
引言:
北京时间:2023/10/9/13:03,一晃好多天过去了,9月14号的文章终于在昨天发出去了,也是许久没有更文了,国庆放假期间由于各种原因,在王者峡谷和铲子世界遨游的不亦乐乎,有待改善!目前面临挑战艰巨,问题很多,在这个空窗期我们需要有一股强大的支撑作为动力,毕竟前路还非常漫长。导致我们更新文章不积极,学习不主动的主要原因有以下两个,一是CSDN博客已经万粉,为了上热榜而日更的要求没有了,二是学习难度上来了,内容变得更加复杂多样,导致我们在总结博客的过程中需要拓展的知识更多,有一种很鸡肋无力的感觉,博客变得越来越长,积极性被削弱。面对这两个问题,目前我没有任何解决方法,因为这都是早期已经规定好的认知,想要让我们的自主性变高,目前的方法只能是寻找源动力,另辟蹊径。这个过程较为漫长,有人说压力就是最好的源动力,当然这是对的,不然目前的我也不会坐在这里给你码字了,但是压力并不符合你切身当前利益,也不是你切身当前所需,所以压力起到的作用其实并没有那么大,否则我就不会有这方面的困扰了。不管那么多,主要是引言分享要到位,零零散散总算是挤出了几个字,该篇博客就让我们来学习一下有关应用层协议相关的知识吧!http我来了!

再谈序列化和反序列化
在上篇博客中,我们重点对网络数据传输进行了学习,明白,因为数据一般都是结构化数据,所以为了提高语言和平台的兼容性,在数据发送时,我们就需要对其进行序列化和反序列化工作,从而让各种语言和平台都能以一种特定的格式(默认已知)获取到数据,最后根据数据完成相应的工作。所以根据这一原理,上篇博客中我们就凭借网络版本计算器的场景,不仅对序列化和反序列化相关知识及代码进行了分析,还对标准序列化反序列化方法JSON的使用进行了学习。只不过在进行新内容的学习之前,我们还需要对序列化和反序列化相关内容进行总结和深入。
首先明白,序列化和反序列化工作除了在网络数据传输时被使用,无论是我们在本地进行数据存储(磁盘),还是将数据存储到数据库(MySql/Redis),都会涉及到序列化和反序列化相关的知识,如:我们将数据(结构化数据)写入到磁盘时,此时操作系统首先就需要将该结构化数据转化为文本字符串,然后对该文本字符串进行格式控制(添加报头/标识符),最后将其序列化成二进制序列存储到磁盘上。当然具体过程以使用的具体标准为准,我们只需要清楚序列化和反序列化过程在数据持久化等存储引擎中也被广泛使用就可以了。
其次还需要知道,在应用层我们无论是对结构化数据进行序列化反序列化(Json),还是对序列化数据进行格式控制(添加报头/标识符),它们都可以被称为是一种协议定制过程,并且都不只有这一种协议定制过程。如:我们使用标准序列化反序列化方法(协议)就不止只有一种方法供给我们使用,而是多种(Xml/Protocol Buffers/MessagePack),再如:我们对序列化数据添加报头和标识符也不止只有一种添加方法,而是可以按照不同的期望,添加各种报头,各种标识符。所以对于协议的理解此时我们就更加明确,明白它本质就是规定,只要是规定就都可以被称为协议,如上述谈到的序列化和反序列化过程,是我们定义的一个规定,所以它是一个协议,当然标准方法它肯定也是一个协议,而我们利用Json(标准序列化反序列化协议)处理结构化数据,然后对序列化数据添加报头/标识符的过程本质也是一个协议定制过程,此时Json就是我们自定义协议中的一个部分而已。而针对于不同的序列化反序列化协议或者对序列化数据添加不同的报头/标识符,此时我们就可以使用协议号进行区分,当然本质也就是将协议号封装到报文中,最终让接收端根据该协议号明确该报文使用的协议,从而实现对数据的正确处理和解析。当然此时再深入理解可以发现,我们在应用层都可以定制各种协议,然后使用协议号来区分,那么在系统层面而言,一个报文使用的是何种协议,最终需要使用何种协议来解析,不同理也可以使用协议号封装到报文的方式解决吗?详情有待深入理解。
正式开始HTTP的学习
对上篇博客有关应用层序列化反序列化相关知识有了更深的认识,此时我们正式进入应用层协议HTTP的学习,只要我们将HTTP协议以及HTTPS协议搞定,那么网络协议栈中有关应用层相关的知识我们就算全部搞定。而在我们学习有关HTTP协议相关知识之前,此时我们先明确几个概念,首先HTTP是一个协议,其次该协议是供给给浏览器使用的,再其次浏览器是一个客户端程序,它的功能和我们平时使用谷歌浏览器/微软浏览器是一样,是在获取用户数据,然后根据用户数据向特定服务器发送请求(HTTP请求)。
显然,上述概念都是应用层宏观概念,可以说是常识,也可以说不是常识,具体是不是我们不关心,但是我们一定要明确。因为只有明确了上述概念,下述知识我们才能有序合理的进行。上述我们强调HTTP是一个协议,想这不是废话吗?然而根据这个概念,并且结合我们对协议二字的理解,此时我们就可以很好的实现知识的迁移和模仿,从而对HTTP有了第一层的认识,明白HTTP和我们之前在网络版本计算器场景下自定义实现的协议本质没有任何区别,当然我说的是本质,并不是内容。本质它们都只是在规定网络通信的方式而已。只不过因为HTTP协议的期望更高,所以HTTP规定的内容更多,处理的细节更加复杂而已。ok,有了协议这一层的理解(注:单独只是对协议二字的理解)之后,此时我们结合客户端和服务端来看一看,在网络版本计算器场景中,我们利用云服务器搭建了一个简易的拥有计算能力的服务器,然后自定义协议让客户端与服务端之间实现了通信。所以此时类比这个我们自定义协议,自定义客户端,自定义服务端的过程,再结合上述概念:HTTP协议是提供给浏览器使用,此时我们就明白,浏览器就是一个客户端,与之对应在远端一定还有一个服务端,浏览器客户端与浏览器服务端之间通过HTTP协议进行网络数据传输。此时从服务端客户端层面,我们对HTTP协议就有了第二层的理解,最后我们根据浏览器的功能,来对HTTP进行最后一层认识,明白,当我们访问浏览器(访问某个客户端(执行某代码)),此时浏览器就会帮我们与远端的浏览器服务端建立连接(三次握手),然后用户就可以在浏览器中输入数据(某链接(IP地址)),此时浏览器服务端获取到该数据之后,结合上述浏览器功能的概念,它首先就会根据IP地址向指定服务器发送HTTP请求来建立连接(三次握手),当目标服务端收到该请求后,根据对应HTTP请求,此时目标服务器就会将自己的网页文本数据作为响应,最终浏览器将该网页文本数据返回到客户端浏览器,浏览器客户端根据其内置代码(HTML/CSS/JavaScript)对网页文本数据进行渲染和展示,最终将一个Web展现在用户的面前。首先根据上述过程,我们就发现,一个协议不仅可以在客户端和服务端之间使用,也可以在服务端和服务端之间使用,并且结合上述理解,此时我们就可以合理的明白,为什么说HTTP协议是提供给浏览器应用程序使用,为什么浏览器客户端和浏览器服务端之间的网络通信协议也一定是HTTP协议。原来是因为浏览器的功能导致,因为浏览器的功能是作为第三方应用,辅助用户与服务器建立联系。然而因为这一用户需求需要被满足,所以市场上就出现了非常多具备该功能的浏览器(谷歌/微软…),而当市场上有了这么多的浏览器之后,因为每个浏览器都是不同的公司研发的,所以在网络数据处理方面使用的一定都是自己定制的协议,那么此时就会导致很多问题,如:用户因为每个浏览器协议不同,使用某些功能的方法不同,使用成本增加;服务器因为每个浏览器协议不同,当任何一个浏览器想要访问该服务器时,就会发送不同协议的请求,如果该服务器都要满足的话,该服务器就要兼容所有浏览器使用的协议,从而实现响应,服务器响应成本增加。所以为了解决上述问题,HTTP协议应运而生。明白HTTP协议就是一款专门为所有浏览器设计的协议,这也就是为什么我们每次在访问服务器时,使用的都是HTTP协议,这也就是为什么我们上述说浏览器客户端和浏览器服务端之间使用的一定是HTTP,因为浏览器服务端想要访问Web服务器就必须使用HTTP,间接导致当数据从浏览器客户端到浏览器服务端的过程也必须是HTTP。
HTTP理论概念理解
当此时有了上述知识的理解之后,我们对HTTP就有了一定的宏观层面认识,HTTP在网络数据传输扮演的角色我们就清晰了。浏览器负责与服务器建立连接,HTTP负责规范浏览器与服务器之间的资源传递。然而对于浏览器如何完成与服务器建立连接这个工作,在之前学习中我们已经明确(socket API),所以此时我们的重点就在于解决HTTP如何规范浏览器和服务器之间的资源传递。
上述我们说HTTP的重点在于规范浏览器和服务器之间的资源传递,为什么称为是资源传递呢?所以此时我们需要明白,对于HTTP协议而言它也被称为超文本传输协议,如何理解超文本传输协议呢?传输协议对于目前的我们来说,非常简单,不就是规定数据传输的格式(序列化)和网络通信的方式(报文),所以同理我们只需要搞定什么叫做超文本就ok啦!那么什么叫做超文本呢?根据日常我们自身对浏览器的使用上来看,可以知道我们在浏览器上可以说是无所不能,无所不用其极的,可以访问任意一个Web服务器(哔哩哔哩/酷狗音乐/爱奇艺/学习通),然后获取到该服务器上的任意数据(音频/视频/图片),发现对于浏览器而言,服务器中的内容这么的五花八门,浏览器想要以第三方的身份完成这份工作,压力也是非常大的,单单接收服务器内容就已经是一个挑战,所以浏览器为了能够成功吃上这碗饭,它就必须提供对应的解决方法,最终同理协议不统一问题,HTTP协议再次应运而生。此时我们对超文本协议HTTP就有了一定的理解,原来其中超文本的意思指的就是HTTP协议不仅可以处理纯文本数据,对于音频、视频、图片等数据它也能处理,并且对于这些五花八门的数据,后续我们就统称为资源。当然,上述我们说HTTP身为超文本传输协议,具有接收音频、视频、图片的能力,但是并不代表HTTP协议有处理解析这些资源的能力,HTTP协议只是规定不同类型资源的传输格式,通过对不同类型资源封装不同格式的报文达到拥有识别这些资源的能力,浏览器就算是合格了。最后具体一个视频或者是一个音频如何被处理,我们进行简单了解,首先明白一个视频和一个音频想要被处理,肯定和硬件离不开,和硬件离不开,那么根据计算机系统的层次结构向上走,它就必须有对应的硬件驱动程序,如:音频驱动程序(声卡)、视频驱动程序(显卡),再向上走就来到操作系统,那么此时我们就明白,一个被HTTP协议标识的音频/视频数据(二进制)最终是如何被操作系统三下五除二给搞定的(具体过程感兴趣你就深入),那么再向上走,此时就来到系统调用,明白操作系统是一个好人,它为了我们可以处理音频/视频等数据,肯定会封装一套系统调用API给我们使用,所以对于我们客户端上的播放器应用程序,本质应该就是一个对系统调用API的封装程序。显然只要有这套逻辑在,能发现浏览器是否具备处理音频/视频的能力,就看它自己是不是够勤奋(封装不封装)。
认识URL
搞定了上述知识,此时我们对HTTP协议为什么被称为超文本传输协议就有了一定的理解,那么承接上述所说,HTTP协议到底是如何规范浏览器和服务器之间的资源传递呢?想要搞懂这个问题,此时我们需要先来了解一下有关URL相关的知识。
什么是URL呢?简简单单URL就是Uniform Resource Locator的缩写,意思就是统一资源定位符,也就是我们平时使用的链接,或者说是网址。所以我们就明白,URL一定是在浏览器中被使用,并且URL一定包含了某服务器的IP地址和端口号。当我们有了这两个认识,同理每个浏览器在使用IP地址和端口号向某个服务器发送HTTP请求时,HTTP协议肯定规定HTTP请求中一定需要包含URL中对应位置的数据(IP地址+端口号),所以当HTTP请求拥有了需要从URL特定位置读取特定数据这个过程,那么此时就间接导致URL的格式一定是不可变的,HTTP天生就知道的,并且因为所有浏览器使用的都是HTTP协议,那么最后就一定会导致所有浏览器使用的URL格式一定是一样的。如下就是一个HTTP协议下的URL:
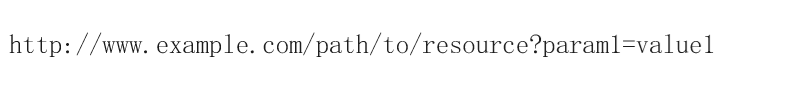
如上图所示,就是一个经典的HTTP协议下的URL,当然目前的URL都是基于HTTPS协议下,具体有什么区别,后续详解。此时从上述URL中我们就可以很好的发现,一个URL的首部一定是该URL使用协议的名称,表示告诉浏览器此时该URL需要使用HTTP协议进行解析,第二部分www.example.com也被称为域名,本质就是服务器的IP地址,在URL中使用域名而不直接使用IP地址的原因很简单,本质就是让用户可以更加轻松的明白该IP地址(域名)表示的具体是那个服务器(www.baidu.com),当然你可以使用特定的方法对域名进行解析,让其变成一个IP地址(ping),在域名之后,也就是URL的第三部分path,表示的就是对应资源在目标服务器上的路径。值得注意的是,这个路径只有在浏览器和服务器建立连接之后,也就是浏览器将Web服务器的网页文本渲染之后(显示网页),此时我们才能通过URL指定不同的路径来访问服务器上的资源。否则,我们在浏览器和服务器建立连接之前,浏览器向服务器发送连接请求时,URL中的路径默认只能是服务器设置好的默认路径,当然也就是网页文本数据所在的路径,如:index.html/default.html,最终成功将网页文本返回给我们。
通过上述一系列的描述,此时我们对URL无论是从概念层面,还是从因果关系层面,我们都有了一定的理解,明白URL的使用场景(浏览器),明白为什么URL必须是统一的数据格式,以及URL标准格式中不同数据代表的含义,明白URL的作用原来就是在浏览器向Web服务器发送HTTP请求时,提供一个标准的、浏览器已知的数据格式供给浏览器获取到用户数据(IP地址+端口号)而已。明白这些之后,此时我们就会发现一个问题,都说访问一个Web服务器不仅需要IP地址,还需要对应IP主机中的某一个端口号,在URL中域名表示IP地址很好理解,那么什么表示端口号呢?答案是协议名称,也就是HTTP表示的就是端口号。如何理解呢?同理,此时我们明白两个点,其一在之前学习使用套接字实现服务端和客户端网络通信之时,对服务端IP地址和端口号进行初始化时我们就有谈到,一个服务端它的端口号和IP地址是不允许随意修改的,必须是众所周知的,只有这样用户在访问该服务器时,才能以最低的成本正确的访问到。以该目的出发,所以当HTTP协议的设计者在规定HTTP协议时,它就规定HTTP协议中必须自带一个默认端口号(80),当URL中没有显式的指定端口号时,默认访问的就是目标IP主机中的80号端口。所以因为该HTTP规定,此时大多数的Web服务器就会在本地将该服务器的端口号设置为80,也就是对应该服务器使用协议中默认的端口号。本质好处也就是让用户可以直接使用域名访问某服务器,降低用户的使用复杂度和成本。
什么是urlencode/urldecode
首先明确,这块知识我们如果展开,将会非常的复杂。为了能够有层次感、有逻辑的讲解,此时我们就需要先进行铺垫。明白在我们平时自己使用浏览器时(微软浏览器/谷歌浏览器),我们并不是直接在浏览器上通过域名去访问某个服务器,而是利用该浏览器上对应的搜索引擎(必应/谷歌/百度),通过在该搜索引擎中输入中文/英文(百度/哔哩哔哩)来获取到浏览器服务器上提供给用户使用的对应Web服务器的链接(URL),然后用户点击该链接实现与目标服务器建立连接,当然该建立连接的过程还是通过浏览器为我们发送HTTP请求完成。所以这也就是为什么一般浏览器会有两个输入窗口,原来是一个输入窗口负责直接对URL进行解析,一个输入窗口负责通过搜索引擎对其进行处理。
明白了上述知识,此时对于学习urlencode和urldecode我们就有了切入点,但该切入点关注的是为什么要进行urlencode和urldecode的问题。在此之前我们需要对什么是urlencode和urldecode做出一定的理解,拆开来看urlencode和urldecode本质还是encode(编码)和decode(解码)的其中一种类型。所以想要搞定urlencode和urldecode我们只要搞定什么是encode和decode就行。而谈到编码和解码,就不得不谈到我们最为熟悉的ASCII码表或者是GBK(国标码),亦或者是Unicode(UTF-8)。明确编码的本质和定制协议是相同的,编码也是一种协议定制过程,当然为什么要进行编码就不用我多说了,谁让傲娇的计算机只认识二进制呢?同理, 所以此时就诞生了ASCII码表,用对应的二进制序列来表示某些特定的字母/符号;GBK,用对应的二进制序列表示某些中文汉字(字符);Unicode,用二进制序列表示全世界语言的字符。所以同理,对于urlencode和urldecode来说,它们本质也就是一种协议定制过程,一种对字符数据进行协议转换的过程,一种将某形式数据转化为另一种形式数据的过程(映射)。明白了这点之后,此时对于urlencode和urldecode的深层次理解我们就明确了,此时只需要套公式将对应urlencode和urldecode之间的转换过程(规则)给完善,我们就大功告成。
规则:
将需要转码的字符数据转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY的形式。源码请看该链接:urlencode/urldecode源码。
拓展编码相关知识: 此时好奇的我对字符类型编码已经有了属于自己的理解,那么我就很好奇对于图片、音频是采用什么方式进行编码的呢?首先从大概念来讲,对于图片的编码方式称为JPEG/PNG,对于音频的编码方式称为MP3/AAC,当然编码方式都是人设计的,上述属于常见编码方式。并且明确无论如何编码,对什么数据进行编码,本质还是在对二进制序列进行编码,只不过此时二进制序列的另一头代表的数据不同,其中对于图片来说,我们要明白,一张图片一定是由很多很多的像素组成,所以我们就把一张图片看成是一个有范围的像素集,而因为像素包括的元素有颜色、亮度、透明度等…,所以我们在编码过程,本质就是在对颜色、亮度、透明度进行编码,对不同颜色、不同亮度、不同透明度组成的像素进行编码,从而完成对图片的编码。音频同理,只不过音频也有其独特的属性,如:音色等…,最终我们对电波进行编码,实现对声音编码。当然无论是具体过程,还是基本概念都不是我们三言两语就能够讲清楚的,此时我们只是简单的了解而已。
明确了上述知识之后,我们对urlencode和urldecode是什么就算搞明白了,那么此时我们就承接上述所说,以浏览器的两个窗口为切入点,来看看到底为什么要进行urlencode和urldecode。在上述讲解HTTP概念时我们说过,因为浏览器是使用HTTP协议向Web服务器发送HTTP请求,而浏览器服务端的数据又来自于浏览器客户端,所以浏览器客户端和浏览器服务端之间使用的协议也是HTTP协议。浏览器客户端在与浏览器服务端建立连接时,发送的也一定是HTTP请求,所以同理,浏览器客户端和浏览器服务端在进行网络数据传输时,也一定要使用URL。行文来到此处,很关键,此时一定就需要结合上述对两个窗口的理解,如:我们使用浏览器时,使用的Web服务器搜索窗口,那么此时我们就只能按照URL规定的格式进行数据输入,输入协议名称,输入分隔符,输入域名,输入分隔符,输入默认网页文本所在路径(index.html),而如果我们使用的是另一个窗口,浏览器自带的搜索引擎窗口,那么此时我们就可以输入任意字符类型的数据(中文/英文/符号),ok,明确这点很关键,所以你发现了什么,是不是就有了一定的因果关系。也就是因为搜索引擎中的任意字符数据,按照上述的理解,一定是发送给浏览器服务端的,而浏览器客户端是通过什么形式发送给浏览器服务端呢?是不是HTTP协议,是不是URL。所以如果我们要将搜索引擎中的任意字符数据成功的发送到浏览器服务端,那么此时就需要对其进行编码。举例:我们在搜索引擎中输入的是URL默认格式中包含的字符,如://、?等…,那么此时浏览器客户端在将该字符数据转化为URL时,是不是就会导致URL的格式出现错乱呢?所以为了规避这个问题,此时就有了urlencode和urldecode。这个非常好理解,本质和我们之前在自己实现网络版本计算器时一样,就是在对客户端发送给服务端的数据进行处理,只不过此时是一个编码过程的处理。
HTTP宏观概念理解
明确了上述有关URL的所有知识,此时我们继续承接上述所说,正式回答HTTP协议到底如何规范浏览器和服务器之间的资源传递问题。本质也就是明确HTTP协议规定了那些内容来保证浏览器和服务器之间通信能够正确进行。同理对比我们在网络版本计算器中自己实现客户端和服务端的场景,明白定制一个网络通信协议,除了对数据进行序列化和反序列化,最关键的就在于如何对序列化数据进行格式控制(添加报头/分隔符),以便于接收方在读取数据时有一定的抓手,从而顺利的读取到预期数据。所以同理HTTP协议,HTTP协议在规定浏览器请求时,除了规定该HTTP请求中对应数据使用何种方式进行序列化和反序列化,更重要的是它还需要规定其它内容来对被序列化反序列化完成的数据进行处理,从而让Web服务器能够依据该请求正确做出响应。当然同理,Web服务器在做出响应时,HTTP协议除了对响应数据进行序列化反序列化过程,同理它也需要对响应数据的其它内容进行规定。那么HTTP协议到底对序列化数据进行了那些内容的规定,本质也就是对序列化数据进行了那些格式控制呢?(添加字段)如下图所示:
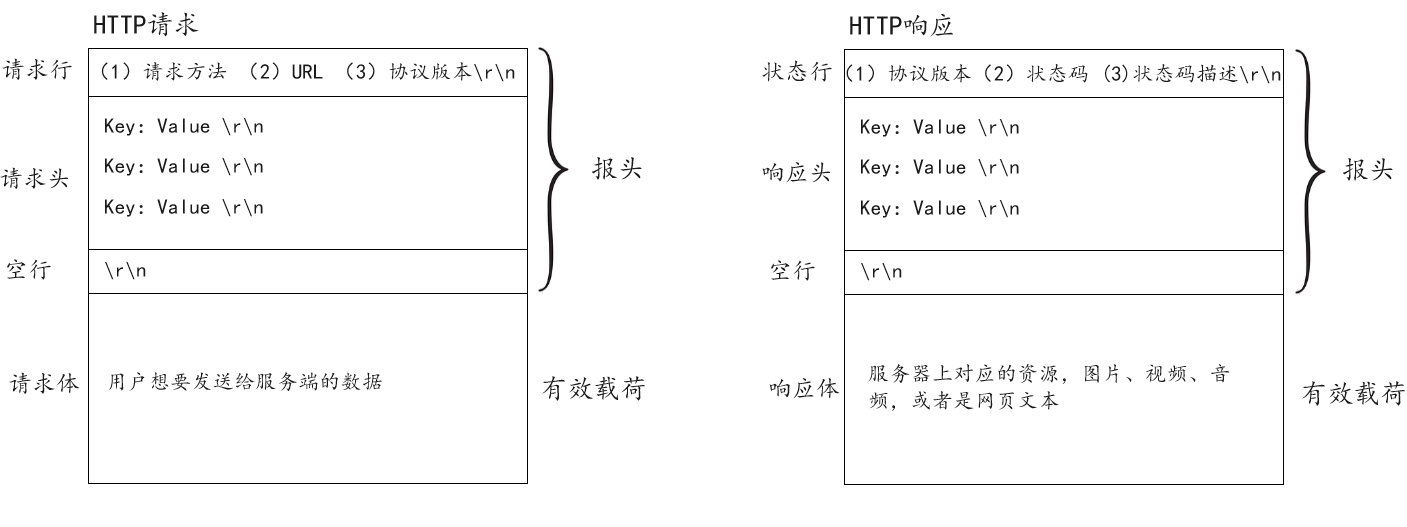
如上图且结合我们在网络版本计算器中自定义协议的过程,明白HTTP请求和HTTP响应就如同是我们自己对结构化数据进行处理时构建的Request类和Response类。在浏览器构建HTTP请求,将用户数据发送给Web服务器这个过程,本质第一步就是在将用户数据依据HTTP协议规定的数据格式进行用户数据结构化,然后再将该结构化数据按照HTTP协议规定的方法进行序列化,最终得到请求体,也就是HTTP报文中的有效载荷。然后再对该有效载荷进行封装,也就是上述谈到的对序列化数据进行添加报头/标识符操作,而这个添加报头的过程对于HTTP协议来说,也就是上图所示在请求体之前添加请求行,请求头,空行等操作。并且HTTP还规定此时请求行中必须带有请求方法(GET/POST)、URL(资源路径)、协议版本字段,当然此时请求头中具体包含那些字段,有待后续深入学习,最后HTTP还规定报头数据格式以\r\n为分隔符,也就是以行的形式进行分割,当对端在读取报文时,就可以依据这一规定,以行的方式区分不同的字段,以空行的方式识别出报头和有效载荷。同理HTTP响应报文,服务端处理对应请求构建HTTP响应的过程,本质还是一个对响应数据(资源路径:某资源)根据HTTP协议规定格式进行结构化,然后再对该结构化响应数据进行序列化的过程。最终根据HTTP响应规定的处理方法,对序列化数据进行如上图所示的状态行(协议版本、状态码(200/404/500)、状态码描述(成功/未找到/服务器异常)),响应头,空行等报头的添加以及\r\n分隔符的添加,最终同理以行为抓手区分字段,空行区分报头和有效载荷。
实践HTTP请求和HTTP响应
该部分知识我们留到下篇博客中详解,主要是因为时间原因,谁让今天是10月24号呢?
总结:通过上述大量的文字描述,对HTTP协议在概念层面我们就算搞定啦!本质剩余知识也就是HTTP协议的实践过程,看看具体在使用过程中是否和我们的概念相印证,印证非常关键!
⭐好书推荐

【内容简介】
《Python从入门到精通》本书以零基础读者为对象,用范例引导读者学习,深入浅出地介绍了Python的相关知识和实战技能。 本书从Python基础入手,介绍了Python的开发环境、各种数据类型的操作方法、流程控制、函数等Python内核技术,以及使用Python处理文件、处理错误与异常等各种应用,最后列举了Python在重要领域的项目实战,内容全面且深入。
📚 京东购买链接:Python从入门到精通
📚 当当购买链接:Python从入门到精通
版权归原作者 狂小伍的博客 所有, 如有侵权,请联系我们删除。