
最近在看Kafka生产者源码的时候, 感觉有个地方可以改进一下, 具体的问题和解决方案都在下面。
问题代码
RecordAccumulator#drainBatchesForOneNode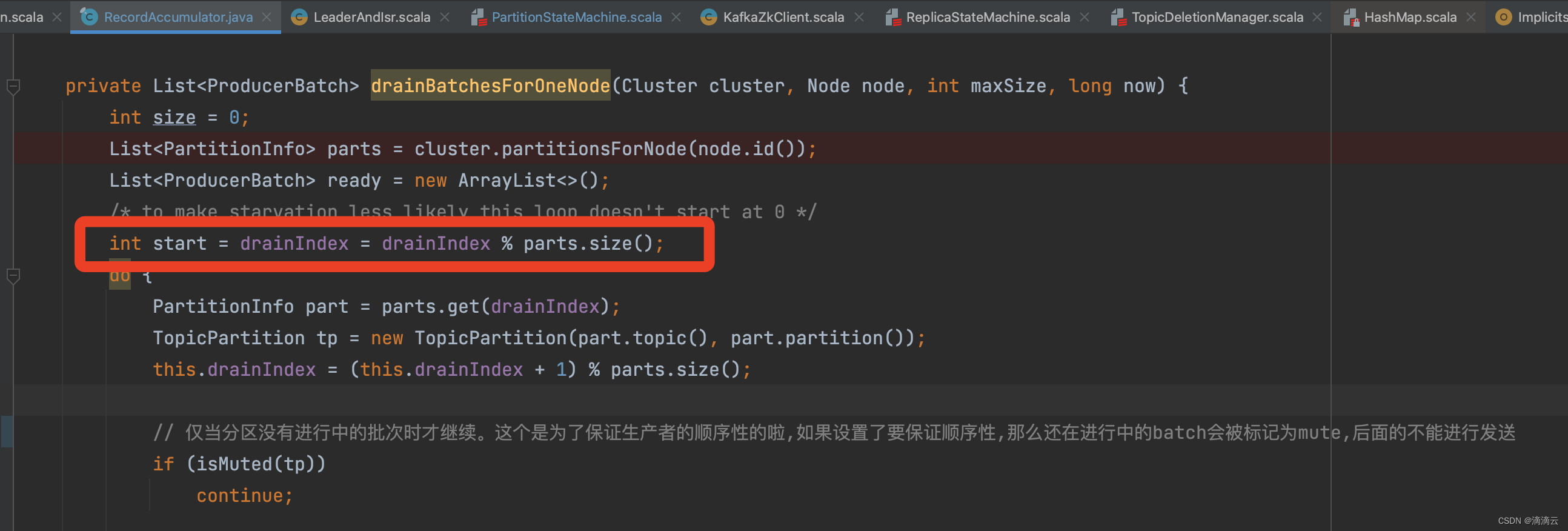
问题出在这个, private int drainIndex;
代码预期
这端代码的逻辑, 是计算出发往每个Node的ProducerBatchs,是批量发送。
因为发送一次的请求量是有限的(max.request.size), 所以一次可能只能发几个ProducerBatch. 那么这次发送了之后, 需要记录一下这里是遍历到了哪个Batch, 下次再次遍历的时候能够接着上一次遍历发送。
简单来说呢就是下图这样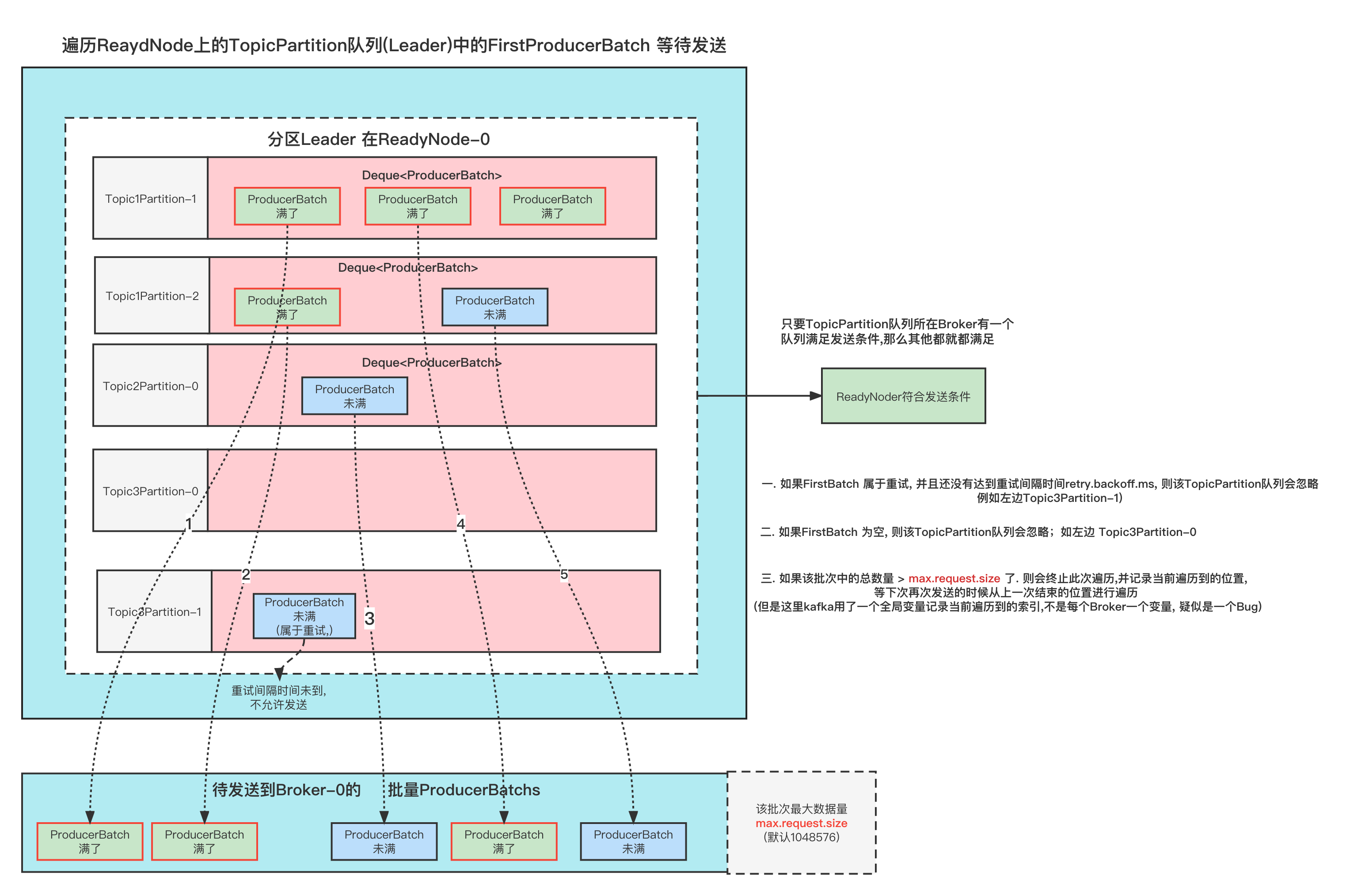
实际情况
但是呢, 因为上面的索引drainIndex 是一个全局变量, 是RecordAccumulator共享的。
那么通常会有很多个Node需要进行遍历, 上一个Node的索引会接着被第二个第三个Node接着使用,那么也就无法比较均衡合理的让每个TopicPartition都遍历到.
正常情况下其实这样也没有事情, 如果不出现极端情况的下,基本上都能遍历到。
怕就怕极端情况, 导致有很多TopicPartition不能够遍历到,也就会造成一部分消息一直发送不出去。
造成的影响
导致部分消息一直发送不出去、或者很久才能够发送出去。
触发异常情况的一个Case
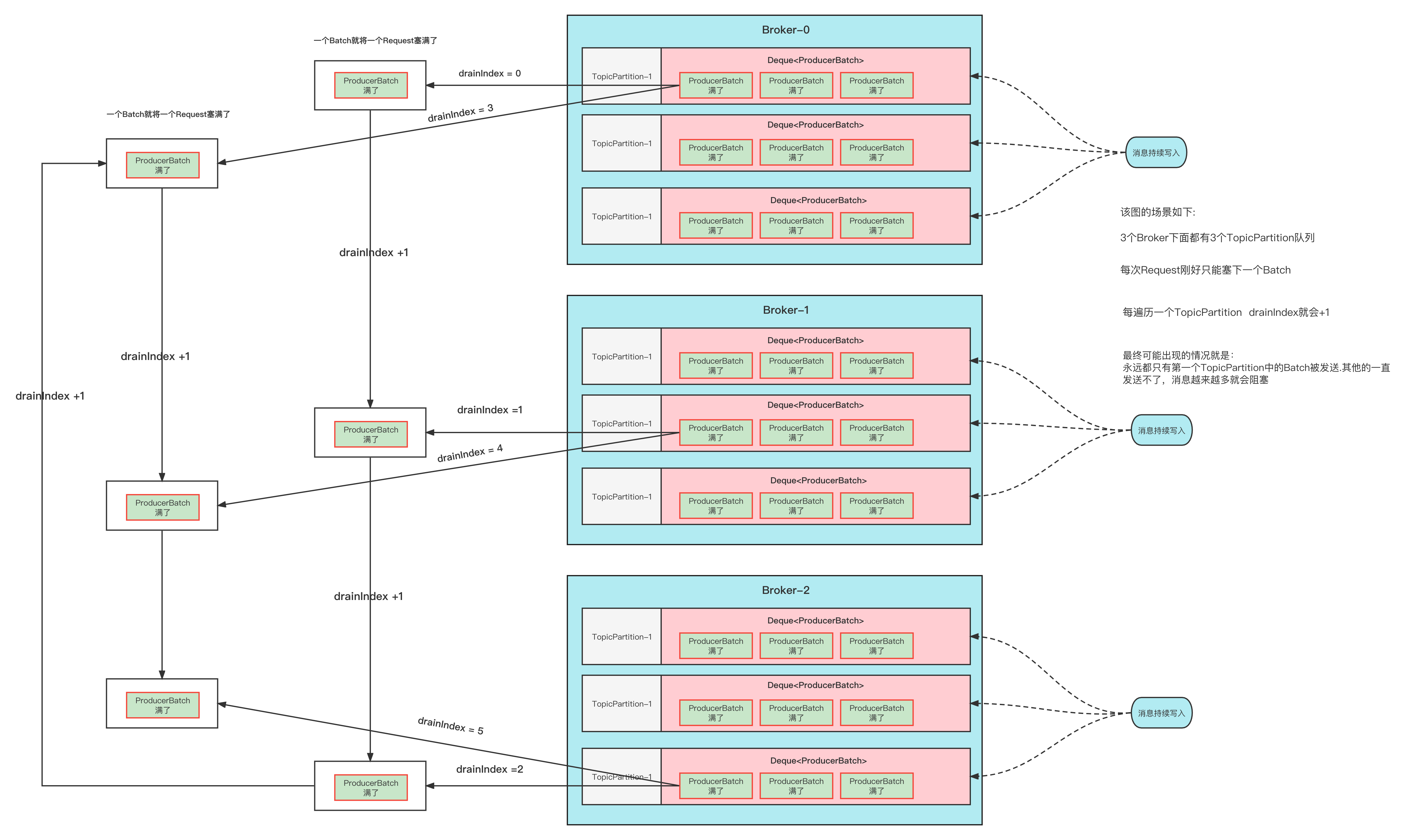
该Case场景如下:
生产者向3个Node发送消息
每个Node都是3个TopicPartition
每个TopicPartition队列都一直源源不断的写入消息、
max.request.size 刚好只能存放一个ProdcuerBatch的大小。
就是这么几个条件,会造成每个Node只能收到一个TopicPartition队列里面的PrdoucerBatch消息。
开始的时候 drainIndex=0. 开始遍历第一个Node-0。 Node-0 准备开始遍历它下面的几个队列中的ProducerBatch,遍历一次 则drainIndex+1,发现遍历了一个队列之后,就装满了这一批次的请求。
那么开始遍历Node-1,这个时候则drainIndex=1,首先遍历到的是 第二个TopicPartition。然后发现一个Batch之后也满了。
那么开始遍历Node-2,这个时候则drainIndex=2,首先遍历到的是 第三个TopicPartition。然后发现一个Batch之后也满了。
这一次的Node遍历结束之后把消息发送之后
又接着上面的请求流程,那么这个时候的drainIndex=3了。
遍历Node-0,这个时候取模计算得到的是第几个TopicPartition呢?那不还是第1个吗。相当于后面的流程跟上面一模一样。
也就导致了每个Node的第2、3个TopicPartition队列中的ProducerBatch永远遍历不到。
也就发送不出去了。
解决方案
只需要每个Node,维护一个自己的索引就行了。
版权归原作者 「已注销」 所有, 如有侵权,请联系我们删除。