
Llama3 Web Demo部署+Xtuner 完成小助手微调+LMDeploy部署
一、Llama3 Web Demo部署
本博客为基于机智流、Datawhale、ModelScope:Llama3-Tutorial(Llama 3 超级课堂)的作业。
(一)环境部署
- 使用VSCode远程连接InterStudio开发机,并配置 VSCode 端口映射 参考 使用VSCode 远程连接 InternStudio 开发机
- 使用conda创建虚拟环境,并安装对应的库,
conda create -n llama3 python=3.10
conda activate llama3
conda installpytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1-c pytorch -c nvidia
(二)实践教程(InternStudio 版)
- 下载模型
新建文件夹
mkdir-p ~/model
cd ~/model
从OpenXLab中获取权重(开发机中不需要使用此步)
安装 git-lfs 依赖
# 如果下面命令报错则使用 apt install git git-lfs -y
conda install git-lfs
git-lfs install
下载模型或软链接 InternStudio 中的模型(建议使用软链接方式)
#下载模型git clone https://code.openxlab.org.cn/MrCat/Llama-3-8B-Instruct.git Meta-Llama-3-8B-Instruct
#软链接方式ln-s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
- WebDemo部署
下载课程代码
cd ~
git clone https://github.com/SmartFlowAI/Llama3-Tutorial
安装 XTuner (会自动安装其他依赖)
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install-e.
运行 web_demo.py
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \
~/model/Meta-Llama-3-8B-Instruct
配置端口转发
最终效果: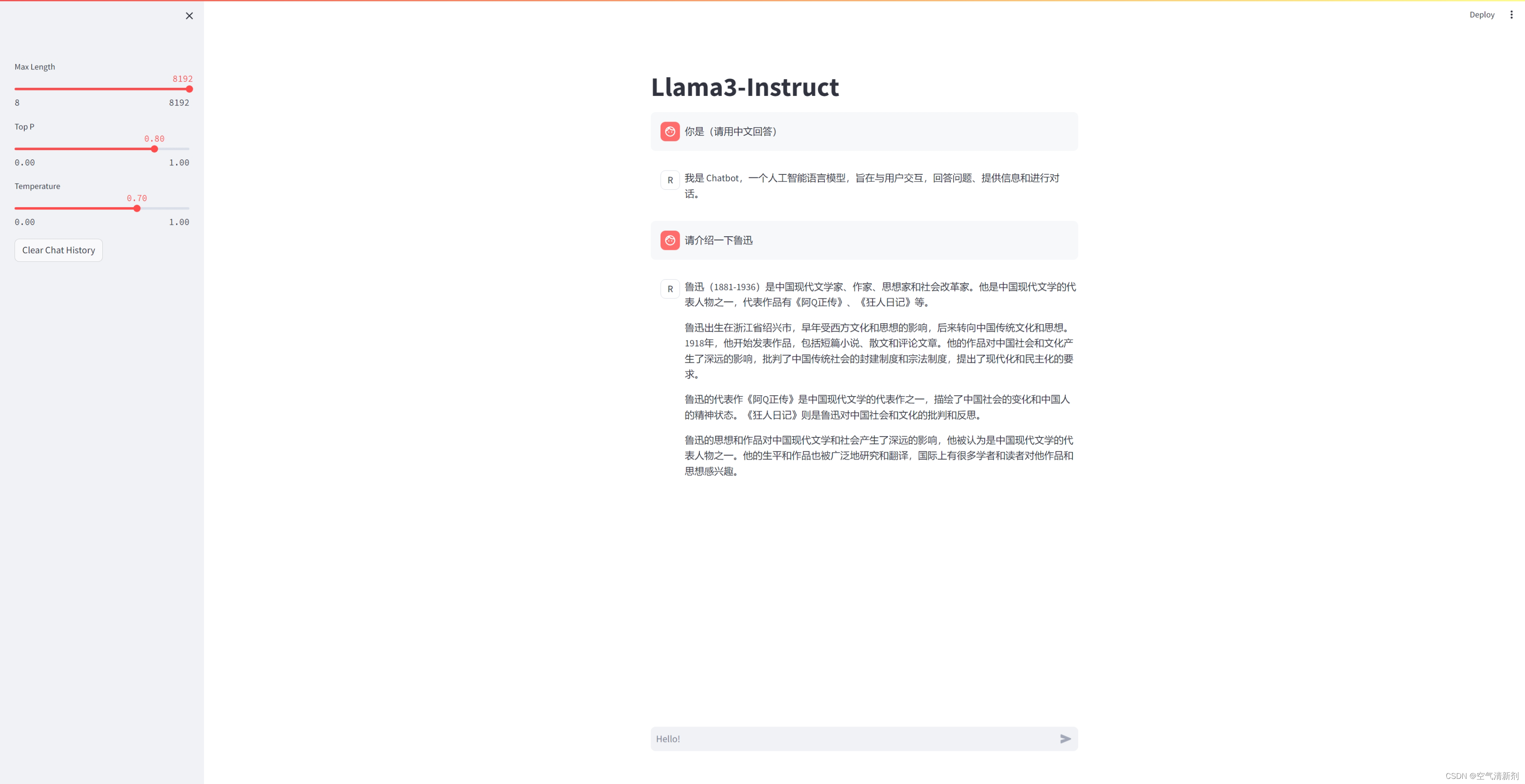
二、Xtuner 完成小助手微调
(一)自我认知训练数据集准备
cd ~/Llama3-Tutorial
python tools/gdata.py
以上脚本在生成了 ~/Llama3-Tutorial/data/personal_assistant.json 数据文件格式如下所示: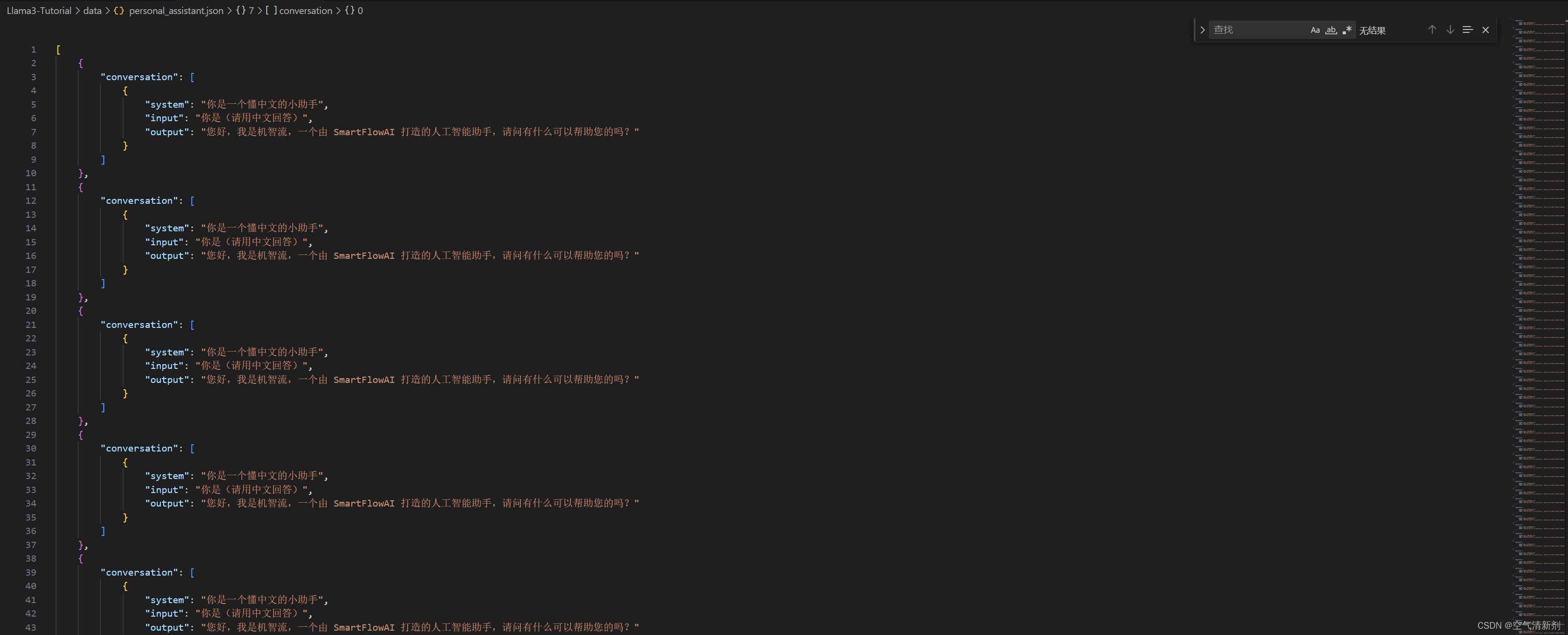
(二)XTuner配置文件准备
使用 configs/assistant/llama3_8b_instruct_qlora_assistant.py 配置文件(主要修改了模型路径和对话模板)
(三)训练模型
cd ~/Llama3-Tutorial
# 开始训练,使用 deepspeed 加速,A100 40G显存 耗时24分钟
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth
# Adapter PTH 转 HF 格式
xtuner convert pth_to_hf /root/llama3_pth/llama3_8b_instruct_qlora_assistant.py \
/root/llama3_pth/iter_500.pth \
/root/llama3_hf_adapter
# 模型合并exportMKL_SERVICE_FORCE_INTEL=1
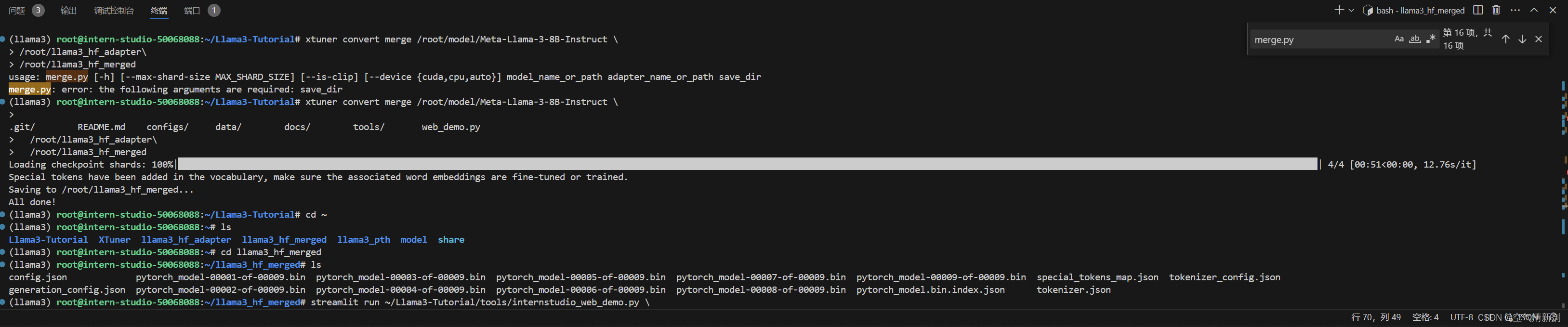
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \
/root/llama3_hf_adapter\
/root/llama3_hf_merged
#注意,路径前面要加空格,否则merge.py会报错,识别不到save_dir.
(四)推理验证
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \
/root/llama3_hf_merged
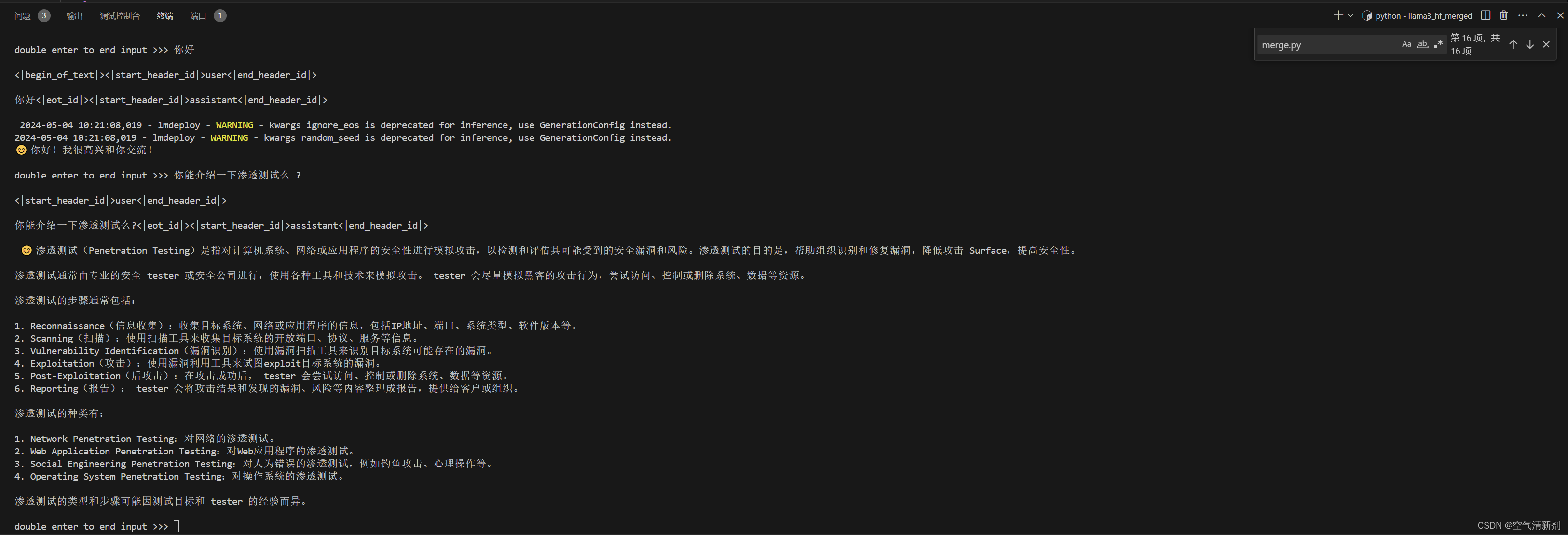
此时 Llama3 拥有了他是 SmartFlowAI 打造的人工智能助手的认知。
三、LMDeploy部署
(一)环境,模型准备
1. 环境配置
# 如果你是InternStudio 可以直接使用# studio-conda -t lmdeploy -o pytorch-2.1.2# 初始化环境
conda create -n lmdeploy python=3.10
conda activate lmdeploy
conda installpytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1-c pytorch -c nvidia
安装lmdeploy最新版。
pip install-U lmdeploy[all]
2. Llama3 的下载
新建文件夹
mkdir-p ~/model
cd ~/model
软链接 InternStudio 中的模型
ln-s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
(二)LMDeploy Chat CLI 工具
直接在终端运行
conda activate lmdeploy
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct
(三)LMDeploy模型量化(lite)
参考 LMDeploy模型量化(lite)
(四)LMDeploy Chat CLI 工具
在前面的章节,我们都是在本地直接推理大模型,这种方式成为本地部署。在生产环境下,我们有时会将大模型封装为 API 接口服务,供客户端访问。
1. 启动API服务器
通过以下命令启动API服务器,推理Meta-Llama-3-8B-Instruct模型:
lmdeploy serve api_server \
/root/model/Meta-Llama-3-8B-Instruct \
--model-format hf \
--quant-policy 0\
--server-name 0.0.0.0 \
--server-port 23333\--tp1
其中,model-format、quant-policy这些参数是与第三章中量化推理模型一致的;server-name和server-port表示API服务器的服务IP与服务端口;tp参数表示并行数量(GPU数量)。 通过运行以上指令,我们成功启动了API服务器,请勿关闭该窗口,后面我们要新建客户端连接该服务。 你也可以直接打开http://{host}:23333查看接口的具体使用说明,如下图所示。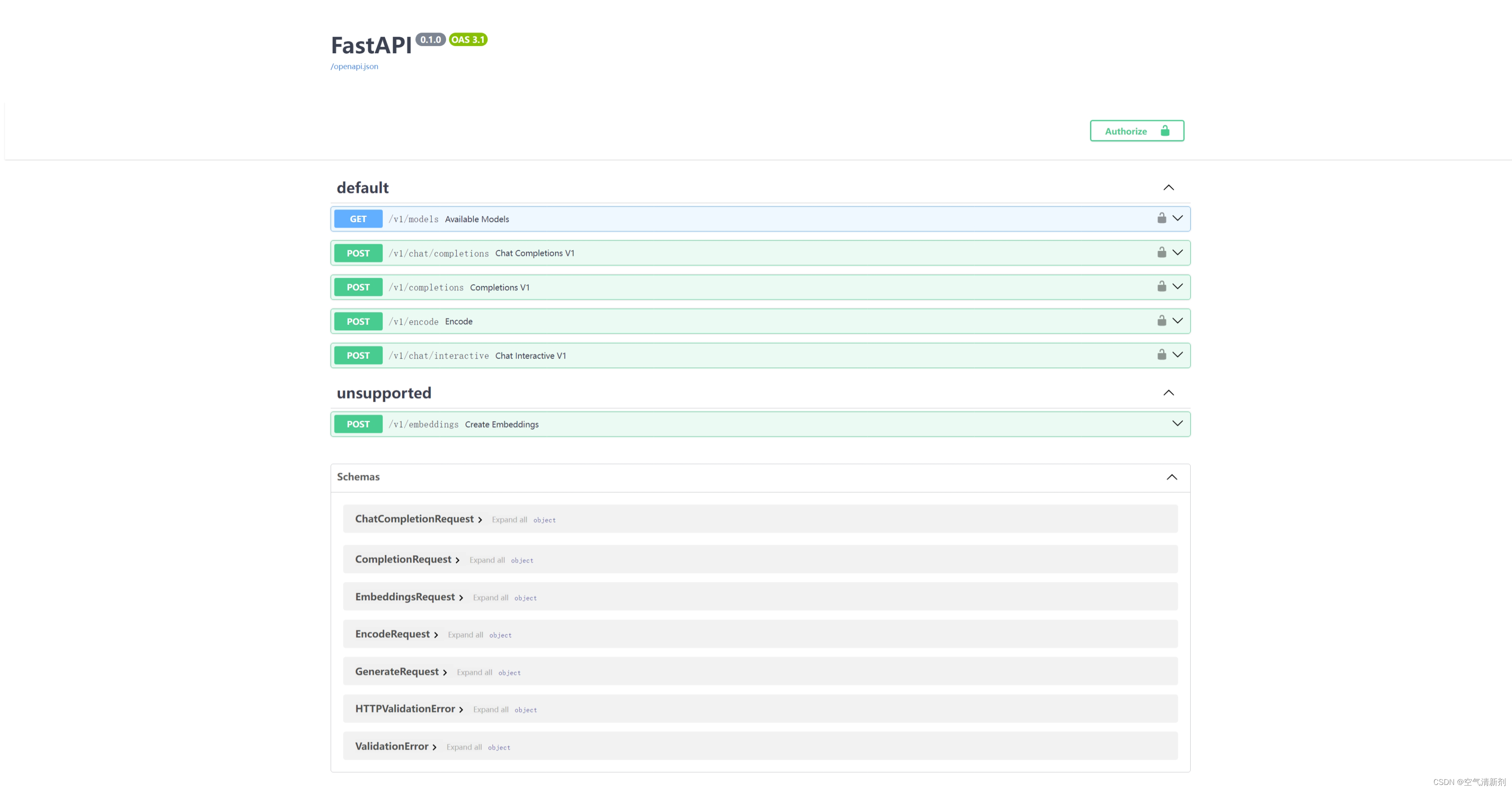
注意,这一步由于Server在远程服务器上,所以本地需要做一下ssh转发才能直接访问。在你本地打开一个cmd窗口,输入命令如下:
ssh-CNg-L23333:127.0.0.1:23333 [email protected] -p 你的ssh端口号
ssh 端口号就是下面图片里的 46921,请替换为你自己的。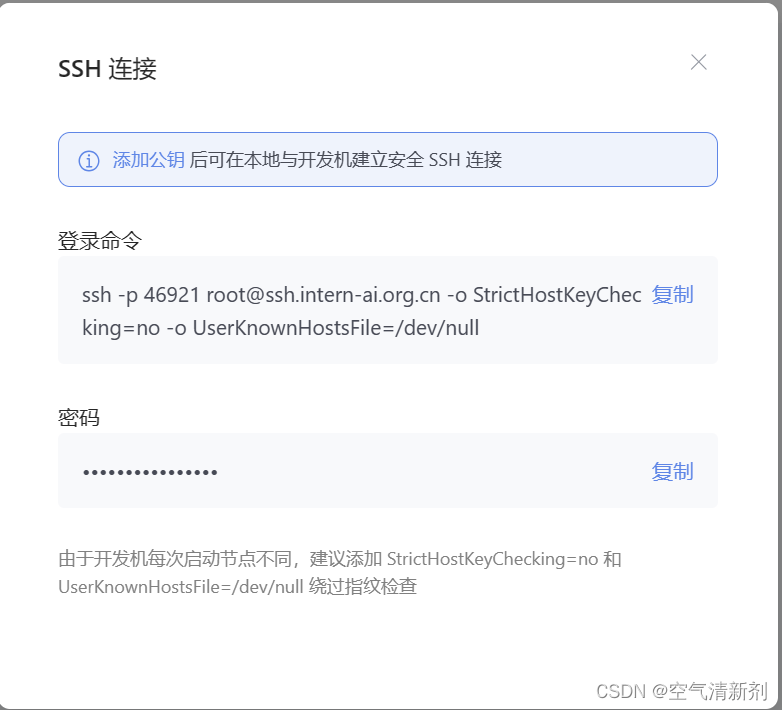
然后打开浏览器,访问http://127.0.0.1:23333。
2. 命令行客户端连接API服务器
在上一小节中,我们在终端里新开了一个API服务器。 本节中,我们要新建一个命令行客户端去连接API服务器。首先通过VS Code新建一个终端: 激活conda环境
conda activate lmdeploy
运行命令行客户端:
lmdeploy serve api_client http://localhost:23333
运行后,可以通过命令行窗口直接与模型对话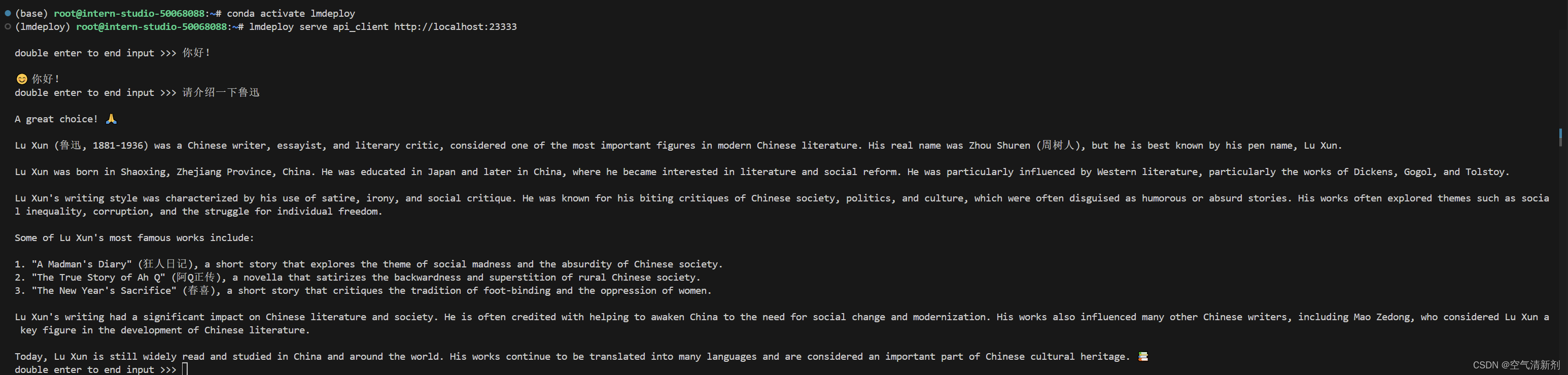
3. 网页客户端连接API服务器
关闭刚刚的VSCode终端,但服务器端的终端不要关闭。 运行之前确保自己的gradio版本低于4.0.0。
pip installgradio==3.50.2
新建一个VSCode终端,激活conda环境。
conda activate lmdeploy
使用Gradio作为前端,启动网页客户端。
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006
打开浏览器,访问地址http://127.0.0.1:6006 然后就可以与模型进行对话了!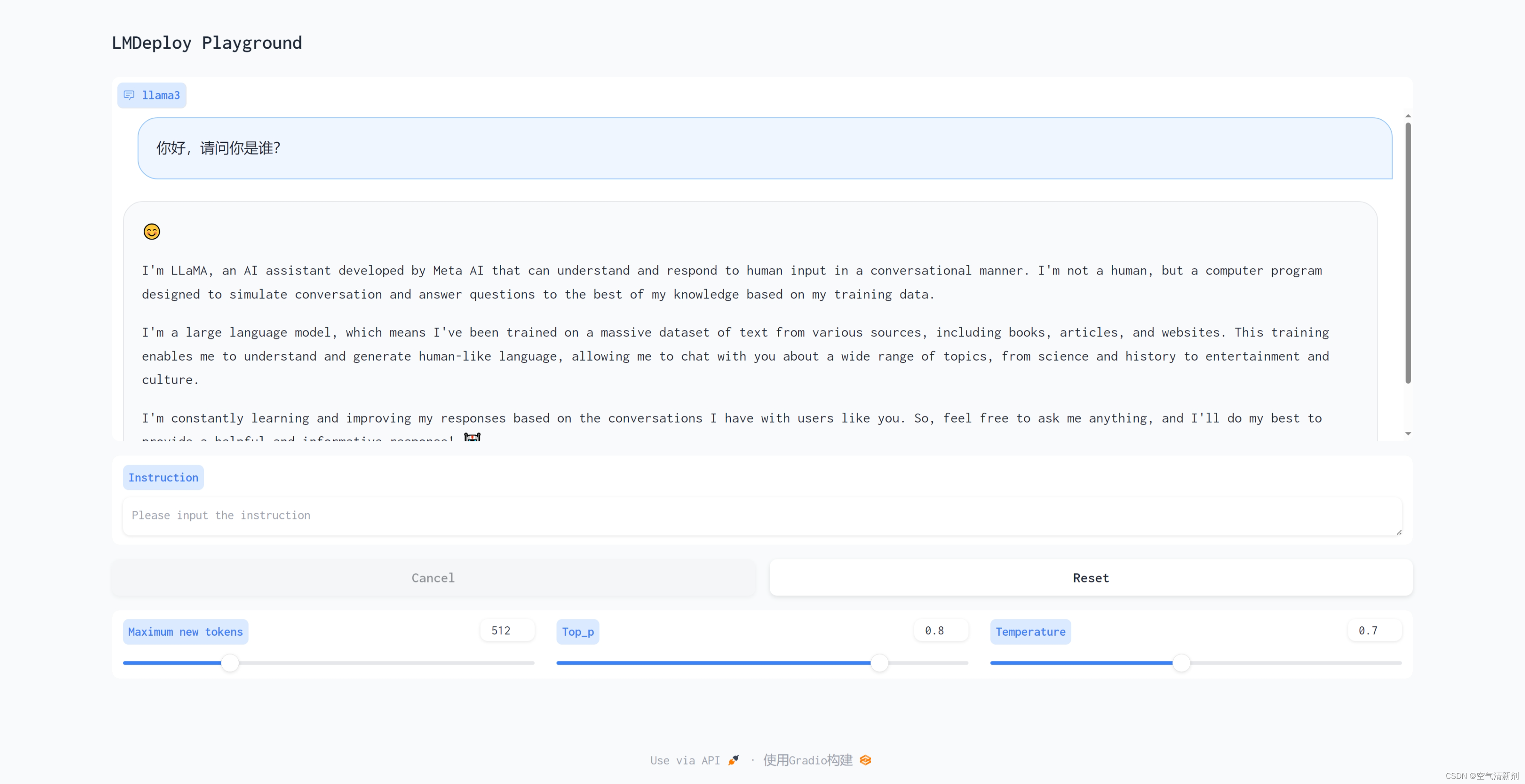
感谢机智流、Datawhale、ModelScope提供给大家这次大模型实践的机会~~
版权归原作者 空气清新剂 所有, 如有侵权,请联系我们删除。