部系统的写入,这个事务是与检查点绑定在一起的。当 Sink 任务遇到 barrier 时,开始保存状态的同时就开启一个事务,接下来所有数据的写入都在这个事务中;待到当前检查点保存完毕时,将事务提交,所有写入的数据就真正可用了。如果中间过程出现故障,状态会回退到上一个检查点,而当前事务没有正常关闭(因为当前检查点没有保存完),所以也会回滚,写入到外部的数据就被撤销了。
- 为什么需要事务呢?
因为幂等写入最大的问题就是“覆水难收”,无法收回外部系统的数据,造成“短暂的不一致性”
⭐️所以事务出现的原因就在于,通过严格控制sink输出,有问题的数据先不输出到外部应用,不给外部应用重复消费的机会,而不是幂等写入的重复的数据处理两次
事务实现的两种方式:
- 预写日志
具体步骤:
- sink里使用接口GenericWriteAheadSink
- 先把结果数据作为日志(log)状态保存起来
- 进行检查点保存时,也会将这些结果数据一并做持久化存储
- 在收到检查点完成的通知时,将所有结果一次性写入外部系统。
- 进行二次确认,一旦外部系统写入失败,再将保存的checkPoint删除
优点:
- 实现简单
- 在二次确认的时候外部系统写入失败,还得重新保存检查点。
⭐️缺点:
- 日志写入到外部系统是批处理,不符合流式处理的思想
- 假设日志写入外部系统失败,检查点保存的就得删除
- 两阶段提交2PC(还行)
大概思路:
构建的事务对应着checkpoint,等到checkpoint真正完成的时候,才提交输出的数据。
具体步骤:
- 当第一条数据到来时,或者收到检查点的分界线时,Sink 任务都会启动一个事务。
- 接下来接收到的所有数据,都通过这个事务写入外部系统;这时由于事务没有提交,所以数据尽管写入了外部系统,但是不可用,是“预提交”的状态。
- 当 Sink 任务收到 JobManager 发来所有taskManager检查点保存完成的通知时,正式提交事务,写入的结果就真正可用了。
其实这里就有个疑问,为什么2pc保护的是检查点后面的新数据,而不是检查点之前的数据?
首先明确sink和其他算子任务的区别。就是sink是处理数据的最后一部分,一旦处理barrier时,之前的数据输出了就输出了,无所谓,最后一步已经走完了。
那么在检查点保存的时候,系统故障,保存检查点失败,那么恢复检查点的时候,恢复的是上次成功保存检查点的数据偏移量,如果不对新数据进行保护,可能就会把之前有可能sink过的部分数据重新消费一次,造成重复消费。
⭐️(3)借助Kafka实现端到端一致
1)各个端如何进行修改:
1) Flink 内部
- 启用检查点
2)输入端
- 输入数据源端的 Kafka 可以对数据进行持久化保存,并可以重置偏移量(offset)。所以我们可以在 Source 任务(FlinkKafkaConsumer)中将当前读取的偏移量保存为算子状态,写入到检查点中;当发生故障时,从检查点中读取恢复状态,并由连接器 FlinkKafkaConsumer 向 Kafka 重新提交偏移量,就可以重新消费数据、保证结果的一致性了。
3)输出端
- 在sink时, FlinkKafkaProducer 的构造函数中传入参数 Semantic.EXACTLY_ONCE,表示精准一次。
4)Kafka
- 配置写入外部系统时消费者的事务隔离级别 为read_committedKafka 中默认的隔离级别 isolation.level 是 read_uncommitted,也就是可以读取未提交的数据。这样一来,flink在计算完结果输出数据后,外部应用就可以直接读取未提交的数据,对于事务性的保证就失效了。所以应该将隔离级别配置 为 read_committed,表示消费者遇到未提交的消息时,会停止从分区中消费数据,直到消息被标记为已提交才会再次恢复消费。当然,这样做的话,外部应用读取flink输出的数据就会有显著的延迟。
- 配置Flink与Kafka配置的事务提交的超时时间Flink的Kafka连接器中配置的事务超时时间transaction.timeout.ms默认是1小时而Kafka 集群配置的事务最大超时时间 transaction.max.timeout.ms 默认是 15 分钟所以最后要配置的事务时间,应该小于Kafka配置的事务最大超时时间
2)示例代码:
pom文件中引入依赖:
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><flink.version>1.13.0</flink.version><java.version>1.8</java.version><scala.binary.version>2.12</scala.binary.version><slf4j.version>1.7.30</slf4j.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency><!--1.12.0需要在服务器上引入如下两个jar包--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-base</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.4.1</version></dependency><!--flink通用连接kafka 可以在写代码时不用指定版本 2.12代表scala版本--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency><!-- 引入Flink相关依赖--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><!-- 引入日志管理相关依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency></dependencies>
- Flink内部- 调用setCheckpointInterval设定多久一次存储检查点- 调用setCheckpointingMode设置语义是精准一次
//1.flink内部保证精准一次:设置检查点CheckpointConfig checkpointConfig = env.getCheckpointConfig();//10s内保存一次检查点checkpointConfig.setCheckpointInterval(10000);//保存检查点的超时时间为5秒钟checkpointConfig.setCheckpointTimeout(5000);//新一轮检查点开始前最少等待上一轮保存15秒才开始checkpointConfig.setMinPauseBetweenCheckpoints(15000);//设置作业失败后删除检查点(默认)checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);//设置检查点模式为精准一次(默认)checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); - 输入端- FlinkKafkaConsumer必须调用setCommitOffsetsOnCheckpoints方法执行Checkpoint的时候提交offset到Checkpoint,当重启Flink时,Flink作业会告诉kafka我要从哪个offset开始消费,这样我们的数据也就恢复
Properties props_source =newProperties();props_source.setProperty("bootstrap.servers","node1:9092");props_source.setProperty("group.id","flink");props_source.setProperty("auto.offset.reset","latest");//会开启一个后台线程每隔5s检测一下Kafka的分区情况props_source.setProperty("flink.partition-discovery.interval-millis","5000");FlinkKafkaConsumer<String> kafkaSource =newFlinkKafkaConsumer<>("flink_kafka",newSimpleStringSchema(), props_source);kafkaSource.setStartFromLatest();//2.输入端保证:执行Checkpoint的时候提交offset到Checkpoint(Flink用)kafkaSource.setCommitOffsetsOnCheckpoints(true);DataStreamSource<String> kafkaDS = env.addSource(kafkaSource); - 输出端- 设置Flink等待事务的超时时间,- 设置语义为精准一次
Properties props_sink =newProperties(); props_sink.setProperty("bootstrap.servers","node1:9092");//3.1 设置事务超时时间,也可在kafka配置中设置 props_sink.setProperty("transaction.timeout.ms",1000*5+"");FlinkKafkaProducer<String> kafkaSink =newFlinkKafkaProducer<>("flink_kafka2",newKeyedSerializationSchemaWrapper<String>(newSimpleStringSchema()), props_sink,//3.2 设置输出的的语义为精准一次FlinkKafkaProducer.Semantic.EXACTLY_ONCE ); result.addSink(kafkaSink); - 完整代码
packagecom.ming.test1;importorg.apache.commons.lang3.SystemUtils;importorg.apache.flink.api.common.functions.FlatMapFunction;importorg.apache.flink.api.common.functions.RichMapFunction;importorg.apache.flink.api.common.serialization.SimpleStringSchema;importorg.apache.flink.api.java.tuple.Tuple;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.runtime.state.filesystem.FsStateBackend;importorg.apache.flink.streaming.api.CheckpointingMode;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.datastream.KeyedStream;importorg.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;importorg.apache.flink.streaming.api.environment.CheckpointConfig;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;importorg.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;importorg.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;importorg.apache.flink.util.Collector;importjava.util.Properties;importjava.util.Random;publicclass test {publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();//1.flink内部保证精准一次:设置检查点CheckpointConfig checkpointConfig = env.getCheckpointConfig();//10s内保存一次检查点 checkpointConfig.setCheckpointInterval(10000);//保存检查点的超时时间为5秒钟 checkpointConfig.setCheckpointTimeout(5000);//新一轮检查点开始前最少等待上一轮保存15秒才开始 checkpointConfig.setMinPauseBetweenCheckpoints(15000);//设置作业失败后删除检查点(默认) checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);//设置检查点模式为精准一次(默认) checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); env.setStateBackend(newFsStateBackend("file:///Users/xingxuanming/Downloads/flink-checkpoint/checkpoint"));Properties props_source =newProperties(); props_source.setProperty("bootstrap.servers","node1:9092"); props_source.setProperty("group.id","flink"); props_source.setProperty("auto.offset.reset","latest");//会开启一个后台线程每隔5s检测一下Kafka的分区情况 props_source.setProperty("flink.partition-discovery.interval-millis","5000");FlinkKafkaConsumer<String> kafkaSource =newFlinkKafkaConsumer<>("flink_kafka",newSimpleStringSchema(), props_source); kafkaSource.setStartFromLatest();//2.输入端保证:执行Checkpoint的时候提交offset到Checkpoint(Flink用) kafkaSource.setCommitOffsetsOnCheckpoints(true);DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);SingleOutputStreamOperator<Tuple2<String,Integer>> wordAndOneDS = kafkaDS.flatMap(newFlatMapFunction<String,Tuple2<String,Integer>>(){@OverridepublicvoidflatMap(String value,Collector<Tuple2<String,Integer>> out)throwsException{//value就是每一行String[] words = value.split(" ");for(String word : words){Random random =newRandom();int i = random.nextInt(5);if(i >3){System.out.println("出bug了...");thrownewRuntimeException("出bug了...");} out.collect(Tuple2.of(word,1));}}});KeyedStream<Tuple2<String,Integer>,Tuple> groupedDS = wordAndOneDS.keyBy(0);SingleOutputStreamOperator<Tuple2<String,Integer>> aggResult = groupedDS.sum(1);SingleOutputStreamOperator<String> result =(SingleOutputStreamOperator<String>) aggResult.map(newRichMapFunction<Tuple2<String,Integer>,String>(){@OverridepublicStringmap(Tuple2<String,Integer> value)throwsException{return value.f0 +":::"+ value.f1;}});//3.输出端保证Properties props_sink =newProperties(); props_sink.setProperty("bootstrap.servers","node1:9092");//3.1 设置事务超时时间,也可在kafka配置中设置 props_sink.setProperty("transaction.timeout.ms",1000*5+"");FlinkKafkaProducer<String> kafkaSink =newFlinkKafkaProducer<>("flink_kafka2",newKeyedSerializationSchemaWrapper<String>(newSimpleStringSchema()), props_sink,//3.2 设置输出的的语义为精准一次FlinkKafkaProducer.Semantic.EXACTLY_ONCE ); result.addSink(kafkaSink); env.execute();}进行测试:先确认下,这里不用关闭应用程序,再重启应用程序来模拟故障,而是程序里模拟故障,用随机数直接throw Exeception进入到kafka的bin目录下- 启动zookeeper./zookeeper-server-start.sh …/config/zookeeper.properties &- 启动kafka./kafka-server-start.sh …/config/server.properties &- 创建主题kafka-topics.sh --bootstrap-server localhost:2181 --create --replication-factor 2 --partitions 3 --topic flink_kafka2- 打开控制台生产者kafka-console-producer.sh --broker-list localhost:9092 --topic flink_kafka- 打开控制台消费者kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic flink_kafka2来看最后的效果:此代码主要功能是对输入的字符串做分区和求和操作,例如,传入hello,world,hello三条数据,按照字符串进行分区,分为hello,world两个分区,求和是按照分区内所有汇总的字段进行求和,最后结果是(hello,2) (world,1)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TjbpOjHL-1681811696794)(image-20230414195452057.png)]](https://img-blog.csdnimg.cn/52480310f07e429790778b0deaeed1b0.png) 我们假设,来了三条数据,hello,world,hello,处理了两条数据,此时算子状态为(hello,1) (world,1) 第三条数据来的时候“恰好”故障,检查点保存的偏移量是第一条数据hello,算子里保存的是(hello,1) 那么继续从第二条数据world开始消费,第二条数据处理成功,此时算子里保存的(hello,1) (world,1),第三条数据处理成功,最终效果为(hello,2) (world,1)
我们假设,来了三条数据,hello,world,hello,处理了两条数据,此时算子状态为(hello,1) (world,1) 第三条数据来的时候“恰好”故障,检查点保存的偏移量是第一条数据hello,算子里保存的是(hello,1) 那么继续从第二条数据world开始消费,第二条数据处理成功,此时算子里保存的(hello,1) (world,1),第三条数据处理成功,最终效果为(hello,2) (world,1)
3)最后补充下完整的流程:
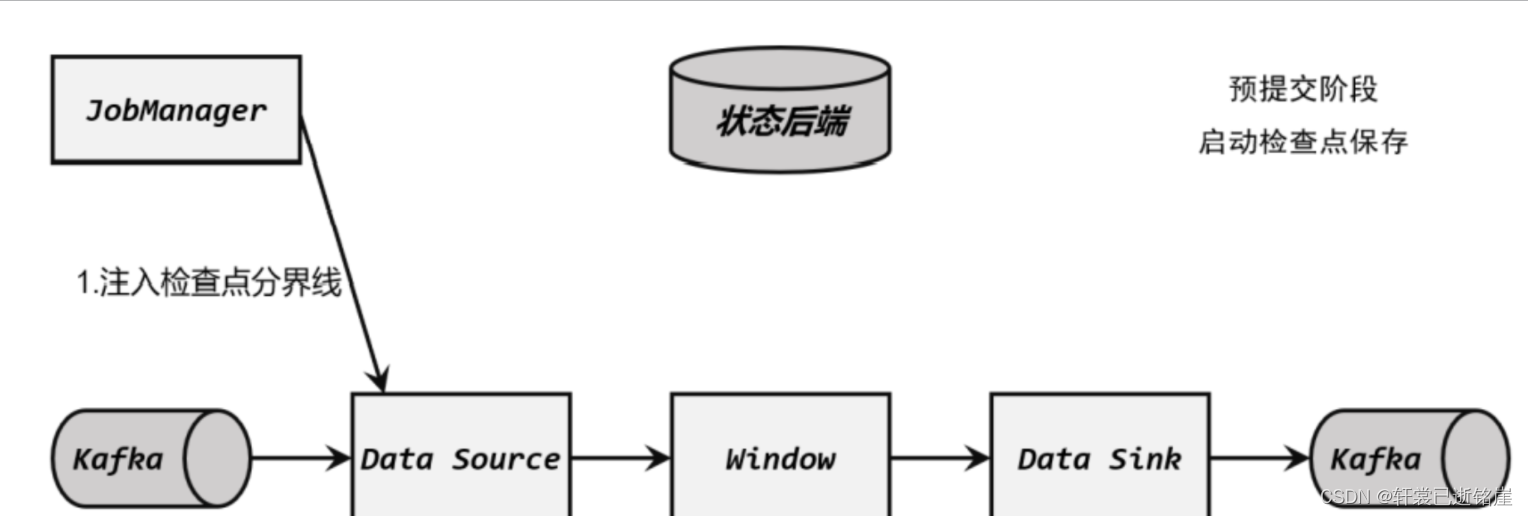
(1)启动检查点保存
检查点保存的启动,标志着我们进入了两阶段提交协议的“预提交”阶段。但此时现在还没有具体提交的数据。
jobManager 通知各个 TaskManager 启动检查点保存,Source 任务会将检查点分界线(barrier)注入数据流。这个 barrier 可以将数据流中的数据,分为进入当前检查点的集合和进入下一个检查点的集合。
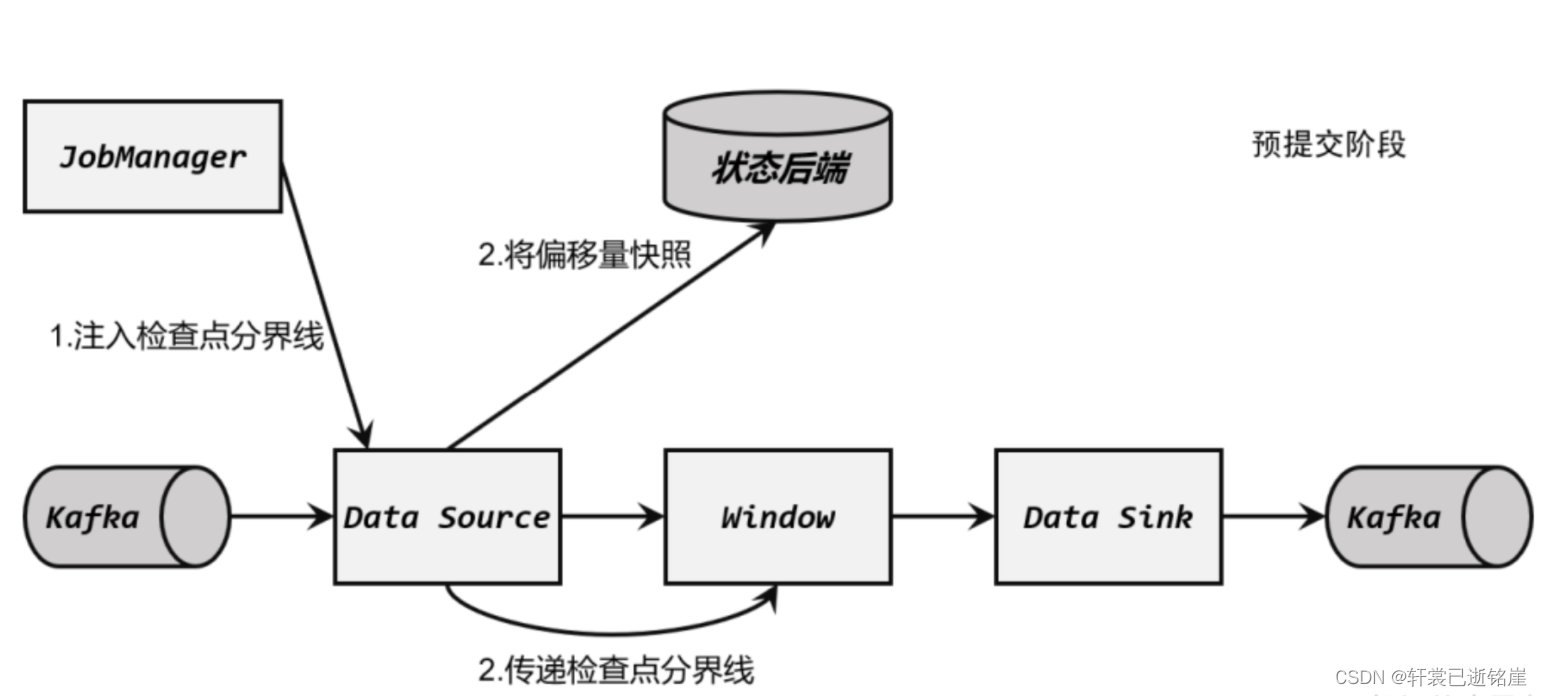
(2)算子任务对状态做快照
分界线(barrier)会在算子间传递下去。每个算子收到 barrier 时,会将当前的状态做个快 照,保存到状态后端。
Source 任务将 barrier 插入数据流后,也会将当前读取数据的偏移量作为状态写入检查点,存入状态后端;然后把 barrier 向下游传递,自己就可以继续读取数据了。 接下来 barrier 传递到了内部的 Window 算子,它同样会对自己的状态进行快照保存,写入远程的持久化存储。
(3)Sink 任务开启事务,完成最后的预提交
分界线(barrier)终于传到了 Sink 任务,这时 Sink 任务会开启一个事务。接下来到来的所有数据,Sink 任务都会通过这个事务来写入 Kafka。这里 barrier 是检查点的分界线,也是事务的分界线。当处理barrier的时候,实际上之前的数据都已经全部处理完了,不用管之前的,直接开启了新的事务。 对于 Kafka 而言,提交的数据会被标记为“未确认”(uncommitted)。整个过程就是所谓 的“预提交”(pre-commit)
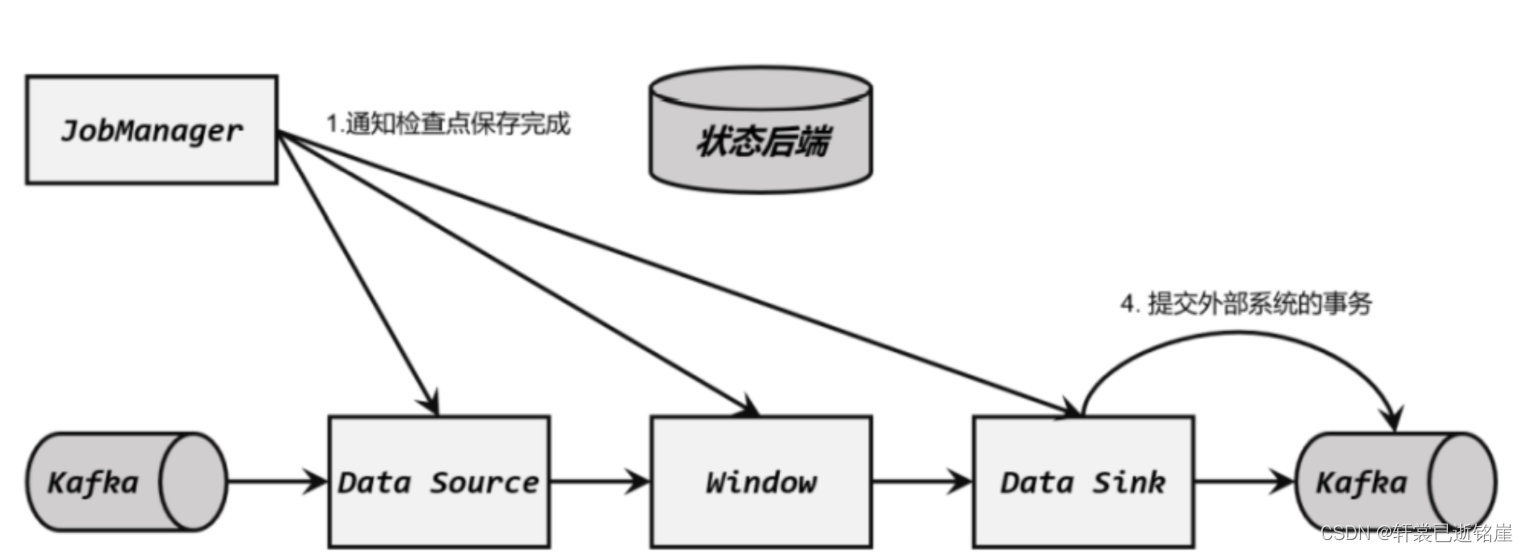
(4)检查点保存完成,提交事务
当所有算子的快照都完成,也就是这次的检查点保存最终完成时,JobManager 会向所有任务发确认通知,告诉大家当前检查点已成功保存。
当 Sink 任务收到确认通知后,就会正式提交之前的事务,把之前“未确认”的数据标为 “已确认”,接下来就可以正常消费了。 在任务运行中的任何阶段失败,都会从上一次的状态恢复,所有没有正式提交的数据也会回滚。这样,Flink 和 Kafka 连接构成的流处理系统,就实现了端到端的 exactly-once 状态一致性。

二、前置知识
⭐️1.检查点(快照)
(1)概念:
其实就是所有任务的状态在某个时间点的一个快照(一份拷贝)。Flink 会定期保存检查点,在检查点中会记录每个算子的 id 和状态;如果发生故障,Flink 就会用最近一次成功保存的检查点来恢复应用的状态,重新启动处理流程,就如同“读档”一样。
⭐️默认情况下,检查点是被禁用的,需要在代码中手动开启。
(2)拓展问题:
1.什么时候进行保存?
当每隔一段时间检查点保存操作被触发时,就把每个任务当前的状态复制一份,按照一定的逻辑结构放在一起持久化保存起来,就构成了检查点。 在 Flink 中,检查点的保存是周期性触发的,间隔时间可以进行设置。
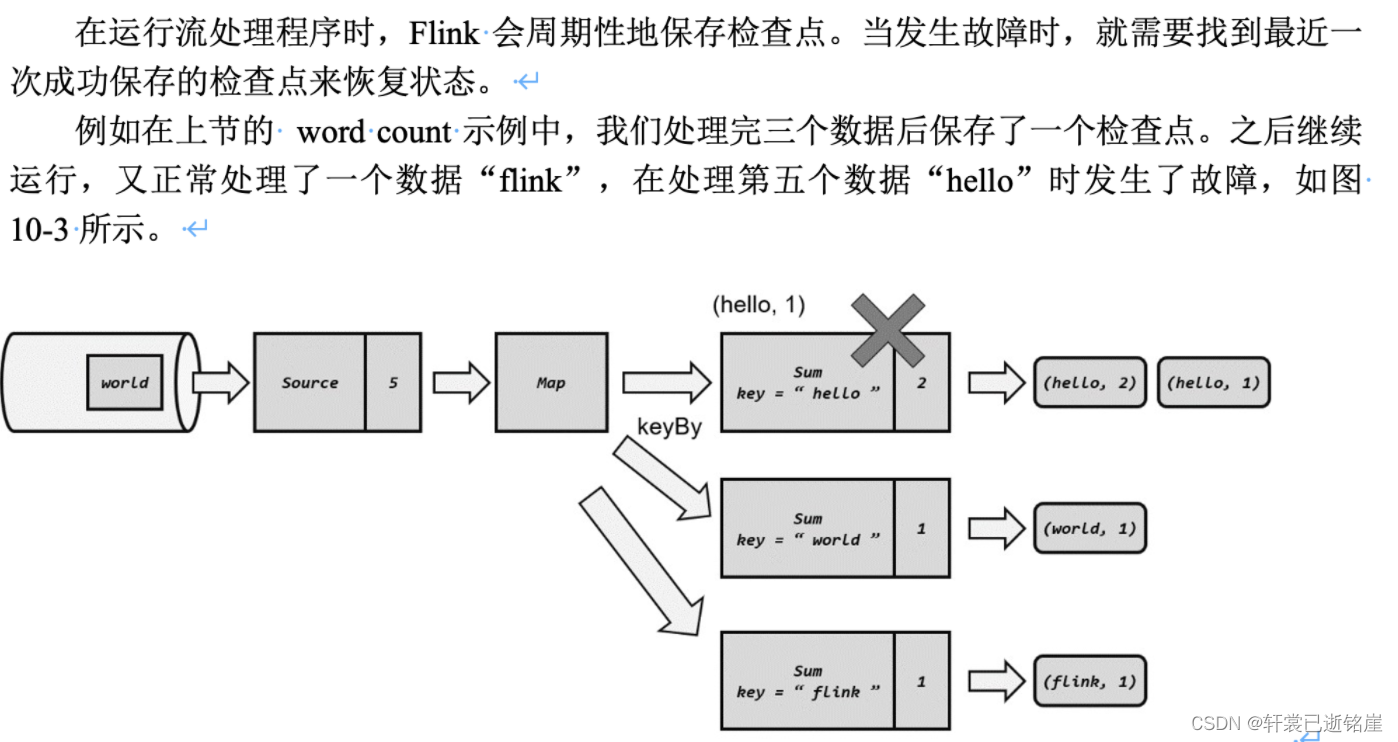
2.如何保存以及恢复的?
举个例子,看看完整的流程图:
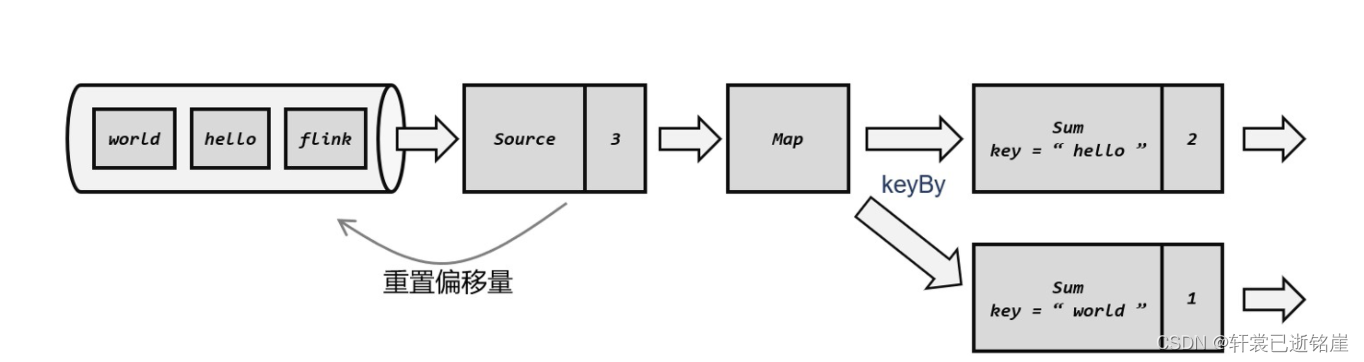
首先,我们已经确认(hello,hello,world)三条数据在所有算子任务都处理完了,那么每个算子任务会把当前处理过程中的值保存到外部存储中,注意是每个算子任务。
由于全部处理完了3条数据,所以source保存的偏移量事3
第一个分区,处理了两条hello数据,所以保存的数据就是hello,2
第二个分区处理了一条world数据,所以保存的数据就是world,1
此时发生故障,系统宕机
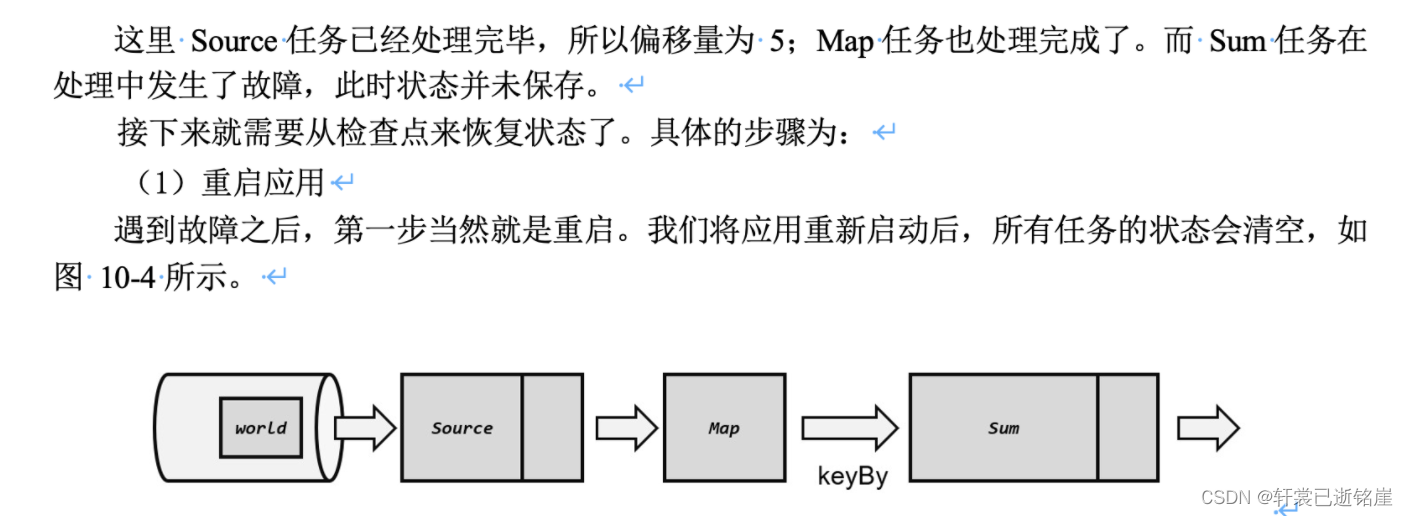
重启应用后,所有算子的状态都是空的,第一件事就是读取检查点,也就是刚才检查点保存的值再读取到内存中
第二件事,通过数据源的偏移量,进行重放数据,因为处理完3条数据了,所以从第三条数据后面开始继续处理。
3.为什么检查点保存时机选择所有算子任务处理完同一批数据?
首先需要思考的一个问题:在算子A保存检查点的过程中,算子B正在处理新的数据,出现宕机,那我恢复的时候虽然明确知道哪条数据没有处理完,但是不确定执行到哪一个算子了,所以只能从头source放入数据,然后到算子A执行,但是算子A可能算出来这条数据的中间状态进行保存了, 相当于算子A要对这条数据处理两次。
举例:比如数据a,要进行处理1(求和),处理2(输出到存储文件)阶段,发生故障的时候在处理2阶段,处理1阶段已经保存了处理1阶段的值,难道恢复的时候,处理1阶段还要对数据的a再操作一次吗?
那我不选择处理完同一批数据,有没有什么其他解决方案?有,比较粗暴的方案。
粗暴的解决方案:
最简单的想法是,可以在某个时刻“按下暂停键”,让所有任务停止处理数据。无论是检查点前的还是检查点后面的,都不许处理保存检查点时来的新的数据,就算宕机故障,恢复后开始处理,大家的状态都还是准确的。
然而仔细思考就会发现这有很多问题。这种想法其实是粗暴地“停止一切来拍照”,在保存检查点的过程中,任务完全中断了,这会造成很大的延迟;我们之前为了实时性做出的所有设计就毁在了做快照上。
4.那怎么确认所有算子都处理完同一批数据?直接按照最后一个sink算子任务输出成功的数据作为偏移量不可以吗?
完全不可以,最后一个sink算子任务输出的时候,虽然保证之前的数据已经全部处理完了。但是有个问题是,你在输出的时候,上一个算子任务开始处理新的数据了,整个过程大家都是异步的,你sink的时候还能不让其他算子继续处理新数据了吗,所以真正要用到的偏移量。一定是“特殊标记”的上一条数据。
那特殊标记在Flink中有概念吗?
有,看下面的检查点算法实现。
5.保存检查点的时候,新来的数据到底该怎么办?
先缓存起来,不着急处理,等到检查点保存后再继续处理。
我们可以在source数据中插入一条分界线,一旦所有算子遇到这个分界线就先把分界线之前的数据都处理完,马上开始各自保存当前的快照,保存完往下个算子传递,相当于增加一个约束,“特殊标记前面的一定是都处理完的数据”)。
6.那么你既然要缓存不处理,不还是粗暴的方案?不让新数据处理执行,有什么意义吗?
有,记住,是每个算子任务都保留“自己”的快照,算子A保留快照的时候,不影响算子B处理数据,同样的,算子A已经保留完快照,算子B保留快照的时候,算子A可以允许处理新的数据。
相当于避免了粗暴方案中的“stop the world”7.那如果任务某个算子任务是并发情况呢?你怎么传递这个特殊标记?
还是要看检查点算法,下游任务必须接收所有上游并发任务的标记过来,才能开始保存快照。
8.既然选择所有任务都处理完一个相同数据,如果有其中一个任务没保存下状态,其他任务都保存了怎么办?
构建一个“事务”,只要有一个任务没保存状态,所有任务保存的状态直接删除,重新发送分界线,重新开始保存
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8uLxBQd7-1681811696788)(image-20230413152858608.png)]](https://img-blog.csdnimg.cn/3586f60c40674985abc43b43e87f5df6.png)


(3)检查点算法:
为什么需要检查点算法?
刚才看到了检查点的保存,是所有算子任务都接受到了“保存快照”的标记,那么,谁来发起保存检查点,谁来通知所有算子任务进行保存呢?
带着这个疑问,先来说说,这个“保存快照的标记”是什么?1)检查点分界线(Barrier)
与水位线很类似,检查点分界线也是一条特殊的数据,由 Source 算子注入到常规的数据流中,它的位置是限定好的,不能超过其他数据,也不能被后面的数据超过。检查点分界线中带有一个检查点 ID,这是当前要保存的检查点的唯一标识。
这样,分界线就将一条流逻辑上分成了两部分:分界线之前到来的旧数据,都数据当前检查点应该保存的,而基于分界线之后的新数据,因为不确定有没有处理,则会被包含在之后的检查点中。
⭐️这个分界线如何进行传递?
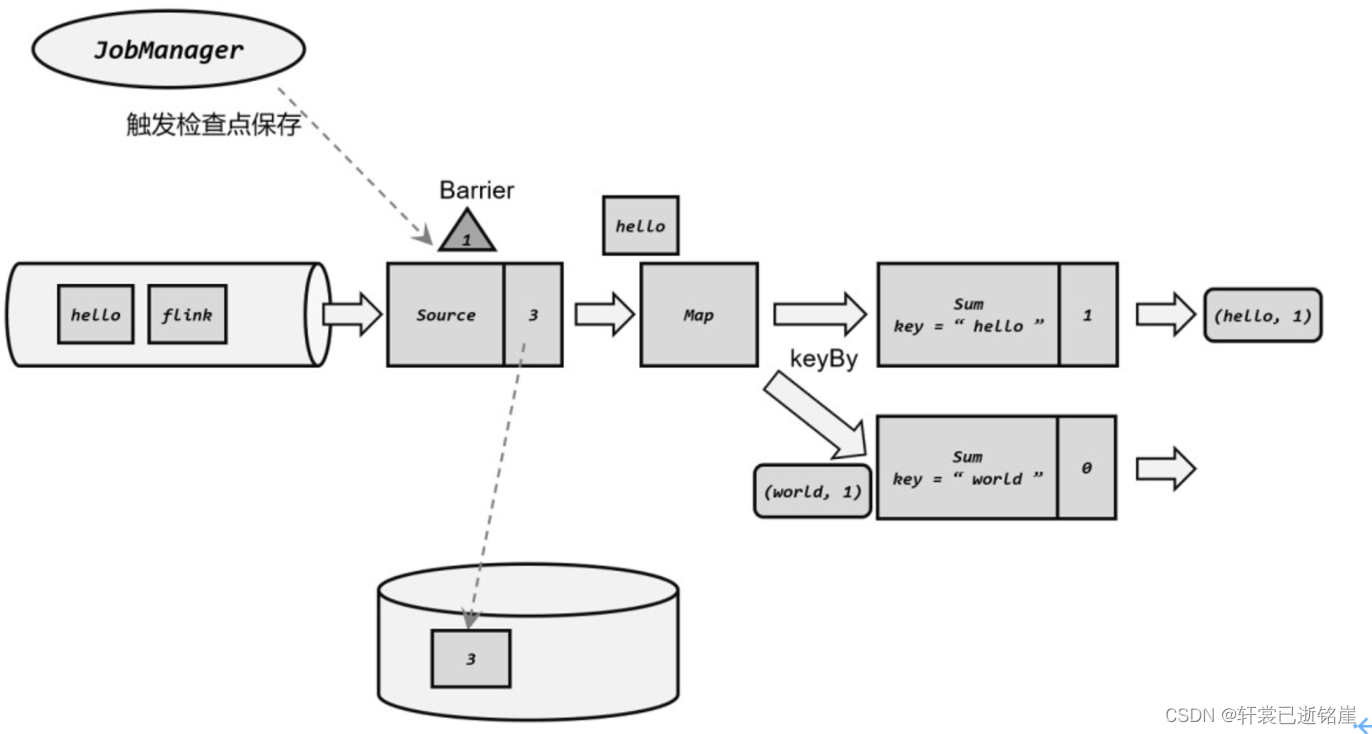
- JobManager中的检查点协调器 定期向 TaskManager 发出指令,要求保存检查点
- TaskManager 会让所有的 Source 任务把自己的偏移量(算子状态)保存起来,并将带有检查点 ID 的分界线(barrier)插入到当前的数据流中,先等待Source任务把快照保存后,并向下游子任务传递barrier。之后 Source 任务就可以继续读入新的数据了。
- 每个算子任务只要处理到这个 barrier,就把当前的状态进行快照。
2)分布式快照算法
我们已经知道了这个特殊字段叫做分界线,那么通知下游的算子任务?此时需要分布式快照算法
⭐️⭐️算法的核心三个原则:
- 当上游任务向多个并行下游任务发送 barrier 时,需要广播出去
- 而当多个上游任务向同一个下游任务传递 barrier 时,需要在下游任务执行“分界线对齐”(barrier alignment)操作,说白了需要等到所有上游任务发送给自己的 barrier 都到齐,才开始“快照”的保存。
- ⭐️在barrier到来后,保存快照期间 新来的数据会进行缓存,不会处理也不会保存到检查点, 直到保存完快照才进行继续进行处理。
- 当多个上游任务向同一个下游任务传递 barrier什么意思?如上图所示,假设 sum1获取到map1,map2的barrier,就开始快照保存,sum2只获取map1的barrier,必须等待map2发送过来barrier才能开始快照保存
- ⭐️那等待所有上游任务发送给自己的 barrier的过程中,有新的数据进来怎么办?也会保存到检查点中,直到收到全部的barrier到来后,才不会放到检查点中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9cKp6B9i-1681811696793)(image-20230412204913560.png)]](https://img-blog.csdnimg.cn/8b52940d64ca4e449c29b78a88f0c7eb.png)
(4)使用:
1)启用检查点:
- enableCheckpointing 传入一个保存检查点的间隔
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 每隔1秒启动一次检查点保存 env.enableCheckpointing(1000);2)配置检查点存储位置:
- setCheckpointStorage
对于实际生产应用,我们一般会将 CheckpointStorage 配置为高可用的分布式文件系统(HDFS,S3 等)。
env.getCheckpointConfig().setCheckpointStorage("hdfs://namenode:40010/flink/checkpoints");⭐️3)其他参数:
- 检查点模式 setCheckpointingModeEXACTLY_ONCE 精准一次(默认) AT_LEAST_ONCE 最少一次对于大多数低延迟的流处理程序,at-least-once 就够用了,而且处理效率会更高。
- 检查点保存的超时时间 setCheckpointTimeout注意enableCheckpointing是多久触发一次检查点保存,setCheckpointTimeout是允许多长时间内保存完毕。
- 新一轮检查点保存开始,等待上一个检查点的时间 setMinPauseBetweenCheckpoint⭐️如果设置的检查点保存超时时间小于保存检查点的时间间隔,这个设置就是生效的。这个跟enableCheckpointing的区别在于enableCheckpointing是多久触发一次检查点保存,setMinPauseBetweenCheckpoint是上一个检查点已经开始了,但是迟迟不久保存下来,第二个检查点必须等多长时间才能开始保存检查点。
- 作业失败时是否删除检查点 enableExternalizedCheckpointsRETAIN_ON_CANCELLATION 保留(默认)DELETE_ON_CANCELLATION 直接删除
- 检查点保存失败时停掉作业 setFailOnCheckpointingErrorstrue 停掉作业(默认)false 不停掉作业
- enableUnalignedCheckpoints不再执行检查点的分界线对齐操作,启用之后可以大大减少产生背压时的检查点保存时间。这个设置要求检查点模式(CheckpointingMode)必须为 exctly-once,并且并发的检查点个数为 1
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();//获取检查点CheckpointConfig checkpointConfig = env.getCheckpointConfig();//设置检查点的保存,用hdfs checkpointConfig.setCheckpointStorage("hdfs://my/checkpoint/dir");//EXACTLY_ONCE表示精准一次 AT_LEAST_ONCE表示最少一次 checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//检查点保存的超时时间,超过10秒直接报失败 checkpointConfig.setCheckpointTimeout(10000L);//检查点的保存时间间隔,20秒后开始下一轮的检查点保存 checkpointConfig.setMinPauseBetweenCheckpoints(20000L);//最多并发几个运行的检查点 checkpointConfig.setMaxConcurrentCheckpoints(2);//启用不对齐的检查方式 checkpointConfig.enableUnalignedCheckpoints();//开启检查点的外部持久化,而且[默认]在作业失败的时候不会自动清理 checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
⭐️(5)保存点
概念:
- 什么是保存点?也是一个存盘的备份,它的原理和算法与检查点完全相同,只是多了一些额外的元数据。
- 跟检查点的区别在哪里?检查点是由 Flink 自动管理的,定期创建,发生故障之后自动读取进行恢复,这是一个“自动存盘”的功能而保存点不会自动创建,必须由用户明确地手动触发保存操作,所以就是“手动存盘”。
适用场景:
- 版本管理和归档存储对重要的节点进行手动备份,设置为某一版本,归档(archive)存储应用程序的状态。
- 更新应用程序我们不仅可以在应用程序不变的时候,更新 Flink 版本;还可以直接更新应用程序。前提是程序必须是兼容的,也就是说更改之后的程序,状态的拓扑结构、数据类型是不变的,这才能正常从之前的保存点去加载。
- 调整并行度如果应用运行的过程中,发现需要的资源不足或已经有了大量剩余,也可以通过从保存点重启的方式,将应用程序的并行度增大或减小。
使用:
- 代码中设置uid对于没有设置 ID 的算子,Flink 默认会自动进行设置,所以在重新启动应用后可能会导致 ID 不同而无法兼容以前的状态。所以为了方便后续的维护,一定要在程序中为每一个算子手动指定 ID。
DataStream<String> stream = env .addSource(newStatefulSource()).uid("source-id").map(newStatefulMapper()).uid("mapper-id").print();- 保存- savepoint 表示要开始执行保存点- jobId (必填) 就是当前作业id名称- targetDirectory(选填)表示持久化的目录不填则使用conf下的state.savepoints.dir 目录
bin/flink savepoint :jobId [:targetDirectory]- 恢复- 这里只要增加一个-s 参数,指定保存点的路径就可以了
bin/flink run -s :savepointPath [:runArgs]
2.持久化保存状态
(1)概念
状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就叫作状态后端(state backend)。状态后端主要负责两件事:一是本地的状态管理,二是将检查点(checkpoint)写入远程的持久化存储。
(2)流程
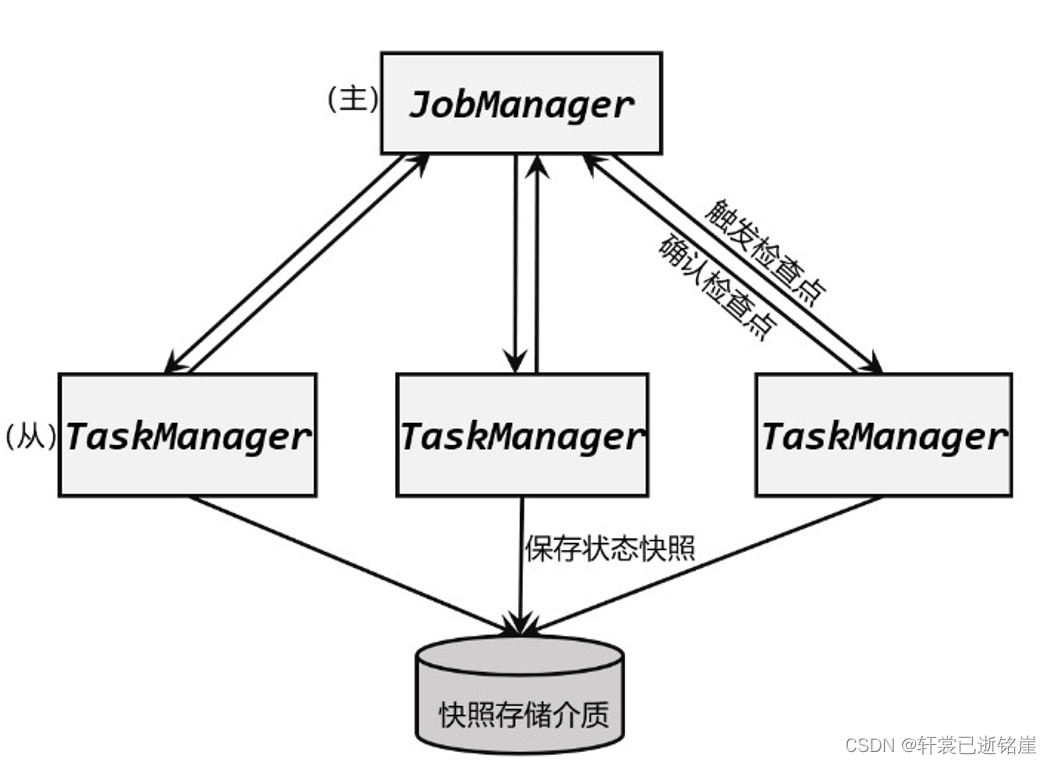
- 在应用进行检查点保存时,状态后端会在 JobManager 向所有 TaskManager 发出触发检查点的命令。
- TaskManger 收到之后,将当前任务的所有状态进行快照保存,持久化到远程的存储介质中。
- 完成之后向 JobManager 返回确认信息。
- 当 JobManger 收到所有 TaskManager 的返回信息后,就会确认当前检查点成功保存。
而这一切工作的协调,就是“状态后端” 来完成的
(3)分类
- ⭐️默认⭐️ 哈希表状态后端(HashMapStateBackend)> 将本地状态全部放入内存,保存在 Taskmanager 的 JVM 堆(heap)上,所以底层是一个哈希表(HashMap),这种状态后端也因此得名。> > 优点:> > > - 读写速度非常快> > 缺点:> > > - 占用taskManager运行内存。> > 配置:> > 文件配置:> >
> # 默认状态后端 state.backend: hashmap > # 存放检查点的文件路径 state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints > >> > 代码配置:> > > - 直接设置StateBackend为HashMapStateBackend> >> StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();> env.setStateBackend(newHashMapStateBackend());> - 内嵌 RocksDB 状态后端(EmbeddedRocksDBStateBackend)> 会将处理中的数据全部放入 RocksDB 数据库中,RocksDB 默认存储在 TaskManager 的本地数据目录里。> > 优点:> > > - 不会占用taskManager运行内存> - 可以根据需要对磁盘空间进行扩展,适合海量状态的存储。> > 缺点:> > > - 状态的访问性能要差一些(数据被存储为序列化的字节数组(Byte Arrays),读写操作需要序列化/反序列化)> > 配置:> > 文件配置:> >
> # 默认状态后端 state.backend: rocksdb > # 存放检查点的文件路径 state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints > >> > 代码配置:> > > - 直接设置StateBackend为EmbeddedRocksDBStateBackend> >> StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment(); > env.setStateBackend(newEmbeddedRocksDBStateBackend());>
版权归原作者 轩裳已逝铭崖 所有, 如有侵权,请联系我们删除。