
spark ui 指南
spark ui 是反应一个spark 作业执行情况的页面,通过查看作业的执行情况,分析作业运行的状态.
1.sparkUI 基本介绍
进入运行主页面如下,主要有6各部分 任务实例: http://10.71.190.31:18081/history/application_1638893170232_266874/jobs/
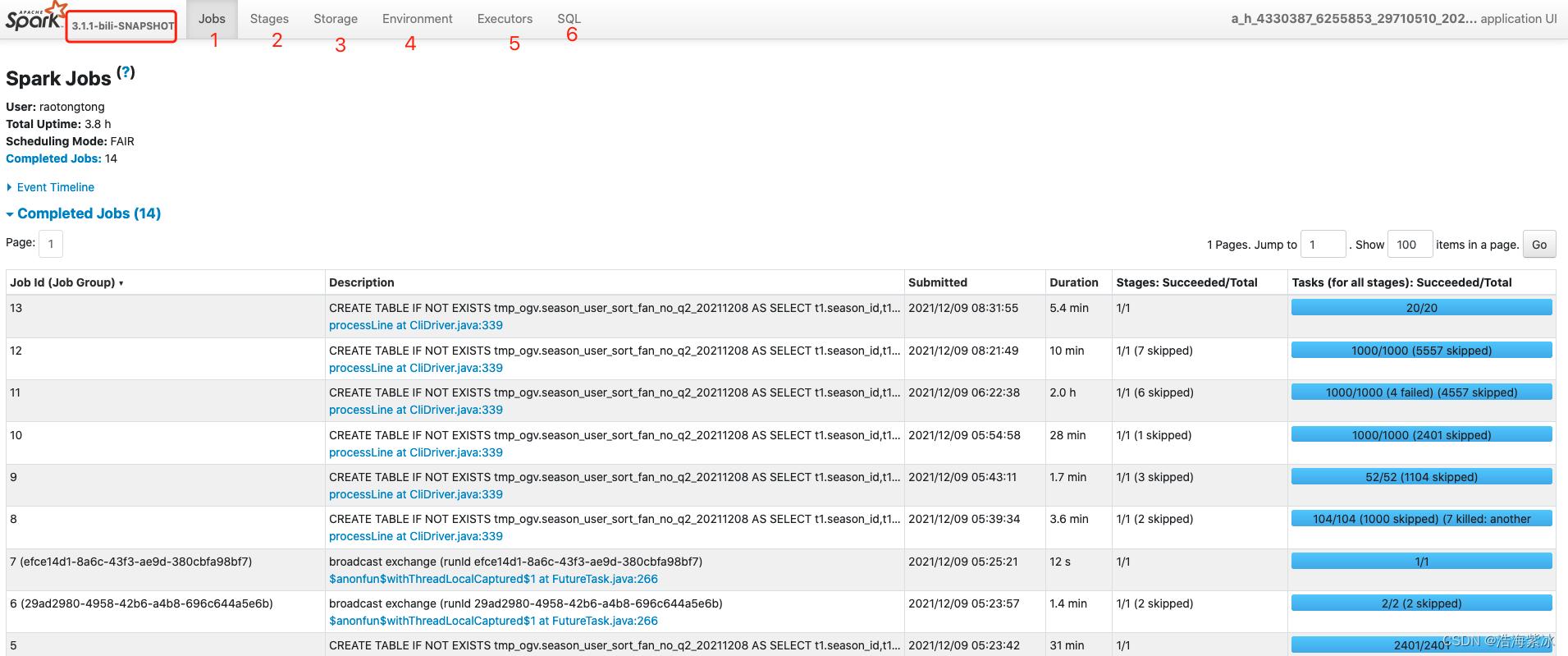
标签页
描述
1
jobs
spark作业执行的job
2
stages
所有stage信息
The Stages tab displays a summary page that shows the current state of all stages of all jobs in the Spark application.
3
storage
rdd存储信息
RDDs and DataFrame持久化
4
environment
作业配置参数
JVM, Spark, and system 属性
5
executors
展示作业executors信息
任务executor创建信息, 包括 内存 ,磁盘使用 ,task ,shuffle信息)
6
sql
解析sql 的信息
2.jobs页面
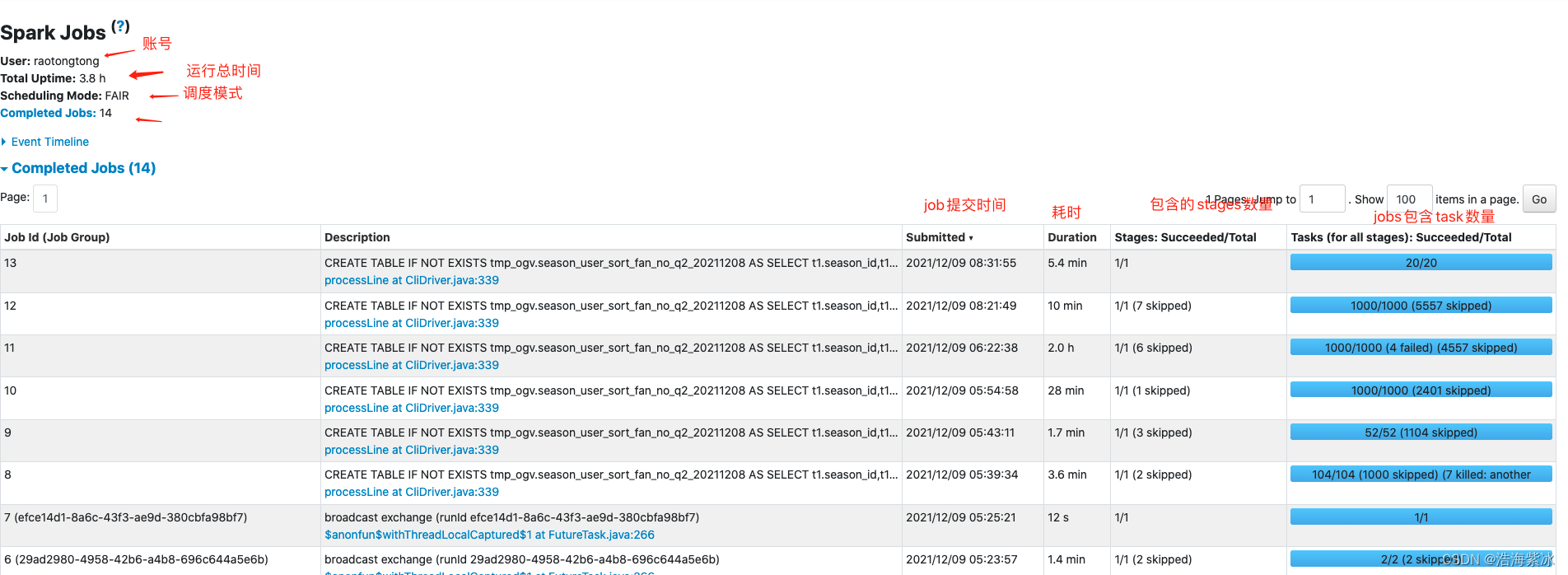
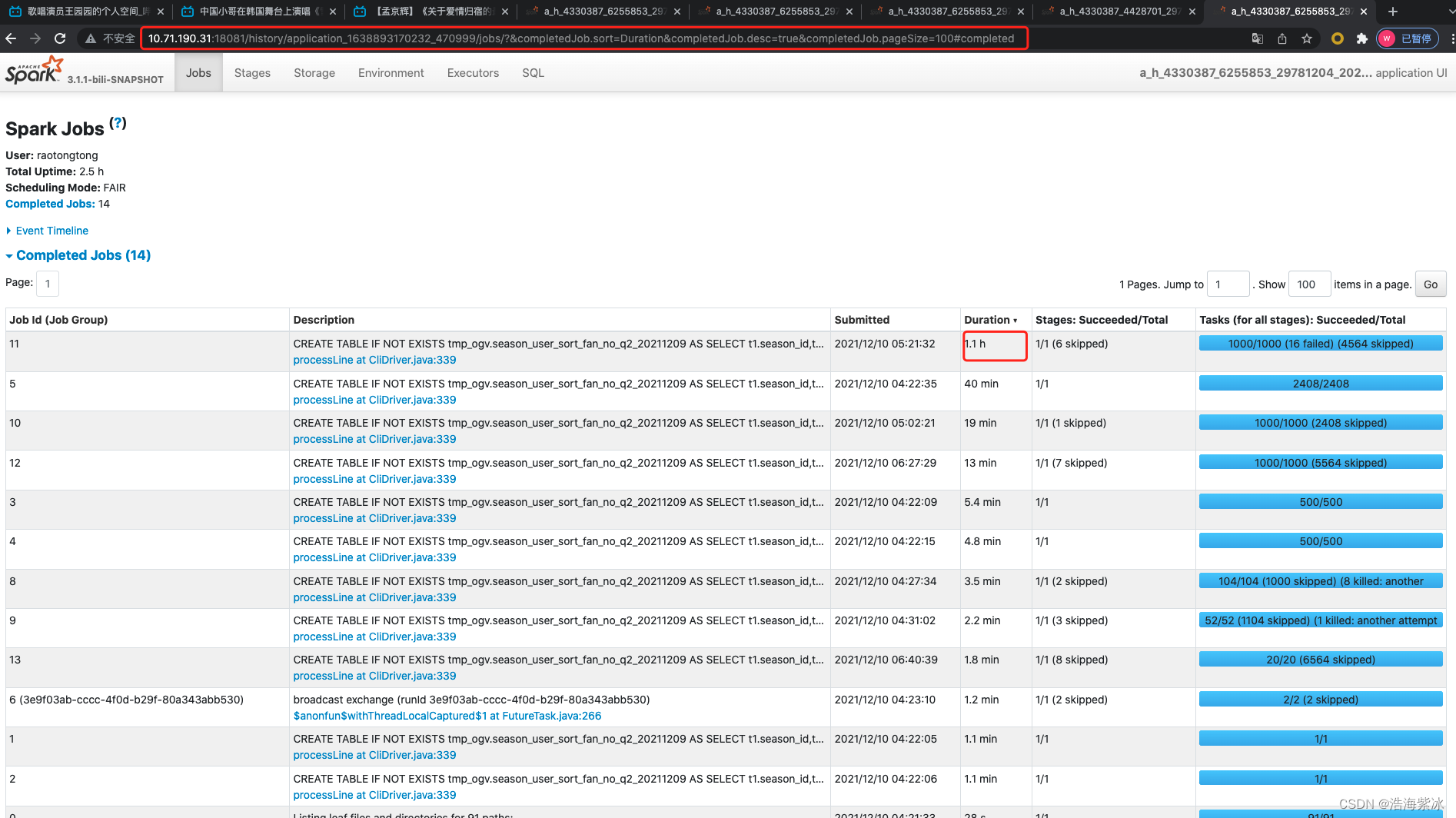
本次任务有14个job
2.1 event_time

按照时间顺序executor 的开始和结束时间点(added, removed)
2.2 job tab页面
每个job的信息包括 job id, description描述 , 提交时间, 耗时, stages数量, task 运行情况
2.3 job详情页面
点击job 描述可以进入对应的job详情页面
- Status: SUCCEEDED (running, succeeded, failed)
- Submitted: 2021/12/14 11:48:06
- Duration: 1.5 min
- **Associated SQL Query: **2 job 的sql tab 连接
Event Timeline
DAG Visualization : job 的有向无环图, 点表示: RDDs or DataFrames 边表示: rdd上的操作
stage根据active, pending, completed, skipped, and failed状态分类的列表
input : 从storage 读取字节数
output: 写入storage 字节数
shuffle read : shuffle 和 记录读取的字节数, 包括 本地数据读取和其他executor 节点读取字节数
shuffle write : 写入磁盘的字节和记录数,在下一个stage的shuffle 阶段读取.
注意看到stage 19-24 是 跳过了, 原因是spark shuffle 的数据会写到磁盘固化,当上游当上游stage(19-24)和之前执行过的stage 相同时,可以直接用之前的结果.
问题 :从图可以看出job之间是否可以并行?
3.stages 页面
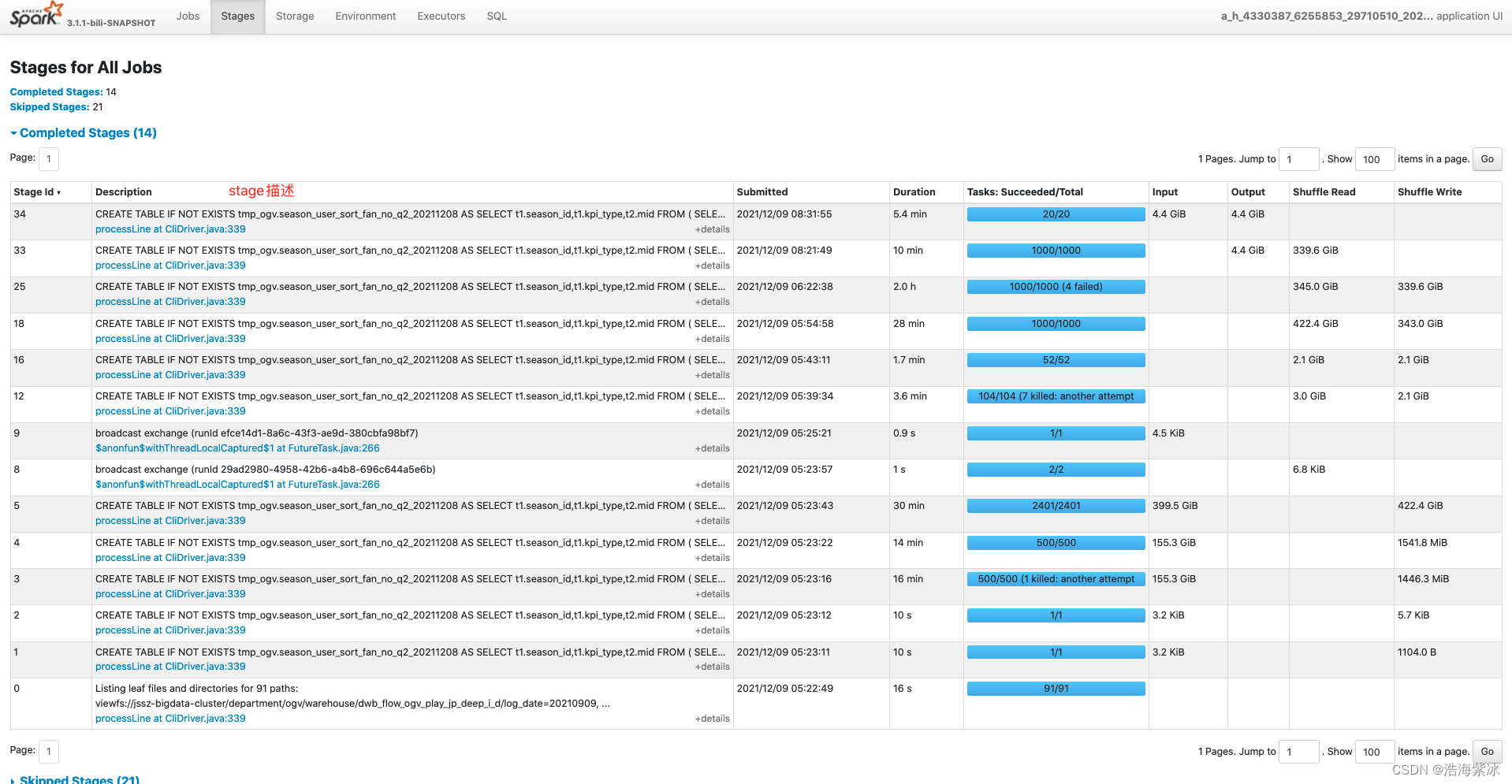
3.1 stages 页面会显示作业所有的stage信息, 同样根据状态分组(active, pending, completed, skipped, and failed)
3.2 Stage detail
所有task 的总时间, 统计矩阵, shuffle 信息, 所属的job id
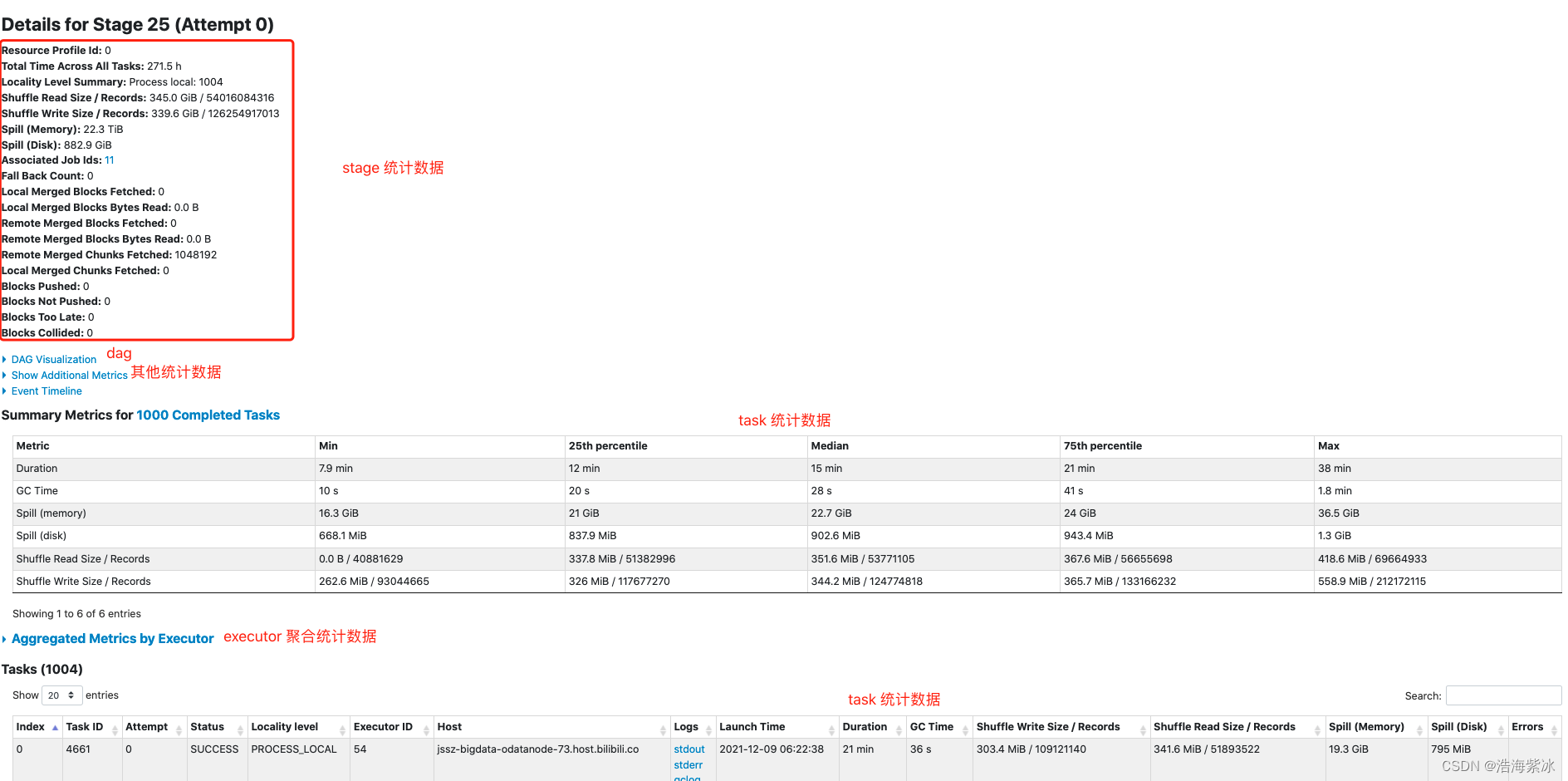
dag图上 展示一些操作名称: BatchScan, WholeStageCodegen, Exchange, etc

task 之间是否可以并行?

4.storage 页面
作业执行过程中缓存信息,包含 rdd 的大小和分部信息
运行时显示,但是B站的spark ui 点了没反应
5.environment 页面
作业运行环境和参数
查看 driver 和 executor 实际配置的大小
driver=6g executor=9g

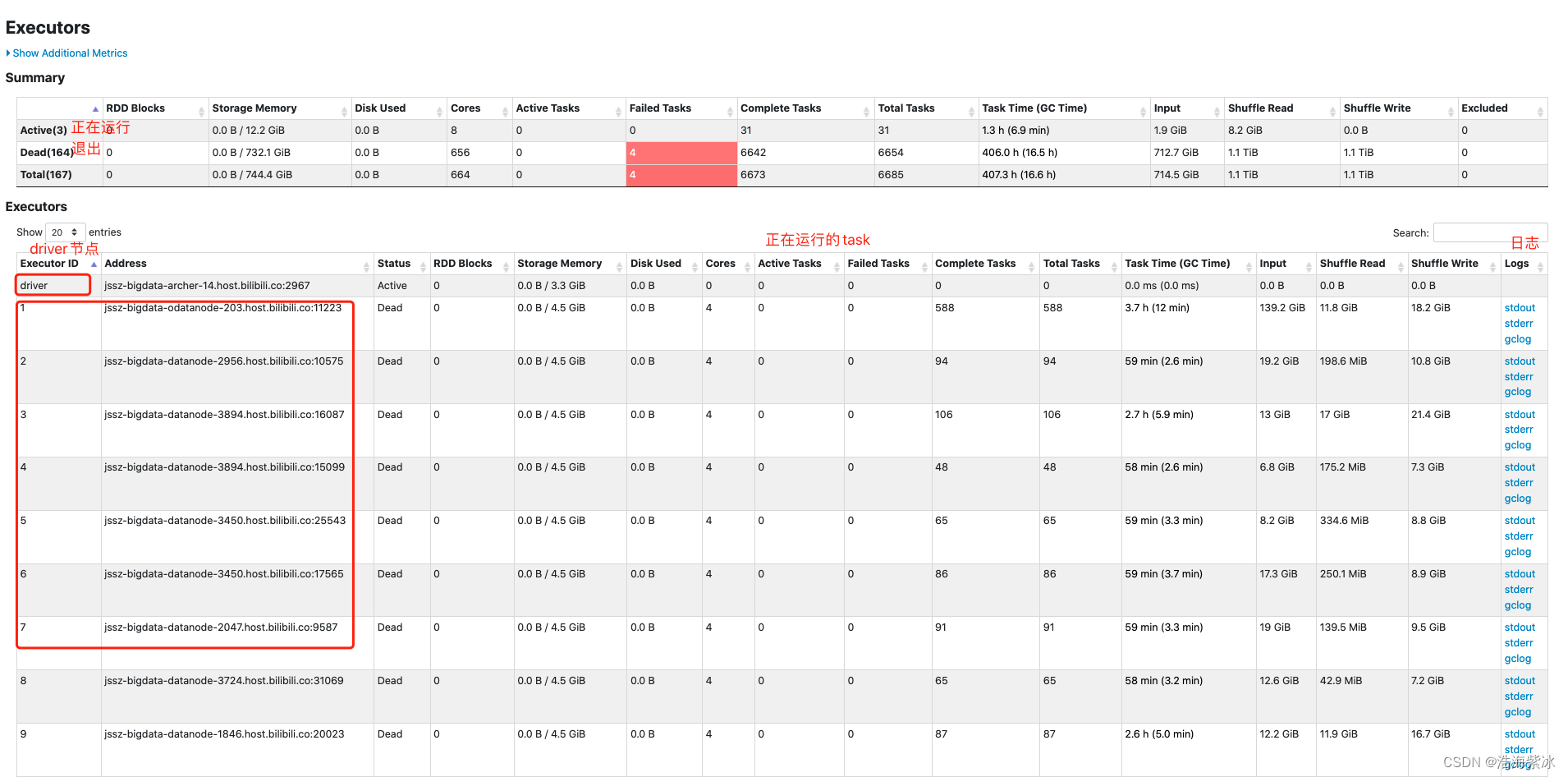
6.ececutor 页面
作业包含的executor统计指标
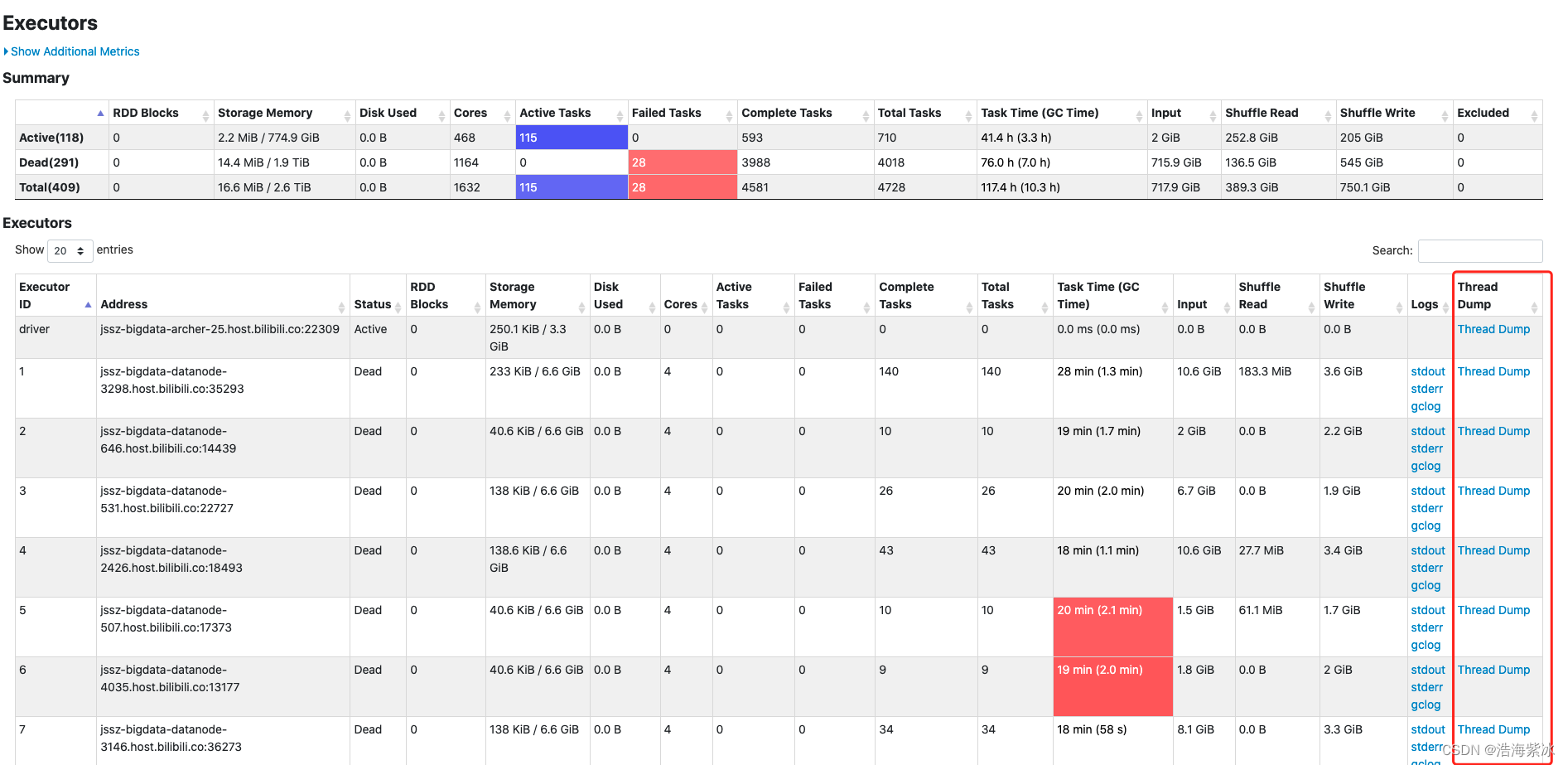
正在运行中的任务有 thread dump ,跟踪task 的执行过程, 目前只能点开 driver 的节点, executor 节点 点击不开.

******7 sql 页面 ******
spark SQL 的执行情况, 一条sql 在spark 中如何执行. 但是B站的spark ui 点了没反应,需要从另外的入口进去, associated sql query 点击

detail 展示sql 在sqprk 中解析和优化的,B站的这一模块只展示了 3和4 部分

1.analysis 2.logical optimization 3. physical planing 4. code generation

问题
1.job driver executor task 关系
物理划分: client 提交→ appmaster 申请资源启动 → driver 启动→ executor启动 → code 执行 → 资源回收释放
逻辑划分 action → job → stage → task
2.判断任务倾斜
运行时间长?
参考链接:
版权归原作者 浩海紫冰 所有, 如有侵权,请联系我们删除。