
大家好呀,20号mathorcup大数据赛发布赛题以来,我就在知乎先是发布了选题建议及初步思路讲解,本来预计是24号完成成品的书写,但没想到最后28号才完成,之后我也录制了成品讲解视频,成品讲解视频以及完整成品获取都可以看本文最下面的我的个人卡片哈。
然后本篇文章是关于这道题的图文讲解,我会一点一点手把手教大家如何去分析以及解决这道题目,是一个保姆级别的教程哈,大家点赞收藏关注一下,后续可能还会更新。
这一次之所以比我预计出成品的时间晚了三天多,因为我24号阳了....同时更悲催的是我发现自己阳之前的计算出了纰漏,所以全部需要推倒重算,所以我这几天只能是退烧的间隙计算以及通宵写论文,幸好最后还是完成了。所有的权重表格给出了,最终的预测在训练集上精度都在95%以上,而针对测试集的精度,我论文里会有大量的篇幅来解释其精度,这道题任何人如果测试集精度在70%以上,要么本末倒置删掉了一些人的数据提高了(这样的做法我能提升到90%以上,论文里也有说明,但这没意义),要么就是做错了。因为打分是很主观的。
本次比赛论文是我有史以来写过最长的一篇,全文98页,一些修改说明提醒7页,正文80页,附录11页,篇幅之所以这么长,是因为:
1.题目给的自变量的因素非常多,并且因变量有8个,所以针对于每一个自变量都要给出详细的权重表格以及最后的预测打分表格,这些表格是不可或缺的,不然这道题根本就没有解答完,一共占了估计有60页,本质上其实是要放到附录里的,为了方便你们阅读和理解我写在正文里。
2.这道题的题意理解以及数据处理和分析等工作比较繁琐,我论文里会有大量的黄字提醒来告诉你们如何理解以及如何操作等,为了照顾每个人的水平,事无巨细,这些理解之后你们是不需要放入最终论文里的
OK,废话不多说,开始吧。
这里是我的论文总览:

这是摘要:

具体讲一下吧,一开始,我们获得的是一个pdf的题目以及几个数据表格。
看一下题目:
第一问:

问的是影响满意度的主要因素对吧?
那也就是给出各个因素的权重。
看一下数据表格:

这一列就是满意度
但是大家一定要注意!不是说后面所有的都是因素!

从这一列开始的才是因素。
为什么这么说呢?
看一下人家题目说的:

大家一定要能理解到,这个叫体验:
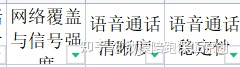
这个叫整体体验:

剩下的这些叫影响客户语音业务体验的因素:

这一点要格外注意,如果有人用客户本身的打分去作为客户满意度这一个本身也是打分的因素,那就是本末倒置了,打分是体验,不叫因素。
OK,在知道这一点后,那就要首先开始我们的数据预处理工作,以便后续计算使用。
OK,开始第一步:
数据预处理——数据删减与补充
看一下题目给出的的数据说明:

我们主要关注的自然是那些缺失数据。
例如用户描述:

这个在数据说明里说了,空白的为缺失,所以可以删去。
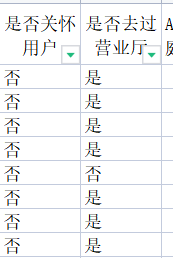
而是否关怀用户:

这个里面的空缺值,空白的是“否”:

所以需要填充上去:
此外,还有一个特殊情况,大家务必注意一下,那就是在附件1和附件2中,这两项的说明是不一样的:


一个说了空白为0,一个没说,那些没说的,按照题目的意思:

就是数据缺失了。
这一点一定要注意,可能是出题人觉得语音跟重定向次数这些没关系,也可能语音和上网的统计部门不一样,总之人家怎么说就怎么来吧。
OK,总之就这个方法,把所有的全处理完。
接下来就是数据标签化了,那些数据是文字的项目,需要标签化为数字,不然无法分析:

标签化完了之后,就是某一些极个别的数据补全了,那些缺失值比较少的虽然没被删,但还是要补全一下:

OK,至此,就全部处理完成了,接下来我们需要做一下数据的分析,这样才能在后面的计算过程中有一个整体的把握:

OK,数据处理和分析完成了。开始具体解决吧:
之前我已经说过,本题我才用的是基于决策树分类的随机森林以及gbdt分类来的,这样做的好处是,既可以在中间过程中得到权重,又可以得到第二问的分类预测结果。
那就一直调精度,等精度高了之后,看一下最后的权重就行:


人家问的是满意度的因素排名,还问了打分的因素排名。
那就是两个附件,每个附件4个打分嘛,全都做一下就行了,这些都是必不可少的内容,所以我的论文才会那么长。。。。:
比如这是语音满意度最后的排名:

给出8个这样的统计图就行。
OK第一问结束。
第二问:

有点累,从现在开始我就简短点说吧。
这道题为什么我说是个分类的预测问题呢。

因为所有的打分就是1-10这10类嘛。
所以最终预测附件3和附件4这两个没有得分的表格,等于就是根据这些因素把他们预测一下看它应该属于哪一类就行了。
第一问已经调参完了对吧。
看一下训练集和测试集表现就行:

训练集精度99%以上,但是测试集不是很高
这一点我会在论文里有大量篇幅去解释哈,这里我就不赘述了。
给出测试集的表现:

给小白解释一下,测试集的意思就是从附件1和附件2这俩个本身就包含真实值的附件里划分出来的,一个是训练集一个是测试集,训练完了测试一下,因为有真实值对比,所以可以获得精度,能理解吧?
OK,测试集表现给出来之后,那就是最终对附件3和4进行预测了嘛。
这里在实际预测之前,需要对附件3和4继续进行预处理,附件1和2怎么处理的这里就怎么处理,不然无法导入进我们训练好的模型中:

当然了,处理过程中还会有很多其他问题,比如附件3和4并没有1和2中的某些项,这一点我也会在论文里详细说明和分析,这里就不赘述了。
8个得分全部预测一下,然后整理进入result表格就行:

好了,到此全部结束。以上呢,只是一个提纲挈领的思路讲解,实际的计算过程以及论文书写自然还有很多很多其他细节问题,都会在我的论文里有所体现,数学建模从来不是说一句用什么模型就能解决的简单问题,永远都需要考虑到很多因素的哈。
那么这里是我用到的全部数据表格以及得到的最终全部结果,我也整理好了:

就讲到这里吧,如果对你有任何帮助,别忘了点赞喜欢关注收藏支持一下,
视频版讲解以及完整成品获取等请点击下方卡片哈:
版权归原作者 smppbzyc 所有, 如有侵权,请联系我们删除。